Iran's Disinformation Campaign
Developing Detection Metrics for SophisticationTeam Members
Alessio Sciascia, Cassidy Jewell, Joris van Breugel, Ouejdane Sabbah, Rama Adityadarma, Reza Mohammadi, Sara Creta, Vic KrensSummary of Key Findings
-
Top 8 users contributed to almost 50% of tweets. These users qualified as "suspect" in most of the metrics that we identified as methods of detection.
-
A majority of users scored "non-suspect" in their discretion and account integrity metrics.
-
In a qualitative analysis of some of the data, we found that there are reasons to doubt the legitimacy in suspending some of the accounts. e.g. 110 out of 660 suspended accounts does not have any activity and content in the database.
1. Introduction
In August of 2018, FireEye —a company specialized in cybersecurity— released a 28-page report claiming that they had "identified a suspected influence operation that appears to originate from Iran aimed at audiences in the U.S., U.K., Latin America, and the Middle East", promoting political narratives in line with Iranian interests. These interests include "anti-Saudi, anti-Israeli, and pro-Palestinian themes, as well as support for specific U.S. policies favorable to Iran, such as the U.S.-Iran nuclear deal (JCPOA)" (“Suspected Iranian Influence Operation Leverages Network of Inauthentic News Sites & Social Media Targeting Audiences in U.S., UK, Latin America, Middle East « Suspected Iranian Influence Operation Leverages Network of Inauthentic News Sites & Social Media Targeting Audiences in U.S., UK, Latin America, Middle East,” n.d.). According to this report, a part of the operation was executed through Twitter, using hundreds of different accounts that are registered using Iranian phone numbers. In October 2018, Twitter announced that they have "removed 770 accounts engaging in coordinated behavior which appeared to originate in Iran" (Harvey & Roth, n.d.). Two weeks later they released a dataset containing the account information and tweets of these 770 account, in order to "enable independent academic research and investigation" (Gadde & Roth, n.d.).
FireEye compared the operation with the accused activities of Russia, using social media platforms Facebook and Twitter as a propaganda tool. While Russia were previously reported in the news for their inference in American politics using their infamous troll farm, Iran is now also cited for having its own troll farm. FireEye has claimed that they have discovered over 700 false profiles from Iran that were disguising themselves as being Americans and are being active on various social media including Twitter (FireEye, Inc., 2018). The profiles are usually linked to misleading news sites where pro-Iranian political views are promoted that are in line with the Tehran regime. As stated earlier research has revealed that the same tactics as those used by the Russians are used to achieve different geopolitical goals (FireEye, Inc., 2018). However, while the Russians are usually trying to pretend to be conservatives, the Iranians are mainly disguised as progressives, who show a preference for Bernie Sanders and share messages that are critical of Donald Trump, Saudi Arabia and Iran’s main enemy, Israel. However, it does not appear that the Iranian activities are intended to influence the coming elections in United States or any other country. On the one hand, it is true that some messages that were posted to American users radiated 'left-wing' sympathies (FireEye, Inc., 2018). But on the other hand, the report does not give a definite answer to the question whether the Iranian government is behind the trolls, although FireEye states that it is unlikely that the operation could be run without government funding.
Other analysts have stated that the disinformation campaign by the Iranian government is “unsophisticated” compared to the Russian troll farms (Leprince-Ringuet, 2018). Therefore, we decided to design a set of metrics to evaluate the sophistication level of a campaign on Twitter, in order to assess the claim about the Iranian campaign being unsophisticated, and also to develop an automated tool to be able to perform the same evaluation on a similar dataset very quickly.
2. Initial Data Sets
We use the publicly available, but hashed, datasets of 1.122.863 tweets published by Twitter of accounts suspended due to suspicion of involvement with the disinformation campaigns claimed to be perpetuated by the Iranian Government. The dataset was accessed through a dedicated TCAT server provided by the organisers of Digital Methods Winter School and Data Sprint 2019.3. Research Questions
How sophisticated was the Iranian disinformation campaign? How can one identify the level of sophistication?4. Methodology
In order to evaluate sophistication within the disinformation campaign, we develop detection metrics that function as indicators. These detection metrics include Discretion, Automation, Media Infrastructure, Account Integrity, and Coordination. Discretion scores are evaluated according to the account's consistency in their use of language in relation to their location, chosen language on the Twitter's interface, and their period of activity in relation to Iran's timezone. Automation evaluates the account's activity by looking at the repetition of tweets and whether the account tweet within an improbable frequency (e.g. five tweets in one second). Media Infrastructure look at the legitimacy of sources shared by the accounts. Account Integrity is scored by looking at the accounts' description, account's age and whether the account has undergone a name change over the period if the datasets. Finally, coordination score looks at whether the account is tweeting, retweeting, and/or mentioning the same content as other accounts as well as linking similar sources to other accounts within the datasets. These metrics are evaluated both quantitatively and qualitatively. Qualitative analysis of the dataset was done by doing a close reading of 17 randomly chosen accounts within the period of 2014-2015 to be compared with the automated results. For every metrics that were evaluated the value of "Yes" or "No" were given to show the degree of sophistication that the account has assuming that they are participating in the campaign. The mean value of the score for every metrics was evaluated to identify whether the metrics are effective in detecting sophistication. Metrics with the mean response of "yes" under 50% were classified as "suspect" which means that the metric shows a lower level of sophistication in the campaign.
These metrics are evaluated both quantitatively and qualitatively. Qualitative analysis of the dataset was done by doing a close reading of 17 randomly chosen accounts within the period of 2014-2015 to be compared with the automated results. For every metrics that were evaluated the value of "Yes" or "No" were given to show the degree of sophistication that the account has assuming that they are participating in the campaign. The mean value of the score for every metrics was evaluated to identify whether the metrics are effective in detecting sophistication. Metrics with the mean response of "yes" under 50% were classified as "suspect" which means that the metric shows a lower level of sophistication in the campaign.
 Meanwhile, an automated machine learning protocols were developed according to the twelve metrics using the programming code python. For every metric, the score of 0-1 was assigned accordingly. Findings from the automation processes were compared with findings from the close reading processes to validate whether the metrics are relevant and works according to the purpose of the research. Finally, results were visualized in the form of scatter plots diagram.
Meanwhile, an automated machine learning protocols were developed according to the twelve metrics using the programming code python. For every metric, the score of 0-1 was assigned accordingly. Findings from the automation processes were compared with findings from the close reading processes to validate whether the metrics are relevant and works according to the purpose of the research. Finally, results were visualized in the form of scatter plots diagram. In addition, a co-network analysis was also done by looking at eight top posters on the dataset. Data of networks relation from a random day and days with peak of tweeting activity the was downloaded from the TCAT servers and was visualized using the software Gephi for analysis.
5. Findings
Close-reading qualitative analysis results
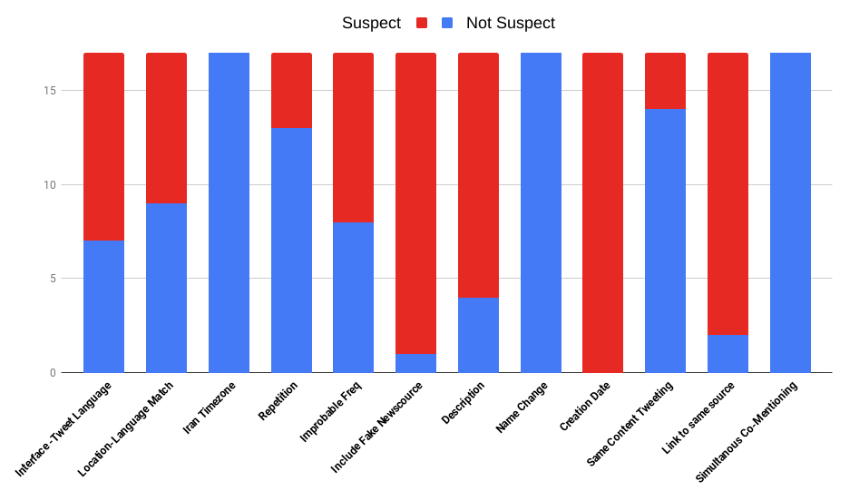
Upon doing a close-reading qualitative analysis of 17 randomly chosen users within the 2014-2015 period, we found that five out of 12 of the metrics are "suspect". Accounts that are found to be "suspect" according to the metrics means that the account has a low level of sophistication in their participation with the disinformation campaign, consistent with the findings from the FireEye report. These "suspect" metrics include inconsistency in the interface and tweet language, tweets in an improbable frequency, the inclusion of URL from fake news sources, suspicious account description, and linking same sources with other accounts within the dataset. These results tell us that while the other metrics are still useful in helping us detect evaluate levels of sophistication of a disinformation campaign, these five metrics are especially useful in helping us detect the sophistication level of a disinformation campaign on Twitter.
Through qualitative analysis, we also found that there are accounts that do not exhibit obvious campaigning behavior within the suspended account datasets. Initial findings from the datasets suggested that almost 50% of the tweets were posted by eight accounts. While on the one hand the statistics points to a possible organised campaign, on the other hand it could also lead us to question the reasoning for banning the rest of the accounts. This includes accounts that have only three or four tweets, and even accounts that do not have recorded tweets in the dataset. Within the datasets we found at least 110 accounts that do not have any tweets, meaning that there is no obvious content-related evidence which the account suspension was based on. While this does not prove wrongful suspension, further analysis and possibly research might be useful to improve accuracy of possible similar suspension of suspected disinformation campaigns in the future.
In addition, we found several accounts that exhibit suspicious behavior, but nevertheless do not fall into the suspect category upon doing a close-reading. One example is the account @real_iran that posted daily Iran-related articles with topics ranging from tourism, politics and social life. By looking at the account using the 12 metrics we developed, we did not find any indication that the account is automated or that it is openly campaigning within the disinformation campaign. That being said, the account did posted several pro-Iranian post including criticism towards the Israeli government and support towards the Palestinians. Nevertheless, we did not find strong evidence that points towards involvement of the account in the disinformation campaigns. This could mean that either the account used very sophisticated campaigning techniques, or that there is inaccuracy in Twitter’s decision to ban some accounts in the dataset.
Automated Quantitative Analysis Results
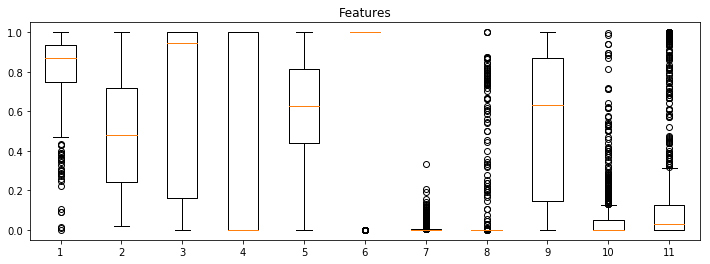
The mean value for the following metrics were higher than 0.5 for the dataset: 1. Account creation date, 3. Interface vs. tweet language, 5. Density of the hours an account was tweeting, 6. Improbable frequency, and 9. High number of retweets.
At the end of this step we understood that the scores were relatively sensitive to their definition, and an absolute value of 0.5 does not mean the same among our defined dimensions. Different methods of aggregation were suggested to give a single decimal score for every user and the whole dataset, but we didn't agree on a final decision because of the complexities discussed in the next section.
6. Discussion
Some questions were raised while the group started to recapitulate the findings:
Does this dataset belong to a state-funded operation?
One of our assumptions for designing the sophistication metric and testing it on this dataset was that the dataset belongs to a state-funded operation. But some of our observations were not in line with this assumption. For example, we didn't find any official explanation for the 110 accounts which are deactivated by Twitter that have no tweets in the dataset. Furthermore, in the qualitative analysis we found several accounts with no noticeable effort in concealing their relationship with Iran. These observations suggest that maybe at least some of the accounts are not consciously recruited for this "operation", if there is any.
Does this dataset belong to a single operation?
Another set of our observations are related to the uniformness of the activities. By visualizing the correlation of the different categories of the metrics calculated for all the accounts in the dataset, we can see that the behaviour of the users were not similar, and we can distinguish a few subgroups which have behaved alike regarding to the pair of dimensions (categories of metrics), but have scored differently from the other subgroups.

Another observation related to this question is the way the accounts use links to external websites:

While awdnews.com is still an active website, and we can see the accounts were still posting links to this domain in 2018, it seems like the focus of the campaign has changed frequently during the time, if there was only one campaign or "operation" conducted by these accounts.
Another important note about these top 20 mostly linked domains among the dataset is their absence in the FireEye report, with the exception of "libertyfrontpress.com". The FireEye report doesn't say anything about most of these domains which have been pushed by the dataset.
These observations make us believe that a more in-depth investigation is required to understand the nature of the activities conducted by these accounts, and calling it an unsophisticated operation is too much simplification regarding this dataset.
How can we improve the automated tool?
While there are automated tools available for analysing the tweets of a single account and to determine if the account is a bot or not, most notably Botometer by OSoMe and Tweets Analyzer by x0rz, we were not able to find such tool for analysing a campaign which consider the users involved in the campaign and their network as a parameter. Considering the recent open approach of Twitter, sharing the datasets connected to "information operations", it is probable that we will see more datasets released and available for such researches in the future. So, it is reasonable to invest more time on the development such tools.
One area that we believe has room for improvement is the validation mechanism. It was hard to be sure about the unsuspicious behaviour in different categories, because we didn't consider to validate our progress using a random dataset of tweets and Twitter accounts.
Another approach that we discussed, but found undoable in the tight schedule of DMI winter school was to feed the metrics into a recent machine learning algorithm, which is able to find the proper importance and weight for each of the features we measured. Although, for a straightforward solution we still needed to be sure about our assumptions, and also we needed to train the algorithm using both suspicious and unsuspicious datasets, there are unsupervised algorithms that were able to cluster the users based on their behaviour and help us to analyse our dataset more effectively even without a validation dataset.
7. Conclusions
During our research we found that the top 8 users contributed to almost 50% of tweets in the datasets. These top users qualified as "suspect" in most of the metrics that we identified as methods of detection. Meanwhile, the majority of other users scored "non-suspect" in their discretion and account integrity metrics. With our qualitative analysis of some of the data, we found that there are reasons to doubt the legitimacy in suspending some of the accounts. e.g. 110 out of 770 suspended accounts do not have any activity and content in the database. In summary, we found that the majority of tweets within the purported campaign were linked to accounts that were highly suspect and did not use sophisticated measures in their campaigning. Most other users did not represent suspect behavior, which could mean a smaller and more sophisticated campaign, or it needs a deeper look to see if this is really a campaign among these other users.
While working on an automation for the qualitative work we had done, in order to create a tool to give a score showing the level of sophistication of a campaign, we failed to agree on a method of aggregation of the scores into a single score. We discussed different reasons for the doubtful output of the automation step. We questioned our assumptions as well as our fragile method of automation, and we suggested a few areas where we believe are the most important points for improvement.
8. ReferencesElections integrity. (n.d.). Retrieved January 17, 2019, from https://about.twitter.com/en_us/values/elections-integrity.html
FireEye, Inc. (2018). Suspected Iranian Influence Operation (Special Report) (p. 28). Milpitas, USA.
Gadde, V., & Roth, Y. (n.d.). Enabling further research of information operations on Twitter. Retrieved January 17, 2019, from https://blog.twitter.com/en_us/topics/company/2018/enabling-further-research-of-information-operations-on-twitter.html
Harvey, D., & Roth, Y. (n.d.). An update on our elections integrity work. Retrieved January 17, 2019, from https://blog.twitter.com/en_us/topics/company/2018/an-update-on-our-elections-integrity-work.html
Leprince-Ringuet, D. (2018, October 25). Iran has its own fake news farms, but they’re complete amateurs. Wired UK. Retrieved from https://www.wired.co.uk/article/iran-fake-news
Suspected Iranian Influence Operation Leverages Network of Inauthentic News Sites & Social Media Targeting Audiences in U.S., UK, Latin America, Middle East « Suspected Iranian Influence Operation Leverages Network of Inauthentic News Sites & Social Media Targeting Audiences in U.S., UK, Latin America, Middle East. (n.d.). Retrieved January 17, 2019, from https://www.fireeye.com/blog/threat-research/2018/08/suspected-iranian-influence-operation.html


| I |
Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
Screen Shot 2019-01-10 at 4.19.48 pm.png | manage | 31 K | 10 Jan 2019 - 15:21 | RamaAdityadarma |
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback