Z Spaces: TikTok Tactics and Cross-Platform Circulation of Russian Propaganda
Team Members
Facilitators: Elena Pilipets & Marloes GeboersTool-contributions by: Jason Chao & Stijn Peeters
Designer: Emanuele Ghebaur Bas le Cointre; Floris Spaans; Haixing Zhang; Ida Muhonen; Lingxi Kong; Lucia Bainotti; Mara Werner;
Maria Ion; Maria Sole Brigati; Max van Veen; Sara Messelaar Hammerschmidt; Senjie Zhang; Sofia Caldeira;
Stijn Peeters; Tessel Bruns; Wessel Kraaijeveld
Contents
Summary of Key Findings
Our most significant findings derive from two methodological techniques:
-
TikTok methodologies, enable the analysis of social video content and its platform-specific vernacular characteristics (with particular attention to original and distributed sounds, co-hashtags, stickers, and AI techniques of speech recognition and video analysis).
-
Cross-platform methodologies, enabling a multi-partite analysis of Z propaganda templates and their hybrid vernacular characteristics (with particular attention to augmented AI (Google Vision API web detection) and platform metadata (co-hashtags).
Using TikTok methodologies, we were able to
-
identify disguised “speech templates” in the “original sound” of Z propaganda by using speech recognition AI
-
compare co-hashtag ecologies of pro-Russian and pro-Ukrainian sounds over time
-
identify Z propaganda templates based on frequently used word pairs in video stickers
-
explore visual templates of Z propaganda through montage techniques focusing on the analysis of video frames
Using cross-platform methodologies, we were able to
-
build an augmented dataset of popular Z images/videos from Twitter, Instagram, and TikTok by merging platform metadata with AI annotations afforded by Google Vision API web detection
-
perform a multi-partite network analysis in order to explore hybrid vernacular characteristics of Z propaganda through
-
associations of visual content shared web entities and co-hashtags
-
associations of visual content shared web entities, and sites with matching images
-
-
identify dominant patterns and unique characteristics of popular cross-platform Z vernaculars by switching between different perspectives on the same dataset
-
identify drastic variations in the intensity of engagement with Z from platform to platform
-
pay attention to both the dynamism and flexibility (hijacking) of Z as well as its characteristic symbolism (templatability) predominantly targeting Russian-speaking audiences.
1. Introduction
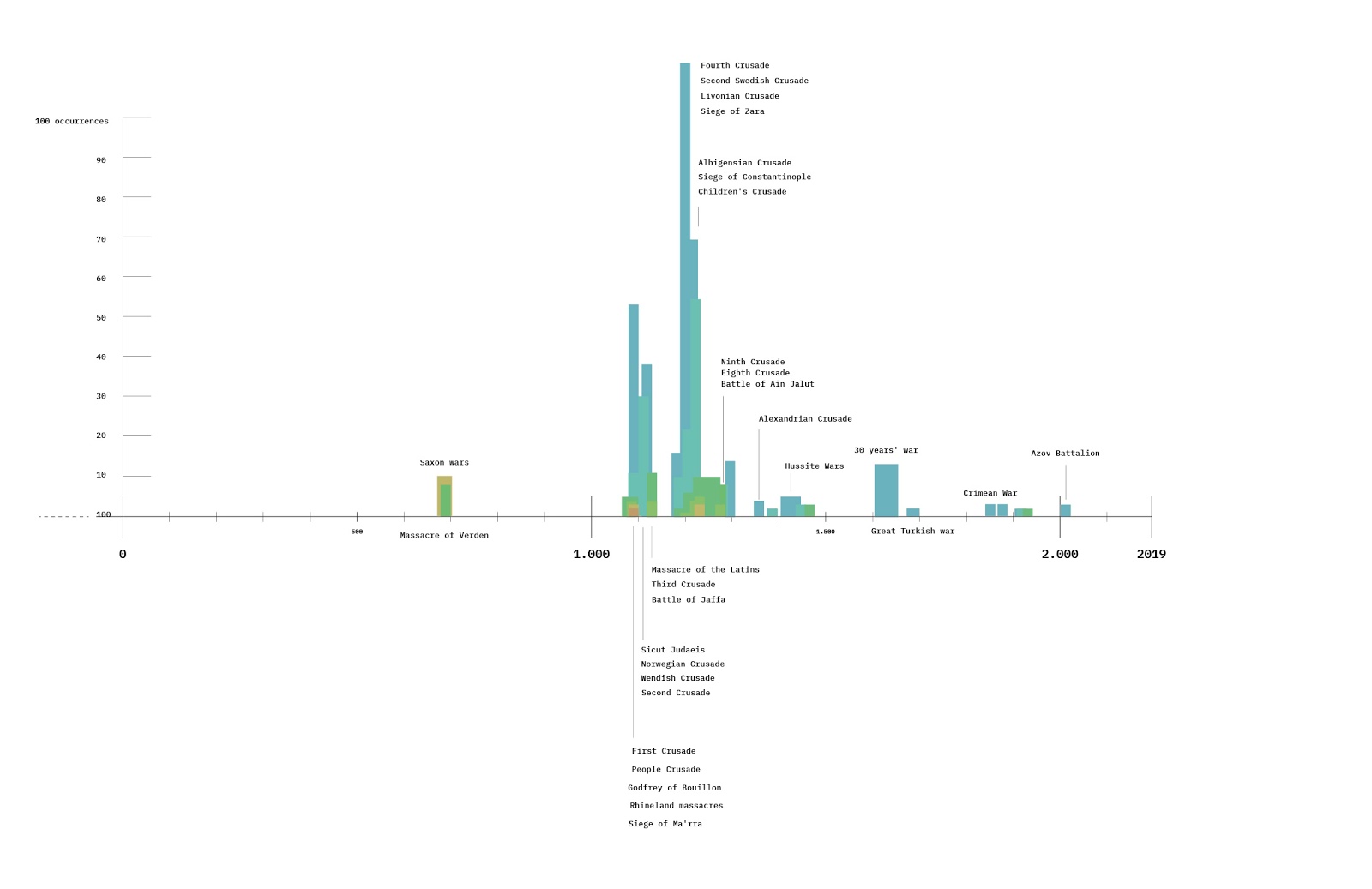
Somewhat opaque in its origins and (intended) meanings, Z (and V) symbolism have been visual 'vehicles' of symbolic power ever since Russia's invasion of Ukraine. Introduced to the world as the markings on the board of Russian military equipment, both symbols quickly became popularized as war propaganda: first in the usual spelling, for example, "за мир” or “for peace" and then with the replacement of the Cyrillic “з” in hashtags with the Latin “z”—#zамир.
This project explores the unfolding of such “Z spaces” within the digitally amplified feedback loops of “partisan polarization” described by Boler and Davis (2018, 2021) as “propaganda by other means”. Some of these spaces are attuned to the patriotic sentiment of World War II, others amplify typical populist “us vs. them” rhetoric (Klain 2022), while many others take up a more youthful attitude to spread ‘gen Z’ content—often with the aid of memes. By critically exploring how the letter “z” has been re-enacted, hijacked, and distributed, we analyze a heterogeneous set of memetic tactics on and across three different platforms (TikTok, Instagram, and Twitter). The ultra-nationalist landscape of Russian “WarTok” (Lowery 2022) and the evanescent character of secondary orality (Venturini 2022; Ong, 1982) that these tactics build upon will be at the center of our investigation.
Attending to the temporal rhythms and performative styles of “Z” symbolism, we address its populist appeal as shaped by the contested narratives of the war and the material affordances of platforms. Visually tethered to the history of World War II through, for example, the ribbons of Saint George, “Z” has been invoked by Putin’s government as a symbol of alleged “denazification”. Aiming to justify Russia’s invasion of Ukraine, it abounds on various platforms but takes on a new level of affectivity and networkedness in the context of TikTok ’s short video format.
Secondary orality, a notion recently revived by Venturini (2022; Ong, 1982), is one way to address this format that is pertinent to understanding the specificity of contributions on a platform where written words often become spoken words and where evanescence is even more ingrained into the logic of engagement. Staying close to TikTok ’s secret sauce we strive to follow a proposed shift from spatial (what and where) to temporal dynamics of when and how specific platform features (effects, duets, stickers, and challenges) matter (see Venturini, 2022; also Bucher 2018). To account for this shift, we foreground the memetic function of sounds as that affording storytelling and identity performance in a complex ecology of imitation, affective expression, trend hijacking, and bonding.
From early explorations of the Z scape on TikTok, we find persisting narratives and myths that tie into the post-trauma of World War II or what is known as the Great Patriotic War in Russia. Gaufman (2017) has extensively studied Russian collective memory and noticed a shift in commemorative rituals and narratives that started with the collapse of the Soviet Union and that accelerated after (among other events) the Euromaidan protests and the annexation of Crimea. Gaufman points to the sheer scale of deliberate planning and investment devoted to commemorative parades, ceremonies, statues, museums, televised programs, and other proceedings as “keeping the War's (epigenetic) memory, glory and trauma alive, despite its events being a post-memory for the majority of the population. Traces of this trauma emerged in spectacular fashion during the Ukraine crisis, as the Russian government and official media deliberately drew discursive parallels between the suffering of Russian speakers in Eastern Ukraine and the ordeal of the Soviet population during World War II.”
Rüsen (2004) points to social networks as providing alternative examples of commemoration: “While in many countries the most common slogan associated with World War II is ‘Never Again’ (Bode and Seo, 2017), Russian uber-patriotic segments of social networks came up with a meme: ‘mozhem povtorit’ (we can repeat), that also became a car sticker, and which features variations of a male figure with the head of a hammer and sickle sodomizing another male figure with a head of a swastika.” There seem to be aspects of epigenetics or inherited collective memory sustained through what is known in neurobiology as the ‘pathos formula’ helping our brains to “reference received pictures and/or discursive constructions through particular similar verbal or non-verbal representations" (Eichenbaum and Cohen, 1993).
Z symbolism is visually tethered to the Russian remembrance of World War 2 through, for example, the ribbons of Saint George, which fits the narrative of a Russian fight against Neo-Nazism going on in Ukraine. This symbolism abounds on various platforms but takes on a new level of affectivity in the context of TikTok ’s short video format due to its added layers of sound and movement. As mentioned earlier, it is also ‘absorbed’ into some hashtags where it replaces the Cyrillic version of Z. These hashtags return in our project as part of our so-called seed query.
We will follow a methodological protocol that partly reflects the methodology of the previous summer school. We will extend these by "TikTok methodologies" by which we refer to quali-quantitative video analyses that focus on gestures and embodied performances and that combine AI-generated annotation outputs (object detection, best guess labels, web entities, and domain recognition) with platform data on reach (diggs) and contextualization through e.g., stickers, effects, sounds, and (emoji) hashtags.
2. Research Questions
Overarching:
-
How are platform materialities and temporalities of TikTok modulating Russian state propaganda?
-
How are Z narratives circulating across social platforms?
-
How are hashtags used in tactical ways to target particular audiences and what regimes of visibility do these tacticalities construct?
Sub questions:
-
How are hashtags attuned to sounds in both the Russian and Ukrainian spaces?
-
With what sentiment are particular visual patterns associated?
-
With what sentiment are particular songs or sounds associated?
3. Methodology and initial datasets
Cross-platform dataset
For our analysis of the cross-platform circulation of Z propaganda on TikTok, Instagram, and Twitter we used a curated dataset based on a contextually relevant seed list of hashtags:
-
#zаправду (for truth)
-
#zапутина (for Putin)
-
#zапобеду (for victory)
-
#zароссию (for Russia)
-
#zамир (for peace).
TikTok dataset
· 819 video posts scraped with Zeeschuimer via five selected z hashtags #zаправду (for truth), #zапутина (for Putin), #zапобеду (for victory), #zароссию (for Russia), #zамир (for peace). The duplicates were removed in a merged spreadsheet. This dataset was used for a video analysis of speech templates.
· Posts scraped via 2 sounds “Good evening, Ukraine” (n=954) & “Good morning, Russia” (n=497). This dataset was used for a temporal analysis of associated co-hashtags and contextual analysis of video stickers.
· Video frames and audiotracks were extracted with Video Frame and Audio Extractor and analyzed with a Speech-toText converter (see methodology section).
Methodological Protocols
TikTok methodologies refer to quali-quantitative video analyses that focus on music, gestures, and embodied performances by combining AI-generated annotation outputs (e.g., Google Cloud Vision API speech recognition and web detection) with platform data on reach (e.g., likes) and contextualization through e.g., hashtags (see DMI tutorials by Chao & Pilipets 2023; Peeters & Bainotti 2023; Pilipets 2022 and project reports by Bainotti et al. 2022; Geboers et al. 2022).
These hybrid methods address the specificity of TikTok videos as engaging content and dynamic media objects, accounting for different memetic aspects of a TikTok dataset (temporality, imitation, amplification) through question-driven techniques of analytical display.
In the first step, this approach requires demarcating data following the material affordances of the platform in accordance with e.g.,
-
Hashtags (emoji hashtags)
-
Sounds (both original sounds and distributed music)
-
Effects (video effects)
-
Challenges
-
Duets
-
Stickers
Relevant video material then can be sampled by combinations of different data points accessible through Zeeschuimer/4CAT (Peeters 2021) .csv output: Relations of popular sounds, effects, and hashtags can serve as memetic linkages to video content that can be further structured by the time of publication or engagement metrics. Providing a valuable entry point into the study of contextual specifics of video creation, in the next step, these methods can be augmented with AI-driven video and audio analysis and enriched through qualitative coding.
The specificity of TikToks is central to our methodological framework. Video length on TikTok can range from approximately 3 seconds to 3 minutes with a frame rate of 30 frames per second, which means that 1 second of video generates 30 images. Finding the right sampling technique for frame extraction and detection of visual elements is therefore key to the process of analysis.
We used Ffmpeg-based Video Frame and Audio Extractor (Chao 2023)— a tool that offers different sampling techniques for extracting frames (stills) from a folder of input video files (recommended frame extraction technique for TikTok videos is one frame per second). It saves extracted images in a new folder, which then can be analyzed with different computer vision techniques using Memespector GUI (Chao 2021). The tool also extracts audio tracks for speech recognition using Google Cloud AI-based Speech-To-Text Converter (Chao 2023), which (at least) partially allows to work around the problem of TikTok ’s “original sound”.
TikTok videos are variously networked, searchable, and templatable. The main ‘networker’ is the sound, not the hashtag. TikTok creators often upload their videos with “original sound” instead of using TikTok ’s built-in music library. If the video is linked with a song taken from the TikTok library, the song and author's name are listed. However, as soon as content involves audio editing, the sound will be listed as “original sound” and provided with a unique numeric ID. Original sounds range from adaptations of popular music to speech to remixed fragments of sounds available in the library. Resulting audio artifacts therefore may contain traces of ’disguised’ sound templates which require new methods of audio and speech pattern recognition. While Speech-To-Text Converter allows to recognize musical elements of speech (e.g., HipHop songs) and converts them to text, further experimentation with audio fingerprinting techniques is needed for the recognition of patterns in audio without lyrics.
In this project, we tested several research techniques aiming not only at the recognition of audiovisual similarity patterns in Russian war propaganda, but also at further contextualization of these patterns through TikTok metadata (time of publication, hashtags, and stickers) and Google Vision API web detection of sites containing visually similar images. Merging the outputs of AI-driven video frame and audio analysis with TikTok metadata in Google Spreadsheets requires applying a series of formulas that are documented in this test spreadsheet and walkthrough document. We then explored this augmented data through two different question-driven analytical techniques: video analysis focusing on the shared soundscapes of Z propaganda (1) and cross-platform analysis of Z vernaculars (2).
4.1 Video analysis with TikTok metadata: Z soundscapes and hashtag hijacking

This methodological protocol has two different starting points: hashtags and sounds.
Hashtags protocol:
-
Posts scraped via five selected z hashtags (n=819, the duplicates were removed)
-
Narrowing down to a smaller set of videos with a shared audio pattern with a Speech-to-Text converter
-
Plotting of video frames using ImageJ /Image Montage
-
Interpreting associated semantic spaces through shared co-hashtags and manual qualitative coding using ao comments
-
Posts scraped via 2 sounds “Good evening, Ukraine” (n=954) & “Good morning, Russia” (n=497)
-
A rank flow of associated co-hashtags over time for each of the two songs.
-
Analysis of video stickers and qualitative exploration of hijacking tactics
-
Plotting of videos with the same sticker templates with ImageJ /Image Montage
4.2 Cross-platform co-hashtag analysis of Z vernaculars with Google Vision web detection

This methodological protocol is designed to analyze hybrid vernacular characteristics of visual content across platforms based on a multi-partite analysis of
-
associations of visual content shared web entities and co-hashtags
-
associations of visual content shared web entities, and sites with matching images
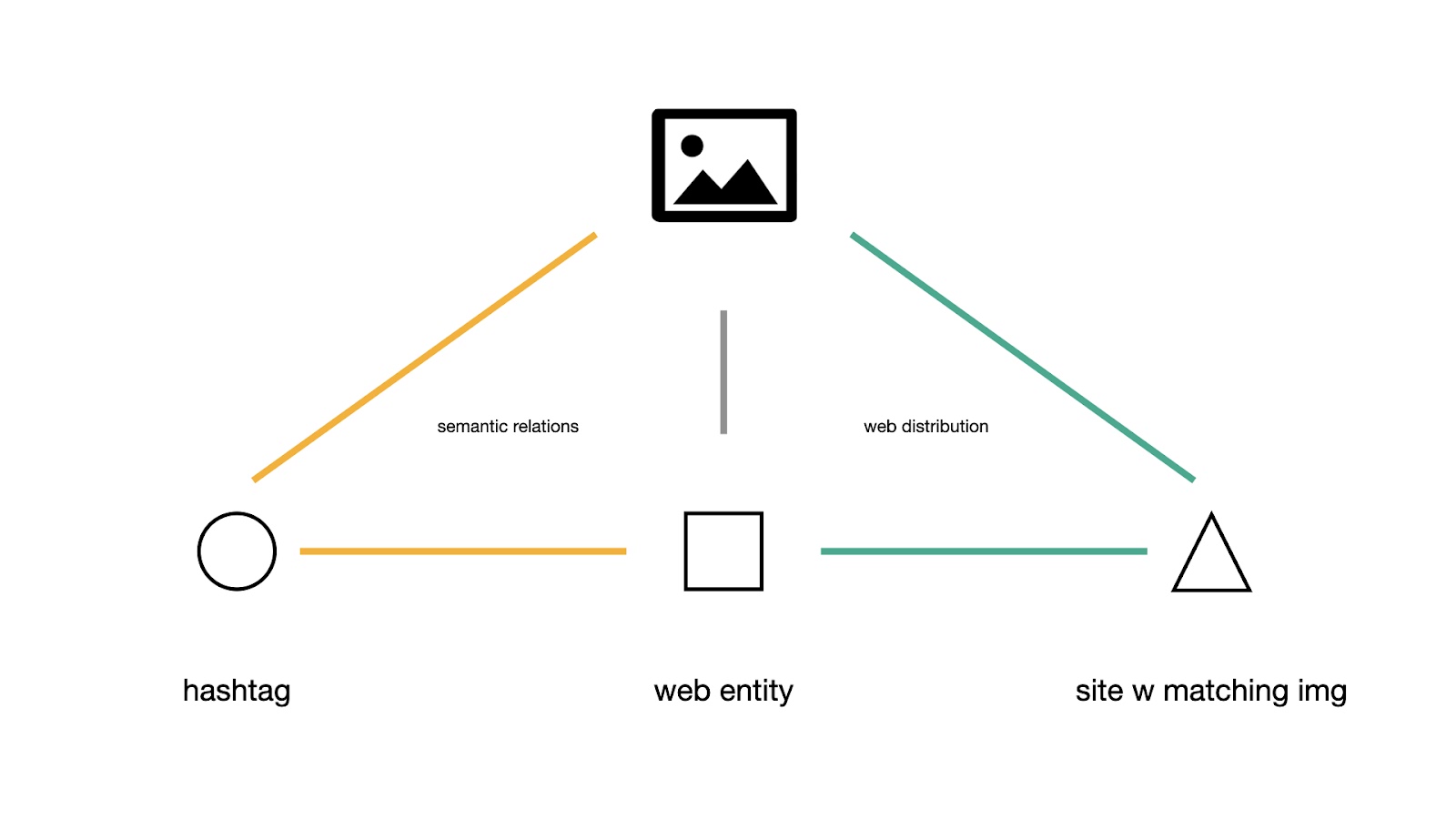
Figure 1: Two types of connection in the multipartite network analysis of Z vernaculars See high-res image.
_Here, we further develop already established techniques for visual media analysis with the aid of web detection (see e.g., Hagen 2017; Omena et al. 2021; Pilipets et al. 2021; Rogers et al. 2021; Pearce et al. 2022; Burkhardt & Rogers 2022) and discuss the value of contextualizing AI-generated image annotations through co-hashtag analysis (Geboers & Van de Wiele 2020; Tucci 2022)._
-
Posts scraped via five selected z hashtags from Twitter, Instagram, and TikTok (50 unique most liked images/videos per platform; n=150) were analyzed in a series of following steps:
-
Annotate each of the images/videos using Google Vision API detection of web entities and pages with fully matching images (TikToks were analyzed by extracting one frame per second).
-
Merge the outputs of Google Vision API web detection with platform metadata in one master spreadsheet. Google Spreadsheets formulas for merging the data are summarized in this walkthrough document
-
Import the downloaded .csv file to Table2Net to create six separate bi-partite Gephi-readable network files (.gdf) with the following node types: 1. entity-image 2. entity-hashtag 3. entity-domain 4. entity-source platform 5. domain-image 6. hashtag-image. Edges will be defined according to these relations. For each file, we used “source platform” as an attribute to be able to color the nodes by their association with Tumblr, Twitter or TikTok. For image nodes, we used “likes” as an additional attribute in order to define the size of the images based on the intensity of engagement within each of the source platforms.
-
Merge all 6 .gdf files in by importing files one by one via File -> Open -> Append to an existing workspace
-
Spatialize the network with Force Atlas 2 while settling the position of three main nodes representing the source platforms
-
Change the size of the image nodes by adding a new column with numeric values “likes_new” with the type “float” and copy data from the column “likes_count” to this new column. This will result in the values appearing as an attribute of the node size in Overview->Node Size->Ranking. The size of all other nodes can be defined by degree.
-
Color the nodes by the attribute “platform”. This will result in specific colors for three types of connection: nodes associated exclusively with one platform, nodes associated with two platforms (Twitter-Instagram, Twitter-Tiktok, Instagram-TikTok), and nodes associated with all three platforms.
-
To explore these different types of connection use Filter->Attributes->Partition-> Platform, which results in different perspectives on the same dataset
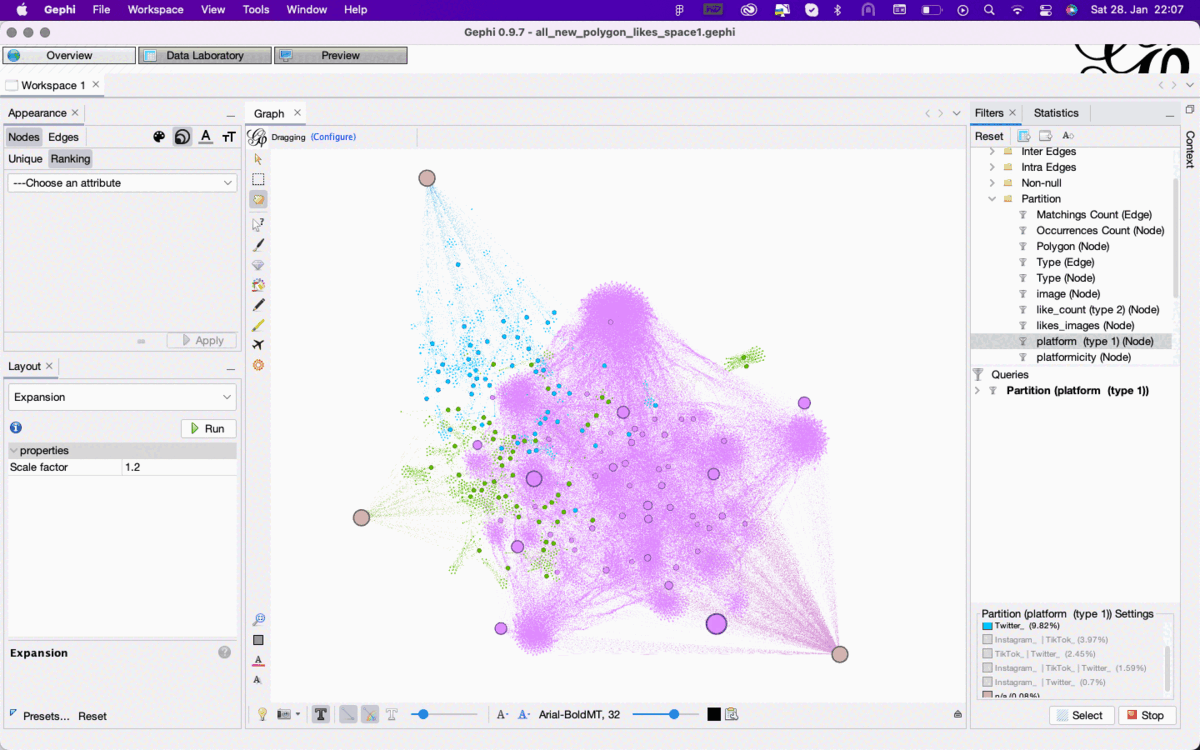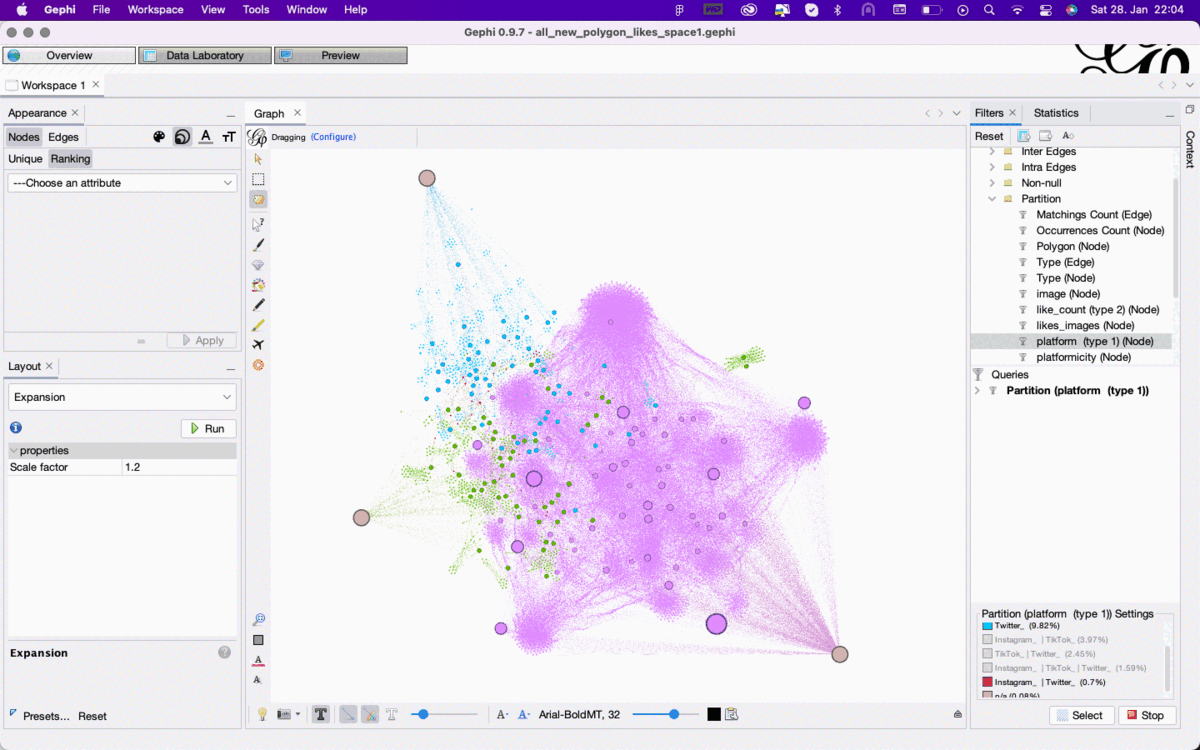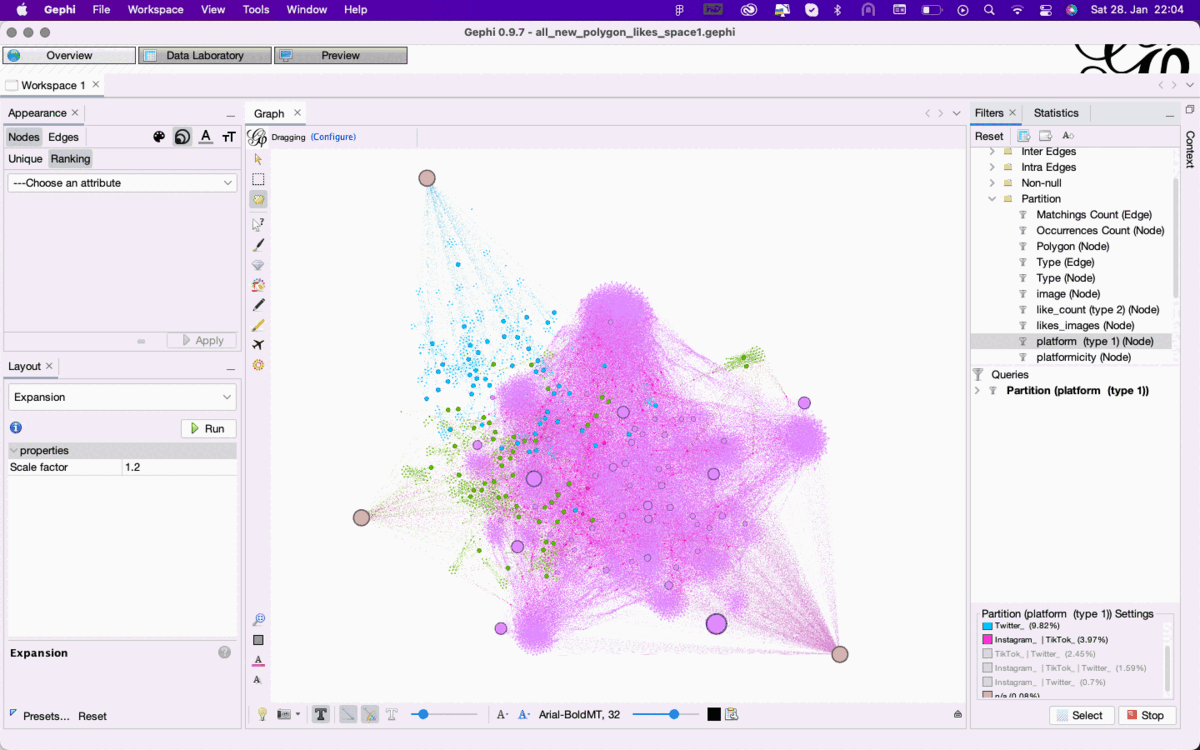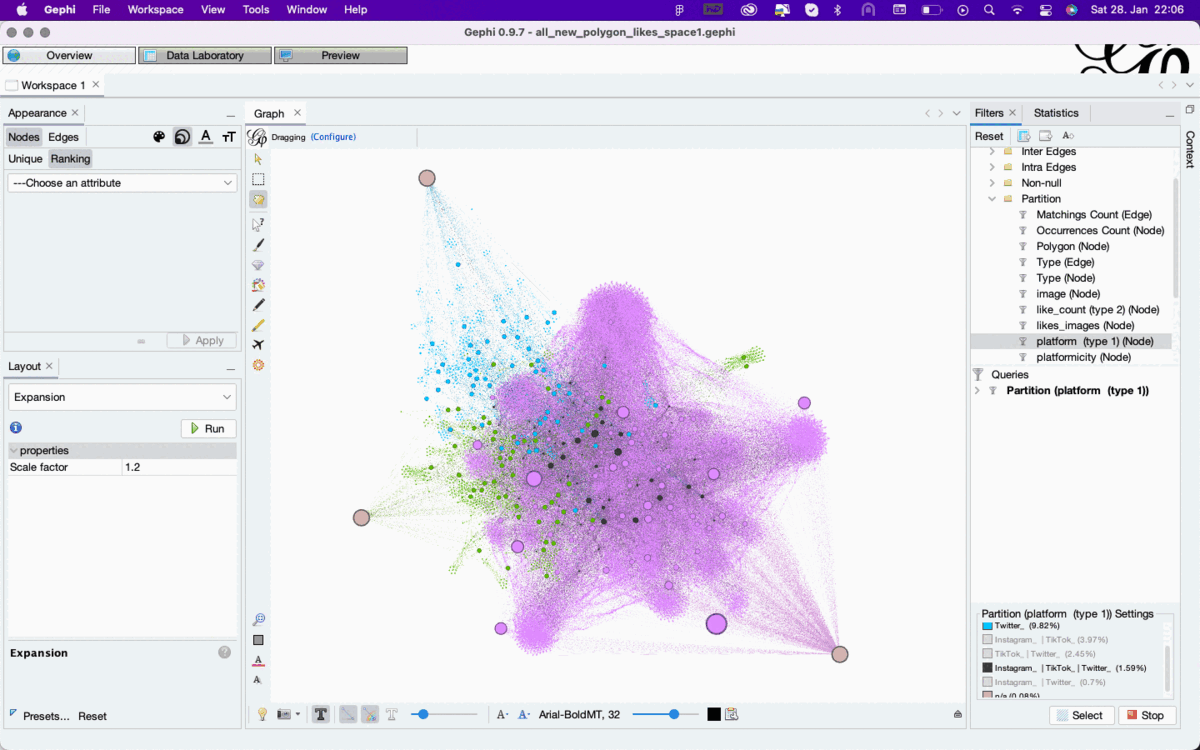
Figure 2: Enabling different filter perspectives on the same dataset in Gephi overview based on the color attribute of nodes that are either unique for or shared between Twitter, Instagram, and TikTok. See high-res image.
-
To demarcate different types of nodes install two Gephi Plugins: “Polygon Shaped Nodes” and “Image Preview”. To provide nodes with distinct shapes open Data Laboratory and add a new column “Polygon” with the type “Integer” and a new column “image” with the type “string”. Adjust the shape of web entity and domain nodes by entering the desired number of sides the node should have in the preview in the column “Polygon”: “4” results in the shape of a square, and “3” results in the shape of a triangle. Hashtag nodes will keep the default shape of a circle.
-
To visualize the shapes in Preview, make sure “Polygon shaped nodes” is selected in the “Manager renderers” tab. In the “Settings” tab, select “enable polygon shaped nodes”. When the preview is refreshed the nodes will be displayed as polygons with sides corresponding to the number in the "Polygon" column
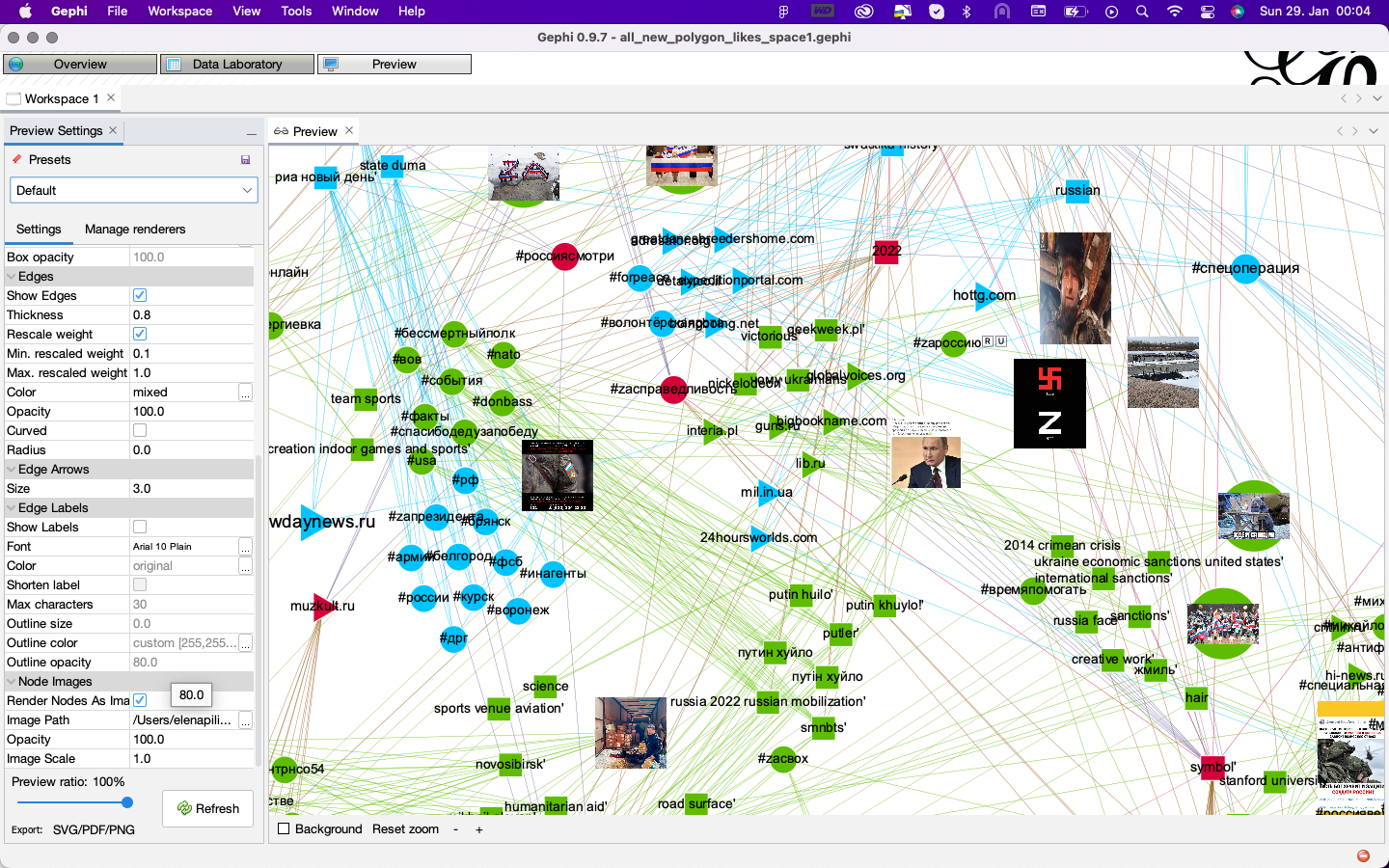
Figure 3: Adding shapes to the nodes in Gephi preview. In this filtered network fragment, visible are only unique and shared characteristics of Z vernaculars from Instagram and Twitter. Shared hashtags (#zасправедливость/#forjustice and #россиясмотри/#watchrussia), web entities (“2022” and “symbol”), and sites with matching images (muzkult.ru) are highlighted in red. Unique Twitter-related nodes are blue. Unique Instagram-related nodes are green. See high-res image.
-
Export the network as .png. In the tab option set the width and height, and export with transparent background (note that modifications in the node shape cannot be exported as .pdf format). Explore the results through manual annotation. Note that the value of this analytical technique derives from its capacity to shift between different perspectives on the same set of images. Different filter views correspond with different research questions.
In order to arrive at videos that tap into similar sounds, we needed to use the JSON file outputted by Zeeschuimer (as opposed to directly moving to the dataset in 4CAT) as it holds potentially relevant columns, especially the author name-related columns are pertinent when wanting to assess the communities that share particular sounds or speech patterns. As mentioned many users upload videos with original sound instead of using the TikTok music library obliterating the actual sounds that are used. However, through detecting bigrams in the converted audio-to-text results patterns can emerge and one can (through spreadsheet filtering) curate the dataset in such a way that videos are organized by their shared sounds. One of the implications of working with the JSON file is that it is huge and cannot be opened easily. In OpenRefine, the files (converted to csv) could be opened and we used the in-built tabular exporter to only export the needed 28 columns to a workable csv file. We deduplicated videos and used the 4CAT video downloader (that has a cap of a 1000 videos). BE SURE TO DOWNLOAD VIDEOS FAST AS URLS EXPIRE WITHIN SOME HOURS For the hashtag protocol, both the frame and audio extraction tools were used. The following steps were then taken: -Create a new column in the spreadsheet file and name it e.g., image_num_time
-Select all images from the folder, copy the file names, and paste into the spreadsheet
Pro tip: Watch this YouTube tutorial if you use Windows (on Mac, it is just copying & pasting)
-The result is a column with the image filenames
-Upload the folder of video files on Google Drive
- Activate Video Frame and Audio Extractor (Chao 2022)
-Use the newly created folder with audio tracks as input for Speech-To-Text converter (Chao 2022)
-To run Speech-To-Text Converter follow the instructions on creating the API key and activating Google Speech-To-Text API.
For more details on both tools, see also the awesome tutorial of Jason Chao and Elena Pilipets.
For the songbased protocol, we only used the frame extractor tool. In order to keep a workable dataset after frame extraction (one frame per second) we needed to narrow down the dataset. For our analysis of sticker texts, we sampled the videos based on the most frequently used bigrams in the sticker text giving us two instances of bigrams: Forbidden to Upload (N=10) and Not Ashamed (N=8). Due to a lack of time, we did not get into mapping further the semantic spaces within which these two sticker patterns emerged but their attunements to hashtags and particular visual templates constitute an interesting venue of research to further explore.
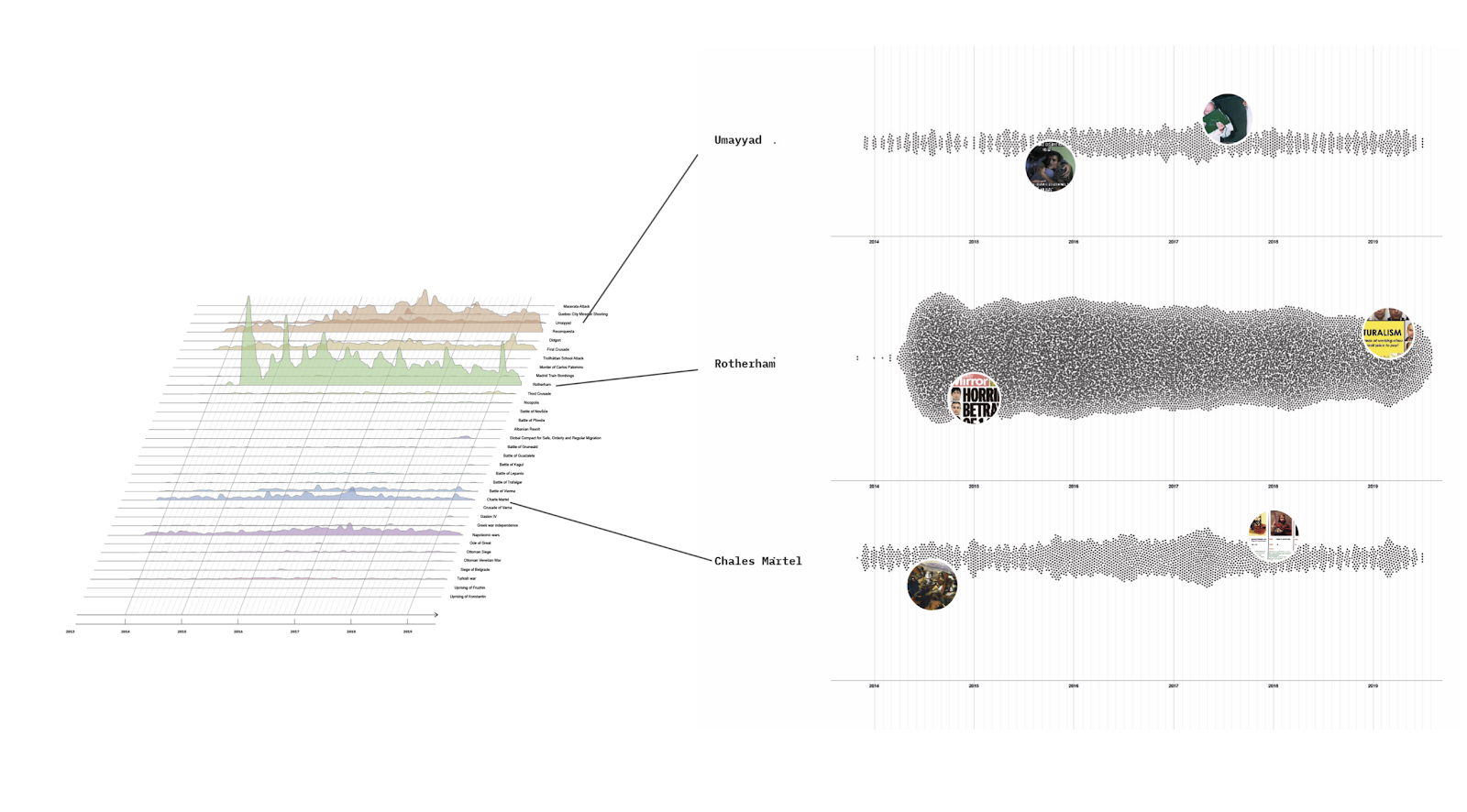
5. Findings
Network analysis
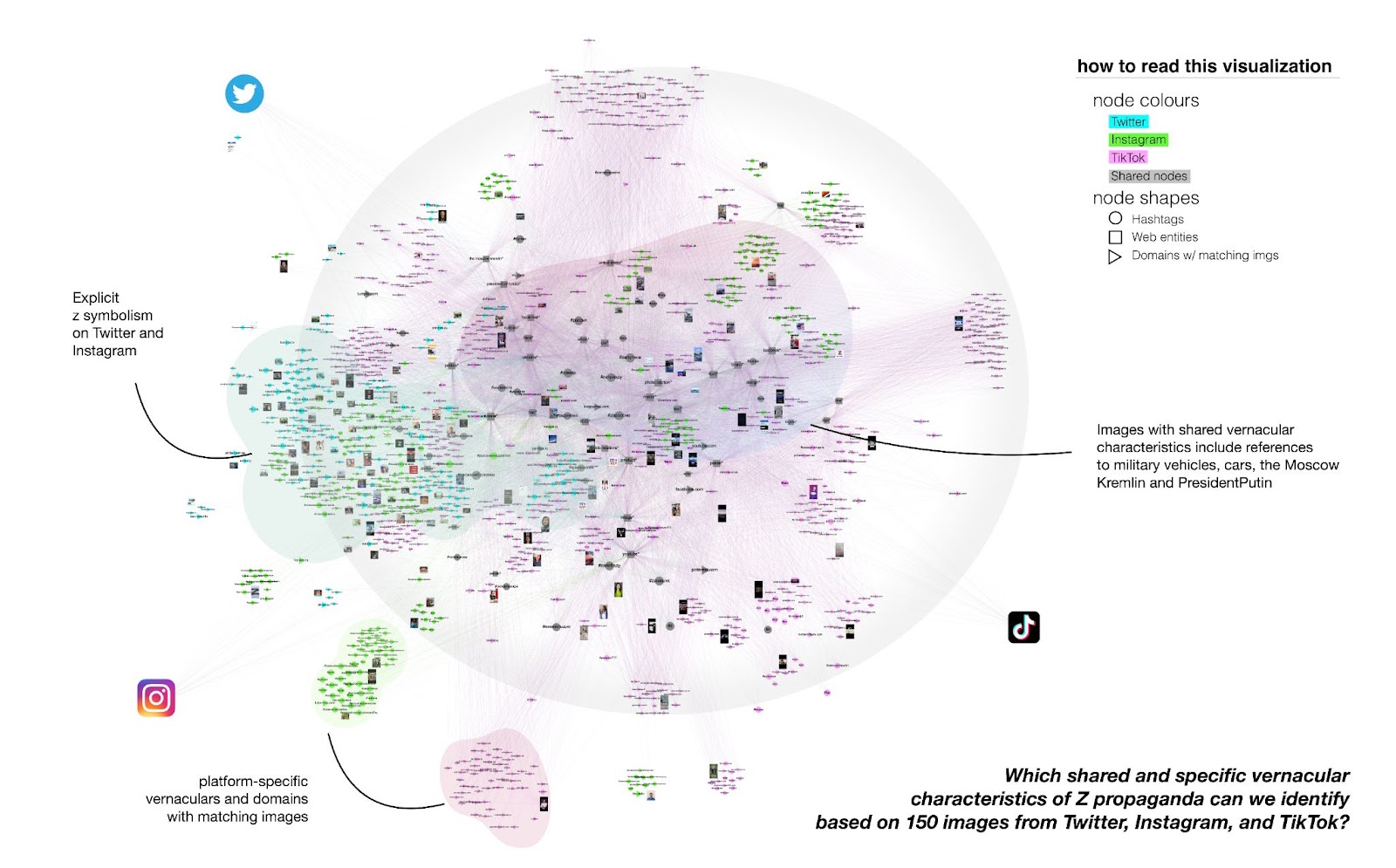
Figure 4: A filter view on the shared and specific vernacular characteristics of Z (based on co-hashtags, web entities, and domains). Visible are only characteristics that are either platform-specific or shared between all three platforms. Characteristics shared between only two of the three platforms were not included in this filter. See high-res image.
The network shows 150 most liked z images/videos from Twitter, Instagram, and TikTok (50 unique posts per platform). Focusing on the shared web entities, domains, and co-hashtags, we found several variations in the distribution of Z vernaculars across platforms. The following research questions were driving our interpretation:
-
Which shared and specific vernacular characteristics of Z propaganda can we identify based on 150 images from Twitter, Instagram, and TikTok?
-
Which associations between popular Z templates can we identify based on the relations of web entities and co-hashtags?
-
Which domains match more platform-specific and which more distributed content?
We found that TikTok content is distributed across different propaganda scenarios and shares multiple memetic references with content from both Twitter and Instagram. Many TikTok videos make use of collage techniques, stitching together still images of Z propaganda that are not TikTok -native—a finding that derives from a variety of TikTok -associated unique domains with matching content.
The main examples are repurposed images of celebrities and politicians supporting Putin’s government; images depicting the Moscow Kremlin and Putin himself; as well as images of military vehicles and cars with z stickers. Emphasizing the compositional nature of Z on TikTok, these generic images clearly indicate ‘post-based virality ambitions’ (Abidin 2021) through use of well-recognizable z templates predominantly targeted at Russian-speaking audiences (see a network fragment below focusing on the distribution of images used in a TikTok video montage of Russian celebrities supporting Putin). Alternatively, TikTok -native videos show female Russian TikTokers filming themselves (often accompanied by Russian flags).
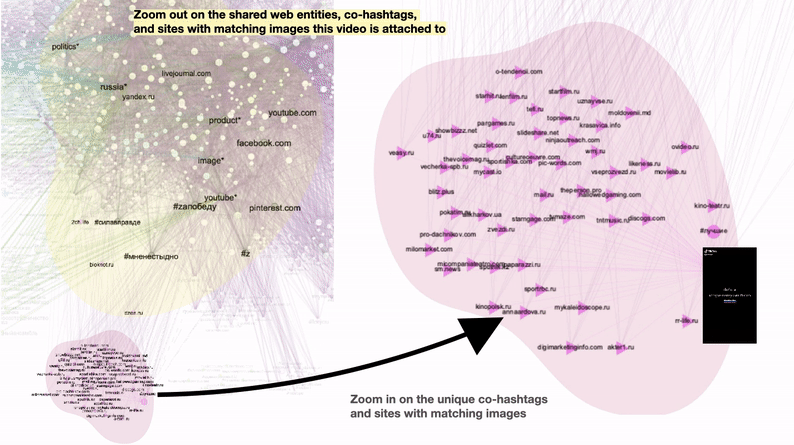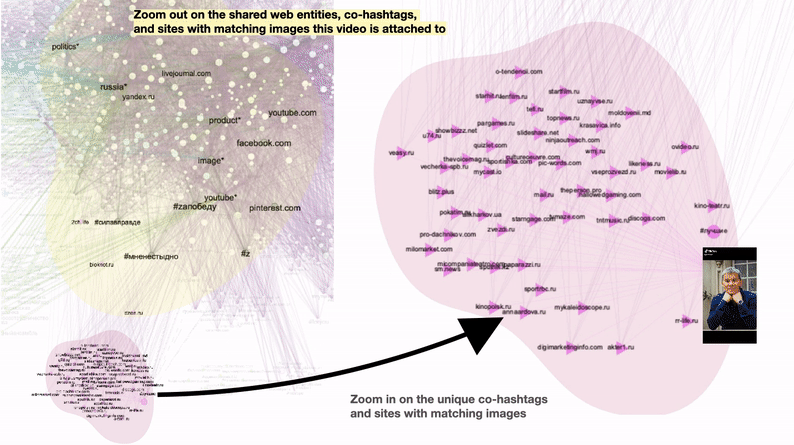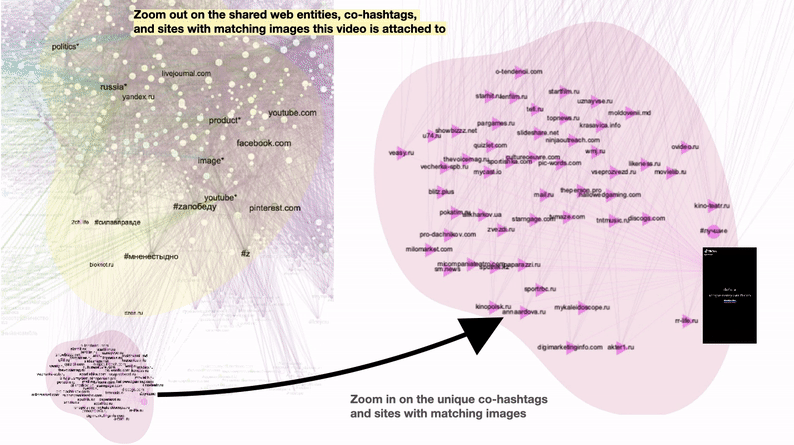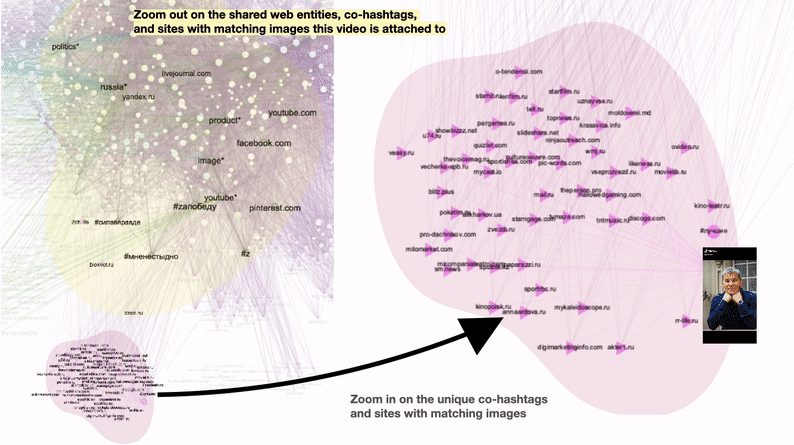
Figure 5: A popular TikTok video “Stars supporting Russia” and its unique and shared vernacular characteristics. Unique characteristics include #лучшие (#thebest) and a variety of online magazines such as zvezdy.ru ( stars.ru) containing celebrities’ photos. Unique web entities with the celebrities’ names are not visible in this preview. Shared characteristics include web entities “politics”, “Russia” “image”, and “product”; mainstream platforms with matching images Facebook, Pinterest, YouTube and LiveJournal; and co-hashtags #силавправде (#thestrenghisintruth) #мненестыдно (#imnotashamed) #zапобеду (#forvictory). See high-res image.
Based on the count of likes encoded in the size of images, we also found drastic variations in the intensity of platform engagement with Z: The most liked Twitter and Instagram posts received only 1265 likes and 8100 likes respectively. On TikTok, we not only found that some trend hijacking takes place with the most liked image of football players tagged with #zанаших and #zапобеду (364000 likes), but also that all other z posts tend to receive more likes (TikTok like count range 257400>8563; Instagram 8100>34; Twitter 1265>0).
Sites with that contain content 100% matching Z vernaculars from all three platforms are:
-
Mainstream social media platforms: facebook.com, pinterest.com, youtube.com.
-
Russian-owned social media and search engines: livejournal.com, vk.com, yandex.ru
-
Russian news and meme aggregators: pikabu.ru
-
Emergent fringe social media: tumpic.com (Tumblr imitator)
Twitter and Instagram share specific vernacular characteristics, which particularly focus on the distribution of Russian nationalist z symbolism (multiple variations of Z template, images of Putin and official military gatherings). Twitter content appears on a variety of news sites while Instagram content is more related to social media and entertainment sites.
To explore visible Z content appearing across all three platforms, we selected three shared web entities “car”, “the Moscow Kremlin”, and “President of Russia”. Based on the unique and shared co-hashtag ecologies of these Z templates we were able to explore the dominant regimes of visibility in the context of Z propaganda. The filter view below allows for a relational interpretation of Z based on its semantic associations (co-hashtags) and its key visual themes (as defined by shared web entities).
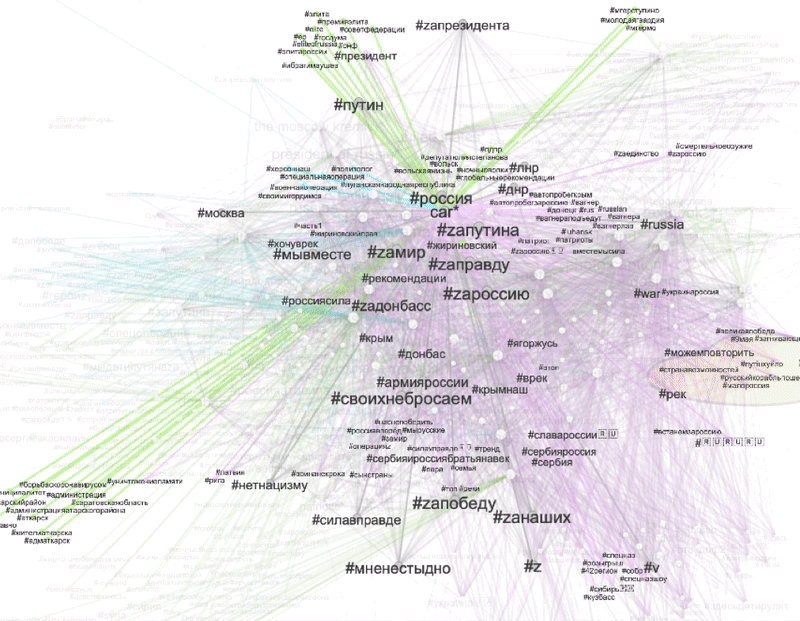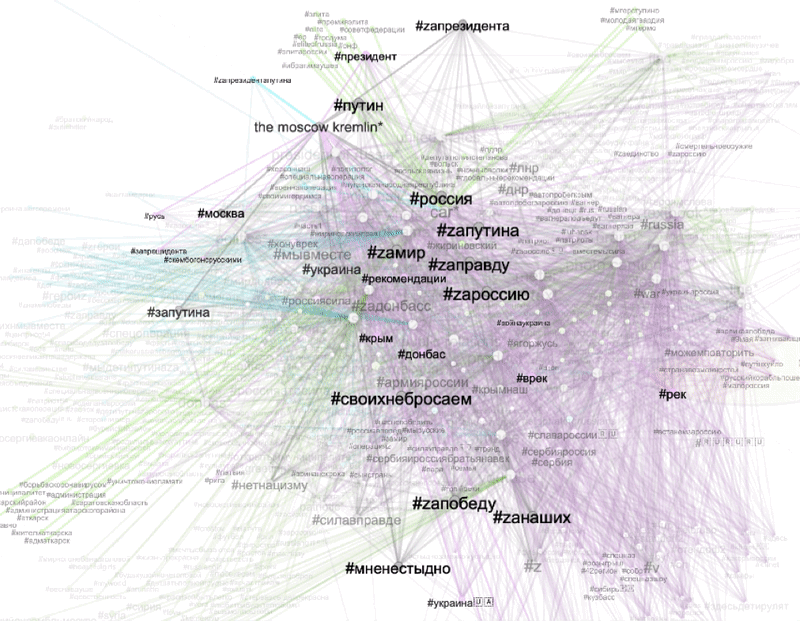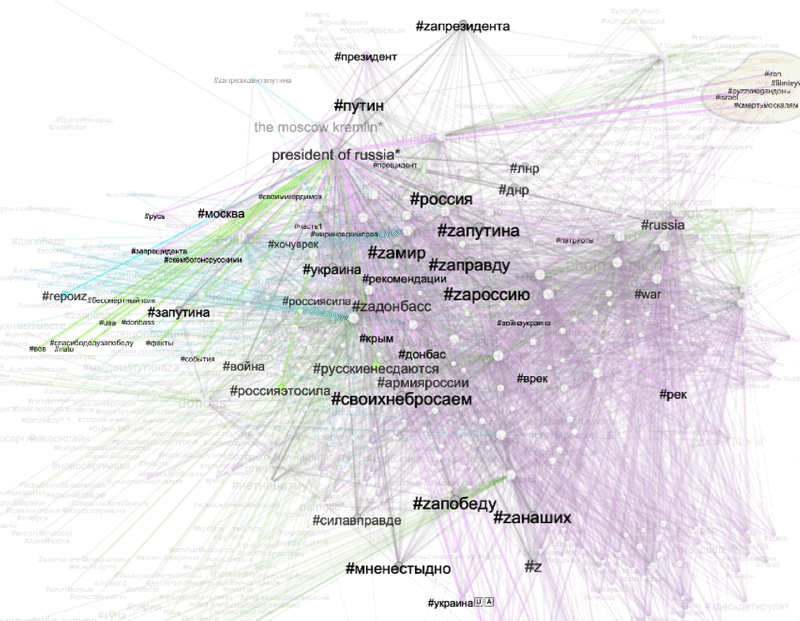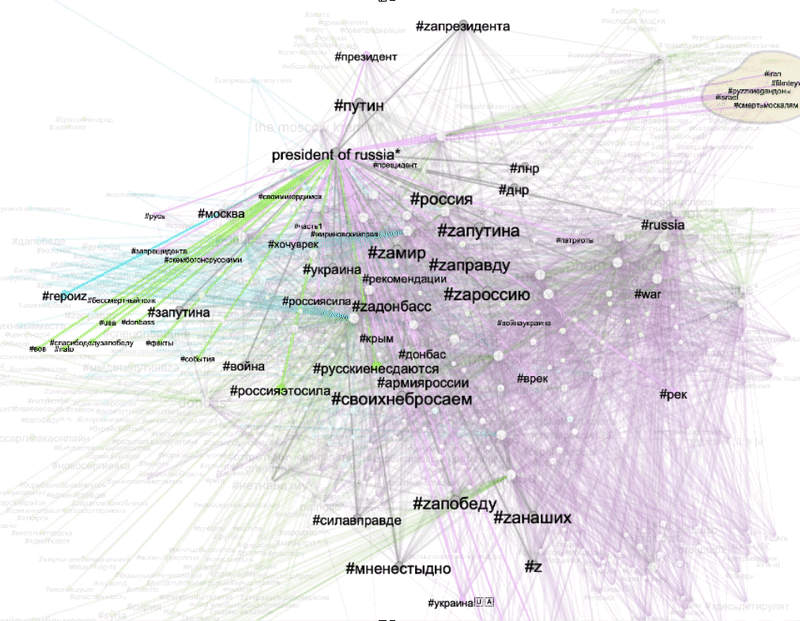
Figure 6: Unique and shared co-hashtag ecologies for videos depicting three popular Z templates: “car”, “the Moscow Kremlin” and “President of Russia” (based on web entities). Grey edges signify co-hashtags that are shared between three platforms. Green edges signify co-hashtags unique for Instagram. Purple edges are unique for TikTok. Blue edges are Twitter-specific. Connections shared between two of the three platforms were excluded from this filter. See high-res image.
We found that:
-
our five main Z hashtags are associated with a variety of adaptations focusing on #za (something “pro” Russian or “for” Russia). e.g., #zапрезидента (#forpresident) and connected to well-recognizable symbols of Russian patriotism in the images of cars with z stickers and images of the Moscow Kremlin. Also, some heroization takes place, connected to Putin’s figure as “our president” and “father of the nation”.
-
frequently used Z co-hashtags associated with all three Z templates are #мненестыдно (#iamnotashamed) #своихнебросаем (#wedontabandonourpeople), and #россия
-
highlighted TikTok -specific co-hashtags come from two pro-Ukrainian posts hijacking typical pro-Russian Z templates: images of “cars” with Z stickers and “President of Russia” with #putinhuilo (#putinisadickhead), #руzzкиеgандоны (slang expression: ”ruzzians are condoms”), #русскийкорабльпошелнахуй (#gofuckyourselfrussianwarship)
-
Twitter-specific co-hashtags associated with images of “president of Russia” are #героиz (#heroez), and #япатриот (#iamapatriot). Instagram-specific co-hashtags are (among others) #россияэтосила (#russiaispowerful) and #русскиенесдаются (#russiansdontgiveup).
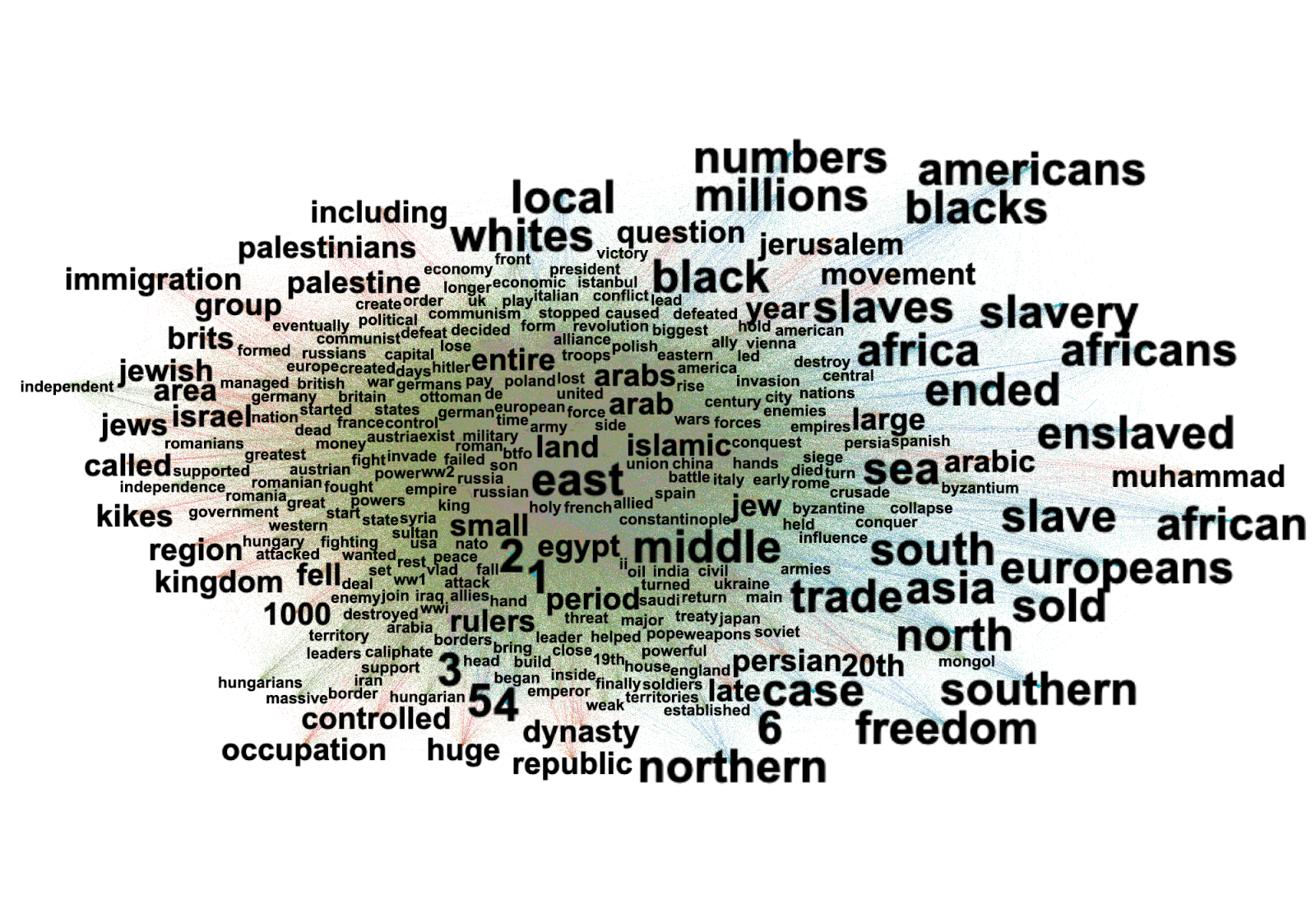
Focused analysis of web domains
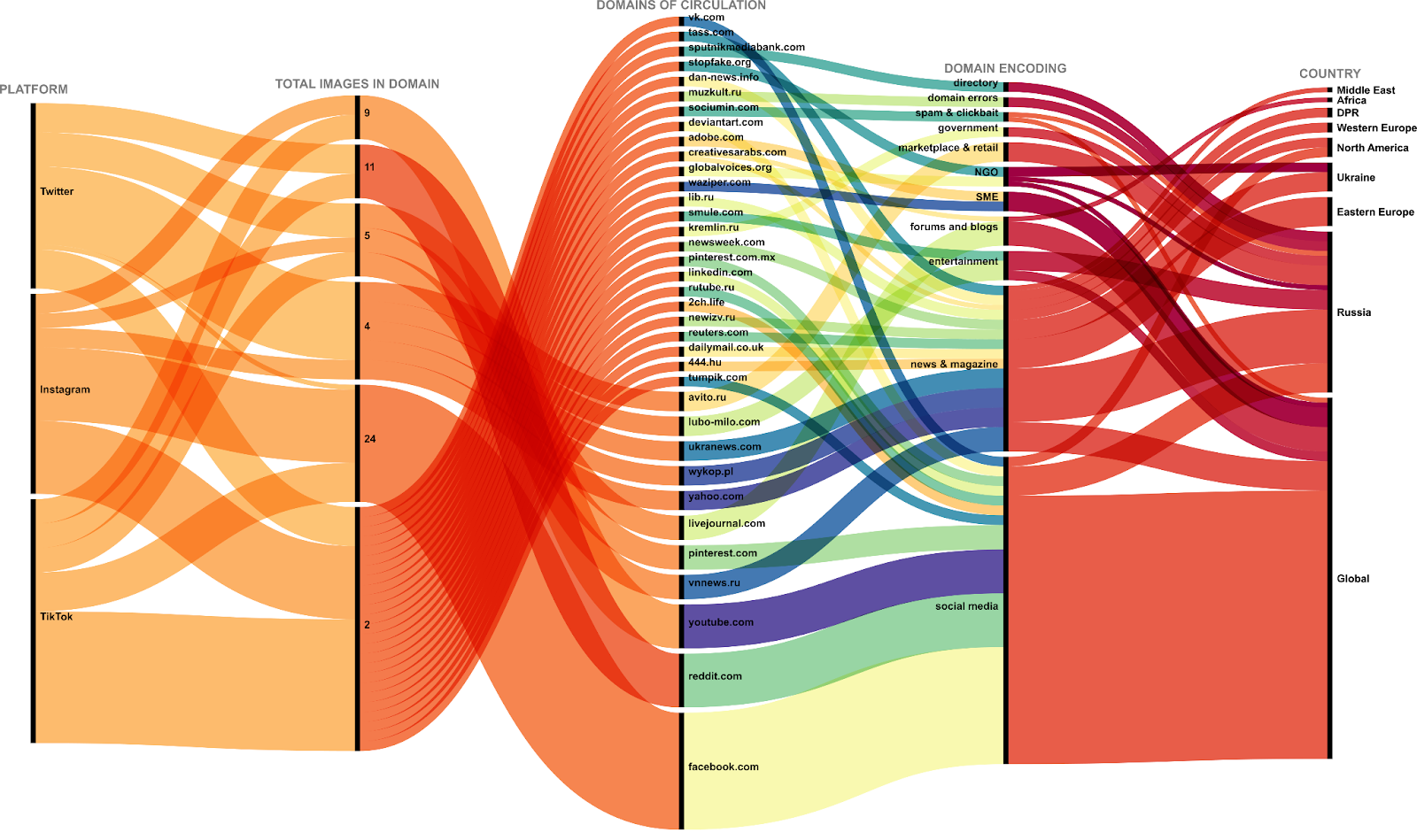
Figure 7: Domains containing images matching Twitter, Instagram and TikTok content identified through Google Vision API web detection and qualitatively coded by the type of domains and their targeted global publics. See high-res image. Domains containing just one unique matching image were excluded from this visualization for better readability.
The graph allows us an insight into the ecology of propaganda platformisation and image distribution across the web. Through our undertaken manual qualitative coding of the external domains, we probed into these domains to get a better understanding of where these images are being published on. We found that:
-
Most of the images circulate on social media, as things are reposted both mono- and cross-platform.
-
TikTok is very prominent, as videos can montage multiple images together.
-
There is a prominence of image appearance on news websites, predominantly on Russian sites however Western media outlets are also prevalent.
-
A lot of images seem to come from unrelated and spam websites, possibly alluding to troll and hacker activity.
-
Images from our dataset circulated in a scattershot pattern. That is to say, there was no single website where all images were shared or that even served as a dissemination hub. The domain category across which images were shared was “news and magazine”. However, within this category, only four websites hosted more than two images matching content from our dataset.
-
The overwhelming majority of news and magazine websites, 157 unique domains, hosted only one or two images from our data set.
-
Z content matching social media images circulated primarily across global domains. However, in the other most important encoding categories – news and magazines, spam and clickbait, services and tools, and marketplace and retail – circulation domains were predominantly Russian.
Analysis of cross-platform Z references and co-hashtag ecologies
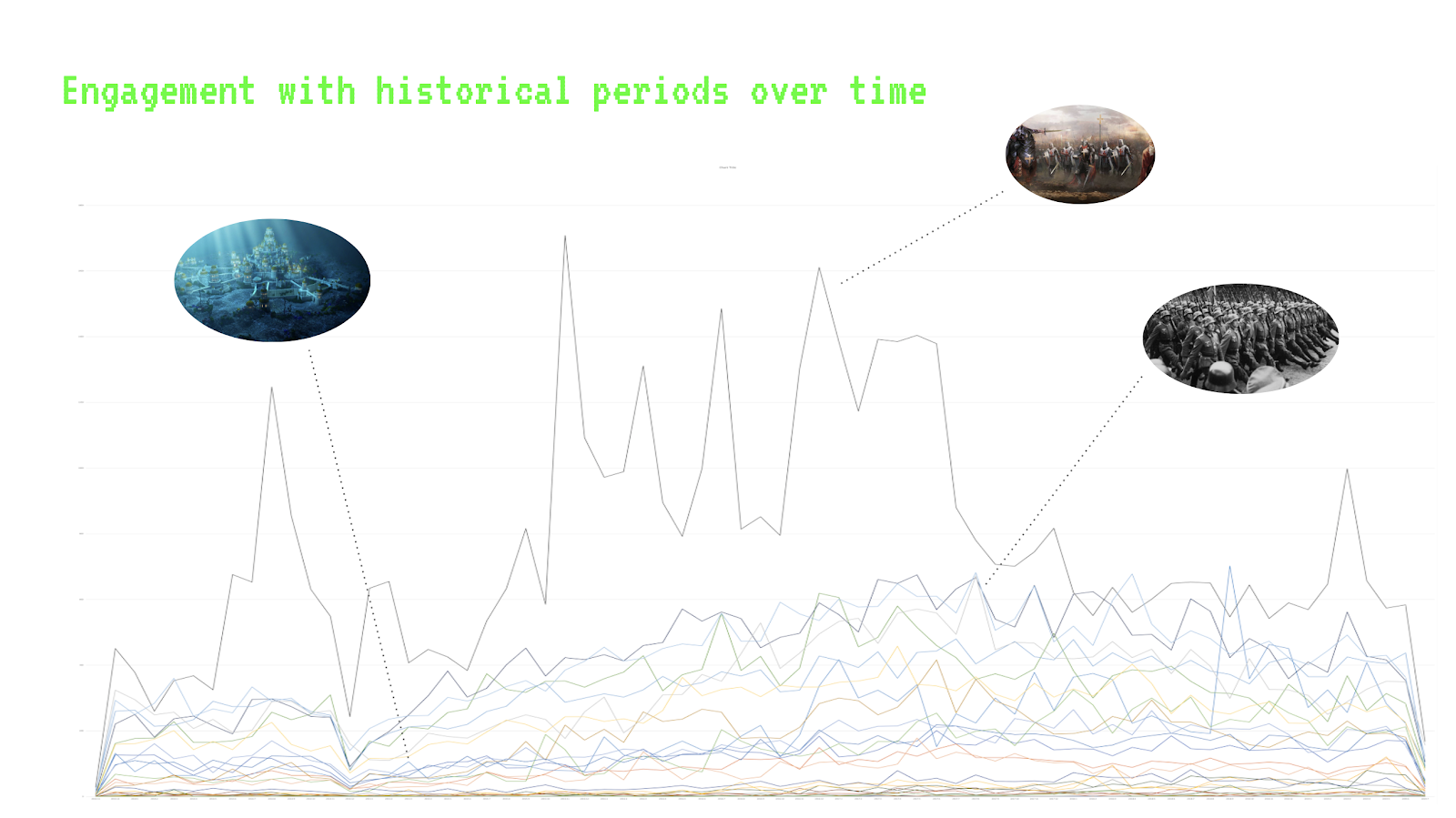
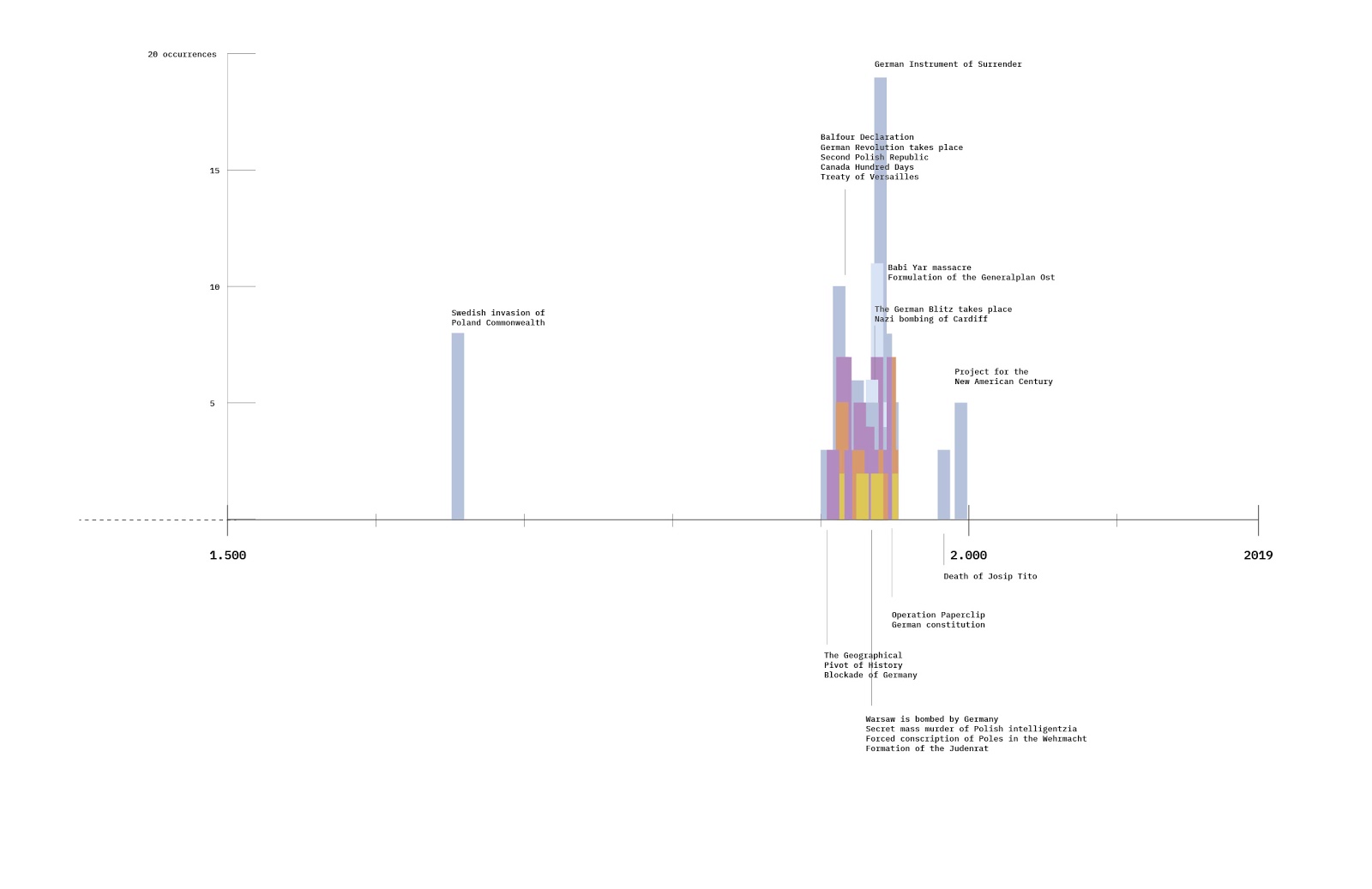
By analyzing the intensity with which most prominent shared co-hashtags and web entities were appearing across Instagram, Twitter, and TikTok, we were able to further explain some of the findings related to the tactics of Z content creation. The first finding relates to the use of hashtags and the number of occurrences of web entities on the three platforms. We found that the occurrence of hashtags on Instagram is the highest, reaching an average of 13.36 hashtags per post; TikTok has the most web entities, which on average will contain as many as 79.62 web entities per video. Twitter, however, has the lowest average number of hashtags and web entities per post. Similar trends can also be identified in the radar charts for the most used web entities and hashtags (see visualizations below). The frequency of posting with hashtags and the number of occurrences of the web entities show the extent to which shared Z vernaculars are relevant per platform.
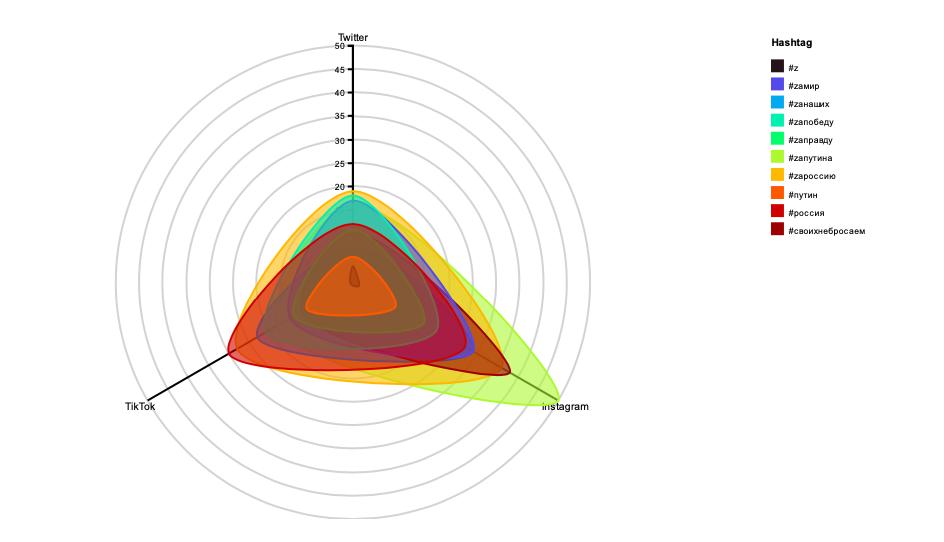
Figure 8: A radar chart of most-used Z co-hashtags and their intensity of use on Twitter, Instagram, and TikTok. See high-res image.
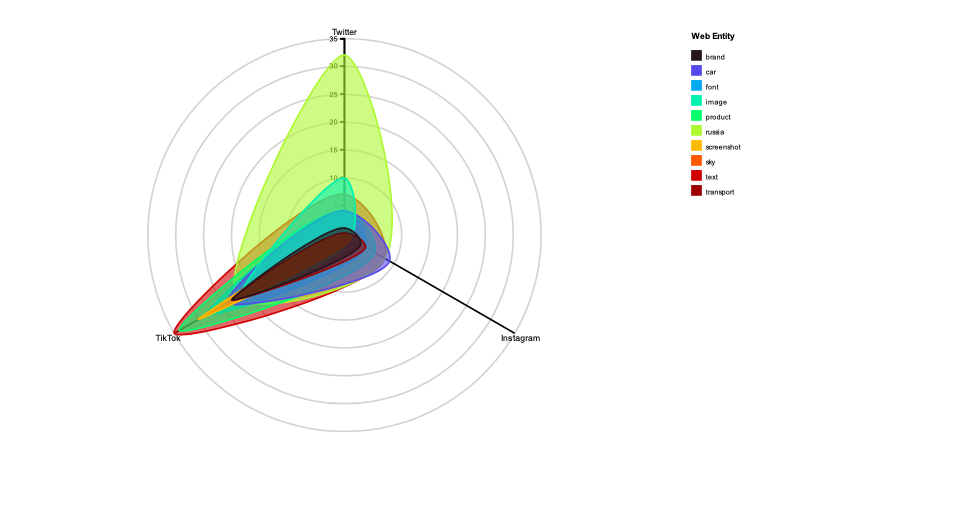
Figure 9: A radar chart of the most frequently appearing z-web entities and their intensity of use on Twitter, Instagram, and TikTok. See high-res image.
A significant finding based on the interpretation of radar charts is the prominent role of TikTok in the circulation of Russian propaganda. We assume this is related to the tactics of content creation on TikTok. The content on TikTok is mainly videos consisting of many static frames, in which materials such as stickers or special effects are often used. Therefore, these videos usually contain many web entity occurrences, making TikTok content more distributed. Also, a large number of Z themes (defined by web entities) on Instagram and Twitter match TikTok content.
We also found that Twitter and Instagram content is dominated by political messages and pro-Russian nationalist symbolism. Content from Twitter also appears on news websites. From the first radar chart focusing on z co-hashtags, we see that the hashtag #zапутина is used most often in posts on Instagram; the second radar chart shows that the web entity "Russia" appears heavily in tweets while being less prominent on other platforms. We assume that the use of ‘newsy’ and politically connotated visual material in the Twitter posts is related to the high number of "Russia" web entities in them.
Soundscape analyses
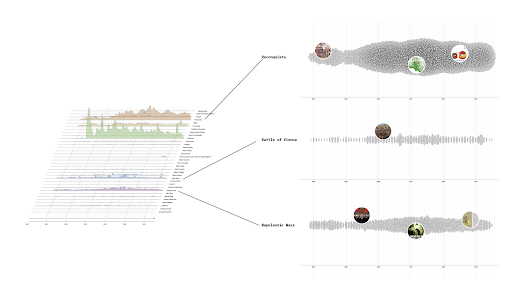
We find quite the 'staged' space on TikTok where multiple suspicious activities abound. Due to the Splinternet we get a skewed view of what Z propaganda is. Nonetheless, we can single out interesting instances where deviations and hijacking seem apparent. These tacticalities emerge from analysis of the relations between particular 'nationalistic' songs and hashtags or stickers/emojis (e.g. by using #putinhuilo in combination with Russian patriotic imagery and sounds). Ambivalence is also present, namely in mashups of queer performances (hard to tell whether it is mockery or not, talking about context collapse..) with seemingly pro-Putin messages.
Speech pattern to be explored through hi-res image
Interesting user practices emerge from for example God with the Russians where one of the five videos in this soundscape displays the befriending of anyone who likes or subscribes to their content, culminating in communities of shared allegiance. Figure 10
For the songs Good Evening Ukraine and Good Morning Russia we used sticker bigrams to see where these speech templates pertain to and how they relate to a particular visuality.
Figure 10
For the songs Good Evening Ukraine and Good Morning Russia we used sticker bigrams to see where these speech templates pertain to and how they relate to a particular visuality.
 Figure 11 shows how the sticker text Forbidden to Upload pertains to a similar visual setting where users post testimonial-like videos proclaiming how they are fine despite Internet restrictions. Nine of
The ten TikTok ’s in the sample containing stickers about ‘Forbidden (to) upload’ were uploaded the day after the introduction of the splinternet. The captions of those TikTok ’s contain phrases like: ‘’we found a way around’’.
Figure 11 shows how the sticker text Forbidden to Upload pertains to a similar visual setting where users post testimonial-like videos proclaiming how they are fine despite Internet restrictions. Nine of
The ten TikTok ’s in the sample containing stickers about ‘Forbidden (to) upload’ were uploaded the day after the introduction of the splinternet. The captions of those TikTok ’s contain phrases like: ‘’we found a way around’’.
 Figure 12: The frames of the videos that share Not Ashamed as present in their stickers. Not Ashamed is also a pertinent hashtag in the Russian propaganda space. These TikTok ’s show people who are filming themselves, their Russian passport or their car with a Russian license plate and Z-sign on it. With these video’s they probably want to show that they are all proud of their Russian citizenship. They emphasize this with the popular patriotic slogan as a sticker: ''мне не стыдно'', which means ''I'm not ashamed'.
Figure 12: The frames of the videos that share Not Ashamed as present in their stickers. Not Ashamed is also a pertinent hashtag in the Russian propaganda space. These TikTok ’s show people who are filming themselves, their Russian passport or their car with a Russian license plate and Z-sign on it. With these video’s they probably want to show that they are all proud of their Russian citizenship. They emphasize this with the popular patriotic slogan as a sticker: ''мне не стыдно'', which means ''I'm not ashamed'.
 Figure 13: Super ambivalent post from the Good Morning Russia song where we see the tag Putin Huilo (Putin fucking cunt/dickhead) with the pro-Russian song, pro-Russian sticker text, and a queer flag not typically associated with Z. This points to tactical activities trying to, possibly, through the hashtag tap into the pro-Ukrainian audience with a Russian message in the sticker and the song.
Figure 13: Super ambivalent post from the Good Morning Russia song where we see the tag Putin Huilo (Putin fucking cunt/dickhead) with the pro-Russian song, pro-Russian sticker text, and a queer flag not typically associated with Z. This points to tactical activities trying to, possibly, through the hashtag tap into the pro-Ukrainian audience with a Russian message in the sticker and the song.
6. Discussion and Conclusion
Our cross-platform explorations demonstrate that
-
TikTok content is distributed across different propaganda scenarios and shares multiple memetic references with content from both Twitter and Instagram. Many TikTok videos make use of collage techniques, stitching together still images of Z propaganda that are not TikTok -native—a finding that derives from a variety of TikTok -associated unique domains with matching content.
-
In general, Z narrative and visual culture is limited and highly dispersed in circulation. Despite platform-specific “virality ambitions” of Z content creators we found that Z propaganda did not exactly “go viral” on social media. Rather, for a majority of images, we found just one or two matches across many different lower-quality websites. This dispersed – but not organically viral – distribution pattern across both social media and the broader web supports Hodgson’s (2021) thesis that Russia is engaging in national branding through a strategy of “littering the information space” (Kiriya 2021).
-
Variations in popular z templates appropriate strategies of trend hijacking (e.g., via z hashtags used to share football-related TikToks) and pro-Ukrainian political hijacking directed against Putin and typical pro-Russian z symbolism.
Our TikTok -specific findings demonstrate that
-
Z videos often employ visual and musical montage techniques, namely through the adaptation of sound and speech templates in the “original sound” and narrative organization of video frames stitching together highly distributed static images associated with pro-Russian sentiment (Kremlin, Putin, Z symbol, flags, bears, etc.).
- Partisan reworkings of songs also emerge in instances of hashtag tacticalities (using the hashtag Putin Huilo to disseminate Russian messages to opposing audiences).
- Speech patterns or shared patterns in sticker texts both seem to reflect the lexicon in captions and hashtags.
- Something to look further into is queer representation in TikTok videos (through tactical uses of emoji but also visual elements) that are very multi-layered and seem to display cases of severe context collapse.
| Dispatches from the place of imminence (INC Tactical Media Room series) Earlier DMI summer school project Tracking Exposed Report on TikTok restrictions Boler, M., & Davis, E. (2018). The affective politics of the “post-truth” era: Feeling rules and networked subjectivity. Emotion, Space and Society, 27, 75-85. Eichenbaum, H.; Cohen, N. (1993). Memory, Amnesia, and the Hippocampal System, Cambridge, MA: MIT Press. Gaufman, E. (2017). The Post-Trauma of the Great Patriotic War in Russia. Studies in Russian, Eurasian and Central European New Media (digitalicons.org), no. 18, 33-44. Retrieved from https://www.academic.edu/36877234/The_Post-Trauma_of_the_Great_Patriotic_War_in_Russia ‘ Gillespie, T. (2010). The politics of ‘platforms.’ New Media & Society, 12(3), 347–364. https://doi-org.proxy.uba.uva.nl/10.1177/1461444809342738 Hennion, A. (2003). “Music and Mediation: Toward a New Sociology of Music.” In The Cultural Study of Music: A Critical Introduction, edited by M. Clayton, T. Herbert, and R. Middleton, 80–91. London: Routledge. Kolstø, P. (2016). Introduction: Russian nationalism is back – but precisely what does that mean? In P. Kolstø & H. Blakkisrud (Eds.), The New Russian Nationalism: Imperialism, Ethnicity and Authoritarianism 2000–2015 (pp. 1–17). Edinburgh University Press. http://www.jstor.org/stable/10.3366/j.ctt1bh2kk5.7 Narayanan, A. (2022). TikTok ’s secret sauce. Retrieved from: https://knightcolumbia.org/blog/tiktoks-secret-sauce Paasonen, S. 2019. “Resonant Networks. Affect and Social Media” In Public Spheres of Resonance. Constellations of Affect and Language, edited by A. Fleig, C. von Scheve, 49-62. London: Routledge. Rüsen, Jörn (2004) ‘How to Overcome Ethnocentrism: Approaches to a Culture of Recognition by History in the Twenty-First Century’, History and Theory, 43(4), 118–129. Venturini, T. (2021). Toward a Sociology of Online Monsters. Online Conspiracy Theories and the Secondary Orality of Digital Platforms. HAL ID: hal-03464174 https://hal.archives-ouvertes.fr/hal-03464174 Zhurzhenko, Tatiana (2007) ‘The Geopolitics of Memory’, Eurozine, May 10, http:// www.eurozine.com/articles/2007-05-10-zhurzhenko-en.html (29.04.2018). |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback