Corona Testing on Twitter
Surfacing testing situations beyond the laboratory
Team Members
Noortje Marres (University of Warwick), Helena Suárez Val (University of Warwick), James Tripp (University of Warwick), Iain Emsley (University of Warwick), Gabriele Colombo (University of Milan), Federica Bardelli (Density Design Lab), Liliana Bounegru (King's College London), Jonathan Gray (King's College London), Elisa Tattersall Wallin, Saide Mobayed, Abdul Sittar, Sara Abdollahi.
With the participation of Cian O'Donovan (University College London) and Cagatay Turkay (University of Warwick)
Contents
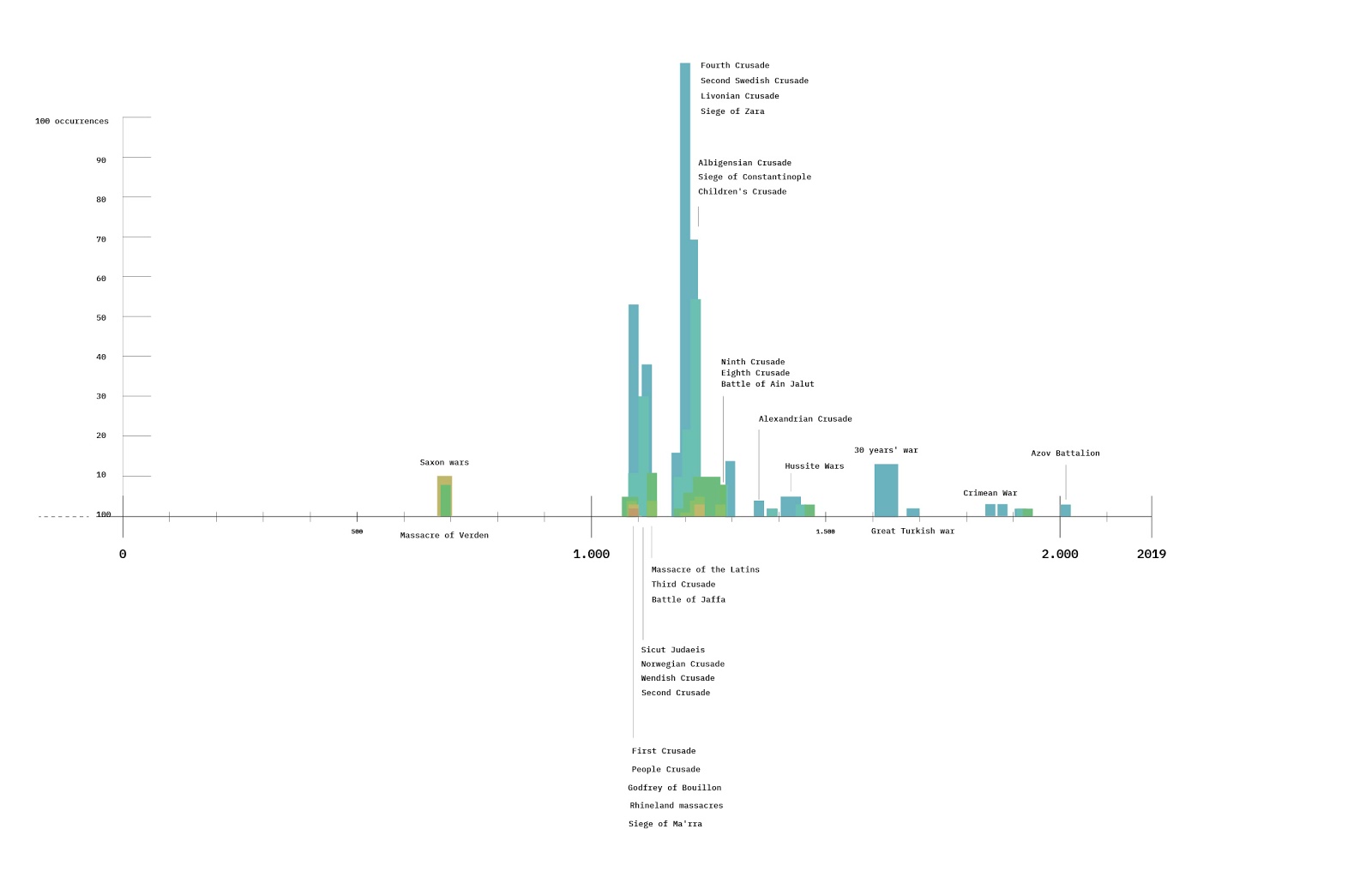
Summary of key findings
We developed a methodological approach to surface and analyse ‘situations’ from a Twitter dataset relating to testing for Corona Virus “beyond the laboratory,” in society. This approach mixes digital and interpretive methods, including visual methods, to enable researchers to move from interpretive analyses of situations at the level of individual ‘tweets’ to the level of a large dataset. In terms of our analysis, we are exploring whether and how Twitter communications about testing for Covid complicates and enriches sociological understandings of testing beyond the laboratory. In many spheres, testing beyond the laboratory has been associated with a move to user-led testing, and self-responsibilization of lay actors (patients, citizens, residents, and so on). Our Twitter analysis to date points towards a different dynamic: on Twitter, testing for Covid beyond the laboratory puts everyday people in direct and explicit relation with institutions (hospitals, schools) and state actors (PM, local government). From the perspective of our social media analysis to date, testing for Covid beyond the laboratory may amount to a socialisation of testing: to test or not to test for COVID ostensibly places people in relations of responsibility or irresponsibility to others ( responsibilization of social relations, not self responsibilization).
1. Introduction
The aim of this project was to develop a methodological approach to conducting an interpretative analysis of COVID-19 or Corona Testing on Twitter in order to surface testing situations ‘beyond the laboratory’. This work was started at a workshop in June co-organised by the Centre for Interdisciplinary Methodologies (University of Warwick), the Department of Digital Humanities (King’s College London), and the Public Data Lab. We wanted to explore the use of digital and visual methods, within a humanities framework, to draw out from Twitter conversations an everyday perspective on the constraints, challenges and affordances of testing for Corona in environments in society.
The project draws on the sociology of testing ‘beyond the laboratory’, particularly building on work presented in the recent special issue ‘Put to the Test -The Sociology of Testing’ in the British Journal of Sociology (2020). As Marres and Stark (2020) have noted, testing is an emergent “total social fact” and we are moving towards a society of ubiquitous testing. For example, the social study of pregnancy testing has powerfully shown that a physical test doubles as a social test, testing social relations at the same time as the body (Robinson 2020). The issues raised in this area of study are highly relevant to COVID-19 or Corona testing, as parallels with pregnancy testing are made in claims that testing kits would be available for personal use at home and testing centres spring out in car parks, theme parks, and shopping malls.
The testing situations that we are interested in are what Marres and Stark (2020, 437) designate as ‘problematic situations’, moments ‘when habitual ways of doing get interrupted in social life, whether by accident or as a consequence of deliberate disruption, [prompting] social actors [...] to articulate their attachments and relations.’ In our case, we are interested in situations in which Corona testing puts to the test social actors, locations, relations, devices, and practices, as a result of their interactions. In order to surface these from our Twitter dataset, we draw on Situational Analysis (SA), a cartographic approach to qualitative data analysis developed by Adele Clarke (2005), which maps heterogeneous entities detected in fieldwork data, in order to determine what is problematic, and/or what can make a difference in a situation.
The broader project aims to explore the potential uses of digital and interpretive image and textual analysis to surface everyday situations of Corona testing from Twitter. Building on the approaches outlined above, we explored different strategies of data visualisation (lexicon methods, co-occurrence networks, image grids), using digital and interpretive methods to surface from Twitter data entities, expressions and attributes that specify, or contribute to, the surfacing of testing beyond the laboratory as an everyday situation.
The ultimate purpose, beyond this workshop, is to develop a visual typology of everyday Corona test situations, which can inform conversations across the expert/non-expert divide about the social life of Corona testing.
2. Initial datasets
We worked with TCAT datasets derived from a larger 97 million tweet dataset, called ‘CoronaVirus’, which consists of tweets containing the word ‘coronavirus’. This is part of a larger capture of terms based on CoronaVirus and Covid-19 that was started on 23rd March and continues to collect data.
The CoronaVirus dataset was queried for the words ‘ test ’, ‘ tests ’, ‘ testing ’ and ‘ tested ’ between the 23rd March 2020 and 27th May 2020, resulting in a smaller subset, named CoronaVirusTestTestsTestingTested. This subset, and the further subsets described below, are stored in a separate TCAT instance.
-
CoronaVirusTestTestsTestingTested (3,991,250 Tweets)
Three smaller subsets were created to focus this smaller dataset into three general themes: Devices, Relations, Locations. The subqueries used to create these subsets were the result of an iterative process of analysis.
-
Testing_Devices (141,891 Tweets)
Query terms: ‘ app ‘, ‘ confidential ‘, ‘ get tested ‘, ‘ getting tested ‘, ‘ kit ‘, ‘ lab ‘, ‘ result ‘, ‘ self test ‘
-
Testing_Location (198,997 Tweets)
Query terms: ‘ Home ‘, ‘ drive ‘, ‘ hospital ‘, ‘ laboratory ‘, ‘ school ‘, ‘ online ‘, ‘ mobile testing ‘, ‘ care home ‘, ‘ supermarket ‘, ‘ superstore ‘, ‘ neighbourhood’
-
Testing_Relations (207,936 Tweets)
Query terms: ‘ body ‘, ‘ boyfriend ‘, ‘ community ‘, ‘ dad ‘, ‘ divide ‘, ‘ family ‘, ‘ father ‘, ‘ friend ‘, ‘ girlfriend ‘, ‘ granddad ‘, ‘ grandfather ‘, ‘ grandma ‘, ‘ grandmother ‘, ‘ grandpa ‘, ‘ granny ‘, ‘ husband ‘, ‘ mother ‘, ‘ mum ‘, ‘ nation ‘, ‘ neighbour ‘, ‘ partner ‘, ‘ relations ‘, ‘ society ‘, ‘ state ‘, ‘ wife ‘
3. Research Questions
In order to fulfill our aim, the following two research questions were constructed:
RQ1. What type of situations surface in Twitter reporting on Corona testing through the circulation of images?
RQ2. What can this tell us about the ways in which Corona testing puts social relations, and society, to the test?
This summer school project is a continuation of a project which began earlier in June 2020. In previous instances of the project we analysed the datasets through lexicon analysis with Le-Cat, topic modelling, and image grids. Given the size of our dataset, one of the outcomes of this workshop was that solely using text-based methods would be challenging. Although an interpretative close reading of random samples of tweets allowed us to specify and qualify situations present in a subset, there were limitations when it came to scaling up these methods to surface these situations at the level of the whole dataset. For instance, due to the subtle ways in which situations are specified (sometimes through irony, sarcasm, or implication), it was difficult to extract query terms that could be used to search the dataset to surface particular situations.
The next task for our project, then, was how to specify or qualify situations at the level of the dataset. We posed the question: Can image analysis help us address this challenge? Can we use the analysis of collections of images (Colombo 2019) derived from the dataset to further specify the relation between location/issue, relations/issue and devices/issue?
With this in mind, we further refined the research questions to find out if we could use visual data analysis to answer the following questions:
-
How does a given location qualify an issue and how do issues play out differently in different locations? (e.g. [stay] home versus care home?)
-
How are different relations put to the test (or qualified) differently through covid testing? (e.g. family relations vs state relations: conferral of 'duty of care' at each level?)
4. Methodology
This summer school workshop was part of a larger project, exploring the potential of digital and interpretive methods, within a humanities framework, to surface situations at the level of a Twitter dataset (as opposed to individual tweets). Through this iterative process, we are developing a protocol for this type of research. The ultimate aim is to build an analysis that can inform conversations across the expert/non-expert divide. In particular, we are interested in the role that images and data visualisation could play in stimulating interpretations about everyday experiences of Corona testing ‘beyond the laboratory’.
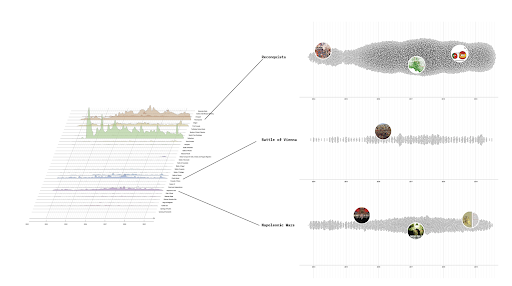
Methodologically, the project draws from Situational Analysis (SA), a cartographic approach to qualitative data analysis developed by Adele Clarke (2005), which maps heterogeneous entities detected in fieldwork data, in order to determine what is problematic and/or what can make a difference in a situation. A key method in SA is the creation of compositional maps, data visualisations that display heterogeneous entities surfaced from fieldwork data: non-humans, issues, organisations, actors, things, events, locations. In this way, situational analysis extracts from the data diverse types of entities that make a difference in the situation, entities that make the situation what it is, that compose it.
For this stage of the project, the aim was to continue building on previous work, where we had explored the Twitter datasets through lexicon building, image grids, and topic modelling, but deepening the visual analysis methods. Could image analysis help us address the challenge of surfacing situations at the level of a whole dataset? Could we use images to extend the kind of compositional maps proposed by SA? And what strategies could we devise in our approach to ‘shift the focus from the individual image to the group of images as the unit of analysis’ (Colombo 2019, 191)?
From our previous workshop, we had a lexicon for the Testing Locations dataset. We decided that on the first day, one group would use this lexicon to start exploring ways into image analysis methods, with a view to defining a protocol. Meanwhile, another group would build a lexicon and use Le-CAT to analyse the Testing Relations dataset. The next day, the Testing Relations dataset group tested the protocol devised by the first group to build their own image grids. The third day, both groups worked together through a collaborative canvas to build a visual map of situations that had emerged in their respective enquiries. In the analysis of this canvas, what emerged were four potential axes of interpretation for the visual output: a methodological and analytical roadmap, to be further explored in the next iterations of the project.
In the next sections of this report, we outline the process of lexicon building and analysis with Le-CAT, the protocol for creating image grids for situational ‘pairs’, and the final clustering of images for collective analysis.
-
Lexicon building with Le-CAT
-
Image grids (using lexicon analysis to prioritise)
-
Image clustering for collaborative interpretation
-
Definition of four axes of interpretation
Situational analysis with Le-CAT: a lexicon-based method
Lexicon analysis provides a way to structure the creation of compositional maps proposed by Clarke as part of SA, so that this cartographic approach can be applied to datasets that exceed our scholarly capacities for interpretation through close reading, such as our Twitter datasets with millions of entries.
In contrast with the inductive approach to data analysis championed by SA, lexicon analysis is an iterative approach to data interpretation (see Timmermans and Tavory 2012 on abduction). Instead of identifying relevant entities through reading fieldwork data in a bottom-up approach, in lexicon analysis we determine the composition of the situation through three intermediate steps: we first define types of categories relevant to our hypothesis or question; secondly, we create relevant categories of heterogeneous entities; and, finally, we search our data - initially, a random sample from the full dataset - for terms (query terms) that can serve as indicators of those categories in our data. Adopting an iterative approach to data interpretation, this structure serves as a guide on the process of specifying and re-specifying the categories and queries that compose the situations latent in our data.
In order to build a lexicon from (and for) the Testing Relations Twitter subset, each member performed a close reading of a random sample of tweets from TCAT, looking for examples of ‘relations’ and ‘issues’, the two category types we had defined. Different categories of relations and issues were created, as candidate query terms for the lexicon analysis. To exemplify, if a tweet said ‘my grandmother is unwell but can’t get a test’, the relation would be the ‘grandmother’, which belonged in the category ‘family’ and the issue would be that she can’t get a test which fit in the category ‘no test’.
The following table outlines some of the relations and issues we defined for this subset:
| Type | Category | Query1 | Query2 | Query... |
| relation | family | mother | uncle | |
| relation | intimate relation | boyfriend | husband | |
| relation | state | county resident | citizen | |
| relation | society/ professions | driver | vendor | |
| relation | care | nurse | caregiver | |
| relation | peers | co-worker | colleague | |
| issue | no test | not enough tests | no test | |
| issue | test results | tested positive | test result | |
| issue | death | died | passed away | |
| issue | exposure | large gathering | funeral feast | |
| issue | quality of information | Hindu Temple | fearmongering | |
| issue | ill-equipped | test result delayed | failed to provide | |
| issue | feeling | worried | concerned | |
| issue | discrimination | racial | racial breakdown | |
| issue | recovery | recovered | discharged | |
| issue | support and advice | support | thanks |
Different queries and categories that had been identified as most indicative were added to the lexicon. In a group discussion, we reviewed categories which were problematic in some way, such as being undefined or uncertain. In the group there were also discussions pertaining to what was missing from the original queries as well as what we had expected to find in the tweets but did not. For example, considering the nature of the dataset, relating to relations, we had a hypothesis around finding situations relating to violence in the home or in intimate relations, which has been flagged as an issue in several countries and in previous pandemics (Adhiambo Onyango 2020). However, this was not found in the dataset. Another aspect which did not surface as strongly as expected in the tweets had to do with situations involving people at higher risk for COVID-19, shielding or key workers in families. It is possible that these issues were simply not present in the random samples, but could have been found elsewhere. We might also consider refining the original queries for the subsets - this is very much part of the iterative process.
Interestingly, we encountered similar discrepancies when the same process had been previously applied to the Testing Locations Twitter subset. For instance, while at the beginning the location category we thought was prominent was that of the ‘home’, the Le-CAT analysis showed us that ‘care home’ was actually the most co-current query. With regard to issues, while our interpretative discussion on the close reading process addressed government accountability and distrust, its explicit prominence was low at the level of the dataset.
Using lexicon-based methods to analyse large datasets, we are then able to separate two tasks: determining relevant categories and entities (defining the lexicon) and detecting whether and how these categories and entities obtain in the dataset (running the lexicon). We determine relevant categories and entities by creating a lexicon on the basis of a reading of a random sample of the dataset. Only when we have built this initial lexicon, do we apply it to the whole dataset, to figure out whether and how categories surface in the dataset, and what entities compose them.
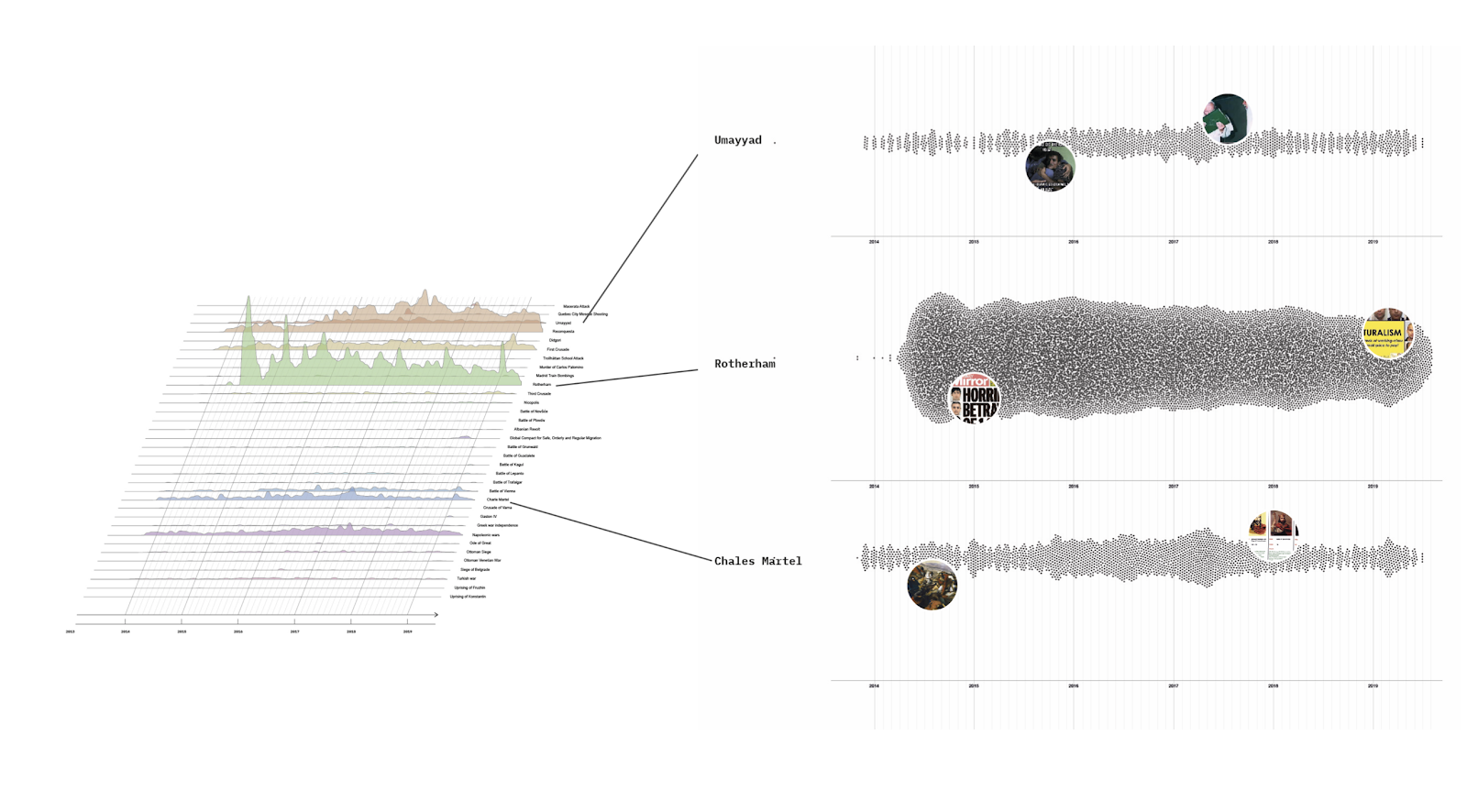
This first version of the Testing Relations lexicon was then run for test in Le-CAT (Lexicon-based Categorization and Analysis Tool¹), a tool which allows you to apply a set of word queries associated with a category (a lexicon) to a dataset (the corpus). Le-CAT determines the frequency of occurrence for each query and category in the corpus, as well as the relations between categories (co-occurrence) in the lexicon. The purpose of this technique is to automate and scale up user-led data analysis as it allows the application of a custom-built Lexicon to large datasets. The quick iteration of analysis allows the user to refine a corpus and deeply analyse a given phenomenon. This first diagnostic on our lexicon against the dataset revealed the frequency and relations between different categories and query terms, which were then discussed in the group.
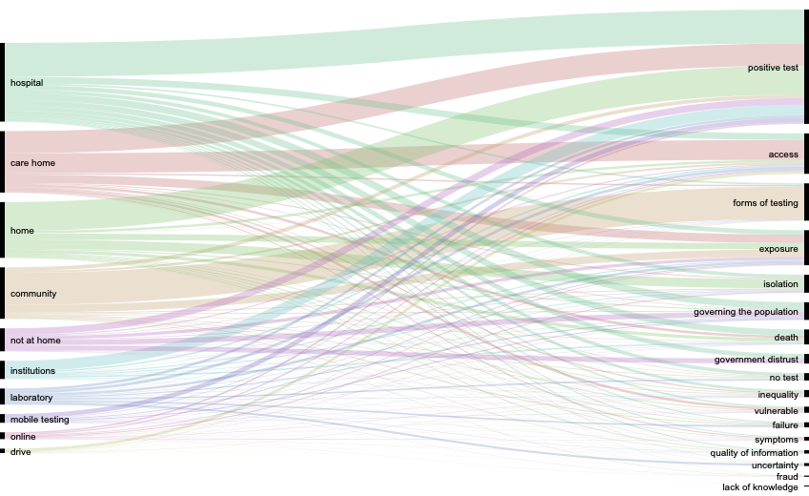
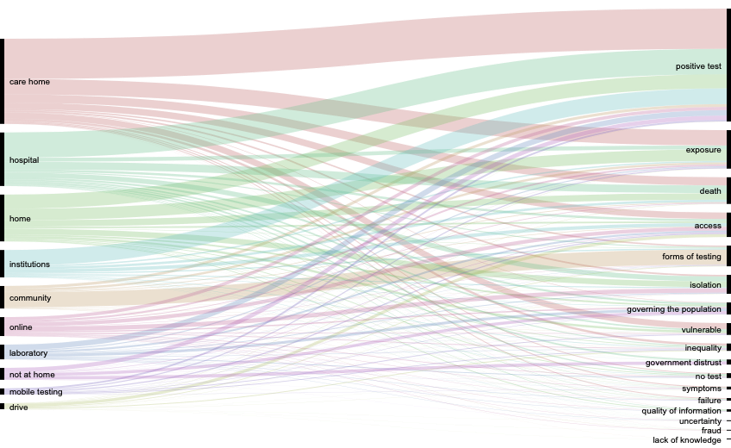
Figure 1. Locations lexicon in the Corona Testing subset (w/o RT) vs Locations lexicon in the Locations subset.
The results of the lexicon analysis were visualised in different ways in a spreadsheet as well as in Gephi and with alluvial graphs. These visualisations allowed us to identify the co-occurrences of different relations and issues. For instance, ‘test result’ was the highest occurring issue and we therefore chose to focus on this in the subsequent image analysis, together with the four highest co-occurring categories of relations: ‘intimate relations’ ‘family’ ‘state’ and ‘society/professions’. The same procedure for prioritising the focus for visual research was followed by the group working on Testing Locations, who started their analysis of their dataset with a Lexicon built on a prior workshop in the larger project.
A research protocol for creating image grids
Colombo (2018 abstract) has argued that ’the specificity of digital images, in terms of production, fruition and circulation, requires a novel approach to their study, one that shifts the focus from the individual image to the group of images.’ The relevant question for this project was whether and how the study of a group of images could facilitate an interpretive analysis at the level of the whole Twitter dataset. In order to test this approach, the group focusing on Testing Locations developed a protocol for the creation of image grids supported by the Lexicon analysis method.
In a previous research event in the project, a lexicon had been built for the Testing Locations subset, following the procedure outlined in the previous section, where the category types were ‘location’ (instead of ‘relation’) and ‘issue’. The group at the summer school used this lexicon to prioritise the creation of image grids for visual analysis. Initially, the Testing Location subset had ten locations and 17 issues. Once the dataset ran through Le-Cat, we selected those locations which had more query term matches at the level of the whole dataset. This resulted in five categorical locations: ‘care home’, ‘laboratory’, ‘home’, ‘community’ and ‘institutions’. The same process was applied to issues. All of our elected issues—‘forms of testing’, ‘exposure’, ‘access’, ‘no test’, ‘isolation’, ‘death’, ‘positive test’, ‘vulnerable’, ‘governing the population’ and ‘inequality’—were analysed across the different locations.
A protocol was agreed for creating and analysing image grids, and each member of the group took an ‘intersection’ of issue-location for analysis (afterwards, the Testing Relations group also followed this protocol). The protocol was as follows:
-
Using T-CAT, query the subset to download all tweets (with images) for a given ‘location’, using the relevant query terms from the lexicon. e.g. for the location category ‘care home’, we used the query: ‘nursing home OR retirement home OR residents OR care home’ from our lexicon.
-
Using OpenRefine, filter the obtained dataset for a given ‘issue’, using the relevant query terms from the lexicon. E.g. for the issue ‘exposure’, we filtered with the query: ‘outbreak|spread|cruise ship|leave home to work|large gathering|community transmission’.
-
Export the resulting dataset to a CSV file into Google Sheets. Using the Pivot table function, create a new list of unique image URLs, with a column listing the frequency with which they appeared in the dataset and another column to display the actual image.
-
Analyse the image grids individually, noting interesting findings and selecting exemplars for collective analysis. Do not refer to the texts of tweets at this stage, unless a particularly interesting image or pattern of images requires to do so.
The final dataset from this process resulted in a set of over 3,000 images divided into about 60 collections, or image grids, representing the combined intersections of selected issues-locations and issues-relations. Individual team members took on the analysis of a number of image grids in order to select examples to be input for the next stage of collaborative interpretation. The grid format and the number of images afforded different approaches to the analysis. For example, some researchers started by analysing each image in detail, but after a number of images started scrolling up and down and seeing patterns or repeated images. Others started in the opposite way, approaching the list of images as a whole and afterwards alighting on specific images for more detailed consideration. Yet another approach was to quickly ‘tag’ the images with a keyword and then use the filtering functions in the spreadsheet to visualise tagged images and see connections or features of interest, to make further notes and select examples. While this diversity of approaches produced interesting results and discussions at a qualitative level, we nevertheless agreed that achieving a consistent approach across analysts working on the dataset was something to be addressed in future developments of the methodology.
Clustering groups of images for collective interpretation
For the last step in our methodology, we clustered images on the Miró platform to serve as a space for collective interpretation of our results. A grid was built on Miró, representing the intersections outlined above (issues-locations, issues-relations), and group members ‘dropped’ their image examples in the relevant location in the Miró grid.
Our aim was not to produce a ‘description’ of Corona testing as seen via Twitter. Rather, we wanted to create a ‘composite image, as a strategy to support interpretative work in the context of digital social research’ (Colombo 2018), to prompt or enable interpretations about everyday testing situations, conveying a feel for how locations and relations relate to, and are tested in, testing situations. The Miró platform allowed us to collectively interpret, annotate, edit, and discuss the clustered images, using its built in functions to move together or individually on the screen as we clicked, scrolled, and zoomed across the composite image grid.
This process had a two-fold objective. On the one hand it served to refine our analysis of the subsets, for example, by keeping track of things we expected to find but did not, clarifying whether this might be due to errors in the data. On the other hand, the process of collaborative interpretation provided a sort of ‘pilot’ for how we might want to present the data from the project to the experts, in order to promote their interpretations and insights.
After building the grid in Miró, we first had a general conversation about the grid. This initial collaborative exploration of the clustered images led us to formulate four axes of interpretation for a more in depth analysis of the composite image. These are:
-
The relative abundance/scarcity of images for a given issue-location coupling
(i.e. is there a visual vocabulary for the situation on Twitter?) -
The extent to which images specify the intersections of issue-location or issue-relation, versus being generic.
(e.g. the visual of the virus itself is a generic image) -
The operation the image/s performs on the intersections of issue-location or issue-relation
(e.g. ‘full house’ addresses the intersection ‘care home-exposure’ to the Health Secretary) -
What is missing
(e.g. pictures of inside the home in the location home)
In a second iteration, we analysed the clustered images through these axes of interpretations to review their analytical productivity.
5. Findings and discussion
Initial observations - Testing Relations
Our initial observations were really contrastive to what social media are popular for. This might be due to the corona-centric analysis of tweets. It appeared in our initial observations that there were other entities holding a strong presence in the relations dataset than celebrities and sports players. These include institutions and departments of states, and different roles of society. It had been seen in the hierarchy of issues that more issues were about directly explaining what problems the public were facing than showing the quality of content etc. For instance, realities of exposure, accessibility to services and no test were significantly more prominent than epistemic issues. Another strong finding was witnessing the disappearance of the word ‘care home’ that could explain whether the relation dataset was focusing on relations or it was equivalent to the locations dataset.
Initial observations - Testing locations
Our initial observations show that testing locations aren’t the locations of testing. For example, ‘care home’ was not among our queries, and not a prominent location of ‘testing’ for COVID, yet it emerged as very prominent in our dataset.
What also emerged from our initial analysis was a hierarchy of issues. rute realities of exposure, access, and lack of tests are significantly more prominent than epistemic issues pertaining to quality of information, uncertainty, and information fraud.
The care home location images, linked to the ‘exposure’ concept, showed the unfolding scandal of the increase in care home deaths, culminating in the one image of a full house. This was the House of Commons listening to Matt Hancock, the Health Secretary, giving a statement about the issue.
The laboratory features as a prominent location of testing (and not eclipsed by testing ‘beyond the laboratory’). The laboratory, under the exposure concept, did not show any crowds. The testing locations suggested that the laboratory had extended into the community in some cases as well as receiving testing kits from the public. However, the images suggest that this location-concept pair was somehow separate and more commercial images, such as the contents of a testing kit or images of a laboratory worker being ready, were in the image cluster. The second surprise was the testing included exposing the virus itself to being understood and sharing that data. This perhaps hints at epistemic issues of open data and science but may not fully explain these concepts. It features as a site of two forms of exposure.
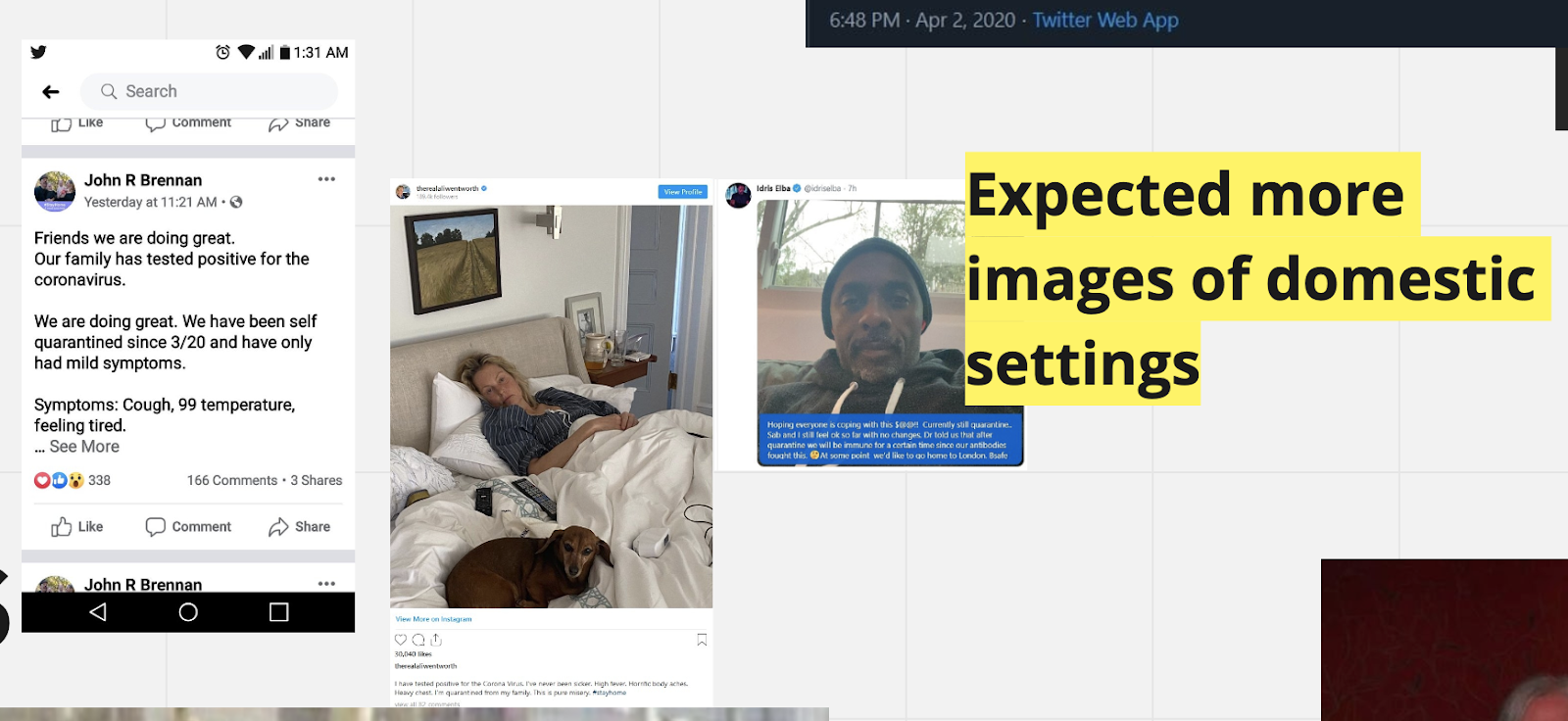
Images of testing situations, whether temperature checks in the street, in airports or supermarkets, or actual Covid-tests, were highly prominent in the dataset relating to the relation ‘state’ and the issue ‘test result’. As most of these tests are either mandated or administered directly by governments, it does make sense that these images should appear in relation to the state. Other prominent types of images related to the ‘State’-’Test result’ dataset were images of people in power making speeches or holding briefings and of politicians and other people in societal power positions who had tested positive for the coronavirus. There were also an abundance of images of official documents with information about the number of infected or deceased persons in particular regions or countries, and screenshots of tweets from people in power containing information relating to covid test results. These different themes that emerged from the subset are perhaps not so surprising. However, there were very few images of official buildings such as parliaments, of flags, emblems or other symbols of state. It seems that the people themselves in power, and the documents and texts they produce, represent the state in this twitter dataset.
Collaborative image analysis - axes of interpretation
1. Relative abundance
Images for the ‘intimate relations’ ‘test results’ intersection tend not to specify ‘test results’ without the textual context. Exceptions may be a composite image of a mother and child and a test result tube and a composite image of ‘the virus’, an ill person, and another person crying (though this last image may be part of a scam). There is a large number of images of celebrities, influential people, and politicians and their intimate relations. Expected more images of domestic/intimate settings (e.g. home) but these were not present. Could be due to Twitter’s mode of publicity.

2. To what extent do images specify ‘intimate relations’ ‘test result’ intersection?
Images specify intimate relations, often in caring situations (adjusting a mask, holding a baby, chatting to an elderly person, embracing/kissing). Test results is not explicitly specified.

In terms of family relation vs corona test results, families having someone in showbizz or sports are more likely to share testing results on Twitter. Moreover, a quite interesting relation among families hierarchy in terms of corona pandemic is mother and newly born baby relation which appears to be one that has an abundance of images. Most of them are showing different preventive measures necessary for child care such as recommended distance between beds in hospitals, and shields covering the whole of babies.
Relative scarcity of images for a given issue-relation coupling
It has been observed that scenes of death due to corona are rarely mentioned along with family members and also there is scarcity of images that can show extended families affected by corona.
To what extent do images specify the “family” “test results” intersection ?Almost all images are visually focusing more on relation than test results. We can see family relations are prominent like father and daughter, and family with its children and grandparents. Therefore, textual context could help more about test results.
What operation does the image perform on the issue-coupling?(eg “full house” addresses the couple care home-exposure to the Health Secretary)
state - test results
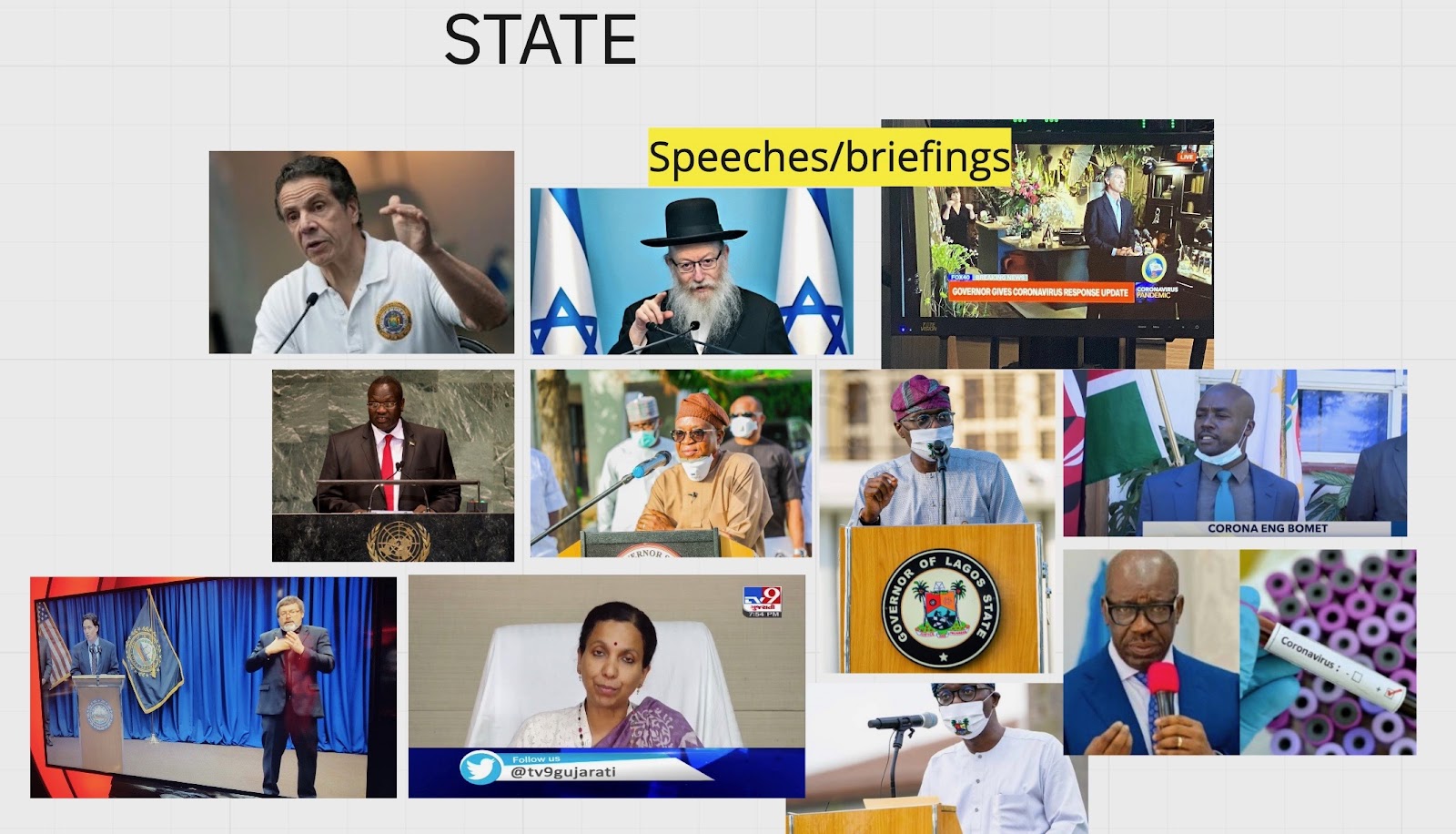

There was an abundance of Images of various people in power making speeches or holding briefings, as well as images of leaders who had tested positive for the virus. Another common type of image related to tests being carried out, such as temperature checks, covid-tests, or what appeared to be official state representatives either interviewing people about symptoms or informing them about guidelines. As most of these types of tests are put in place by states, governments or governmental agencies, it makes sense these images would figure here.
Two things stand out when we think about the images of ‘death’ across locations. The first one is that the pictures depicted are often those of closed spaces, facades where presumably death occurs—or is being spoken about—yet the viewer remains unable to see what is ‘inside’. This creates a sort of semantic dissonance between signifier and signified. In this sense, could we argue that the situational specificity of ‘death’ on tweets about coronavirus and testing happens ‘behind closed doors’? (Three screenshots: ‘care home’, ‘community’ and ‘laboratory’): AXIS OF INTERPRETATION 4.
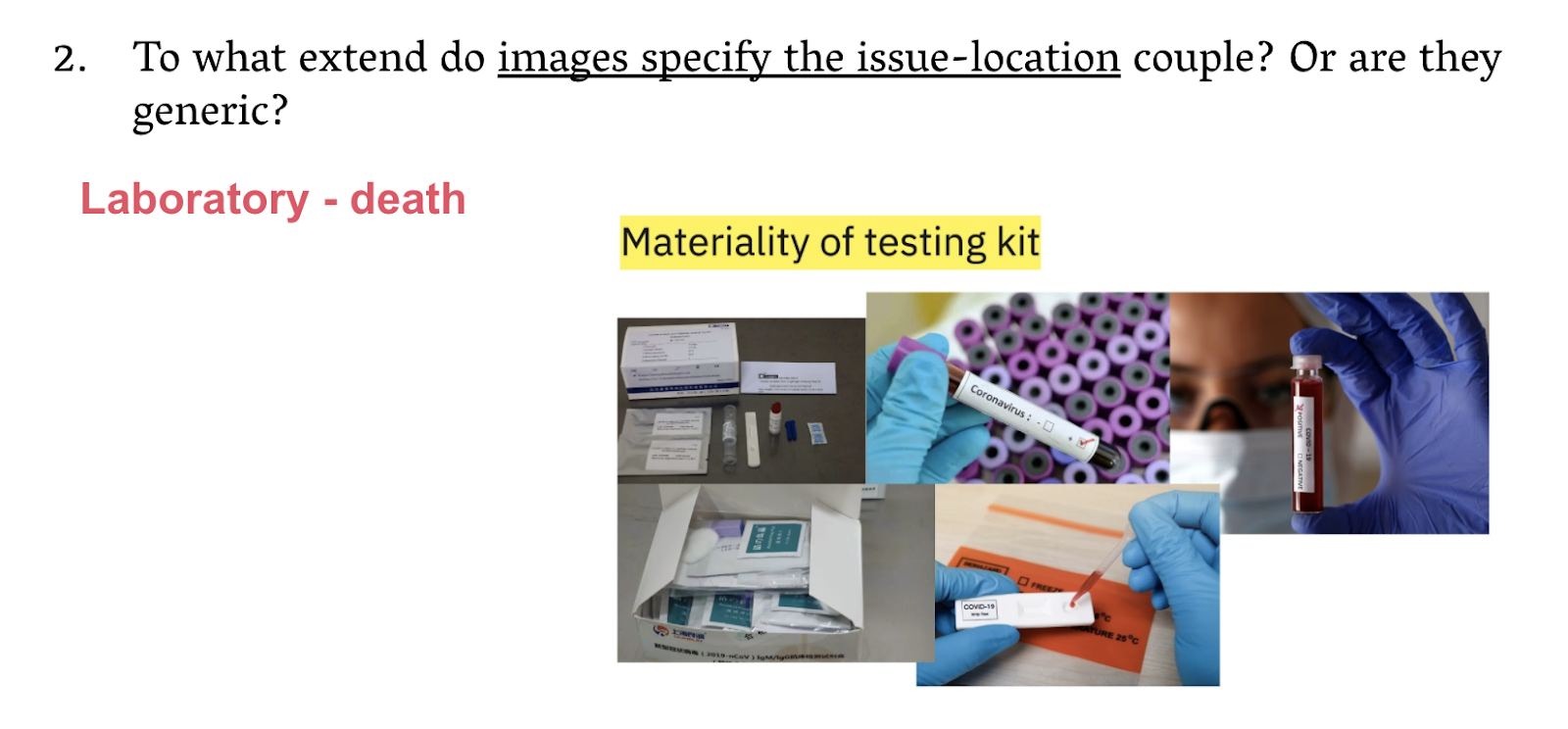
The second interesting finding across locations is the depiction of testing materials and objects, often found in the laboratories, transcending into other spaces, such as the care home. An obvious interpretation of this relates to the prominence of both testing and the vaccine to prevent deaths (One screenshot: ‘materiality of testing kit’): AXIS OF INTERPRETATION 2

In these two images, ‘Test results’ specifies the sharing of care responsibilities between intimate relations and key workers. Images of prayer and church suggest the presence of -- and an appeal to -- a broader community of care (pray for a negative test result, pray for someone who tested positive), though from these images ‘test result’ is not specified explicitly (need textual context).

6. Notes
1. Le-CAT was developed by the Centre for Interdisciplinary Methodologies (CIM) in collaboration with the Media of Cooperation Group at the University of Siegen. Le-CAT was coded by James Tripp. It has been used to support workshops on YouTube as Test Society (University of Siegen) and Digital Test of the News (University of Warwick) and the MA Module Digital Objects, Digital Methods (CIM, University of Warwick).7. References
Timmermans, Stefan, and Iddo Tavory. 2012. ‘Theory Construction in Qualitative Research: From Grounded Theory to Abductive Analysis’. Sociological Theory 30 (3): 167–86. https://doi.org/10.1177/0735275112457914.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Topic revision: 20 Oct 2020, NoortjeMarres
Ideas, requests, problems regarding Foswiki? Send feedback