Exploring neo-nationalism through Knowledge Graph
Team Members in alphabetical order
Sara Abdollahi Agustin Ferrari Braun Jasper van der Heide CristinaContents
1. Introduction
Since the beginning of the century, European integration has accelerated itself. The European Union emerged as a community of nations that provides unity to a historically conflictive continent. This unity is reflected in the vast amounts of multilingual information being produced around certain events. The EU-funded project CLEOPATRA is currently attempting to develop new ways of processing and presenting cross-lingual information in an insightful and easily accessible manner (“CORDIS | European Commission”, 2020). During the 2020 Winter School organized by the Digital Methods Initiative at the University of Amsterdam we had the opportunity to collaborate with PhD student Sara Abdollahi in one of the aspects of this project, the development of software Event KG.
Event KG is a multilingual knowledge graph that covers 690 thousand contemporary and historical events and over 2.3 million temporal relations extracted from several large-scale knowledge graphs and semi-structured sources. As it stands right now, Event KG browses pre-existing semantic databases, like Wikidata and DBpedia, for linked data. The results are then indexed by the mutual relations of each entity, following the Resource Description Framework (RDF). The overall goal of this software is to provide a tool for cross-cultural studies that allows researchers to analyze language and community specific elements on historical and contemporary events.
To test the viability of EventKG we decided to focus on the surge of neo-nationalist ideas in Europe. The recent election of Boris Johnson in the United Kingdom, the stable rule of Viktor Orban in Hungary and the growing popularity of figures like Marine Le Pen and Matteo Salvini are but examples indicating the urgency of the topic. Moreover, from a procedural perspective, this political science question provides a frame encompassing all of Europe while, at the same time, being highly dependable on national contexts. All the aforementioned leaders can be classified as neo-nationalists, but their particular brand of neo-nationalism is intrinsically tied to the history of their respective countries (Taylor 2016). Therefore neo-nationalism lends itself particularly well for an evaluation of EventKG.
The first hours of our group work were devoted to find a specific research question that could structure our activity over the course of the week. We finally decided to study how neo-nationalist populist parties are characterized in Wikipedia across languages. This research question contains a number of choices. The first one was to center our efforts around political parties. As Peter Mair (2013) argued, parties still are the basic unity of European political life, which makes them the most interesting element to research. We also decided to focus our efforts in populist neo-nationalist parties. We did so because those parties have structured their entire ideology around nativist conceptions, in a way that more traditional parties have not (Mudde, 2009). Boris Johnson and Marine Le Pen are both neo-nationalist leaders, but the British Conservative Party is not ontologically neo-nationalist, whereas the National Rally is. Lastly, the choice of Wikipedia was motivated both for its value to analyze ongoing events (Gottschalk et al. 2017) and its large and accessible semantic databases.
The aim of the project was to test EventKG rather than to obtain a comprehensive answer to the research question. Our collective effort during the Winter School aimed at providing constructive criticism for the software. This report will therefore focus on assessing the viability of EventKG for research in social sciences. We will start by detailing our methodology and the software. We will then engage with the results that it produced, assessing its strengths and weaknesses as a research software for social sciences. Finally, in the discussion section, we will outline some of the ways in which it could be improved in the future.
4. Methodology and initial datasets
Qualitative Reading of the Wikipedia pages
The research started with a close reading of the wikipedia pages of neo-nationalist populist parties that would be later analysed by EventKG. This initial step had two purposes: on the one hand, it allowed all the members of the group to be familiar with the studied parties. On the other, it provided us with precise knowledge about the Wikipedia pages’ content, which we then used to asses the data yielded by EventKG.
Our original plan was to cover up to 11 parties across Europe, from Spain to Poland (fig. 1). However, as we started to work with EventKG, we realised that it would be better for us to narrow our focus. We finally chose four parties: the Italian Lega, the French NR, the British UKIP and the Austrian FPÖ. This selection was designed to be representative of different neo-nationalist populist parties. Each one of these parties is a different type of actor, ranging from single-issue parties (UKIP) to institutions rooted in national politics since the Cold War (FPÖ); and from regional-turned-national factions (Lega) to unified parties with politically divergent regional branches (NR).
We read each party’s page in English, Italian, French and German. The choice was based on the available languages on EventKG and the skills of the different people in the group. English, Italian and French were chosen as the group members were proficient in them. Two of the group members had basic notions of German, so it was chosen as a test, to see whether EventKG was able to produce usable results for researchers that did not speak the language of the original data. German articles were read by said two members who parsed them out together.
| English party name | Country |
| Freedom Party of Austria (FPÖ) | Austria |
| National Rally (NR) | France |
| Alternative for Germany (AfD) | Germany |
| Fidesz | Hungary |
| Lega | Italy |
| Brothers of Italy | Italy |
| Forum for Democracy (FvD) | Netherlands |
| Party for Freedom (PVV) | Netherlands |
| Law and Justice (PiS) | Poland |
| Vox | Spain |
| UK Independence Party (UKIP) | United Kingdom |
Table 1: Populist parties selected for qualitative reading on Wikipedia in the research’s initial stages.
EventKG
A script provided by the CLEOPATRA project was used to get data from the EventKG dataset. This script uses SPARQL to retrieve the RDF tuples from the projects website and then Python to convert it to a csv-file. This script had to be used for every party in every language. The resulting file consists of the source node (in this case always the queried political party), the target node and the weight attributed to the edge. The weight is based on the number of semantic relationships in EventKG and the number of co-mentions of the entities on Wikipedia.
The csv files produced by the script contained a lot of possible duplicates due to slight differences in Wikipedia’s articles across languages. For example, both “Labour Party (UK)” and “Labour Party” were present with the same weights. Elections also tended to appear twice, for instance “2016 United States presidential election” and “United States presidential election, 2016”. Finally, many duplicates were present because some nodes contained uppercased characters, while others had the same name, but completely lowercase. All nodes containing the name of another node with the same weight were removed to improve the results’ clarity, with those differing between lowercase and uppercase removed manually. Despite our best efforts, some duplication was still present in the final results, particularly in the cross-language comparisons, where the differences between articles’ names were more flagrant.
The final visualisations were produced through Gephi and RAWgraphs. Gephi was used to deploy networks mapping the overlap of terms in different languages in relation to each one of the parties (figs 1, 2, 3 & 4). The position of the nodes was determined by overlaps of different languages over the same entities. This topological distribution created overlapping zones containing the terms that were systematically used to describe the party cross-lingualy, as well as isolated zones containing culturally-specific terms appearing exclusively in one language. RAWgraphs was used to create circular packings that reflected the entities that had over 100 co-mentions in each language (fig. 5). A further network combining all parties and all languages was projected in our research plan. Such visualization would have been useful to map the overall conversation surrounding neo-nationalism in Europe. However, due to time limitations, it was not possible to create it. In the following section we will analyse some of the findings that we were brought up by those visualisations.
6. Findings
The data provided by EventKG allowed us to obtain quantitative evidence to support arguments that originally used qualitative data, as well as new elements for potential future research. Additionally, no frictions between languages arose, proving that it can be used for cross-lingual analysis. However, the results also showed some of the software’s bugs and shortcomings.
The network visualisations presented a considerable polarisation in each party’s native tongue, which can be explained by the wealth of information produced around the party in their own language. The overlapping zones were dominated by authoritative figures within the party (either their current or former leaders), geographical areas and elections. Interestingly, there were very few mentions to ideological positions or specific events besides elections in those zones, with “populism” and “euroscepticism” usually taking the lead. Two parties, the Lega and the NR (figs. 1 & 2), displayed separate overlaps between their native language and each one of the others, while FPÖ and UKIP (figs. 3 & 4) had more homogeneous results across languages.
The results of the networks were then confirmed by the circular packings. Leading figures and national spaces were by far the more popular entities. As it was to be expected, each language leaned towards its national entities. Italian was particularly self-centered, with only one foreign entity foreign, “Marine Le Pen”. On the other end of the spectrum, the English bubble presented more variety and contained German, French and Italian elements. While leaders from the Lega, UKIP and NR featured in all bubbles, interest for the leadership of FPÖ was remarkably low. Even in the German bubble the historic leader of the party, Jörg Haider, was virtually tied with Marine Le Pen. That being said, party leaders were largely overrepresented in that bubble as well.
It is worth noting that over the course of the research we did not find any problems with German language. Both the German areas in all four graphics and the German bubble in the circular packings largely corresponded with what we observed in our qualitative reading. EventKG ’s translation mechanism, based on Wikipedia’s versions of the same article in different languages, worked without issues. Considering the software’s goal of becoming a cross-lingual tool for research, the ease with which we worked in a foreign language is nothing short of a victory.
The dominant presence of charismatic figures in both networks and circular packings is far from anodyne. According to political scientist Cas Mudde, the authoritarian tendencies that form the backbone of populist parties are crystallized in collective following of a charismatic leader. This following combines submission to the leader’s personality, aggressiveness towards those who criticize them and a firm conventionalist belief in the importance of order (Mudde, 2009, 22 - 23). The data provided by Mudde to support this assertion was qualitative, based on a close reading of the party’s literature (37 - 38). Our quantitative data would tend to confirm his assertion: party leaders (both current and historical) dominate the conversations, way ahead of any concrete policy or ideological position. While these individuals enjoyed a privileged position within the network, any other person affiliated to the party was relegated to a more discreet position. Mudde’s hyper-leadership hypothesis is strengthened by our findings.
Culturally-specific narratives can also be explored through the results produced by EventKG. For instance, the NR network presents a number of interesting entities. On the one hand, the exclusively French side of the graph features a number of rather niche historical references, many of which are associated with far-right nationalist cosmogonies. For instance, “War in the Vendée”, an episode of the French Revolution that ended with widespread repression of royalist forces, or “Siege of Orleans”, an iconic French victory in the Hundred Years’ War (Richard, 2017). That being said, there are also a number of events that reflect negatively on the NR, such as the protest song “Un Jour en France” or “1983 March For Equality and Against Racism”. On the other end of the graph, there are a number of entities that are not mentioned in French and whose exclusion is also interesting. “Jean Vallette d’Osia”, a hero of the French Resistance and known sympathizer of the NR, is only mentioned in English and Italian. From a purely exploratory perspective, the different entities in this graph and their topological position provide a number of clues for a researcher interested in the construction of historical memory in France.
The results provided by EventKG proved to be useful, both to analyse existing arguments and to explore new research avenues. That being said, they also displayed bugs and errors. As we engaged with the networks in detail, we realized that a number of entities appeared in different languages independently, without connections to each other. Instead of being central nodes at the intersection of all languages, they were peripheral in each one of them. For instance, “European Migrant Crisis” appears four times in the Lega visualization, without any cross-lingual connections. The absence of the crisis in the Lega’s overlapping zone immediately captured our attention, as it was largely referenced in the party’s articles in all four languages. Had it not featured in that zone, it would have triggered a number of reflections on the way in which Wikipedia indexes information. Alas, it was a misleading mistake.
The circular packings visualization also show a number of odd results. The English bubble displays a similar level of interest for “Nigel Farage”, a major political figure in the United Kingdom, and “Liga Veneta”, the regional chapter of the Lega. The region “Veneto” also appears as one of the most mentioned elements, significantly ahead of “Brexit” or any general election. Similarly, “2015 French Departmental Elections” are the third most mentioned element in French bubble, considerably ahead of the other entities. Considering that over half of the electorate abstained during that election, it is hard to determine why it would be more relevant than a general election.
EventKG is still in early development process. These mistakes were to be expected; our work during the Winter School was to identify them and propose solutions and new features that could be added to the software. Our ideas will be explored in the following section.
6. Discussion
The results produced by EventKG indicate that the tool can be useful in different stages of the research process. However, the visualizations also indicate a number of important issues with the software that need to be solved before it can be reliably used by scholars.
Issues related to weighting were particularly salient during the exploration of the results. The clearest example of this was the overrepresentation of “Liga Veneto” and “Veneto” in the English results, as described in the Findings section. We could not find a definitive answer as to why these entities were so heavy in the final results. Some semantic databases on which EventKG is based were checked, but we found no high numbers of relationships. Therefore, we suspect that the number of co-mentions is the source of the heavy weight. We recommend re-evaluating the metric, in particular the influence of the co-mentions, and eventually fine-tuning it.
Besides fine-tuning EventKG ’s weighting, it would be useful to have more transparency around the linking between entities. So far the software does not provide an easy way to qualitatively research the relationships that brings forward. A number of steps could be taken to improve this. First of all, it would be useful to grant access to the semantic relationships that EventKG uses to create its connections. This would allow researchers to see the precise nature of the link between two entities. Likewise, providing with an easy way of accessing the co-mentions that partially determine the weight of the relationship would create a contextualisation tool within the software itself. By fine-tuning the weighting system and improving its transparency, EventKG would lend itself more easily to qualitative research and improve its credentials as an exploratory tool.
As the visualizations make clear, EventKG associates a very large number of entities, which makes it difficult to analyse them in detail. The software’s very high granularity is one of its main assets, but it can also be a liability, as it makes spotting and analysing patterns at first glance almost impossible. To make results more accessible, it would be useful to provide more detailed information about the entities’ relationship. Information regarding the RDF type of each entity is already available in EventKG ’s database, but it is not displayed in the final outcome of a query. Systematically including it in the final results would allow for a number of measures that could improve clarity. It would allow filtering results and only explore one specific category in the ongoing conversation. Filtering out all results but historical events in the NR graph would be very useful for the type of exploratory use of EventKG that was proposed in the Findings section. Likewise, it would enable more precise visualizations that take into consideration other factors than the relevance metrics in the clustering of entities.
Finally, we would like to close this section with a consideration on duplicates. As mentioned in Methodology, the removal of duplicates was an important part of our research process. We did so because, at the time, we believed that this was an error in EventKG. Only near the end of the project we found out that it was most likely an error in the SPARQL script. The script gathered all the labels, while entities could have multiple labels, and thus created the duplicates. EventKG should therefore use an improved SPARQL script that avoids duplicates.
Overall, the main avenues for improving EventKG are related to its RDF and the overall indexation of results. Our three main recommendations are (1) fine-tuning the weighting system, (2) increase its transparency exponentially and (3) mobilising all the relationships between entities that EventKG already has in the final results. An improvement of the SPARQL script would also be advisable, although it might depend on the central CLEOPATRA project rather than the EventKG development specifically, since it was the general project that provided with the script.
7. Conclusions
EventKG is a promising tool that is already capable of presenting interesting and detailed results after only a few months of development. First and foremost, it allows for cross-lingual comparisons in languages that are not mastered by the researchers. By doing so, it already fulfills part of the CLEOPATRA project’s goals. The results that it provides also are very interesting. Although we could not obtain a definitive answer to our research question, we did manage to gather data supporting some arguments from the field of political science and to identify new elements for other research. We also managed to identify a number of bugs and issues with the software which can be solved over the course of the next few months. Considering that the overall goal of our research project was to test EventKG rather than to answer a specific question, we can say that the Winter School was productive and provides avenues for further research. According to Sara, she will be back in the Summer School to test EventKG again; we look forward to seeing how the software evolves between now and then.8. References
CORDIS | European Commission. (2020). Retrieved January 22, 2020, from Europa.eu website: https://cordis.europa.eu/project/id/812997
Gottschalk, S., Demidova, E., Bernacchi, V., Rogers, R. (2017). “Ongoing Events in Wikipedia: A Cross-lingual Case Study” in WebSci '17: Proceedings of the 2017 ACM on Web Science Conference. pp. 387–388.
Mair, P. (2013). Ruling the void : the hollowing of Western democracy. Verso: London
Mudde, C. (2009). Populist radical right parties in Europe. Cambridge University Press: Cambridge
Richard, G. (2017). Histoire des Droites en France (1815 - 2017). Éditions Perrin: Paris.
Taylor, R. (2006) “Brexit, Trump and the new nationalism are harbingers of a return to the 1930s”. Retrieved January 22, 2020, from the London School of Economics website: https://blogs.lse.ac.uk/brexit/2016/09/20/brexit-trump-and-the-new-nationalism-are-harbingers-of-a-return-to-the-1930s/Appendix
Appendix A: Figures
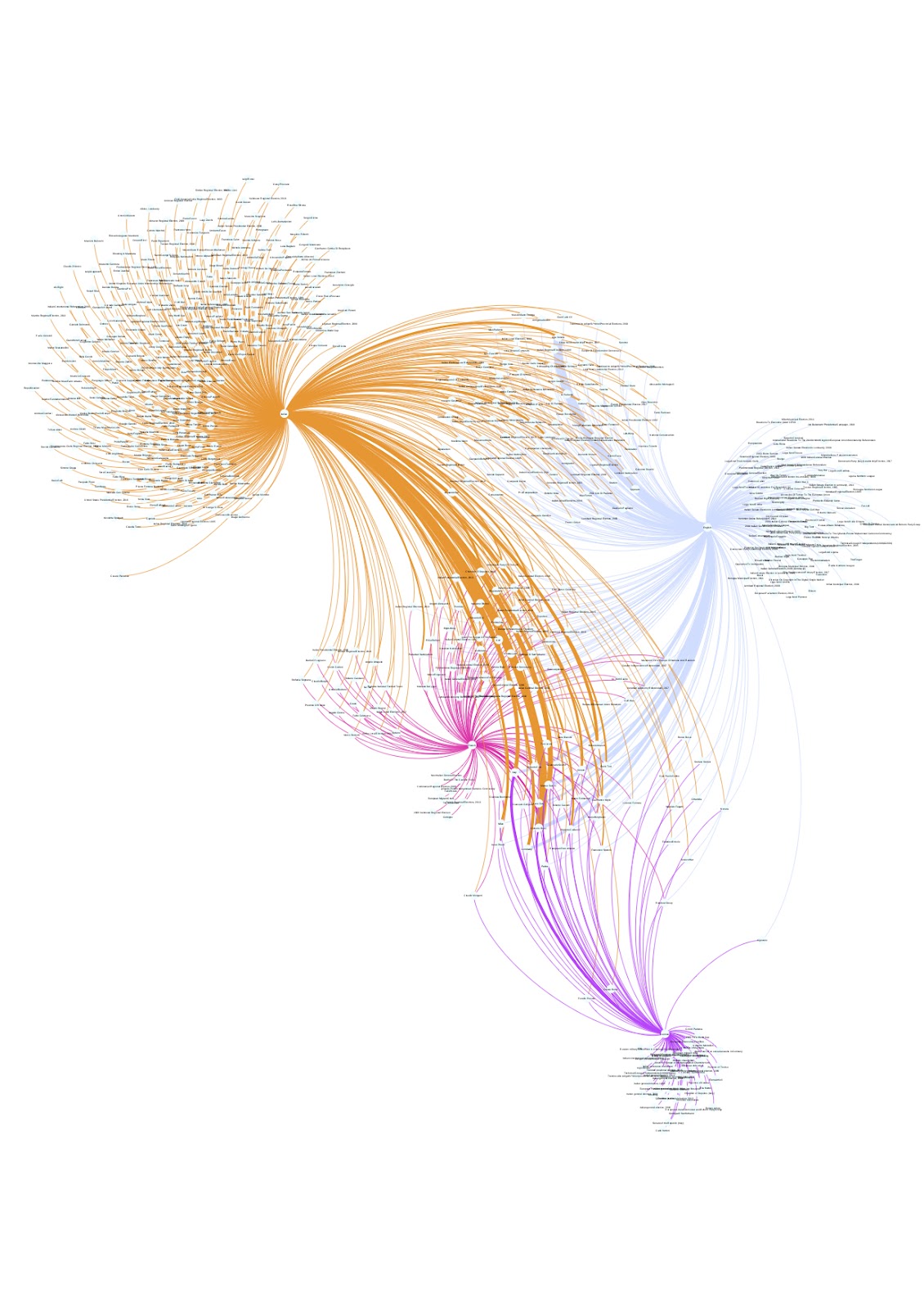
Figure 1: EventKG links in French, German, English and Italian for Lega Nord.
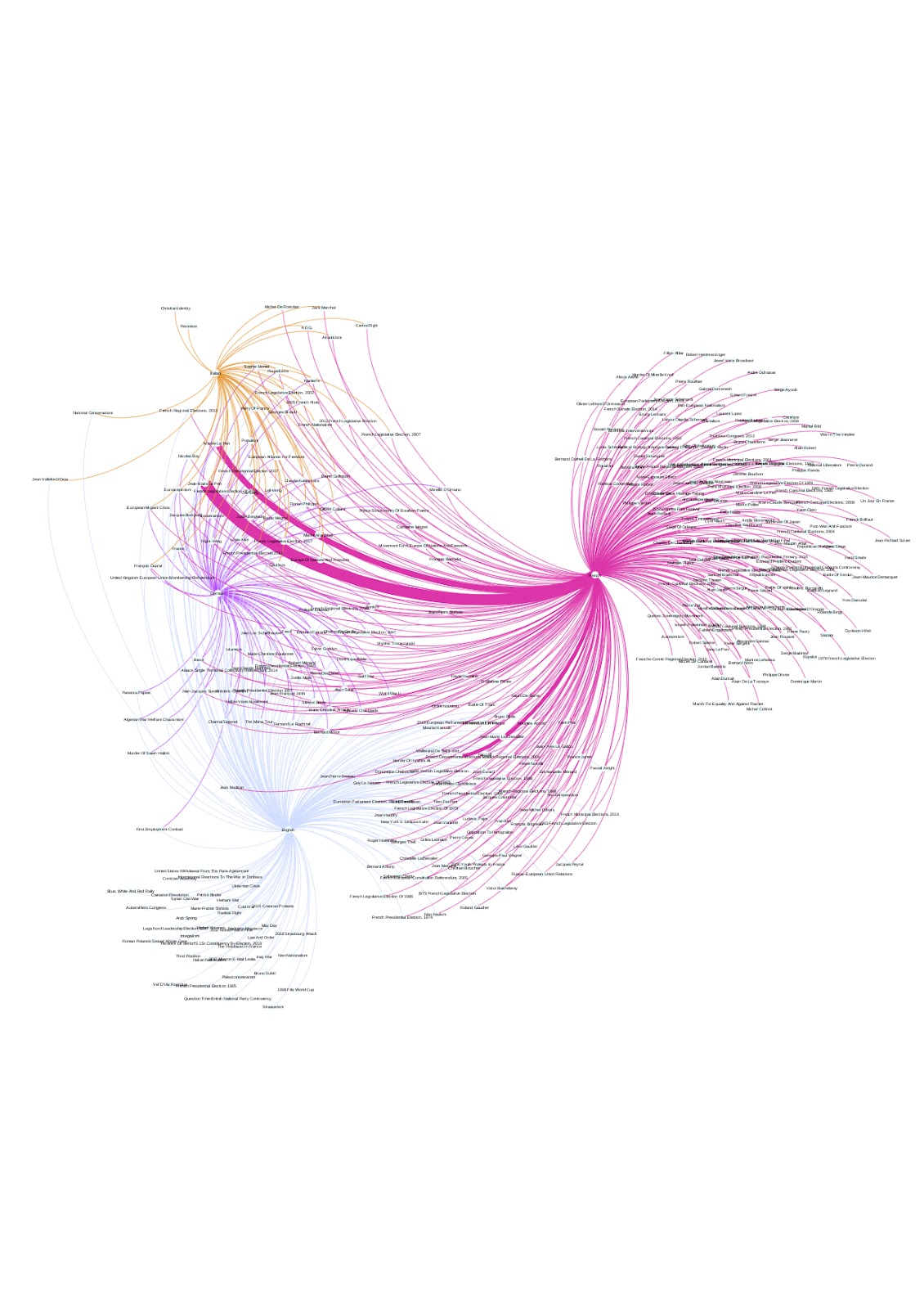
Figure 2: EventKG links in French, German, English and Italian for National Rally..
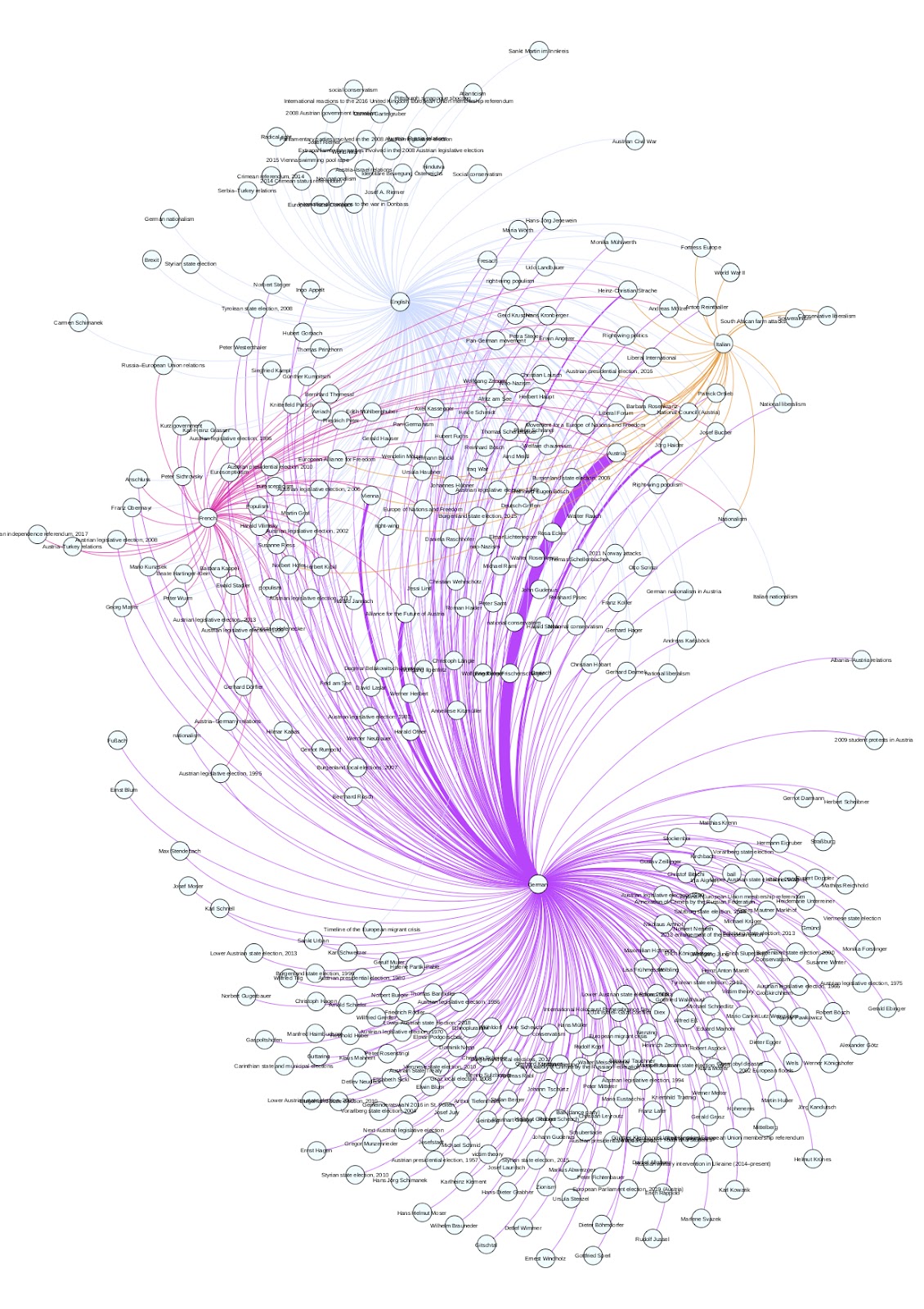
Figure 3: EventKG links in French, German, English and Italian for FPÖ..

Figure 4: EventKG links in French, German, English and Italian for UKIP.
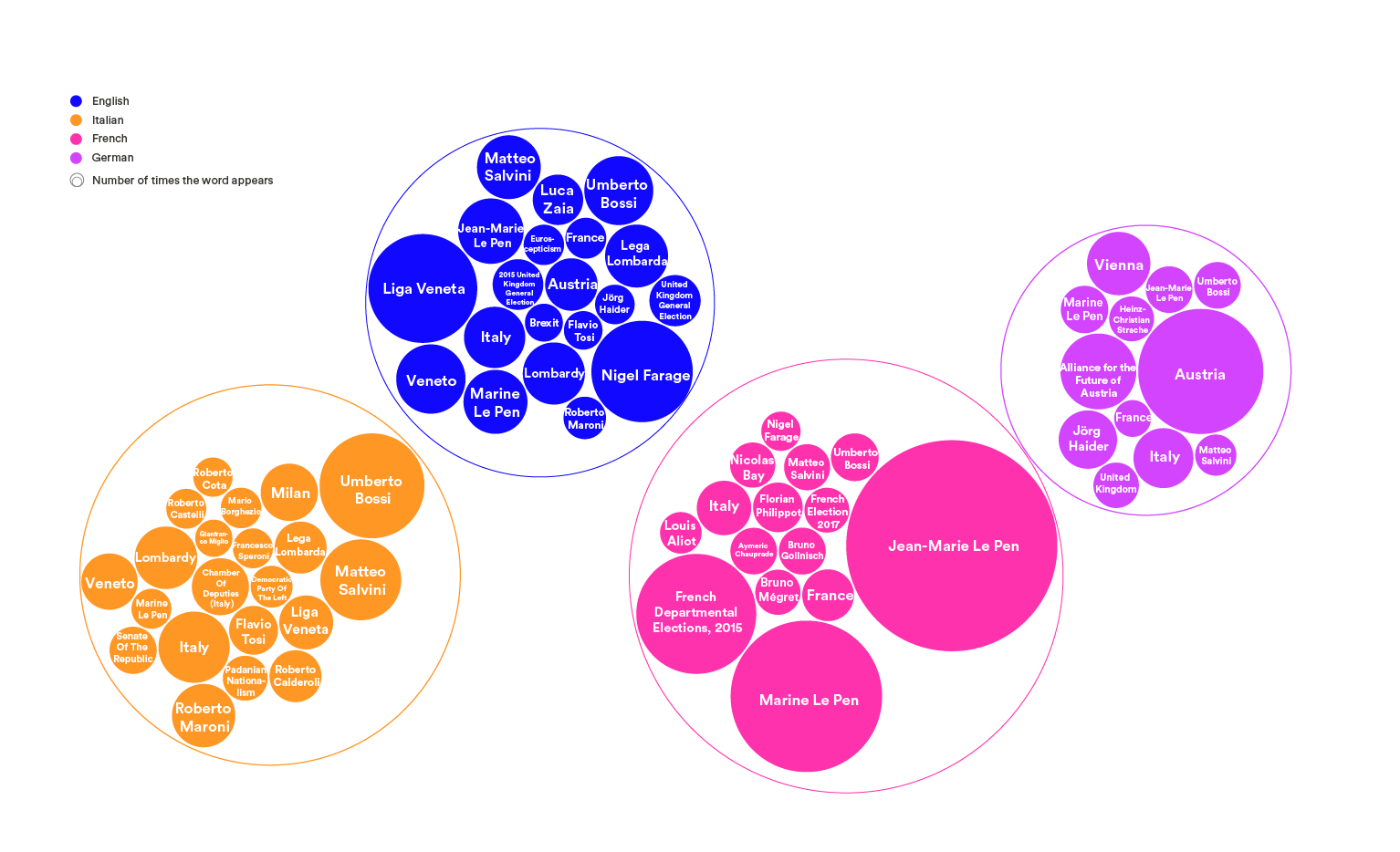
Figure 5: Circular packings containing all words with over 100 co-mentions per language
Ideas, requests, problems regarding Foswiki? Send feedback