Exploring the Impact of LLM-powered Search Engines on Political Candidates
Team Members
Facilitators: Claudio Agosti, Margherita Di Cicco, Natalie Kerby, Salvatore Romano, Miazia Schueler, Camilla Volpe Participants: Piyush Aggarwal, Bastian August, Meret Baumgartner, Alissa Drieduite, Franziska Hoolmans, Joanne Kuai, Azzurra Pini, Jasmin Shahbazi, Leda Tortora, Nina WeltLink to Poster:
Please find our poster and visualizations here.Contents
1. Introduction
After the fast adoption of Large Language Models (LLM) following the ChatGPT release last November, many big platforms, such as search engines (Google, Bing) and social media platforms (FaceBook, TikTok), decided to integrate chatbots into their applications. Natural Language Processing (NLP) and other probabilistic models for text generation were integrated into search engines before the release of all the new LLMs, such as the common auto-complete feature. Nevertheless, the integration of search engines with LLMs is described by Google and Microsoft in 2021 as a “milestone for understanding information” that could “massively improve search relevance”. Even if this new User-Interface paradigm seems to be a significant competitive advantage, new concerns are rising about the impact on information quality regarding political information, particularly in sensitive contexts such as elections. The question remains open: Now that chatbots are becoming search engines — to what extent can we trust their results?
This project aims to investigate how LLM-powered search engines function and how they might shape the perception and information retrieval of different political candidates, as such systems are known to perpetuate bias. Hence, our concern is rooted in the assumption that LLMs and LLM-based search engines could act as a filter between citizens and their perception of public discourse and hence the landscape of political campaigning or societal controversies. Due to the inherently encoded biases of such technologies and the prejudice and even discrimination they perpetuate, this research aims to shine light on the risks of fostering a culture of over-reliance on such information sources, the reproduction of potentially harmful misinformation, and its globally impactful consequences. Through prompt design, we investigated how the search outputs might vary according to a set of different parameters, including user IDs, geolocation, languages and several personalisation settings.
We take Bing Chat as our case study, the LLM chat bot produced by Microsoft Bing. Bing Chat is of particular interest because at the time of this research, it was the most widely accessible LLM that is directly linked to a search engine feature. Chat GPT-4, for example, only can pull information up until 2021, whereas Bing Chat conducts a live search through Bing’s search engine to provide up to date results. Further, Bing Chat provides sources to back up its responses, enabling us to conduct a source analysis.
2. Research Questions
By undertaking a comprehensive examination of the impact of LLM-powered search on political candidates, this project seeks to provide valuable insights into the evolving nature of political campaigning in the digital age and how LLMs shape public opinion and electoral outcomes, producing broader societal consequences and posing a threat to a democratic access to information. Hence, our research questions are:
-
How do LLM-powered search engines remediate information about political candidates? In particular, which types of sources do they prefer when providing information about political candidates?
-
What is the role of personalization in Bing Chat, if any? Do different settings of geolocation and languages affect the responses?
-
How does information and source quality vary across different languages, especially for non-English user settings?
3. Methodology and initial datasets
Initially, we wanted to record and compare how differently the same question gets answered, to then conduct a qualitative analysis and evaluate the accuracy of the given answers. However, we soon noticed that this methodology was inconclusive and provided limited insights. Hence, our exploration of BingChat followed two axes, one along personalization and the other focused on political candidates specifically. We began with the same approach to each of these lines of inquiry, focusing on prompt design and search settings. We designed our prompts according to a spectrum from factual, to semi-factual/ambiguous, and more controversial questions. In doing so, we hoped to reveal the way that BingChat varies its responses, deals with ambiguity, and how the system might take a stance on more controversial topics. We expected factual questions to provide more factually consistent and unanimous answers and the answers to more controversial questions to be more nuanced and contested. While prompting, we were not logged-in to Bing Chat so that our conversations were ideally unpersonalized. However, this meant that we were limited to five prompts per conversation, at which point Bing Chat nudged the user to log in to continue. For every prompt, we used the same settings to ensure comparability across them. Bing Chat’s conversation style was always set to “precise,” we cleaned browser cookies in between each “conversation” and turned SafeSearch off to allow for unfiltered results.
Case: Indian Elections
We chose to focus on the upcoming elections in India to investigate how Bing Chat surfaces information about political candidates. Narendra Modi (India’s current Prime Minister, Bharatiya Jarata Party) and Rahul Gandhi (Indian National Congress) were the focus of our prompts, two candidates from opposite sides of the political spectrum. Following the spectrum of low to high controversy, the prompts focused on the following topics, with three questions per level of controversy:
Level 1: Factual/Informational
-
What is the title of [Narendra Modi/Rahul Gandhi]?
-
What is the career path of [Narendra Modi/Rahul Gandhi]?
-
What political party does [Narendra Modi/Rahul Gandhi] belong to?
Level 2: Semi-Factual/Controversial
-
What is the educational background of [Narendra Modi/Rahul Gandhi]?
-
What is the position of [Narendra Modi/Rahul Gandhi] on homosexuality?
-
What is the position of [Narendra Modi/Rahul Gandhi] on border issues with China?
Level 3: Highly Controversial
-
What is the position of [Narendra Modi/Rahul Gandhi] on minorities?
-
How does [Narendra Modi/Rahul Gandhi] interact with journalists?
-
What was the stand of [Narendra Modi/Rahul Gandhi] on Farm Laws?
In this case, Bing Chat’s region was set to Netherlands and language to English. We repeated the experiment within Turkey and Pakistan, using political candidates from the respective countries who are similarly polarized politically (Sharif and Zardari, Erdogan and Kilicdaroglu).
Personalization
To explore how Bing Chat responds to personalization, we took two different approaches: that of country and language. For country, we used VPNs to simulate users in the Netherlands, United States, Australia, Taiwan, Brazil, United Kingdom, Israel, and United Arab Emirates. Given that India and Pakistan were unavailable via VPN, but closely related to our prompts, we changed Bing Chat’s region to those countries. We did a second test for the rest of the countries that were available by VPN as well by only setting Bing Chat to their regions to test whether the VPN made a significant difference in the results. Prompt topics focused around India, following the spectrum from less to more controversial:
-
Level 1: geography and population
-
Level 2: founding, official language, elections
-
Level 3: Minority experiences in India, their role in the elections, and the reliability of the elections
We conducted this experiment once more by only changing the region, and translating our prompts into the corresponding languages of the region, namely: Dutch, English (US), Hindi, Portuguese (Brazil), Chinese (traditional), Chinese (simplified), German, French, Italian, and Spanish. We then tested language with a second set of prompts, asking Bing Chat to “tell me about” Narendra Modi, Rahul Gandhi, Luiz Inácio Lula da Silva, and Jair Bolsonaro.
Data Extraction and Analysis
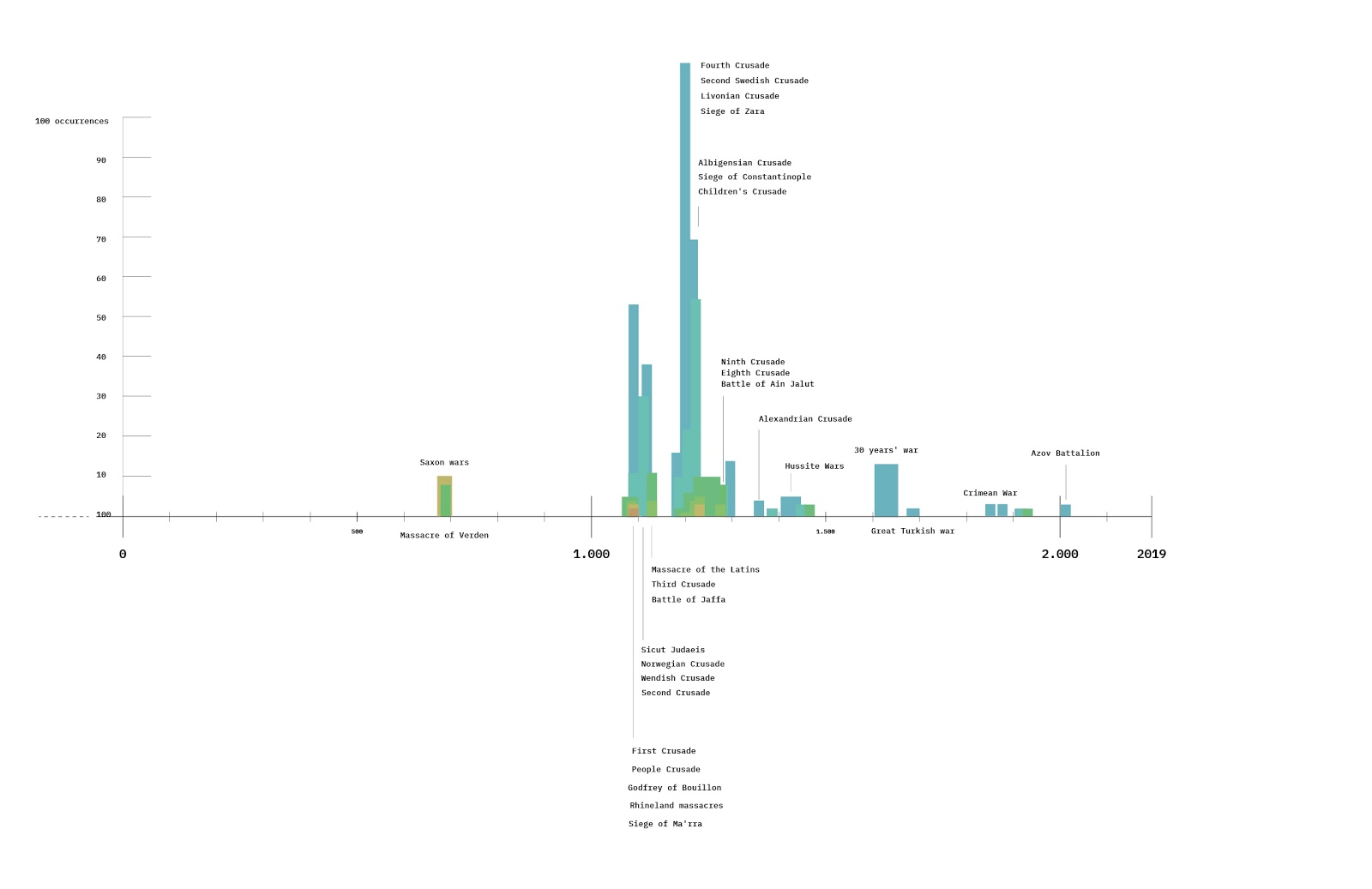
To extract the prompt responses, we used Babbling Computer, an open-source tool developed by AI Forensics, designed to collect chatbot responses. With this tool, each prompt generated three different types of output: the prompt answer itself (text), the sources (links), and a semantic analysis by Dandelion API to identify recurring patterns across common terms, language, and sentiment expressed by Bing Chat. This data was then compiled as a CSV or JSON file. Each prompt was marked with the name of the researcher as well as the title of the respective prompt experiment. This is a crucial feature, which underlines the varying numbers of references/links each of the individual researchers received per prompt (Figure 1).
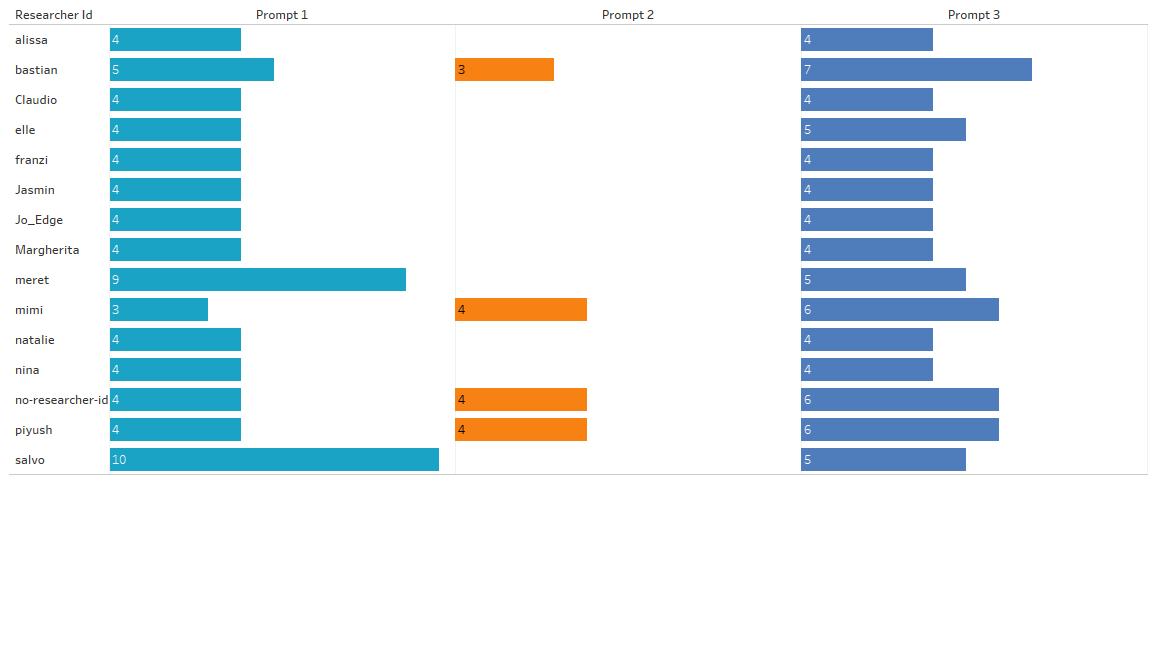
Figure 1: A example of the different number of links returned for the same prompts across researchers.
4. Findings
Across political candidate queries and those that tackled personalization, common themes emerged in our sentiment and source analyses.
Key Findings: Source Analysis
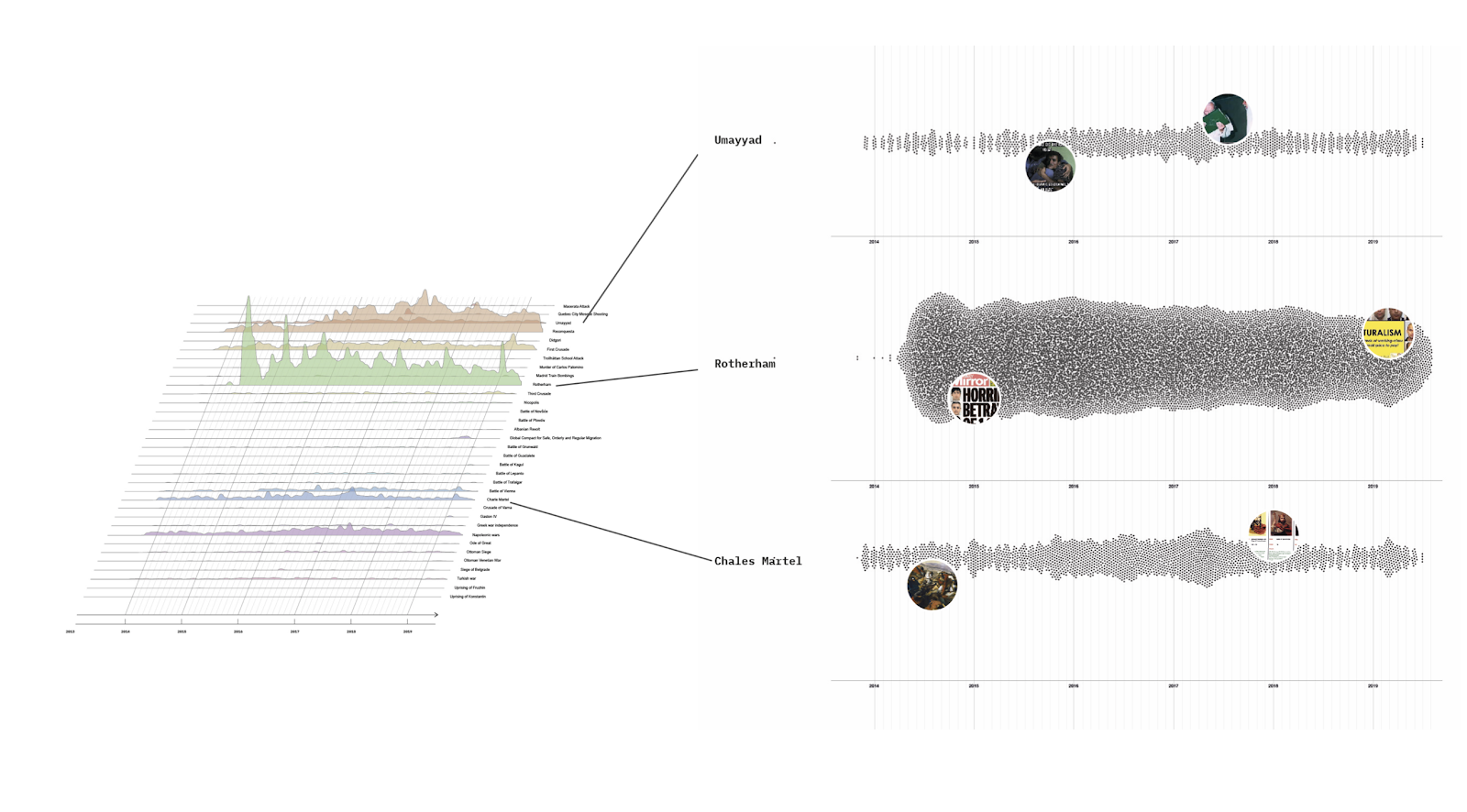
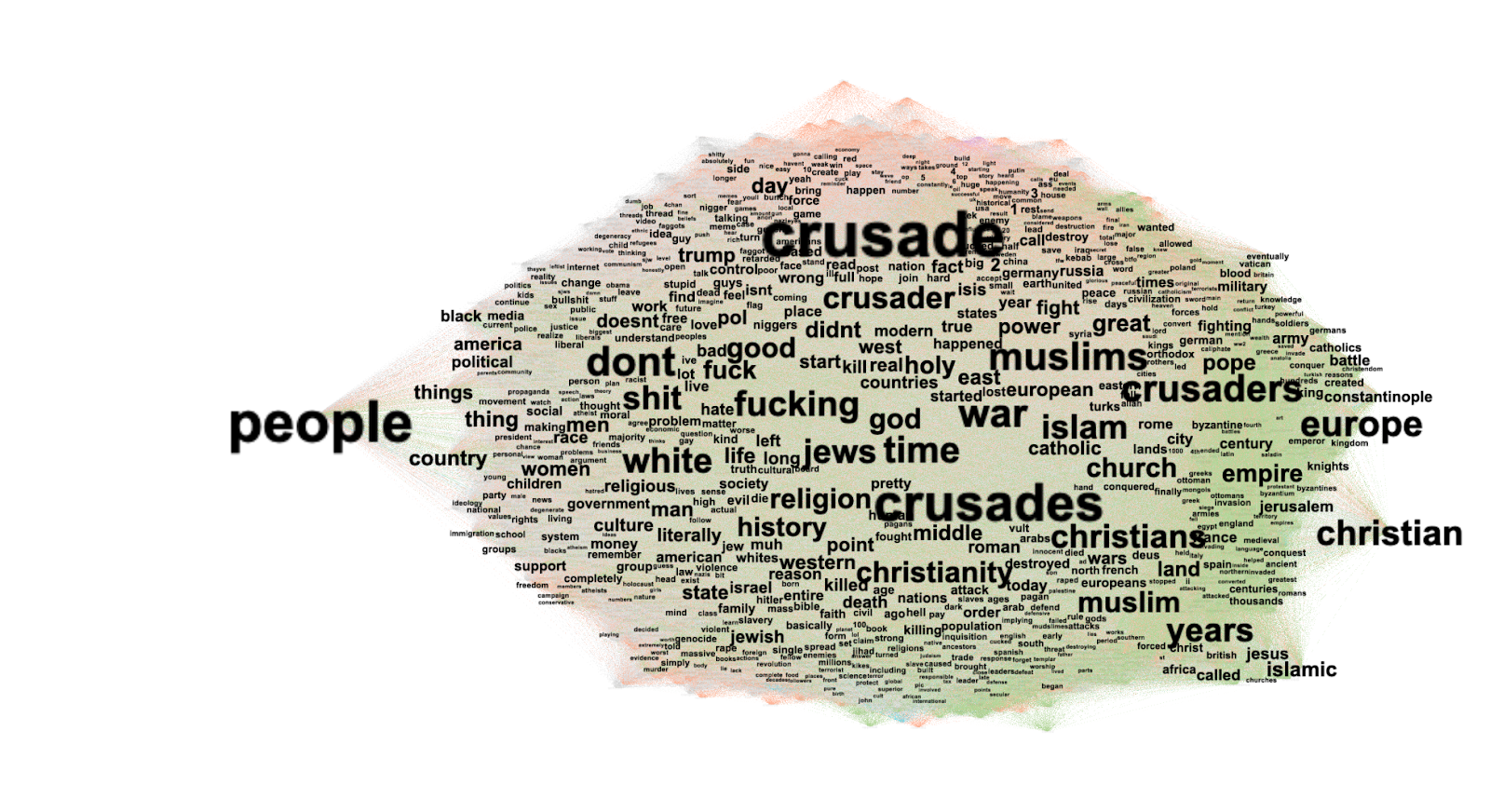
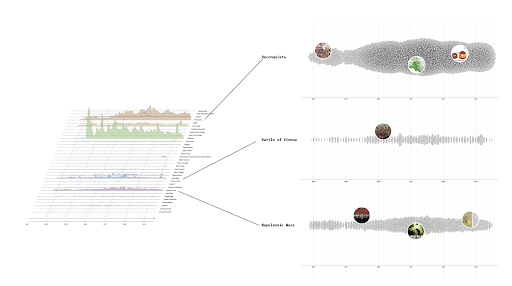
Surprisingly, we found that there is only a 45% overlap between sources presented by Bing Chat and the top 10 Bing search results when presented with the same prompt across all three levels of controversy (Figure 2; see Poster “Comparing Bing Chat with the Bing Search Engine”). There was an overall dominance of English language sources, even when those sources were local to a country (Figure 3; see Poster “Source Analysis by Source Language”). One exception to this finding are the sources of the prompts in Traditional and Simplified Chinese language, which were the only cases that did not provide sources in other languages. Responses for French, Spanish, Portuguese, and English had a significant amount of native language sources, whereas prompts in German, Hindu, Italian, and Dutch had significantly less native sources compared to the English language sources. Further, the use of encyclopedic sources, instead of using native news sources, are dominant through all different prompts (Figure 4a and 4b; see Poster “Source Analysis by Prompt Language” and “Source Link Analysis”). Indeed, there were almost moments of overlap in sources used, regardless of the language used to prompt Bing Chat.
A significant fraction of the sources provided by Bing Chat originated from the United States or the United Kingdom (Figure 5a and 5b; see Poster “Comparing Sources Across Countries” and “Biases and Relevance Concerns”). This preference for foreign sources was particularly evident when searching for the incumbent politician during our political candidate search, whereas a higher proportion of local sources were presented for the competing politician. It implies that Bing Chat gives more preference to US or UK sources, potentially influencing the information users receive. Also, it is worth mentioning that the sources provided by Bing Chat were not always relevant to the query or the specific question asked. Sometimes, Bing Chat would offer sources even when it claimed not to know the answer. Also, we observed that user-generated platforms such as Twitter, Instagram, YouTube, and Getty Images were occasionally cited as sources, raising questions about the information's reliability and accuracy.
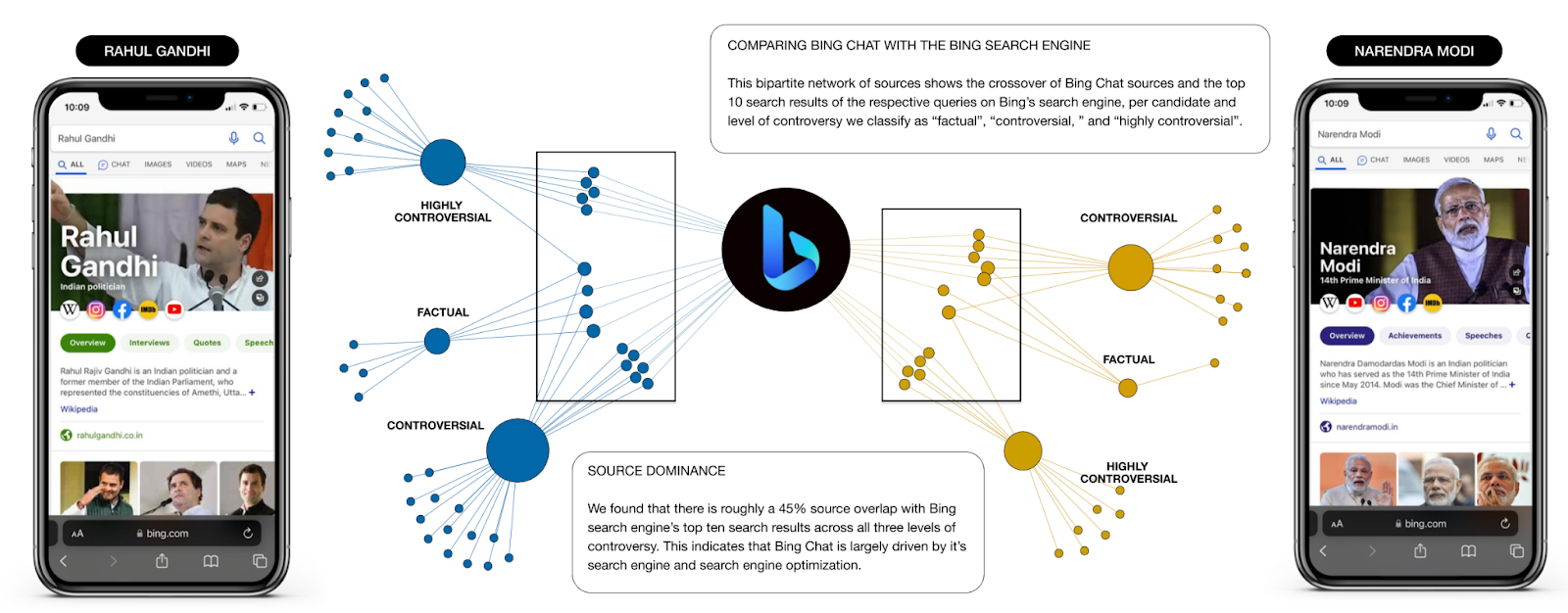
Figure 2: Comparing Bing Chat with the Bing Search Engine
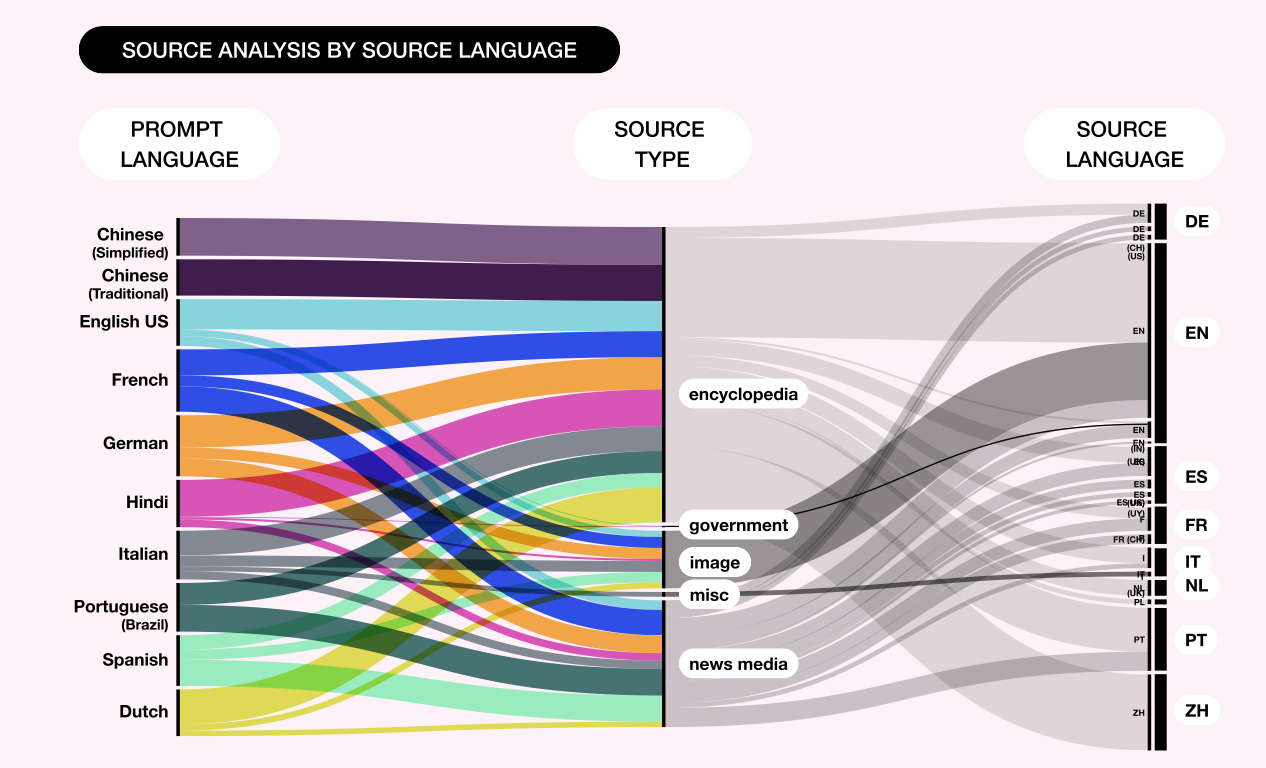
Figure 3: Source Analysis by Source Language
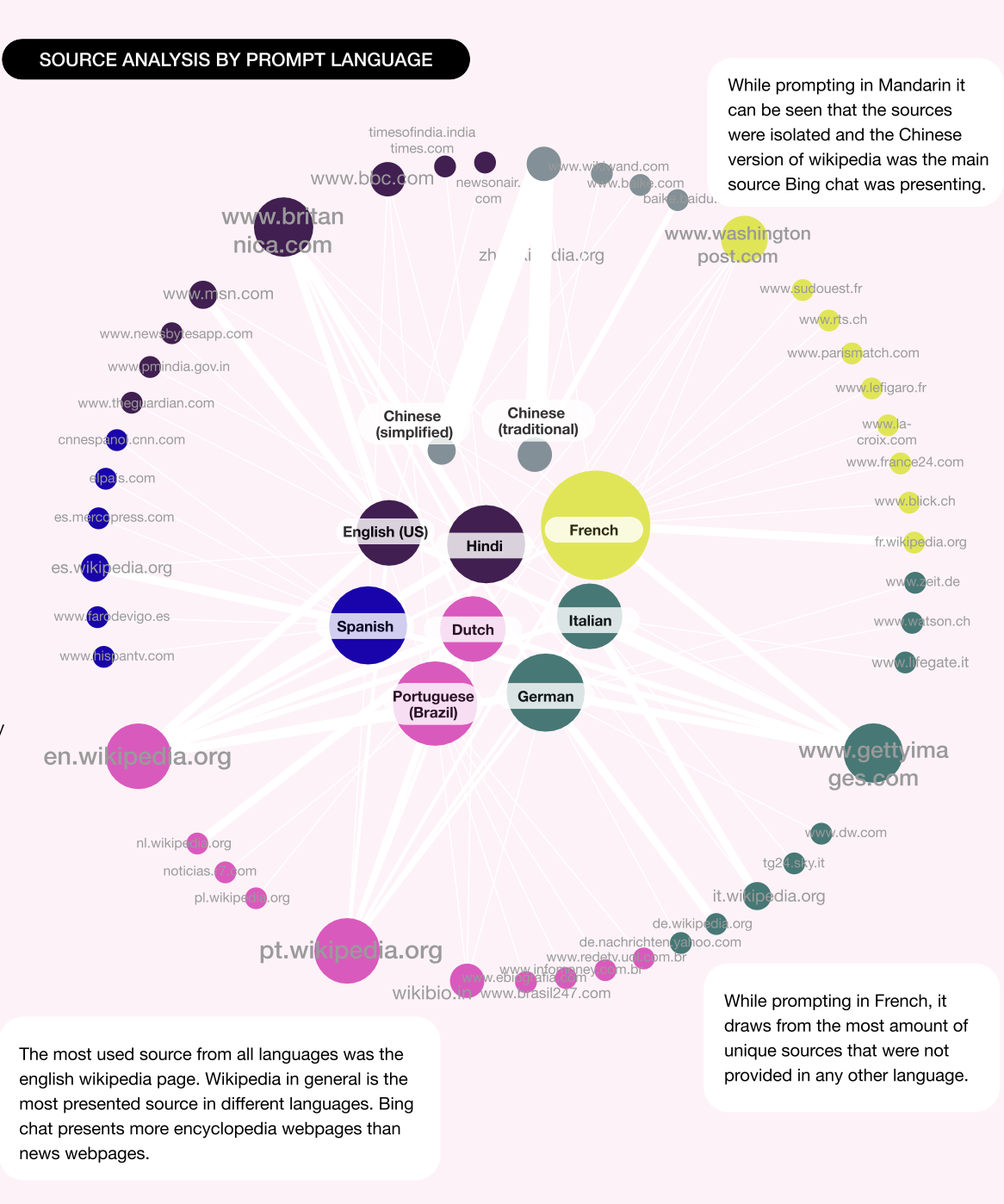
Figure 4a: Source Analysis by Prompt Language
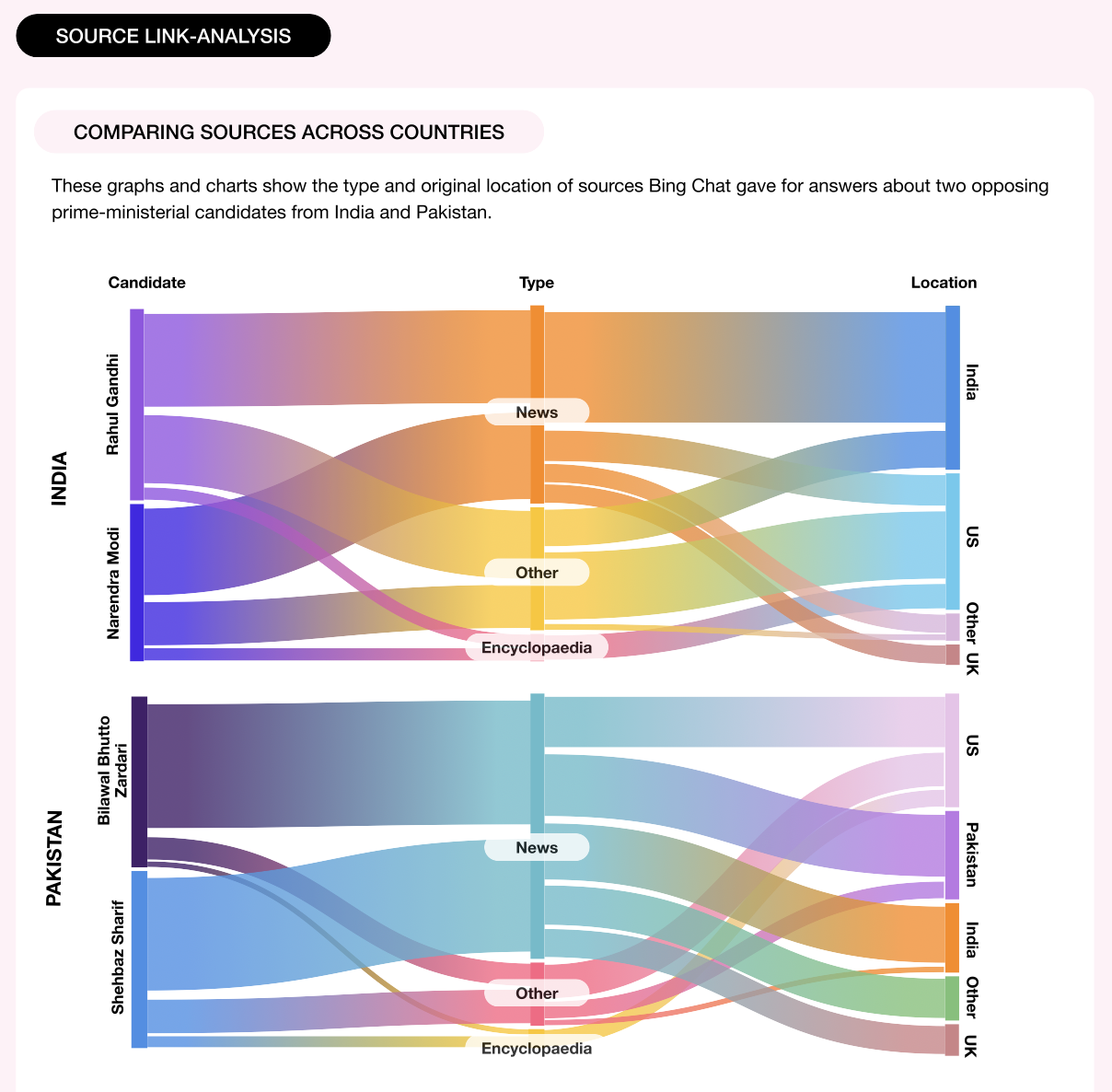
Figure 4b: Source Link Analysis
Figure 5a: Comparing Sources Across Countries and Biases and Relevance Concerns
Outlook: Semantic Analysis
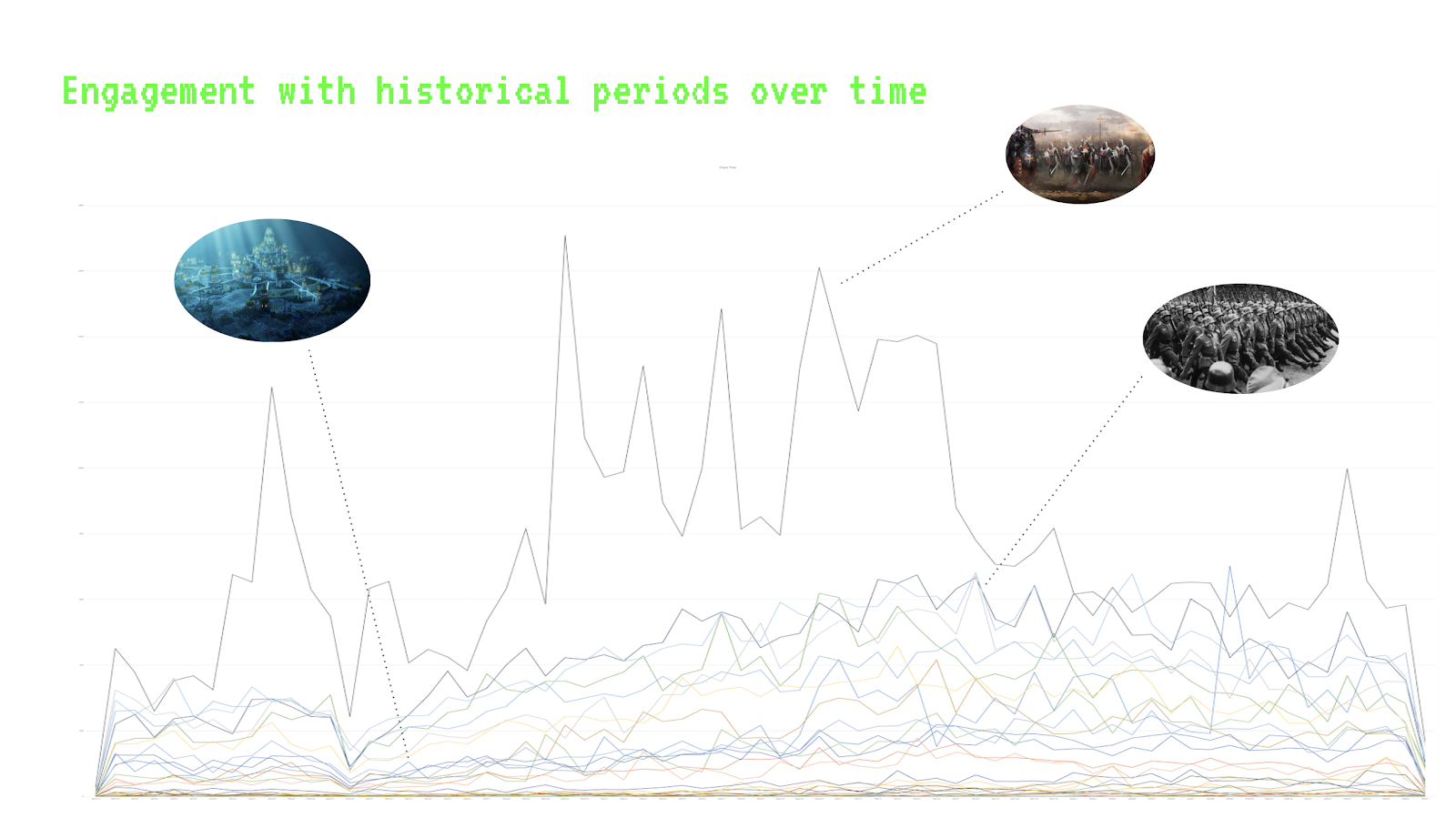
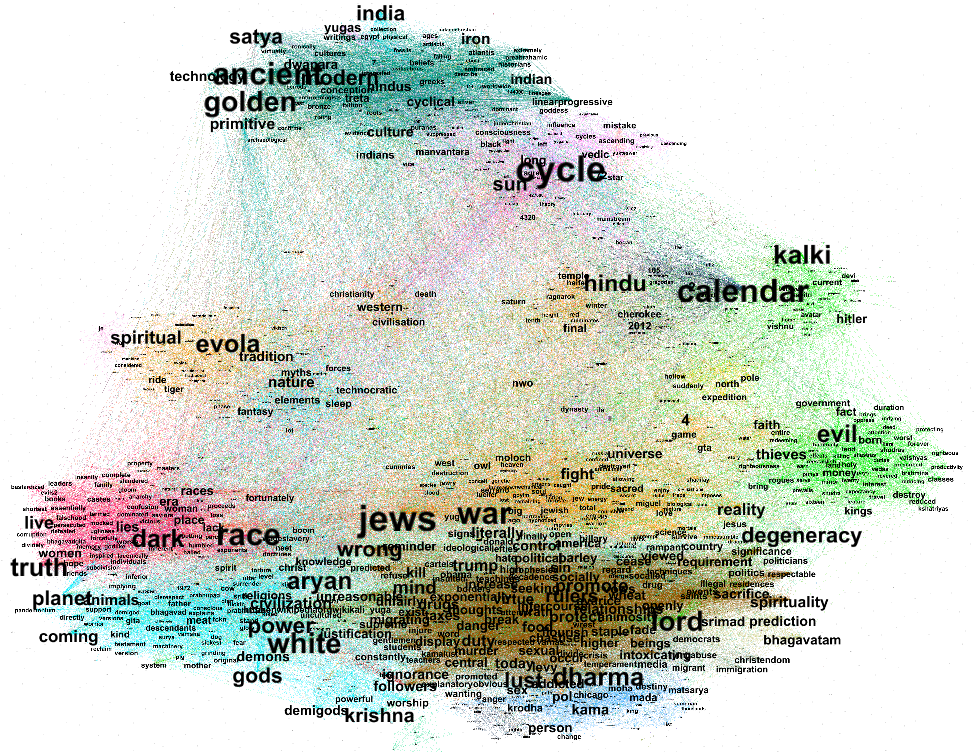
We conducted a semantic analysis with the help of Dandelion API as an automated technique to assign meaning to a sentence by analyzing its language structure. Beyond simple word tokenization, this semantic analysis attempts to infer the concepts in a sentence. However, we are aware that as part of computational semantics the system guesses and attributes meanings that are not necessarily exclusively accurate based on what it is trained on. In our case, the following attributes were collected and matched to the prompt output: Person, Works, Organisations, Places, Events, Concepts (Figure 6).
As previously mentioned, this method was applied programmatically to all prompt responses, taking into account the researcher and the question. Our assumption was that if the question was more factual the semantic values would not differ as much between researchers as they would with more controversial questions. Across all three levels of controversy, we however saw how apparently different and non-deterministic Bing Chat’s answers are (Figure 7; see Poster “Semantic Analysis”).
For future semantic research on Bing Chat, we see two main areas of improvement, to possibly increase the reliability of the semantic analysis process. Firstly, Bing chat often adds some "fluff" to the answers such as "Is there anything else you'd like to know about him? 😊" (emoji included). We concluded that these parts should be removed from our automated analysis, as they may contaminate the extracted semantic concepts. Secondly, both the categories themselves as well as their accuracy are two parameters that could be taken into account for further filtering and refining of the output in the future. Both of these steps were not prioritized in this research due to time restraints and will be taken into consideration for further research.

Figure 6: This example shows how a prompt response is processed by the semantic model.
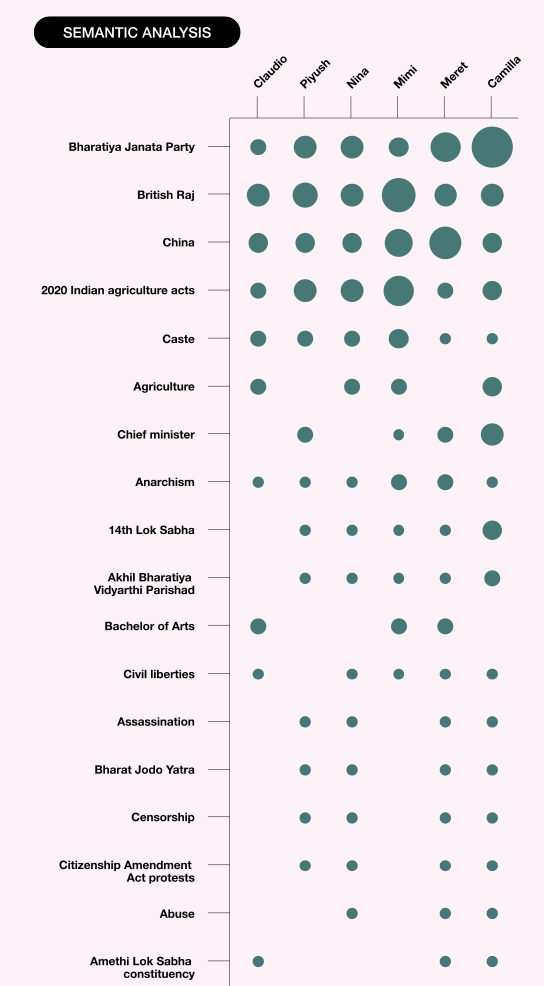
Figure 7: Semantic Analysis
5. Discussion & Conclusions
In conclusion, this research contributes to the realm of research on LLMs, specifically the integration of LLMs into search engines such as Bing Chat, as a source for political information. Our case study on Indian elections and Bing Chat sheds light on the complex dynamics between information retrieval, personalization, bias, as well as the shaping of public opinion in the digital age. Our research questions were centered on investigating how LLM-powered search engines convey information about opposing political candidates, the role user personalization plays, as well as the variations in information and source quality. Our findings highlight the need for users to critically evaluate the sources and information provided by LLM-powered search engines. It underscores the importance of fact-checking the information obtained, especially when dealing with politically sensitive topics.
The dominance of English language sources prevailed, which leads us to conclude that while Bing Chat speaks different languages it thinks in English and draws information from mostly western based sources. Additionally, the reliability and relevance of certain sources were occasionally questionable, as user-generated encyclopedic sources were frequently used across different prompts, often at the expense of local news sources. A considerable proportion of these sources originated from the United states or the United Kingdom, which reinforces western perspectives on non-western politics, potentially influencing the global perception of politics.
Hence, we argue that the integration of LLMs into search engines like Bing Chat introduces new dynamics when it comes to the dissemination and retrieval of (political) information, contributing to the digital landscape of political campaigning and public opinion. Our research underscores potential technologically-imbedded points of bias and challenges associated with using such technologies for information retrieval and are raising concern about the quality and accuracy of information provided to users. With this research, we invite our readers to think about responsible information dissemination, and contribute to a deeper understanding of how LLMs influence public discourse, political elections and campaigns, and what it means to have democratic access to unbiased information.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback