The presence of problematic information and users on political Twitter in the wake of the 2020 U.S. elections
Team Members
Carlo De Gaetano, Seb Dewhirst, Marloes Geboers, Maarten Groen, Charis Papaevangelou, Simeon Vidolov, Grace WatsonContents
1. Introduction
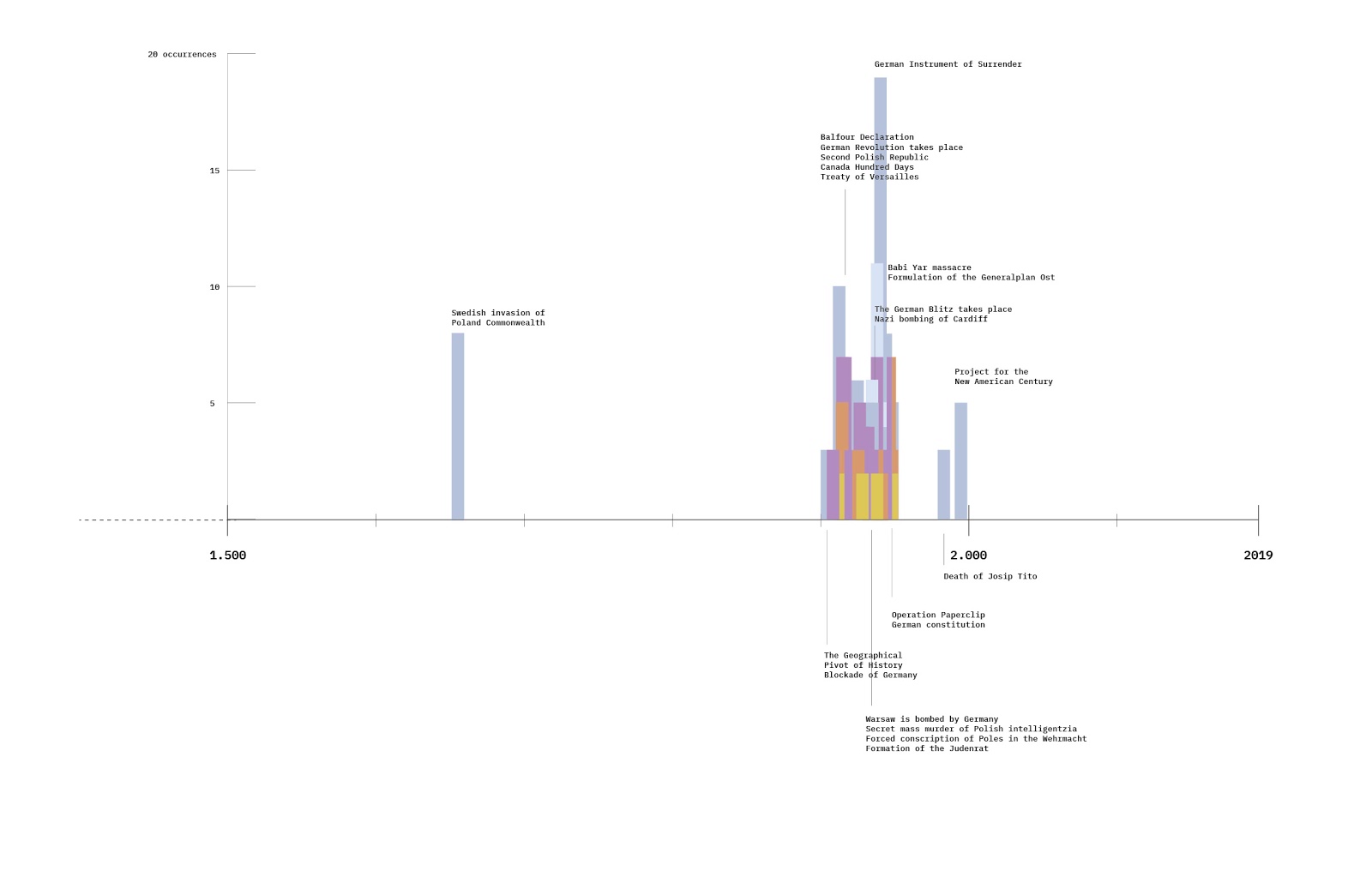
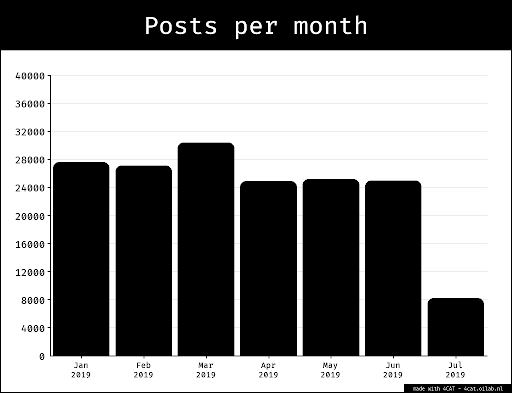
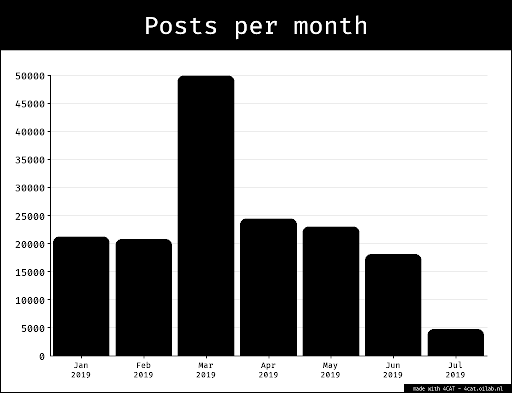
In the spring of 2020 researchers of DMI engaged in a data sprint working with data covering a part of the (early) run-up to the 2020 U.S. presidential elections; more specifically they focused on a time span covering a period of increased user activity due to Super Tuesday (March 3 with the data spanning 2 to 22 March 2020). In order to shed light on the magnitude of problematic information and users circulating and present on Twitter they employed digital methods to find that mainstream sources are shared more often than problematic ones, but (hyper)partisan sources are half of all sources shared, implying that social media may be marginalizing mainstream media. Additionally, highly active, problematic users (fake profiles, bots, or locked/suspended accounts) were found on both sides of the political spectrum. In order to assess how the presence of problematic sources and users has evolved over time, we replicated the research protocol during the 2021 winter school data sprint, using data spanning December 24 2020 to January 4 2021 which is situated in a post Trump era and also encompasses the lead up to both Georgia senate elections (Jan 5), crucial for the democrats to gain a majority in Congress, and (somewhat unforeseen) the Capitol Hill riots of Jan 6.
To be sure, problematic information is “inaccurate, misleading, inappropriately attributed, or altogether fabricated” (Jack, 2017, p1), and most engaged-with content on Twitter refers to the most retweeted tweets and/or most frequently shared sources within the given time period. Most active users or accounts are those with the highest tweeting activity, and problematic ones are fake accounts, bots, or locked/suspended users. Political and issue spaces on Twitter (or ‘political Twitter’) refer to the result sets from keyword and hashtags queries for presidential candidates, political parties, and social issues.
2. Research Questions
To what extent are problematic sources present in the most engaged-with content in political and issue spaces on Twitter in the wake of the 2020 US elections?And are there problematic users among the most active?
Are they typically of a particular political leaning?
3. Methodology and initial datasets
We set off with a TCAT bin containing over 32 million tweets at the start of the winter school (see keywords and hashtag bin query in the appendix). This implicates the speed of analyses to such an extent that we had to narrow down the time span of at least two parts of our threefold analyses: the top user and top tweet analyses. For the first analysis, a source frequency analysis, we could use the entire time span, which was still limited (December 24 to January 4), however very relevant as it includes the lead up to significant events as mentioned earlier, in the introduction. a) Most shared sources For most shared sources we exported user URL tables from the DMI-TCAT tool over the time frame 24th December 2020 until the 4th January 2021 listing the top engaged with sources within each political/issue space. Using a Python script, these tables were compared to an expert source list which categorises each source into two main categories; mainstream or problematic. The mainstream sources are further divided into the sub-categories (hyper)partisan conservative, (hyper)partisan progressive or neither. The expert list was created using existing labelling sites, Allsides.com, Media bias/Fact check, ‘The Chart’ and NewsGuard. This categorisation process allows for a comparison of source quality within each query. Therefore we can identify the extent to which problematic sources are present compared to mainstream information and, of the mainstream sources, identify the presence of hyperpartisan sources. b) Top users To analyse top users within each political and issue space we exported the top 20 most active users (highest tweet count) within each query. In order to accurately replicate the study in March this analysis took place over a four day period, from 1st January to 4th January. Where in the previous study a smaller time frame of three days starting from the 2nd March was chosen to capture the ‘Super Tuesday’ event where Twitter activity would be noticeably high, our smaller date range of four days was not based around any significant date and was only selected in order to aid comparison between both studies. Within the top users we underwent a two-step categorisation process. Firstly, we identified the authenticity of accounts, broken down into fake accounts, bot accounts, suspended/locked accounts and authentic accounts. Secondly, we identified the partisanship of each account; Republican, Democrat or unknown. This was achieved through a manual labelling process aided by online account categorisation sites ‘Botometer’ and ‘Sparktorro’. Within ‘Botometer’, after searching an account, the researcher is given a score “on a 0-to-5 scale with zero being most human-like and five being the most bot-like” (Botomer FAQs). This score can be further broken down into scores of specific activity such as; AstroTurf, Fake Follower, Financial, Self Declared, Spammer and Other. In addition to Botometer, Spark Torro is a useful online site that analyses twitter account bios and activity. One useful function of Spark Torro is that it lists common words found in the bios of account followers. Therefore, listing phrases such as; ‘Trump’ and ‘MAGA2020’ would suggest the account was pro Republican this aided the categorization of an account’s partisanship. It is worth noting that, although these sides aided the categorisation process, they did not produce the correct result each time and can only be viewed as complementary tools. Ultimately each account was viewed personally by the authors and labels were given after a subjective analysis. c) Top tweets To analyze top tweets we used the same time span as the top user analysis (from 1st January to 4th January). The top 20 tweets were extracted from the political spaces, and from the three issue-specific hashtags, DACA, Green Deal, and Medicare. The most retweeted or the most popular tweets were further categorized into two categories, partisanship and problematic information providers. Similar to the problematic users’ segment, the partisanship of the tweets were manually labelled by looking at the lexicon of the tweet and further details about the person who tweeted. To decide if a tweet contains problematic information, we checked whether any news sources linked in the tweets were classified as such in the labelled source list (expert list based on fact-checking websites: Allsides.com, Media bias/Fact check, ‘The Chart’, and NewsGuard). d) Network analysis of Sources/Users We exported the “Source-User” data table (“.csv”) of thematic subsets (democrat, republican, trump and biden queries, separated by theme) from DMI-TCAT, concerning the range of dates: 01/01/2020 to 04/01/2020. We then processed the “.csv” file through the “table2net” tool, developed by the MédiaLab, in order to create a network file that could be then analysed using Gephi. We chose the creation of a bipartite network, with two types of nodes, where the one node was the domains’ names and the second node was the users’ names, and the nodes were connected in a weighted manner according to their frequency, that is the edges’ weight was proportional to the frequency with which a user shared a specific source. This process provided us with a network file. We then opened the “.gefx” file with Gephi and proceeded with the following protocol:- We first ran the “ForceAtlas 2” algorithm.
- We then filtered out the data using the “Degree Range” filter from the “Topology” sub-library, using a minimum degree range of 2 and, thus, filtering out any “weak” connection.
- What we aimed at was to focus on the most active users and the most shared sources and, after a brief analysis of our data, we draw the conclusion that the most reasonable step would be to pinpoint those nodes that had an “occurrence” degree of 3 or more.
- We then ended up with a manageable dataset comprised of most shared sources by the most active users, which we labelled manually according to DMI’s established criteria, like “mainstream or problematic sources”, “Democrats or Republicans” and “real or fake/bot user”; in cases where we could not identify the partisanship or authenticity of users and sources, we labelled them as unknown.
- We then created a column within the “Data Laboratory” section of Gephi, where we named each user node in terms of authenticity and each source node in terms of partisanship.
- We then coloured each node differently and adjusted font size and node size depending on their occurrence to make the network visualisation clearer.
- Finally, we exported the network visualisation with the following protocol:

4. Findings
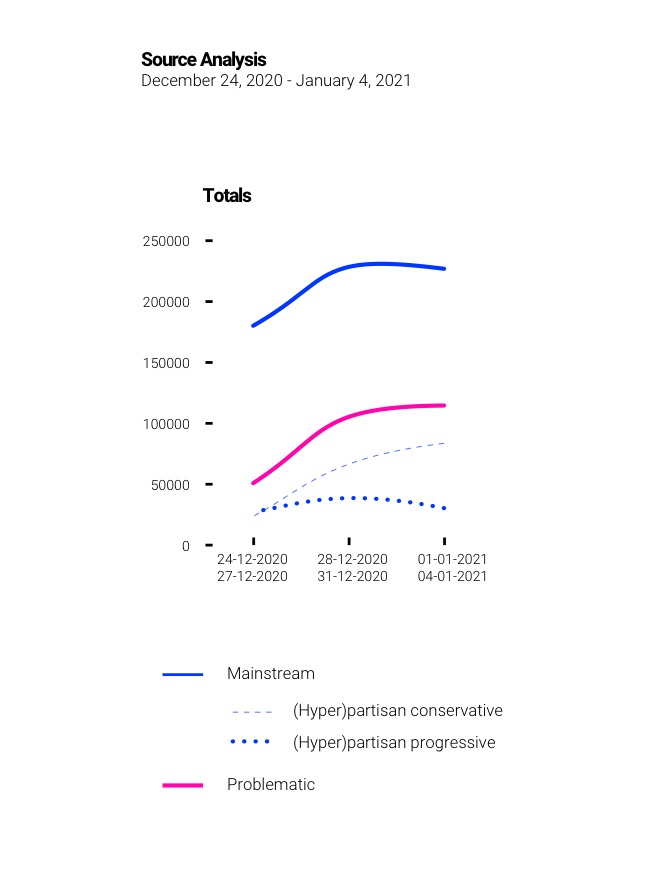
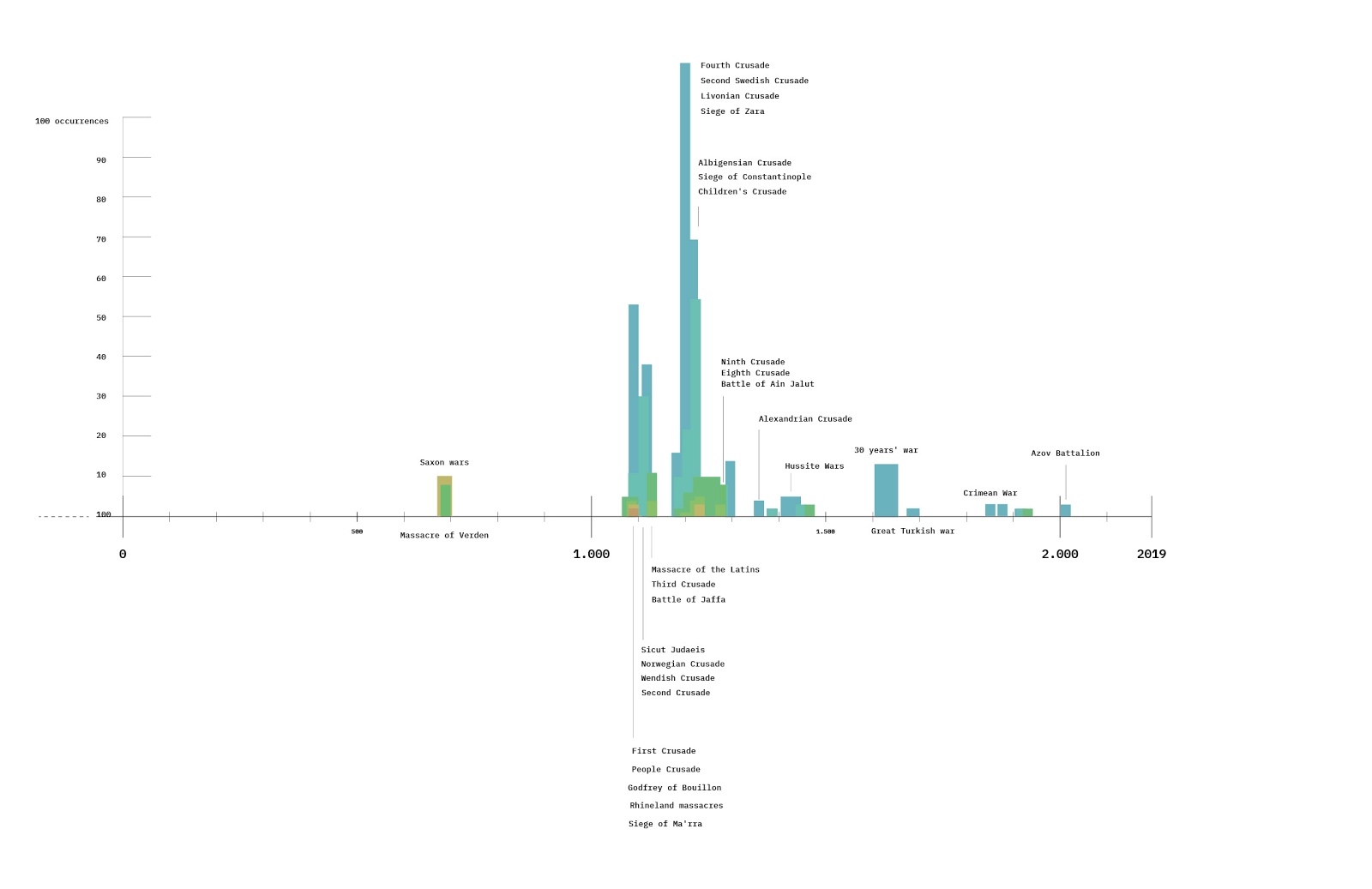
Firstly, the most significant similarity between the March study and this one is that mainstream sources are still outperforming problematic sources. A sum total of sources shared across all four political spaces and three issue spaces indicate that mainstream sources are more engaged with than problematic sources. However, problematic sources are increasingly popular. In March they represented ⅕ of all sources shared now it is ⅓. Although mainstream sources still represent the majority, it should be acknowledged that the rise of problematic sources indicates a pattern trending towards conditions analyzed by Craig Silverman on Facebook for the 2016 election; though when one changes the classification on what constitutes problematic sources (see Rogers, 2020) i.e., make the definition more narrow through the exclusion of hyperpartisan (conservative and progressive) sources the results are different.
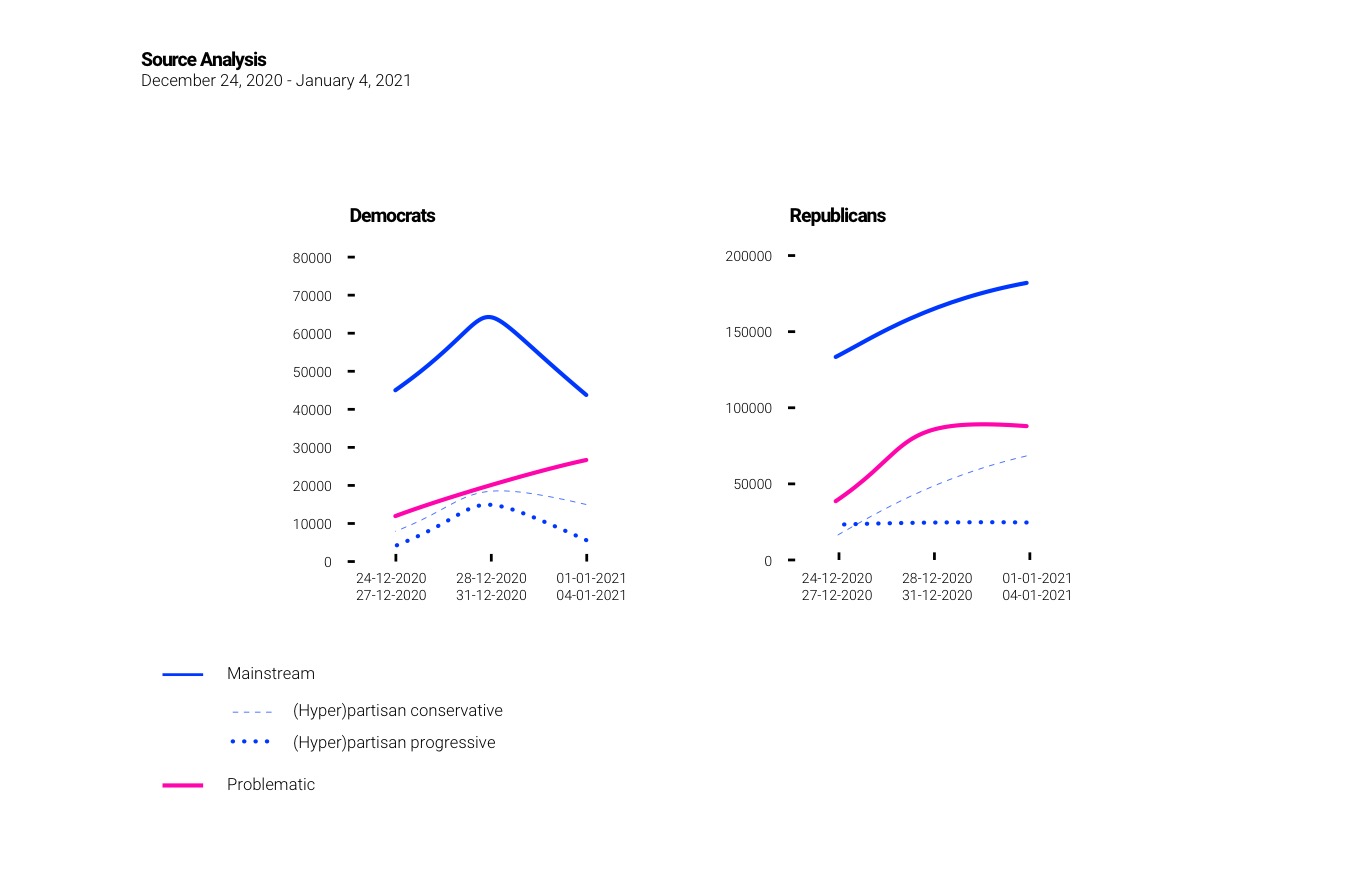
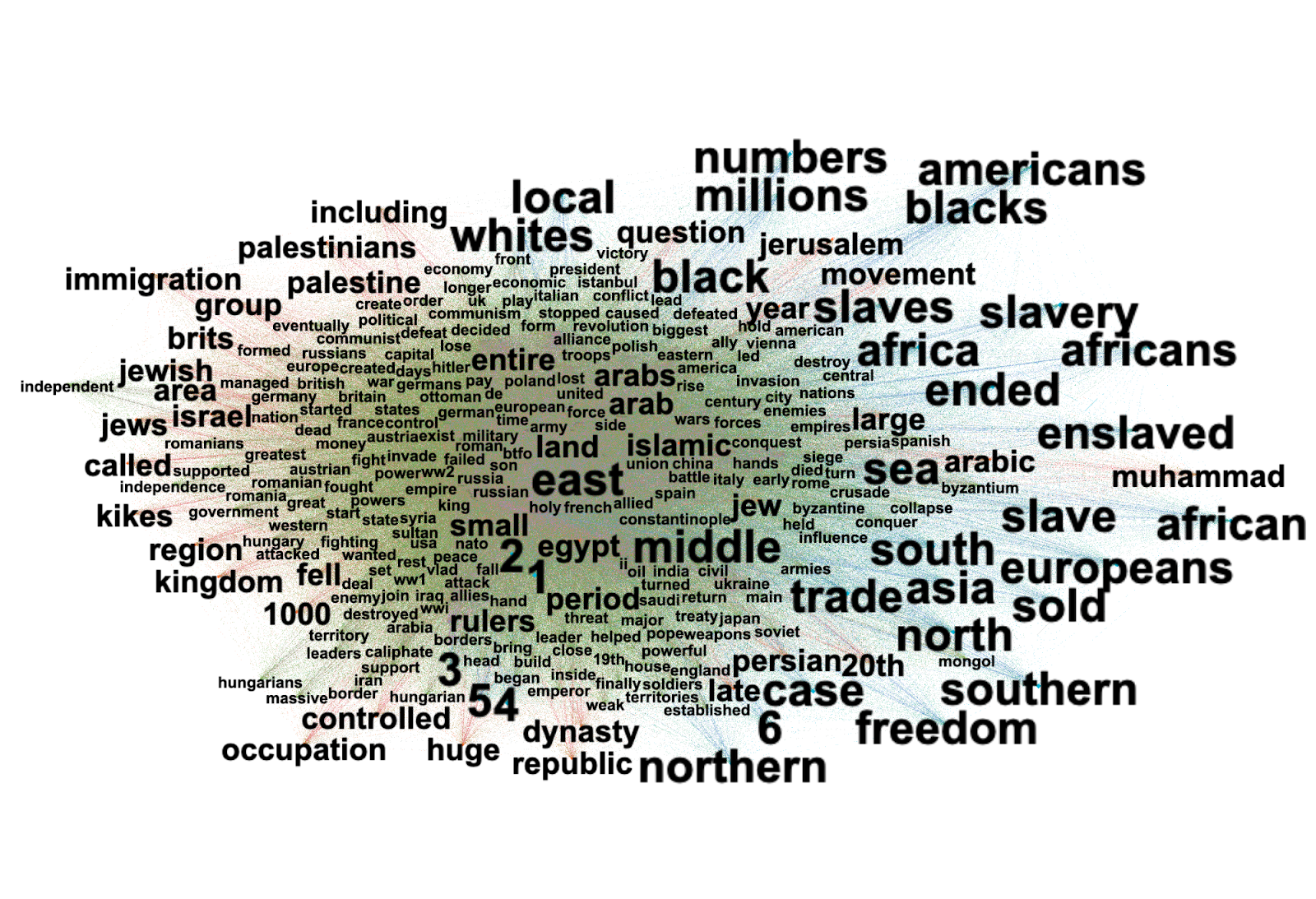
Within mainstream sources, 43% are considered (hyper)partisan. Although not officially recognised as problematic, (hyper)partisan sources can be considered to contain bias or manipulative information incapable of delivering a neutral account of events. In March (hyper)partisan sources represented about 50 % of the mainstream sources meaning there has been a fall of seven % in this study. (Hyper)partisan sources still represent a significant proportion of mainstream sources. With almost one-third of sources being problematic and 43 % of mainstream sources considered (hyper)partisan it can be argued that with regards to problematic information the state of Twitter has worsened since March and that mainstream news has become more marginal on social media (Barnidge & Peacock, 2019). (Hyper)partisan conservative sources are now being shared more often across both Republican and Democrat political spaces. This contrasts results in March that indicated a cross over of information where (hyper)partisan conservative sources were being shared by Democrats and (hyper)partisan progressive sources were being shared by Republicans. The findings of this study indicate that Democrats are sharing more (hyper)partisan Republican sources in an attempt to attack the Republican political party. Whereas the Republicans share more of their ‘own’ sources. After the results of the election, it appears that Democrats continue to attack Donald Trump whilst Republicans no longer attack the Democrats.
 User analysis
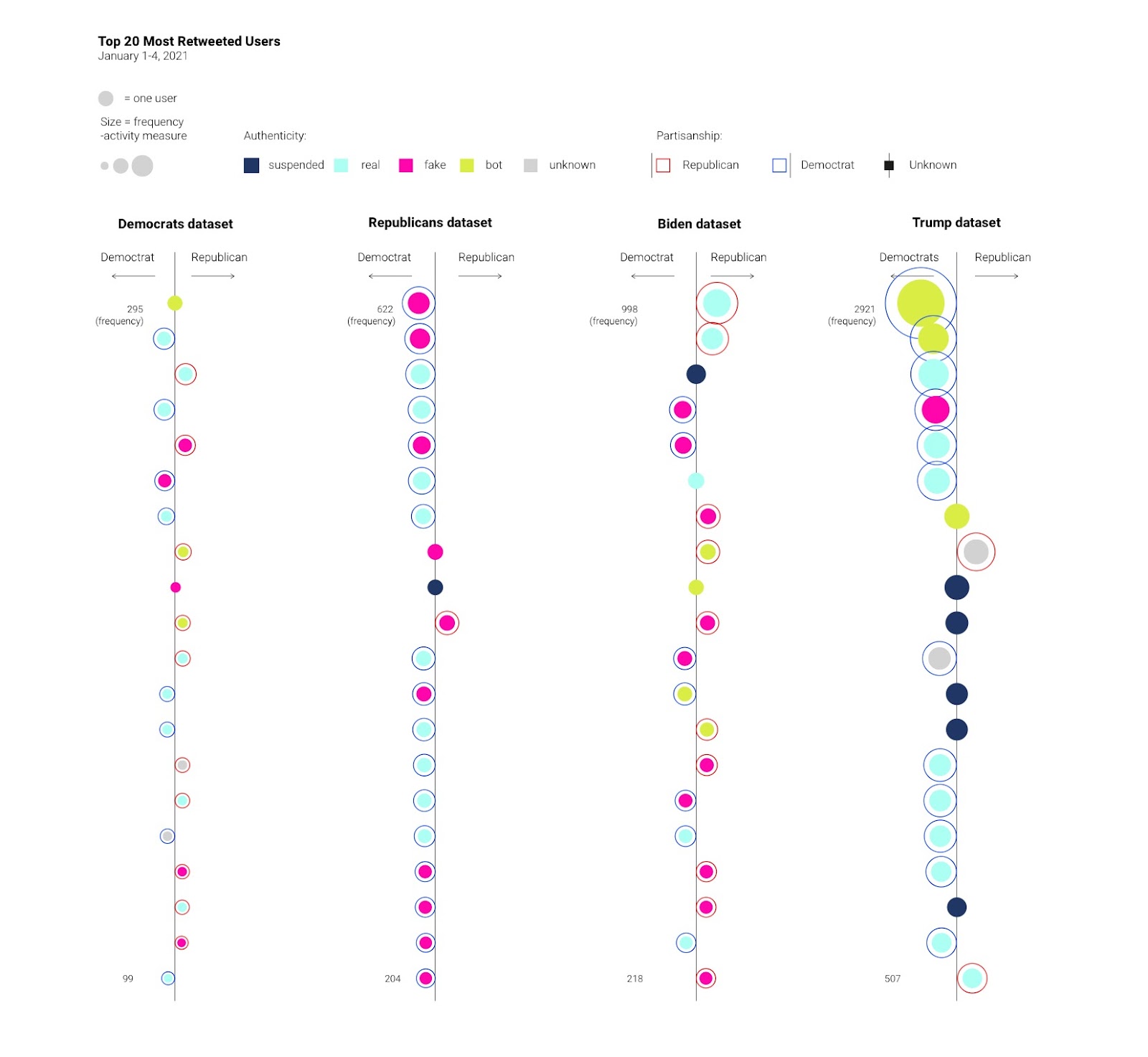
This finding is validated when analysing top 20 most active users across the four political spaces. Pro-Democrat accounts now dominate the top 20 within both Republican and Trump political spaces. This infiltration of political space indicates that Democrats are employing Republican keywords and hashtags in an attempt to attack the Republican party. This somewhat echoes the study in March that found both sides of the political spectrum would adopt the opposition's keywords and hashtags in order to target each other. However, the most significant aspect of this study is that it is the Democrats who are undergoing this activity more than Republicans. The second aspect of this finding concerns the presence of problematic accounts across the four political spaces.
In total problematic accounts take up about 60 % of all accounts which is roughly the same as the study in March. In 2016 it was found that suspect accounts were mostly Pro-republican and these were responsible for spreading most of the problematic information (Bovet & Maske, 2019). In March it was found that there was a rise in problematic accounts associated with pro-democrats. Within the data sets of this study we have found that there are more pro-democrat problematic accounts. Therefore it can be argued that Democrats are employing problematic accounts within Republican political spaces to attack the Republican party. These attacks could arguably align with the election results and the events that followed. The Democratic party gained momentum after Joe Biden’s victory empowering more Twitter activity. Furthermore, Democrat attacks on Republicans could have been instigated by Trump’s refusal to concede and allow for a smooth transition of power.
<img alt='A close up of a white background
Description automatically generated' height='575' src='https://lh6.googleusercontent.com/cQcViIHz-gLkwITzJd3_qbzkV_ntdHLM_KwOnpH86ma-j68z2IiQDVorxGwUXBpxL7MrwwdLXNud8NJHg37rMjGCGUNMWV-jJLMuuvRyHUK8RCScLX1CDvGBdV_HzlNehX2zdWM' width='624' />
User analysis
This finding is validated when analysing top 20 most active users across the four political spaces. Pro-Democrat accounts now dominate the top 20 within both Republican and Trump political spaces. This infiltration of political space indicates that Democrats are employing Republican keywords and hashtags in an attempt to attack the Republican party. This somewhat echoes the study in March that found both sides of the political spectrum would adopt the opposition's keywords and hashtags in order to target each other. However, the most significant aspect of this study is that it is the Democrats who are undergoing this activity more than Republicans. The second aspect of this finding concerns the presence of problematic accounts across the four political spaces.
In total problematic accounts take up about 60 % of all accounts which is roughly the same as the study in March. In 2016 it was found that suspect accounts were mostly Pro-republican and these were responsible for spreading most of the problematic information (Bovet & Maske, 2019). In March it was found that there was a rise in problematic accounts associated with pro-democrats. Within the data sets of this study we have found that there are more pro-democrat problematic accounts. Therefore it can be argued that Democrats are employing problematic accounts within Republican political spaces to attack the Republican party. These attacks could arguably align with the election results and the events that followed. The Democratic party gained momentum after Joe Biden’s victory empowering more Twitter activity. Furthermore, Democrat attacks on Republicans could have been instigated by Trump’s refusal to concede and allow for a smooth transition of power.
<img alt='A close up of a white background
Description automatically generated' height='575' src='https://lh6.googleusercontent.com/cQcViIHz-gLkwITzJd3_qbzkV_ntdHLM_KwOnpH86ma-j68z2IiQDVorxGwUXBpxL7MrwwdLXNud8NJHg37rMjGCGUNMWV-jJLMuuvRyHUK8RCScLX1CDvGBdV_HzlNehX2zdWM' width='624' />
 (Re)tweet analysis
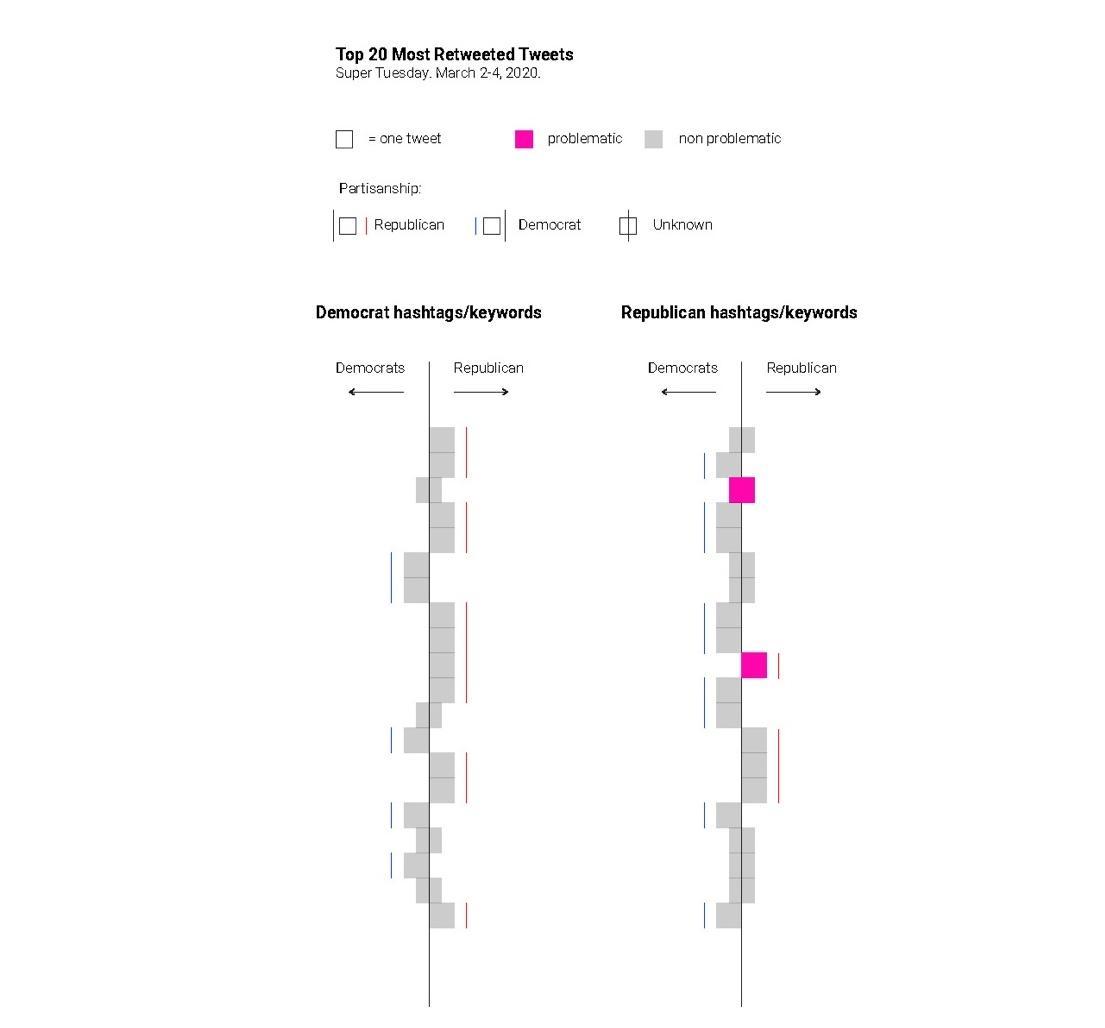
Within the most retweeted tweets, a large majority are tweeted by influential people, including presidential candidates, members of Congress and journalists. As found in the March study, within
(Re)tweet analysis
Within the most retweeted tweets, a large majority are tweeted by influential people, including presidential candidates, members of Congress and journalists. As found in the March study, withinour study there is a distinct lack of problematic information. This confirms the implications of the March study that most retweeted tweets can be viewed as a source of credible information.
Furthermore, from a methodological point of view, most retweeted tweets are not the most effective dataset if researchers in the future are only concerned with studying problematic
information.

 Network analysis Source/Users
Network analysis Source/Users
 Network 1: Democrat query
Network 1: Democrat query
 Network 2 Republican query
Network 2 Republican query
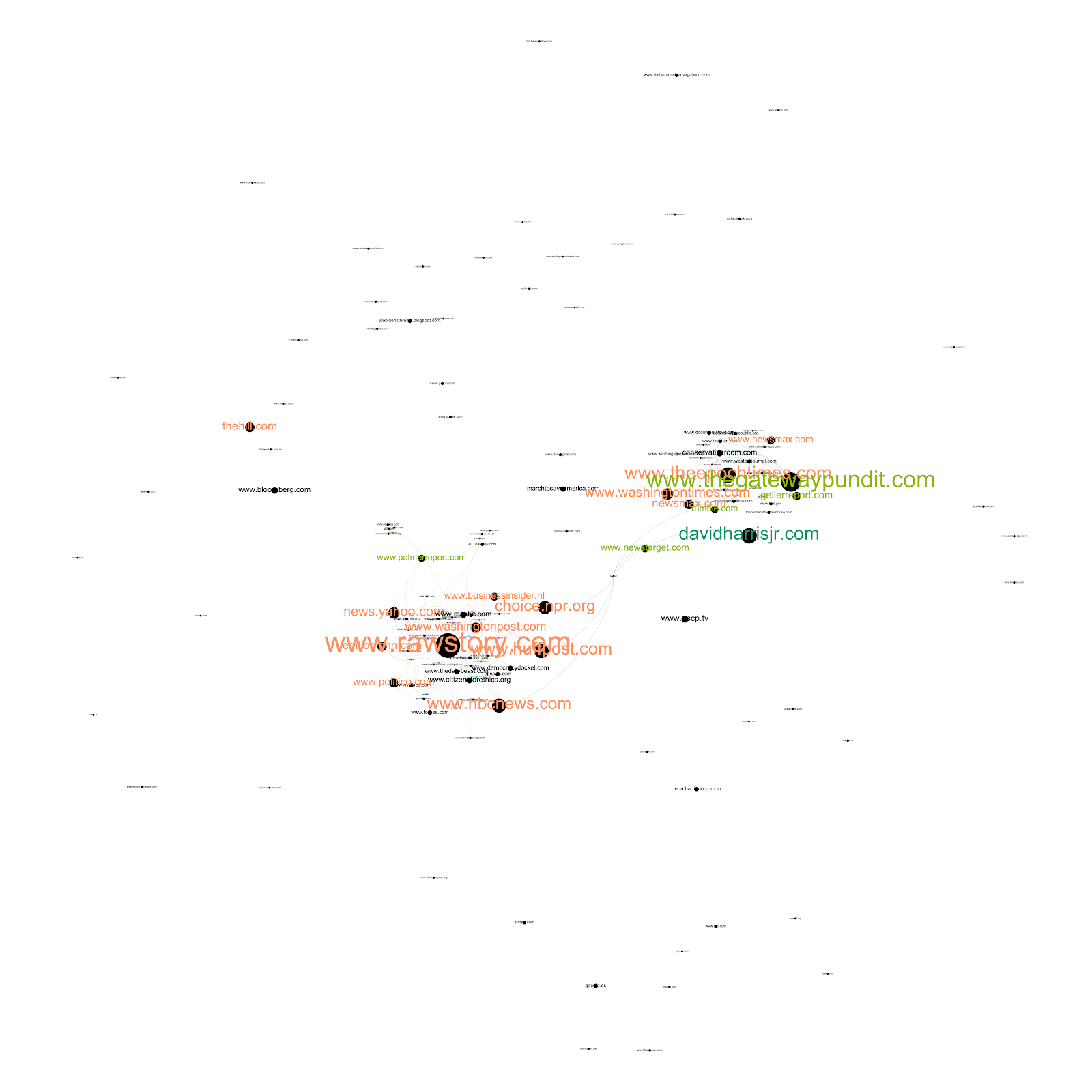 Network 3 Trump query
Network 3 Trump query
 Network 4 Biden query
Newer sources emerged in the top 5 which we based on most occurring sources within the networks.
Network 4 Biden query
Newer sources emerged in the top 5 which we based on most occurring sources within the networks.
 March data sprint
March data sprint
 January 2021 (1-4) shows new actors in the field of prominent mainstream and niche news outlets
January 2021 (1-4) shows new actors in the field of prominent mainstream and niche news outlets
5. Discussion
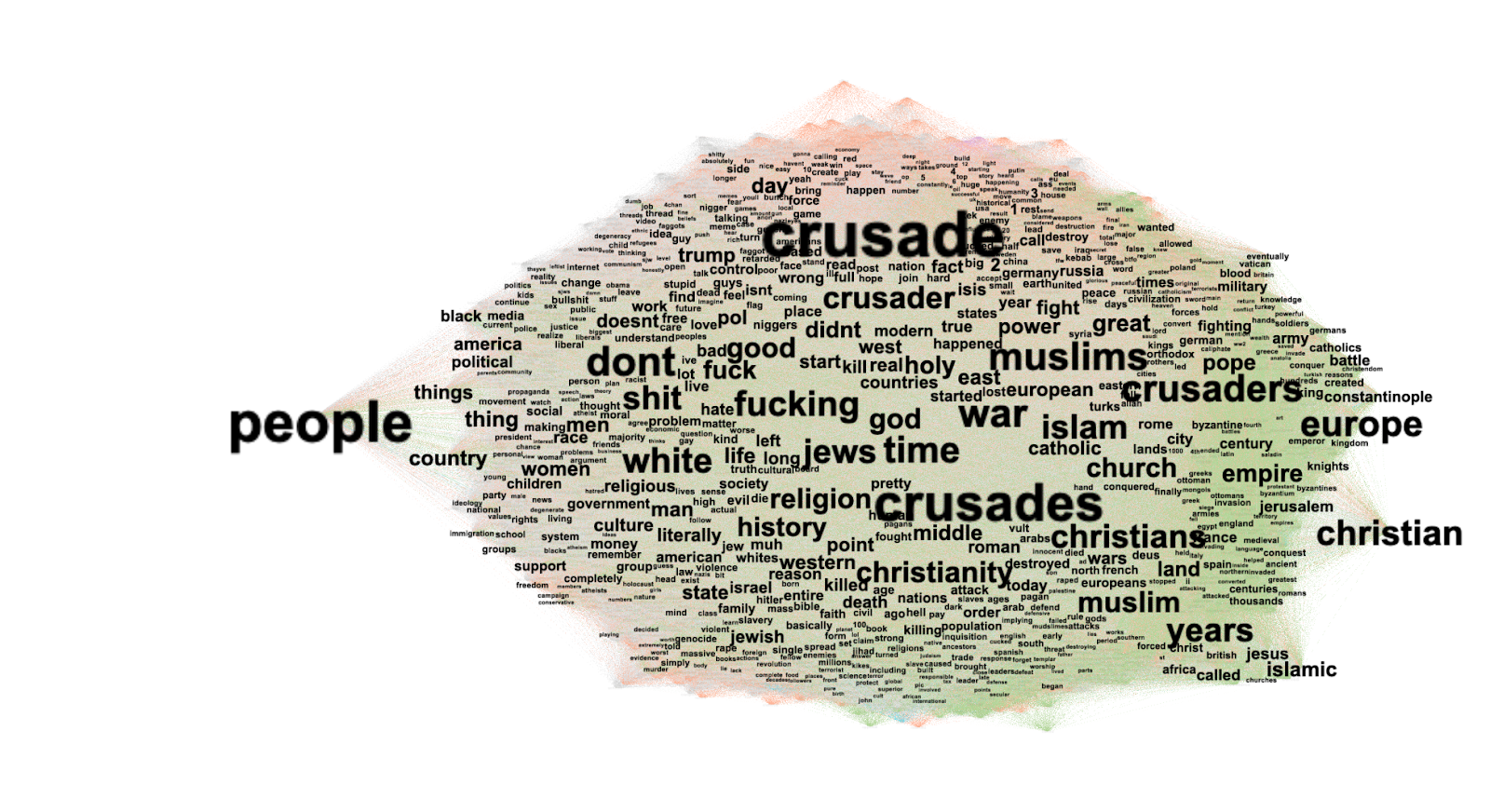
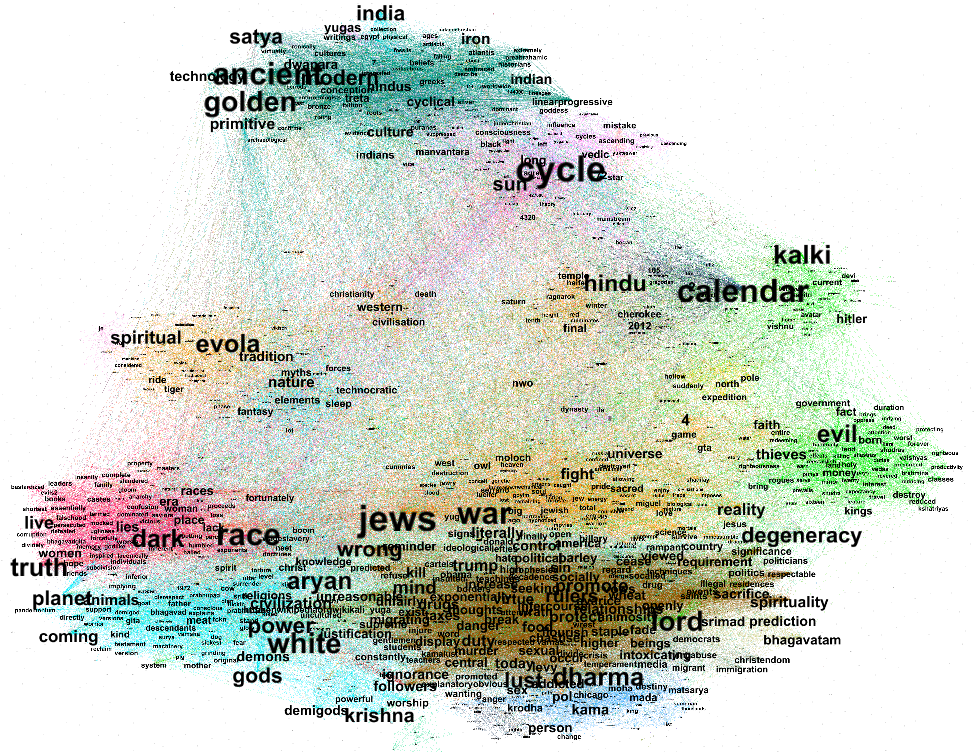
Within all datasets, we found a pattern whereby users employ the opposition’s keywords and hashtags in order to target each other. It occurs in political spaces organized around both political parties and candidates. Within these supporter spaces, there appear to be more sources shared that attack the opponent rather than support the candidate. It reiterates how the relentless targeting of people with hyper-partisan viewpoints continues and is a phenomenon practised on both sides of the political spectrum. The methodological implication is that one cannot neatly demarcate a supporter space through hashtags and/or keyword queries only. (From March sprint group)
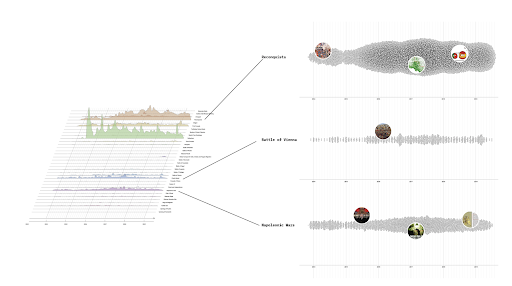
We propose to untangle keyword and tag data sets with demarcating supporter spaces. To do this a next step would involve analysis using NLP to assess the lexicon of tweets that refer to mainstream or problematic sources (further segmented based on different classifications of what constitutes problematic sources, see also Rogers, 2020). One could even integrate this with sentiment analysis. In the (quick and rough) example below you get an idea of the importance of tweet lexicon with which sources are contextualized in the social media realm.6. Conclusions
Overall, problematic sources were more present than in March 2020. In 2016 according to studies by Silverman (XXXX), it was mostly pro-republican fake and bot accounts that spread information on Twitter. However, we noticed that there are also pro democrat fake and bot account actively spreading information. (March 2020) > Aggravation of the phenomenon identified in the study carried out in March 2020 evident in December/January 2020/2021 Among the users with the highest activities on Twitter, the majority were fake accounts or bots (March 2020) > This holds up for the republican and the Trump queries. The Biden and Democrat queries showed slightly more authentic accounts in Dec/Jan. Seeing slightly more real users in the most active user list could relate to Twitter’s deplatforming activities and their effectivity.7. References
Barnidge, M., & Peacock, C. (2019). A third wave of selective exposure research? The challenges posed by hyperpartisan news on social media. Media and Communication, 7(3), 4-7. Botometer by OSoMe. (2021). Retrieved 15 January 2021, from https://botometer.osome.iu.edu/faq#which-score Bovet, A., & Makse, H. A. (2019). Influence of fake news in Twitter during the 2016 US presidential election. Nature Communications, 10(1), 7. https://doi.org/10.1038/s41467-018-07761-2 Jack, C. (2017). Lexicon of Lies: Terms for Problematic Information (p. 22). New York: Data & Society, retrieved from https://datasociety.net/library/lexicon-of-lies/ Pew Research Centre. (2020). “Differences in how Democrats and Republicans behave on Twitter”. (2) Rogers, R. (2020). Research note: The scale of Facebook’s problem depends upon how ‘fake news’ is classified. Harvard Kennedy School (HKS) Misinformation Review. https://doi.org/10.37016/mr-2020-43 Silverman, C. (2016). This analysis shows how viral fake election news stories outperformed real news On Facebook. Buzzfeed News, November 16. Retrieved from https://www.buzzfeednews.com/article/craigsilverman/viral-fake-election-news-outperformed-real-news-on-facebook. Appendix: Curated list of political keywords and hashtags. Democrat
#democrats, 2020Democrats, BackTheBlueWave, CountryOverParty, DemocraticParty, Democrats2020, Dems, NotMeUs, TowardsADemocraticPartyICanTrust, VoteBlue, VoteBlueNoMatterWho, VoteBlueNoMatterWho2020, VoteBlueToSaveAmerica, WelcomeToNotMeUs, democrats, thedemocrats
Republican
#gop, gop, republicans, #republicans, VoteRed, VoteRed2020, VoteRedToSaveAmerica, VoteRedToSaveAmerica2020
Biden
#biden, #joebiden, ‘joe biden’, Biden2020, BidenBounceBack, BidenForPresident, BidenHarris, BidenHarris2020, BidenBeatsTrump, JoeBiden2020, JoeMentum, Mojoe, QuidProJoe, RidinWithBiden, TeamBiden, TeamJoe, WeKnowJoe, biden, joebiden
Trump
#trump, ‘donald trump’, BlackVoicesForTrump, CubansForTrump, DonaldTrumpjr, KAG, KAG2020, KAG2020LandslideVictory, KeepAmericaGreat, MAGA, MAGA2020, MAGA2020Landslide, PresidentTrump, PresidentTrump2020, ReElectPresidentTrump2020, TWGRP, Trump2020, Trump2020Landslide, Trump2020LandslideVictory, trump
DACA
daca
Green New Deal
greennewdeal
Medicare
medicareforall, medicare4all


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback