What is a meme, technically speaking?
Exploring the technicity of memes across different digital environmentsTeam Members
Alberto Olivieri, Alexander, Alice Noris, Andre Theng, Anton Berg, Anunaya Rajhans, Artur Holiavin, Chloë Arkenbout, Giovanni Daniele Starita, Kristen Zheng, Marcantonio Bracale, Marco Valli, Nabeel Siddiqui, Nina Welt, Octavian, Samson Geboers, Swati
Facilitators: Prof. Richard Rogers, Dr. Janna Joceli Omena, Giulia Giorgi
Contents
Key findings
-
Software environments greatly affect the conceptualisation and the aesthetics of memes. In fact, the dominant genres and formats tend to vary depending on the platform they are extracted from.
-
The visual analysis reveals a spectrum of formats, whose presence and frequency on the software environments may swing considerably: for instance, Imgur contains the highest number of image macros, as opposed to the dataset extracted with CrowdTangle, in which they were almost absent.
-
Overall, screenshots of tweets is the most frequently occurring format of memes, transversely crossing all the four software environments considered in the analysis.
-
Besides visual analysis, computer vision networks can contribute to memetic ontology. While, the network centrality of dominant web-entities captures what a meme is, identifying pre-memetic components like 'text', 'image', 'screenshot', 'caption', 'cartoon', 'drawing', ' quotation', the peripheral zones of the network show the peculiarities of meme as tied to specific web environments. Finally, ‘bridging’ clusters reveal the entities associated with two or more platforms to classify their covid meme images. Overall, the analysis reveals how meme cultures are shaped by different platform vernaculars, shedding light on what is common between two or more platforms, and what is missing or absent.
1. Introduction
The research we conducted during the Digital Methods Winter School 2022 offers an account of how memes are identified and detected within and across different software environments, thereby contributing to the broader field of meme research. More specifically, this work aims at mapping out the technical composition of memetic images and how this technicality relates or is specific to one or multiple software environments. The project builds on a recent research article, ‘What is a meme, technically speaking?' (Rogers and Giorgi, under review), which conceives memes as collections of artefacts shaped by the software that outputs them.
Existing research understands memes as multimodal cultural artefacts, which are created, remixed and circulated by users across digital platforms (Shifman, 2014; Milner, 2016; Davison, 2012). Their origin can be traced back to fringe digital spaces and, until the beginning of 2010s, they were a prerogative of subcultural communities populating websites like 4chan and Reddit (cfr. Zanettou et al., 2018). It has however become evident that the relevance of memes has extended onto mainstream digital media as well, as they have become an “ubiquitous, arguably foundational, digital media practice” (Miltner, 2018, p. 412). In this respect, memes are regarded as a full-fledged genre, with sets of sociologically defined rules and conventions (Wiggins and Bowers, 2015).
Notably, scholars have placed the emphasis on different aspects of memes, such as their typology (Shifman, 2013; Laineste and Voolaid, 2016; Dynel, 2016), their viral circulation (Spitzberg, 2014) and their role in different subcultural environments (Nissenbaum & Shifman, 2017; Miltner, 2018). Besides the vernacular approach, an interesting and relatively understudied aspect consists in the exploration of memes’ technicity, materiality and relationality tied to platform specificities. As described by Niederer (2019), this “technicity of content” is demarcated and co-constituted by the carrier that furnishes them (p. 18). In this light, the point of departure of the present work is the definition of memes as products resulting from a combination of technical affordances, conventionalised practises and digital participatory culture.
Borrowing the term ‘technicity’ (Niederer & Van Dijck, 2010) to capture the idea of the meme as ‘technologically composed’ or ‘co-constituted’ by its software environment (Bucher, 2012), we thus set out to investigate memes as online products that may be labelled and collected in databases, media–making software or generators, identified and labelled by analytical and vision software and returned by ‘meme search’ in research and marketing data dashboards. Each software brings a peculiar meme collection into being, bringing into focus certain features and overshadowing others. That is, the collections of technical objects rendered by the software environments have different features that depend on whether they were amassed through a database, templating, analytics, matching or other logic. In this light, we also seek to lay the ground for an empirical reflection on how the technical environment may affect the type of meme research that can be carried out.
3. Research Questions
Following the theoretical framework outlined above, this research seeks to provide an answer to these research questions:
-
How does the software environment in which memes are demarcated contribute to shaping different meme collections?
-
How does that set- or collection-making affect meme research?
Through this empirical study, we aim at showing that different software environments contain a different logic to the formations of meme collections. With this in mind, we formulate the following hypothesis: the collections of technical objects rendered by the software environments have unique features that depend on whether they were amassed through a database, templating, analytics, matching, or other logic.
4. Initial datasets
Case selection. The database for this research was assembled by participants of the Winter School by collecting images on four selected software environments. Our selection of platforms, which could be described as a form of maximum variation sampling (Etikan et al., 2016) with a focus on case diversity and heterogeneity, includes:
-
CrowdTangle, a marketing tool of the company Meta (former Facebook), which was employed to extract data from Instagram and Facebook;
-
Google Images;
-
Imgur, a digital generator that furnishes templates for image macros;
-
KnowYourMeme, one of the earliest and most well-known meme repositories.
Data collection. To capture contemporary representations of what may constitute a meme according to these software environments, and emphasise comparability, we decide to gather memetic content around the topic of the Covid-19 pandemic, as we deemed it a highly mediatised content which has given rise to an intense content production across different platforms (Murru and Vicari, 2021). To further enhance the operability of the image results, the data collection focused on English content (Pearce et al. 2018). In order to ensure an "English" software environment, virtual private networks were used, mimicking a location-based system in the United States (Rogers, 2019).
To this end, we searched for the keywords "covid meme" on the selected platforms. The marketing data dashboard CrowdTangle provides the option for "meme search," where one can query for memetic content on Facebook and Instagram. Furthermore, the dashboard allows us to filter the language (we selected "English") and the type of content (we selected "Photos” for Facebook and “Photos” and “Albums” for Instagram). Data from Google Images, Imgur, and Know Your Meme were collected with the ImageScraper tool (available on GitHub). The time range for the search results was restricted to the year 2021.
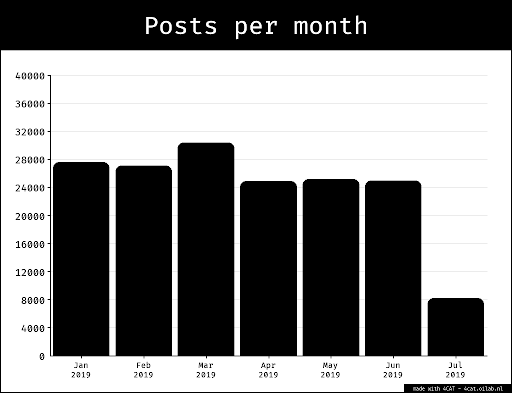
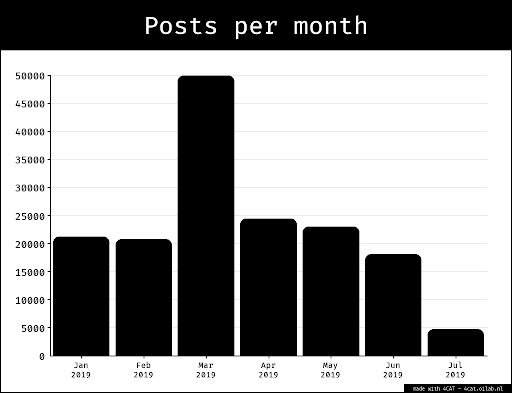
Sampling the dataset. We subsampled the data extracted with CrowdTangle from Instagram and Facebook, choosing the first 1000 images sorted by total number of interactions (one of the default metadata provided by CrowdTangle). For Imgur and Know Your Meme, the first 1000 Images of the search result have been selected, sorted by the interaction rating of the websites. The Google Image data set consists of the first 500 image results due to limitations of the research scope. Figure 1 details the composition of each subsample in terms of number of items considered per software environment.
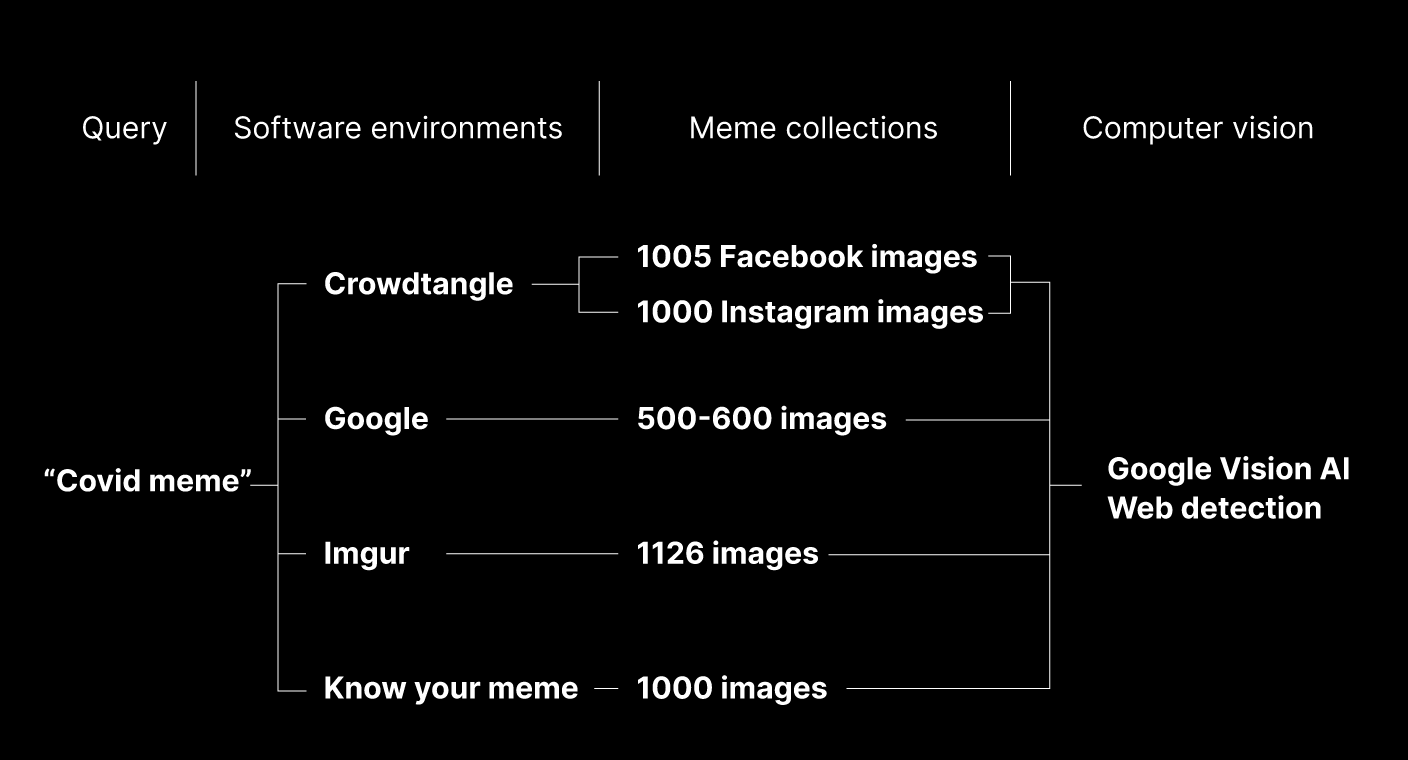
Figure 1. Dataset building process
5. Methodology
Our investigation takes the form of a comparative analysis, aimed at revealing how different software environments identify and group memes differently. By using digital methods and tools such as ImageSorter and Google Vision, the memes collected are sorted based on their formal, visual and content properties, which results in a set of meme formats, some more platform-specific than the others. What one software environment accounts for as a meme differentiates from one environment to another. For instance, what Imgur lists as a meme differs from what Facebook or Instagram accounts for as a meme when looking at their top results. These contrasts add to the argument of Rogers and Giorgi (under review), that the software environment contributes to shaping meme collections.
The analysis of the digital data consisted into two sections of empirical work, respectively carried out by two different subgroups of participants. Specifically, the analysis conducted by Group 1 was based on visual analysis (Rogers, 2021), whereas Group 2 adopted a computer vision network approach (Omena et. al. 2021; Omena 2021). In the remainder of this section, we will illustrate both methodological procedures.
Group 1 - Exploring meme collections through a software for automated visual analysis. Taking each subsample separately, we employed the software ImageSorter to visually analyse the collections returned by the four environments (Rogers, 2021). Organising the images with ImageSorter by hue and colour, the tool enabled us to identify both homogeneous clusters of images (Warren Pearce et al., 2018) and frequently recurring images. Contextually, we were also able to distinguish between exact copies and similar images (Rogers, 2021). We then delved deeper into the analysis of the similarities and differences of the clusters, conducting a close reading of the samples, with a focus on three characteristics traits:
-
Dominant types of Images: which image typologies occurred the most in each sample, in terms of similar images and copies;
-
Ontology: which material and aesthetic elements characterised each platform;
-
Epistemology: what constitutes a meme for each platform based on the respective images in each sample.
Additionally, and assisted by Memespector GUI (Chao, 2021), we looked at the image metadata to extract the websites where fully matching images were found. This helped us contextualise the circulation of images across the web (Omena et. al. 2021), so as to assess the extent to which each subsample resulted from images related to other platforms or were mainly reshared on the same platform we extracted them from.
Group 2 - Exploring meme collections through computer vision. In a second level of analysis, we followed a computer vision network approach (Omena et. al. 2021; Omena 2021) to study the image collections captured in different software environments. A range of research software and tools were required to implement this method, such as DownThemAll (Maier, Parodi & Verna, 2007), Memespector GUI (Chao, 2021), Google Spreadsheets, Table2Net, and Gephi (Bastian, Heymann & Jacomy, 2009).
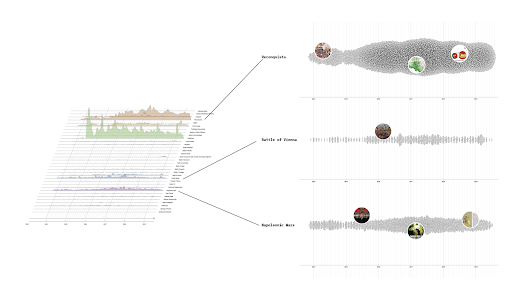
We built a network with computer vision outputs (Google Vision AI web detection, namely web entities) for our image collection, making nodes as platforms (Facebook, Instagram, Imgur, and KnowYourMeme) and web entities. Web entities could be described as a thing, a person, a place (location) or an organisation/event name detected and recognised in Internet-based content. In our context, they provided contextual and cultural references to our image collections, yet going beyond the content of the images themselves (Omena et. al. 2021). Without rendering the images within the network, we were able to make sense of meme materiality by looking at dominant web entities (centre of the network) and meme specific cultural contexts through the periphery zones of the network and bridging web entities clusters.
In the network visual exploration and analysis (Venturini, Jacomy & Jensen, 2019), we focused on the fixed zones of the network, yet understanding the meaning of node position and size to the analysis of images (see Omena & Amaral, 2019). In the network below, platform node size means the total of web entities associated with the meme image collection coming from a platform. Web entity node size means the number of times a given entity was used to describe one or more images (considering all images which come from different platforms). Following the affordances of the graph layout algorithm ForceAtlas2 (Jacomy, Venturini, Heymann & Bastian, 2014), the table below explains node position and how we interpreted the network.


Figure 2. How to read a network of platforms and web entities associated with covid meme images? Explanatory and descriptive table (above) and network gif visualisation (below).
6. Findings
6.1 Exploring meme collections through software for automated visual analysis.
The main findings outputted by the visual analysis approach illustrated in the methods section are visualised in Figure 3. As illustrated in the top spectrum bar, there were various image formats throughout the data sets. When all data sets were combined, tweet screenshots were the most dominant format: a closer look revealed that this format was predominant on CrowdTangle while the Imgur dataset contained the fewest number of occurrences, as illustrated on the second spectrum bar in Figure 3. While some of the sets had overlapping formats, there were also clear distinctions between them. Looking into platform specificities, the highest number of image macros (i.e. images with text over an image and are usually viewed as a traditional meme format) was found on Imgur, whereas CrowdTangle (Facebook and Instagram) contained the fewest image macros. On its part, the dataset retrieved from CrowdTangle featured formats such as portraits (press pictures of famous people, magazine covers, and selfies), social media text images (plain text that is formatted in a specific layout with specific colours as an image for Instagram Stories or Facebook posts for example), social statement cards (information which is formatted with text and images, for news items or inspirational quotes for example) and infographics (often containing graphs and charts). KnowYourMeme included multiple image macro templates (images without texts that are used in meme generators) and logos, while data from Google Image showed merchandise images.Looking at the occurrence of images, it emerges that samples extracted from the Google Images and the Imgur datasets contain a significant number of similar images. These sets also featured a relatively small number of same images (duplicates), which were mostly image macros.
Looking at these results, it can be argued that software environments greatly affect the gathered sets of images. In fact, the dominant genres of images tend to vary depending on the platform they are extracted from. If one were to consider as memes only the formats present in all datasets, then memes would be screenshots of tweets.
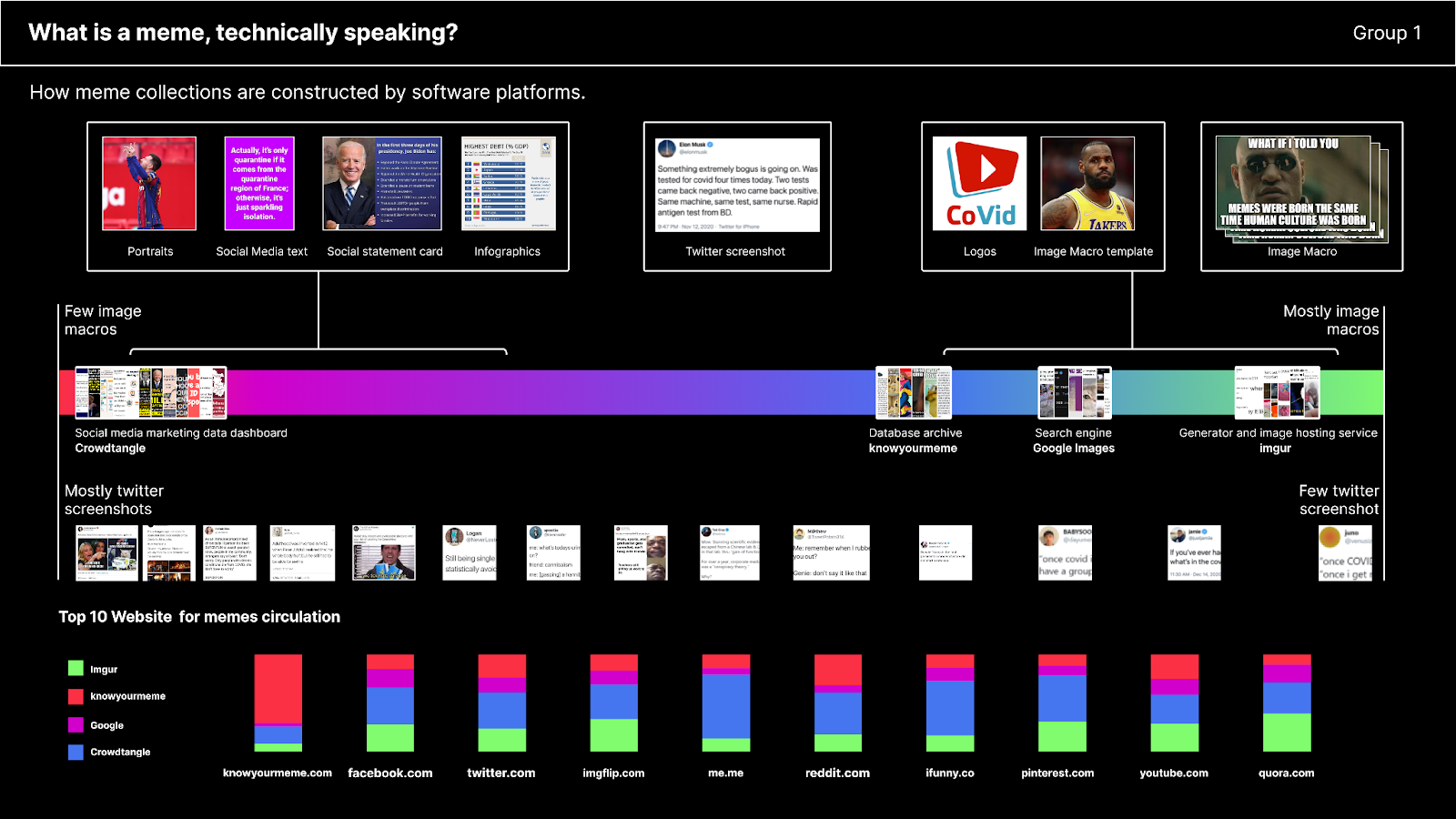
Figure 3. The spectrum of meme formats and their circulation on the web.
6.2 Exploring meme collections through computer vision.
#Google vision’s web entities detection as an accurate tool to identifying memes
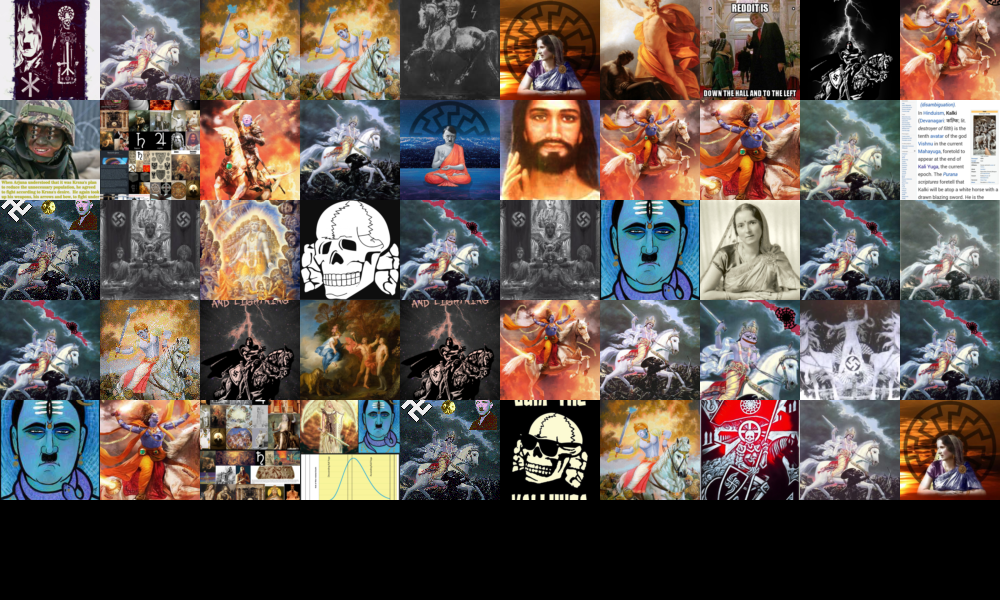
The following image-wall is generated with the dimensionality reduction technique UMAP and clustered by PixPlot. As can see, how Google Vision’s web entities are surprisingly accurate in identifying memes, outperforming Crowdtangle. All the images have ‘meme’ in their web-entity description, and the classification returns all de facto memes, constructed through familiar templates and image macros. Google Vision’s accuracy in separating memes from non-memes highlights the medium-specificity of memes: they are natively digital collections, co-constituted by the software environments in which they are disseminated and circulated. In fact, web-entities detection considers sites of circulation among its parameters, thus improving its classification accuracy. In other words, if an image circulates in a memetic environment, and is part of an extensive collection of similar images, then this image is probably a meme. Therefore, researchers should take into account the technicity of the memetic medium and its web environments to make sense of large memetic corpora.
Figure 4. Using Pixplot to interrogate the accuracy of web entities for meme identification.
#Computer vision networks for making sense of meme image collection
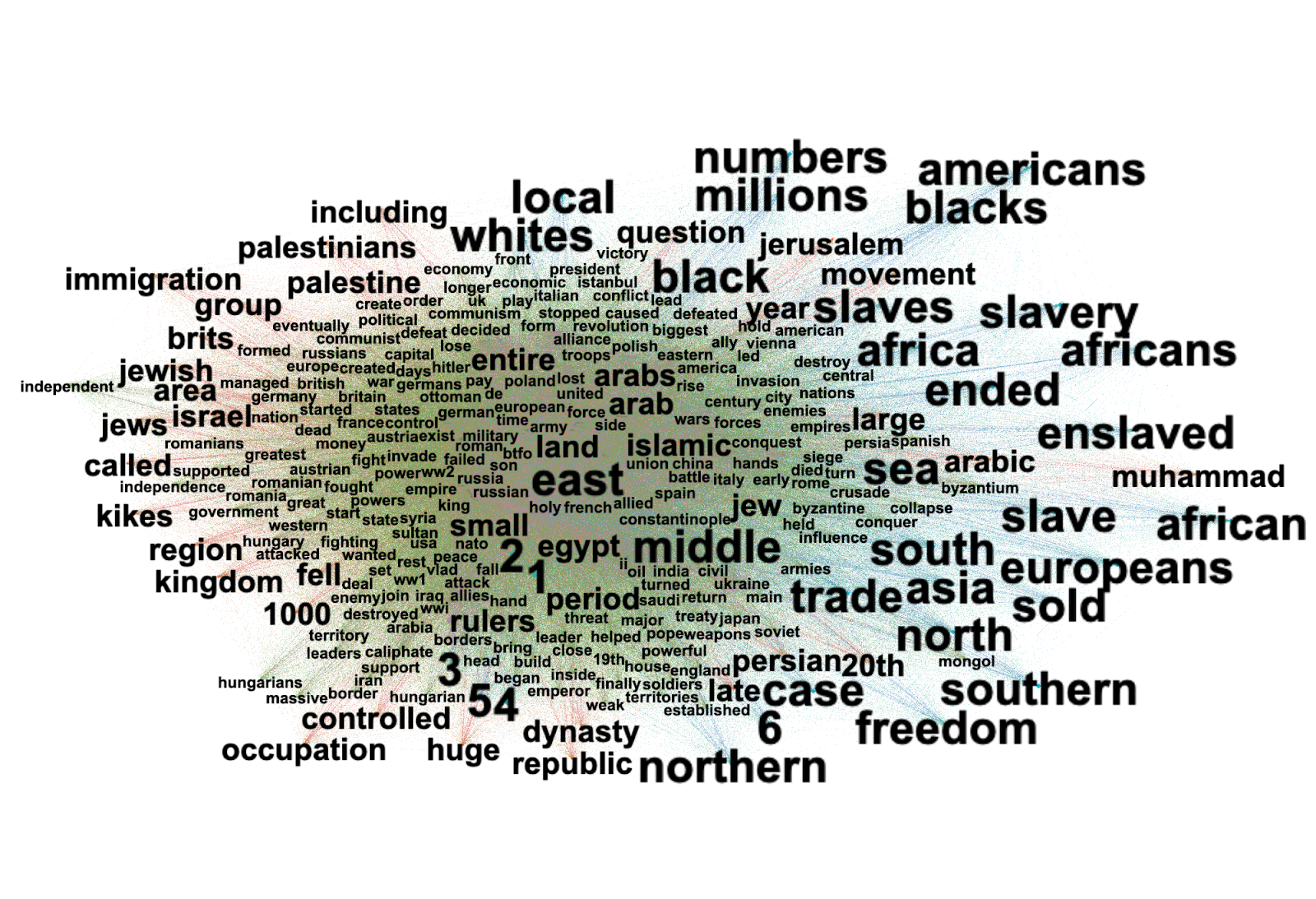
Computer vision networks are built on top of computer vision features such as image classification and web-entities detection. Here we used web-entities detection, going beyond and behind the immediate image content, and using the web environment as a contextual and cultural knowledge source to augment and enrich image analysis. From detected web-entities we construct a bipartite network with a platform node to which platform-specific web-entities are linked. In the centre, we find shared-web entities, while in the periphery web-entities are associated with specific web-environments and meme cultures (Imgur, FB, IG, KnowYourMeme). Between platform pairs, we can see bridging clusters representing shared web-entities, in other words, what platforms have in common.
Computer vision networks are built on top of computer vision features such as image classification and web-entities detection. Here we used web-entities detection, going beyond and behind the immediate image content, and using the web environment as a contextual and cultural knowledge source to augment and enrich image analysis. From detected web-entities we construct a bipartite network with a platform node to which platform-specific web-entities are linked. In the centre, we find shared-web entities, while in the periphery web-entities are associated with specific web-environments and meme cultures (Imgur, FB, IG, KnowYourMeme). Between platform pairs we can see bridging clusters representing shared web-entities, in other words what platforms have in common.

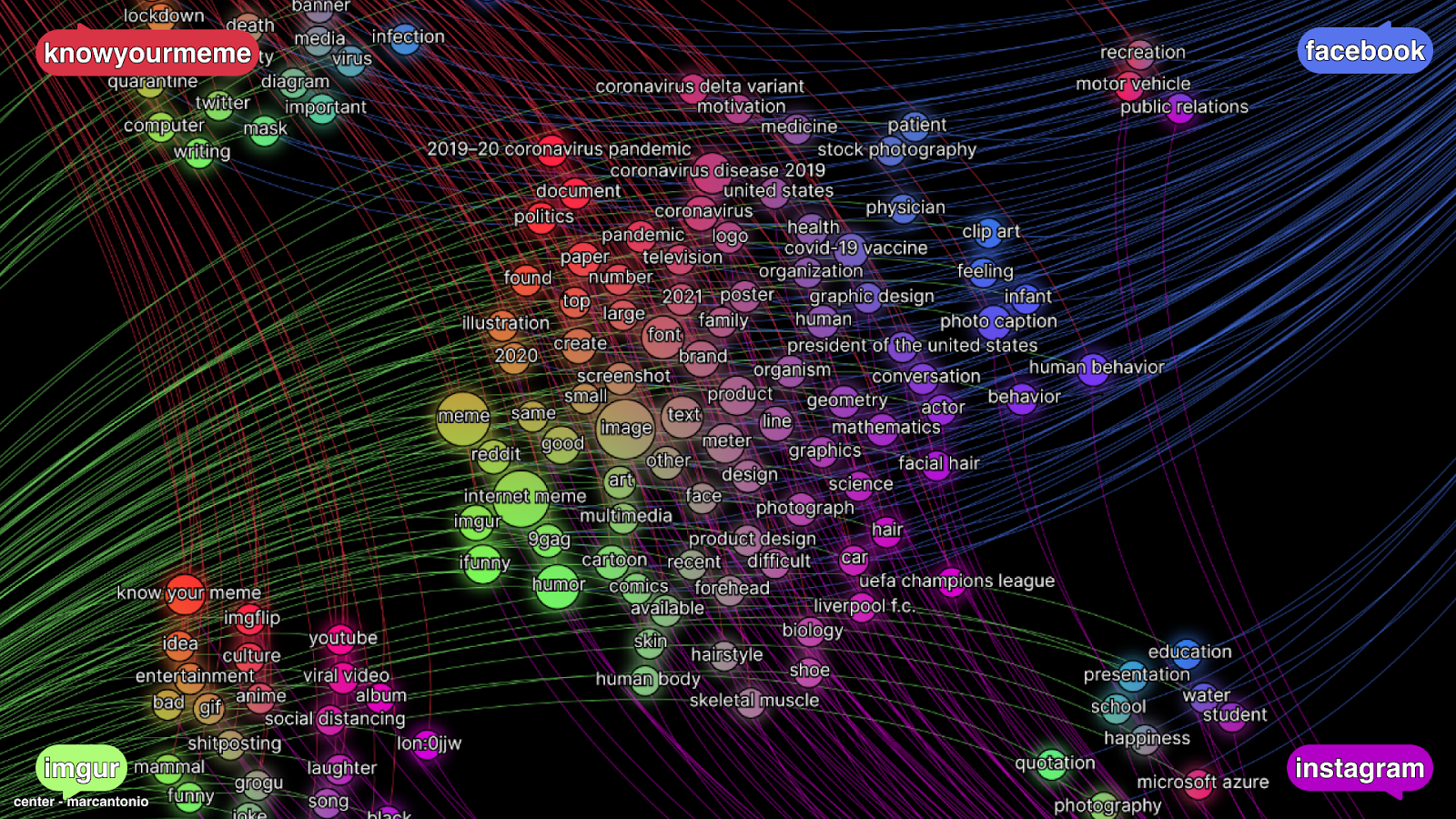 Figure 5. The formal and thematic elements that constitute covid memes images. Shared web entities associated with cross-platform meme image collection (above).
Figure 5. The formal and thematic elements that constitute covid memes images. Shared web entities associated with cross-platform meme image collection (above).
An analysis of the central cluster shows how computer vision networks can contribute to memetic ontology. The network centrality of dominant web-entities, functioning as cross-platform bridges, shows through the flatness for network analysis how the ontological hierarchy of computer vision models captures what a meme is. Entities such as 'text', 'image', 'screenshot', 'caption', 'cartoon', 'drawing', ' quotation' are pre-memetic components that are not-yet memes. In other words, the formal elements of memes, their building blocks and necessary conditions, are – from a network perspective - cross-platform web-entities. These central web-entities constitute the ontological and epistemological primitives of the memetic medium: what a meme is, how can we recognize them and how can we create them. As we can see, the only thematic cluster in the centre is composed of entities relating to Covid, reflecting the original query design and representing it as network centrality. A similar reasoning applies to the ontology of a ‘covid meme’: it must say something about the pandemic, the vaccination campaign and engage with politics. We can argue that meme research conducted through computer vision networks will often return similar results: in the centre we will find memetic primitives – formal and thematic -, while the peripheral constellations will express local meme cultures.

Figure 6. The peripheral zones: meme cultures and platform vernaculars
In the peripheral zones of the network we see a clear division. On one side, covid memes are more mainstream-oriented, being Facebook featured by mainstream politics whereas Instagram as mainstream culture. On the other side, we see niche memes related to nerd culture (Imgur) and alt-politics (Know Your Meme). Both cases reinforce the argument of memes as collections that respond to the software environment in which they are inserted.
The web entities associated with Facebook covid memes exposes the pandemic and its related news, also current events with special focus on political news, political personalities, country politics and policies. Memes are disconnected from pop culture and internet culture references. Below, examples of web entities exclusively associated with Facebook covid memes.
-
Memes as mainstream politics/political figures:
-
modi, greg abbott, national health service, ron desantis, governor, florida, government of india
-
-
Memes as mainstream news:
-
press information bureau, ministry of health, omicron variant, philippine daily inquirer, transmission of covid, occupy democrats, lambda variant, handwashing, long covid, dose, lambda variant
-

Figure 7. Facebook web entities network
On Instagram we see a direct relationship with the mainstream aspects of pop culture. For example, sports and celebrities with entities like messi, ronaldo, real madrid, england football team. Also, the obvious visual language of Instagram, e.g. fashion, glamour and hype, was identified through entities like socialite, dress, turquoise, sunglasses, crypto, bitcoin, ethereum, beauty, physical fitness, model. The memetic culture of covid memes on Instagram is not directly related to pandemic, news or politics.
Figure 8. Instagram web entities network
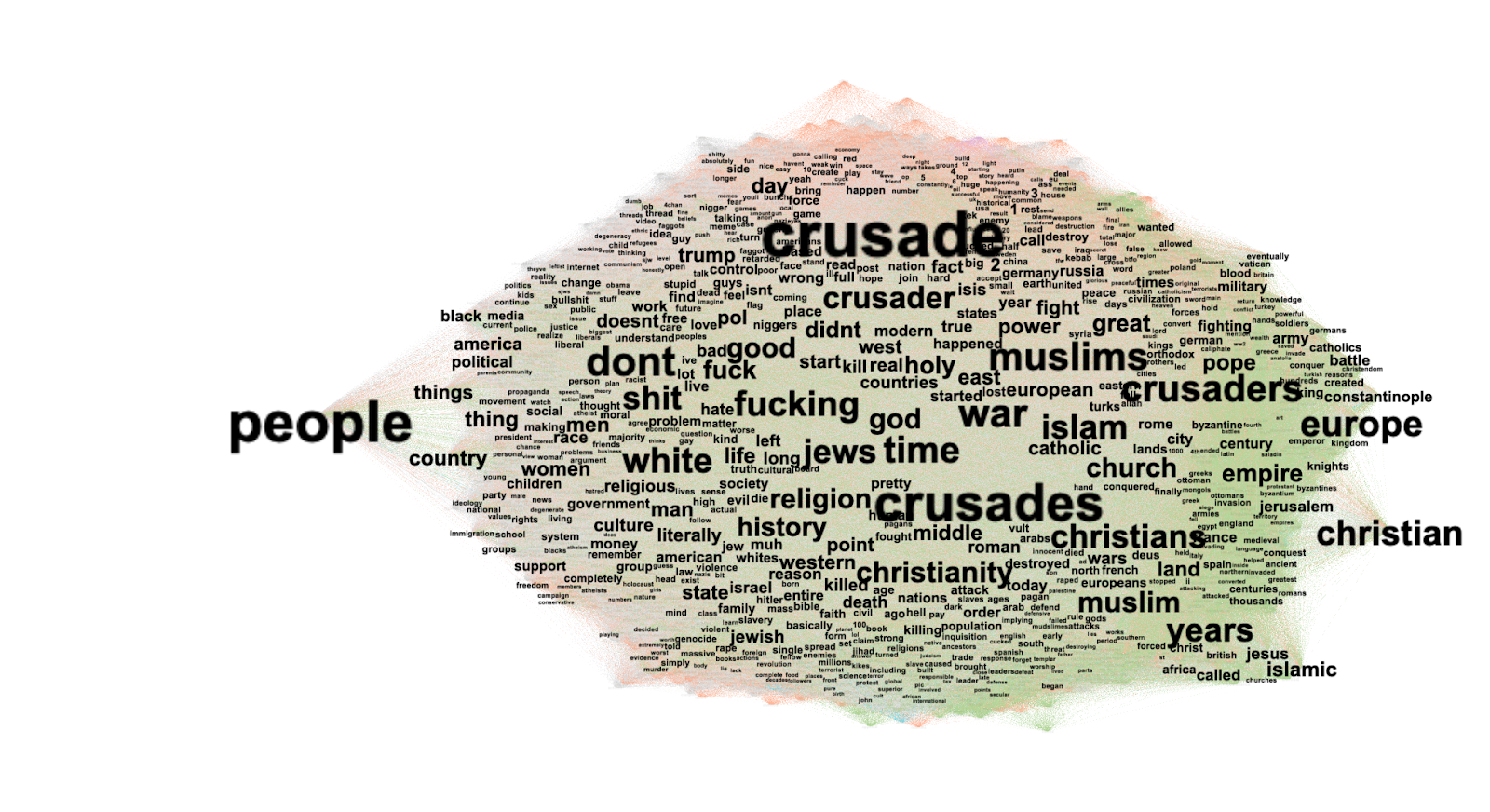
The web entities exclusive to the software environment of Imgur are mostly associated with pop cultural references and located at the junction of pop culture and internet culture. Within them, we can spot two distinct yet interrelated sets: the first contains references to nerd culture, displaying entities such as Harry Potter, Batman, Voldemort, Hobbit, Studio Ghibli, Star Wars, Lord of the Rings, Dungeons and Dragons, Pixar, and Fullmetal Alchemist. The second set appears to be related to viral internet culture and cultural phenomena in general: among the entities, we find ‘i can has cheezburger’, tiger king, dog videos, okay boomer, guitar, depression.

Figure 8. Imgur web entities network
Looking at the web entities associated with the web archive Know Your Meme, it emerges a cluster of niche and therefore non-mainstream references. At the same time, there is a substantial lack of references to mainstream politics or mainstream celebrity culture. Instead, it is possible to identify a general focus on internet phenomena and specific to the deep vernacular web (Tuters, 2019), as suggested by entities like wojak, corona chan, space karen, wookiepedia, 4 chan, deviantart, cheems. Besides that, it can be observed that political references are more representative of extreme political ideologies (both far right and far left), as hinted by a group of entities associated with the Alt-right ideology: Pepe the Frog, right wing, anthony fauci, political spectrum, political compass, authoritarianism, and vaccine controversies.

Figure 9. KnowYourMeme web entities network
Looking at the web entities of the four clusters it can be argued that KnowYourMeme and Imgur together are more niche and less mainstream, with respect to the other two web environments considered. Finally, the network also enables one to look at the “upside down” of each software environment, which contains the web entities common to the other platforms. In this sense, it is possible to define the memetic production of a specific digital space by looking at its “shadows”, that is by considering what is missing from the memes that it produces and disseminates. That is the case of the web entities cluster shared by Instagram, Know Your Meme and Imgur but not by Facebook, such as know your meme, joke, laughter, entertainment, youtube, viral video, grogu, imgflip.
Figure 10. The “Facebook shadow” or “upside down”
7. Discussion
This research, conducted during the Digital Methods Winter School 2022, looks into the technicity of memes as tied to platform specificities. This study follows the research trajectory set forth by Rogers & Giorgi (under review) in their paper 'What is a Meme, Technically Speaking?', which proposes to demarcate the technicity of memes as collections of content outputted by software environments.
Epistemologically speaking, when looking at the findings a few points are worth discussing. Firstly, when looking at what a meme is technically speaking with a social media marketing dashboard logic lens, this constitutes the broadest ontology of what is considered a meme; not just the classical image macro format is present here, but also many different other formats. Secondly, when looking at what a meme is technically speaking with a generator and image hosting server logic lens, this constitutes the narrowest ontology of what is considered a meme; a classical image macro format. Thirdly, when looking at what a meme is technically speaking with a database archive and search engine logic lens, the ontology lies somewhere in between; classic image macros are combined with a couple of other formats. Lastly, what is interesting is that all of the previously mentioned logics see tweet screenshots as an important part of the technical meme ontology.
From the standpoint of computer vision analysis, we inferred what a meme is through Google Vision’s web entity detection. The network building technique enabled image cross-platform analysis using all of the languages Google and its Vision technology support, yet without viewing the images. Not only were we able to inform what technically constitute covid memes but we also grasped meme vernaculars cross-platforms. We inferred platform-specific topics derived from web entities by closing reading the periphery and mid-zones of the network. Here, meme analysis required the expertise of a multidisciplinary team and the acknowledgement of the technicity of the memetic medium and its web-environments.
8. Conclusion
The research question of what a meme is, technically speaking and how meme collections are constructed by software platforms, is a broad one. Our research project has only started to scratch the surface of how the technicity of memes can be empirically investigated. Looking at the results, it can be overall argued that what constitutes a meme is highly dependent on the software environment as a platform-specific contextual web environment and definitions differ widely per platform. In fact, this project provides empirical findings supporting the main claim of Rogers and Giorgi (under review), i.e. that memes have a technicity that materially affects them as collections under study.
Albeit limited, these findings also enable us to conclude with a speculative statement on what the above could mean for meme research in general. The ontological definition of what a meme is, based on the software environment we looked into, is broader than what researchers most likely would categorise as a meme themselves (the classic image macro) and includes more image formats. This implies that when researchers use these tools to conduct meme research, what they are researching is moving towards a wider mode of viral image analysis, moving from a more niche vernacular type of research.
9. References
Bastian, M., Heymann, S., & Jacomy, M. (2009). Gephi: An Open Source Software for Exploring and Manipulating Networks. Third International AAAI Conference on Weblogs and Social Media, 361–362. https://doi.org/10.1136/qshc.2004.010033Bucher, T. (2012). A technicity of attention: How software 'makes sense'. Culture Machine, 13, 1-23.
Chao, J. (2021). Memespector GUI: Graphical User Interface Client for Computer Vision APIs (Version 0.2) [Software]. Available from https://github.com/jason-chao/memespector-gui.
Davison, P. (2012). The language of internet memes. The social media reader, 120-134.
Dynel, M. (2016). “I has seen Image Macros!” Advice Animals memes as visual-verbal jokes. International Journal of Communication, 10, 29.
Jacomy M, Venturini T, Heymann S, Bastian M (2014) ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. PLoS ONE 9(6): e98679. https://doi.org/10.1371/journal.pone.0098679
Laineste, L., & Voolaid, P. (2016). Laughing across borders: Intertextuality of internet memes. The European Journal of Humour Research, 4(4), 26-49.
Maier, Nils; Parodi, Federico & Verna, Stefano (2007). DownThemAll (Version 4.04) [browser extention] . Available from https://www.downthemall.org/
Medialab Tools. Table2Net Available from https://medialab.github.io/table2net/
Milner, R. M. (2018). The world made meme: Public conversations and participatory media. MIT Press.
Miltner, K. M. (2014). “There’s no place for lulz on LOLCats”: The role of genre, gender, and group identity in the interpretation and enjoyment of an Internet meme. First Monday.
Miltner, K. M. (2018). Internet memes. The SAGE handbook of social media, 55, 412-428.
Niederer, S. (2019). Networked Content Analysis: The case of climate change. (1 ed.)
(Theory on Demand; No. 32). Hogeschool van Amsterdam, Lectoraat Netwerkcultuur.
Niederer, S., & Van Dijck, J. (2010). Wisdom of the crowd or technicity of content? Wikipedia as a sociotechnical system. New media & society, 12(8), 1368-1387.
Nissenbaum, A., & Shifman, L. (2017). Internet memes as contested cultural capital: The case of 4chan’s/b/board. New Media & Society, 19(4), 483-501.
Omena, J. J. (2021). Digital Methods and Technicity-of-the-Mediums. From Regimes of Functioning to Digital Research [Universidade Nova de Lisboa]. Available from https://run.unl.pt/handle/10362/127961
Omena, J. J., Elena, P., Gobbo, B., & Jason, C. (2021). The Potentials of Google Vision API-based Networks to Study Natively Digital Images. Diseña, (19), 1-1.
Omena, J. J., & Amaral, I. (2019). Sistemas de leitura de redes digitais multiplatform. In J. J. Omena (Ed.) Métodos Digitais: Teoria-Prática-Crítica. Lisboa: ICNOVA. ISBN: 978‐972‐9347‐34‐4
Rogers, R. (2019). Doing digital methods. Sage.
Rogers, R. (2021). Visual media analysis for Instagram and other online platforms. London. SAGE Publications Ltd.
Rogers, R., and Giorgi, G. (under review). ‘What is a meme, technically speaking?’.
Shifman, L. (2014). Memes in digital culture. MIT press.
Tuters, M. (2019). LARPing & liberal tears: Irony, belief and idiocy in the deep vernacular web. Available from https://mediarep.org/bitstream/handle/doc/13282/Post_Digital_Cultures_37-48_Tuters_LARPing_Liberal_Tears.pdf?sequence=1
Venturini, T., Jacomy, M., & Jensen, P. (2019). What do we see when we look at networks. arXiv preprint arXiv:1905.02202.
Pearce, W., Özkula, S. M., Greene, A. K., Teeling, L., Bansard, J. S., Omena, J. J., & Rabello, E. T. (2020). Visual cross-platform analysis: Digital methods to research social media images. Information, Communication & Society, 23(2), 161-180.
Spitzberg, B. H. (2014). Toward a model of meme diffusion (M3D). Communication Theory, 24(3), 311-339.
Wiggins, B. E., & Bowers, G. B. (2015). Memes as genre: A structurational analysis of the memescape. New media & society, 17(11), 1886-1906.
Zannettou, S., Caulfield, T., Blackburn, J., De Cristofaro, E., Sirivianos, M., Stringhini, G., & Suarez-Tangil, G. (2018, October). On the origins of memes by means of fringe web communities. In Proceedings of the Internet Measurement Conference 2018 (pp. 188-202).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback