Research Persona as Digital Method
Team Members
Project lead: Esther Weltevrede, Wendy Chun, Liliana Bounegru, Alexandra Juhasz, Ganaele LangloisParticipants: Carina Albrecht, Elena Aversa, Kath Bassett, Nayana Dhavan, Adam Ferron, Jonathan Gray, Anne Helmond, Ben Hunter, Daniel Joseph, Ioana Jucan, Lieke Rademakers, Noemi Schiavi, Julia Scott, Linan Tang, Kim van Ruiven, Fernando van der Vlist, Yixiu Wu, Chris Young,
Designers: Alice Ziantoni, Bruno Zilli.
Contents
1. Research Persona as Digital Method: Exploring the Temporality and Affectivity of Information Disorders
This project is concerned with personalised information disorders on social media. The question is how to study information disorders in times of personalisation. There seems to be a discrepancy between big data scrapes and the highly personalised media practices of current media environments. While some strands of digital research bracket out the user and their practices, this is not always achievable or desirable when studying personalised media spaces, even when users and their practices are not the main focus. This project experimented with the research persona (cf. Dieter et al.), a research-dedicated account to track activities and information online. More specifically it developed four perspectives for research persona making: (1) the self-persona, (2) the ‘ready to connect’ persona, (3) the fictional persona and (4) ‘in media res’ persona.1. The Self Persona: Exploring the Self as User with the Walkthrough Method
The objective of this exercise is to explore the depth of the user experience, to uncover its affective charge and to develop skills for researching affect. Being a social media user is paradoxically a lonely experience. While as users we might spend our time connecting with information and with other users, what we actually feel when we engage in these practices is not something that we usually discuss. Most of us might actually feel uncomfortable and anxious with being a user - after all, we are trying to project an image of ourselves that we know is a fabrication. Being a user is an exercise in crafting modes of being, of relating in usually complex, demanding digital environments. How do we negotiate this mediation? Being a user is an intimate, private experience, even though as users we are constantly captured, monitored, profiled, prompted, probed by the platform we are on, and by other users. As users as well, we strategize our practices, making choices as to how we engage with platform affordances. What drives these choices and what do they reveal about how we understand our positioning as users and respond to it? This exercise is about exploring our user experience. We work in pairs to understand how we navigate, use and connect on specific platforms, the sense of self we derive from it and the negotiations that we engage with. This is an ethnographic approach where we move from identifying with a user account to looking at it from another perspective, and therefore understanding the interplay between our actions and inputs and the ways in which the platform prompts us to act. Instructions: working in pairs, choose one of your social media accounts (Facebook, LinkedIn, Twitter, Youtube, etc), and walk your partner through your typical use of your account. Your partner will ask you questions such as: “how often do you check this account?”, “how long do you stay on it?” and other questions about why and how you use a specific platform. Purposefully describe to your partners how you interact with the interface, why you posted specific kinds of information, how other users relate to you and so on. Pay attention to prompts from the platform: what kind of recommendations are generated, and how do you feel they relate to you and our intentions as a user of a platform? Writing Exercise:- Describe the user as a person in one sentence. What overall sense of the user as a person do you derive from both what you saw on the interface, and what the user told about themselves?
- Why is the person using this particular platform?
- How is the person using this platform?
- How does the person reacts to prompts from the platform?
2. ‘Ready to connect’ Persona: Exploring the Information Campaigner Perspective
The objective of this exercise is to explore how the digital media, PR and advertising ecosystems conceptualize the type of user they want to target within specific information disorder campaigns. This particular exercise draws from design and marketing, where imagining an ideal user for whom to design a product or service is common. However, it explores a complex ecosystem of information disorders, with many different actors (e.g. political parties, think tanks, NGOs, advocacy campaigners, advertisers, etc.), to understand the kind of aspects of the user that are targeted. Through document and interface analysis, the aim is to understand the techniques and materials used to activate and enlist users in (dis)information campaigns. This is done by inhabiting, exploring and documenting media environments of the assembled research persona. Steps that might be taken in this process include: 1. Mapping the data spaces of persona-making Question: What is the data space of persona-making according to different platforms, devices, infrastructures and media spaces? Issues to consider:- What are the data fields and categories which are available to advertisers and others who use platform data?
- How are persons rendered legible and intelligible using data?
- What are the data fields which are available to users when they sign up and use a platform?
- What insights from the self-ethnographic exercise could be relevant for the creation of the research persona?
- How are data spaces of persona-making organised across platforms, advertisers and other actors?
- What are the natively digital objects and methods which can be repurposed to understand user practices from the perspective of platforms and devices (e.g. links, tweets, likes, groups, hashtags, rankings, etc)?
- What are existing datasets that could be repurposed as starting points (e.g. list of junk news stories)?
- How can these be analysed to elicit features (eg topical interests) that can be used for persona making?
- How can one “follow” natively digital objects in order to explore the relations between users, issues and devices?
- What are the different ways of creating 1/10/100 personas based on your dataset?
- What are the themes that might become a target of misinformation campaigns? (eg immigration)
- What sources can be used to understand users and user practices (e.g. targeting ads; demographic/ethnographic studies of content publics)?
- Which fields could be populated using these materials?
- What is present and what is missing in these materials to populate the data space of a given platform or device?
- How can you use this data to attend to how personas are assembled from the perspective of platforms and devices?
- How is it that personas can generated are made possible in specific ways in order to attend to the various interests of platform data users (e.g. advertisers, political parties, etc)?
- What are the conditions of persona-making that you have encountered?
- What decisions are involved in assembling personas?
- What kinds of agencies are involved in assembling personas?
- How many personas and how to combine and analyse different datasets and sources to create them?
- Do you want to attend to the variety of different kinds of personas or weight them proportionally to the datasets that you have?
- How to occupy, inhabit and give life to the persona? What kinds of interactions might you have?
- Regular/programmed interactions vs sporadic interaction
- Acting on all vs some recommendations (and which)
- Liking groups based on a set of seed content?
- How can you observe, document, record and account for how the persona elicits certain kinds of content, personalisation, media environments, experiences, interactions?
- What kinds of data might you gather from these explorations?
- What are the ethical issues that arise?
- For example around interacting with other users?
- How might you use the personas to (re-)perform an issue from different perspectives?
- How can personas be animated in order to attend to their platformised, datafied and machinic conditions of co-production?
- How might platform users and others engage with personas? What can they bring and what can they learn?
- How might persona-making be broadened and modified from specific profesionalised practices (e.g. systems design, audience segmentation) to prompt critical encounters and reflections between persons and personas?
- How can personas provide light on the various forms of methodological individualism and collectivism “baked into” platforms and devices?
- How might the performance of a persona interfere with, breach, interrupt or otherwise intervene with the media environment under examination?
3. Fictional Persona
This exercise is based on character building techniques from theater practice, specifically character design guidelines developed by Elmo Terry-Morgan, adapted and extended by Ioana Jucan. The interest is in how to build a feeling, affective persona that has the capacity to meaningfully encounter and be transformed in the digital environment. We start by asking in what kind of situations would you need to create or feel comfortable creating a fictional character? Character aspects to develop include:- Background + life-story: What are the remarkable/life-changing events in their background that shaped who they are and how they think. Is there a secret in their background? What kind of environment did they grow up in?
- Rationale: What are the character’s goals and motivations? How do they go about achieving this? Are there obstacles in their way?
- Embodiment: What do they look like? How do they speak? How do they hold themselves in the world?
- Sub/Unconscious: What are the person’s habits of thinking, living that they are not aware of = automatisms? What is this person’s affective universe? What are a couple of contradictions that define this person?
- Debriefing with participants: how does this exercise contrast with the previous one? What kind of relationship do you feel towards your character? (in this instance, the character animates the data).
- Contextual
- Dependent on questions asked, platforms used, discipline, etc.
- What are the ethical limits in terms of interaction with platform and potentially other users?
4. Personas in Medias Res: Multiplicity vs. Fragmentation
This approach sees research personas being constructed by combining one or more of the perspectives described above, depending on what the research question of the project is. The assembled research personas are let out in the digital world and its interactions within a digital context are tracked. For example, the affective changes in the persona as it encounters information strategies are of interest. For instance, crafting a fictional persona might benefit from elements of our self persona, for instance, browsing habits, media consumption habits, or values, psychological traits and triggers. The research persona could also benefit from the ready-to-connect persona: what kind of psycho-social category would the fictional persona be close to, whether they would accept it or not. In the second part of the exercise, participants launch their persona online: refining their social media profiles, and then browsing, consulting and interacting with information. Rather than just “forcing” an issue to pop up by searching for it, this step of the exercise asks that participants spend some time developing browsing habits, to develop a context of use rather than just focus on hitting the “right” kind of content immediately. So for instance, rather than looking for “immigration” on Facebook (who uses Facebook search for keyword queries anyway?), imagine the kind of online news sources that your persona might consult. Would they perhaps like or share a news article on an immigration story? Say to their (fictional) spouse, because they have differing opinions on the topic and quarrelled about it a bit last night? It is best at this point to continue working in groups to verbalize steps and thoughts, and keep a diary of this walkthrough. In the diary, participants can record:- User actions as they correspond to the persona’s profile and browsing habits
- Prompts from the platform in relation to actions: including recommendations, ads, and so on.
- Triggers: prompts that the persona would respond to, both big (e.g. an important news) and more mundane (a refreshed newsfeed)
- Events (transformative, worldview shift, allegiance): the moments of meaningful interaction, and transformation
- affective state of mind, both at specific times and over a browsing session
How to integrate backend connections research into this: understanding the capturing of users on the backend of platforms and the kinds of informational infrastructures that create potential mobilization of users (users as standing resources from an infrastructural perspective).
2. 'Proxying Personas'
Proxying Dating Apps
Proxying Gaming Apps
Group: Kath Bassett, Daniel Joseph, Julia Scott, and Chris YoungIntroduction
Our perogitive with this sub-stream of the ‘Proxying Personas’ project was to ‘poke around’ the back-end of Slotomania (the top grossing gambling app in both the Google Play and App Store) in order to better understand how the player/user is being captured and profiled during the main event of the game -- “the spin”. We did this in order to shed light on what facets of user profiles (or personas) are relevant to developers and potentially profitable for stakeholders and third parties. Due to some complications which arose during data collection (which will be detailed later on), we can’t speak as much about Slotomania’s third party relationships, however, we found proxying useful due to its ability to reveal the concealed sociality of the game. We reckon that the game is designed in this manner to ensure its profitability and that the "house always wins".Research Questions
When (and where) is ‘the social’ located in Slotomania? Is the game social for the user? Or how might ‘the social’ be utilized by and monetized by game developers?Methodology
In order to ‘poke around’ the back-end of Slotomania we used the Charles proxy. Charles is an HTTP monitor that runs on a computer. Once the tool-user has configured their web browser and/or mobile application ('app') to access the internet through Charles, the proxy is able to record and display all the data that is sent and received. This includes all of the HTTP and SSL/HTTPS traffic between their machine and the internet in the form of requests, responses, and the HTTP headers (which contain cookie and caching information). While this tool is marketed to web and app developers as a means to quickly diagnose and fix problems (such as ‘debugging’), we repurposed the tool for social research purposes.
In the case of our project, we used the Charles proxy to track how the user profile (or persona) is constructed and developed as the user engages with and progresses through Slotomania. Unlike creating a profile (or ‘persona’) on dating apps where the user exercises some control over their profile (i.e. how they appear to other users) before or in between engaging with the app more seriously (‘swiping’), the user of Slotomania doesn’t get this same opportunity to craft a profile. Instead the user of Slotomania’s profile is wholly a by product of their interaction with the app (‘spinning’). So while the profile/persona construction of the former might be usefully compared to how one becomes a Facebook user, the latter (our case study) is closer to how one becomes a Spotify or Netflix user. More specifically, we were interested in learning what events on the interface / from the perspective of the user, trigger inter & intra-game communications on the back-end in order to answer the first part of our research question about the temporality of ‘the social’. It was within tracking it’s temporality, that we found it necessary to also discuss the ‘where’ of the ‘the social’.
As mentioned earlier, many complications arose while trying to use the Charles proxy which shaped the direction our project took. These complications were mainly related to utilizing an Android mobile device for running these tests. For example we discovered that the majority of games we wished to use the proxy on could not be used without editing them on APK first, which turned out to be extremely time consuming, and ultimatly beyond the scope of our skill-set and short timeline. Similar to how certain games wouldn’t work with the Charles proxy without editing them in APK first, we discovered that while the Slotomania app worked with the proxy, that the game’s attempts at connecting with social networking platforms, like Facebook wouldn’t work without first editing them in APK first. This in turn limited the extent of data that we could collect and analyze about Slotomania and ultimately meant that we couldn’t learn about some of the external and third party connections that the dating app group was able to access. While this was a tad disappointing, we still found what was revealed by the proxy to be fruitful for understanding how the game is designed and monetized.
For data collection, we started out by running a 30 minute test of Slotomania. Here we had one person play the game and narrate what was happening on the user’s end, one person keeping an eye on Charles and narrating what was going on in the back-end, and two people spectating and taking notes about the relationship between the front and back ends. This 30 minute play through rendered an overwhelming amount of data. Because of this, we decided to hone our data-capture further and picked a single event to focus on -- that of 'the spin'. We captured three spins and allowed the proxy to run for slightly different amounts of time in order to capture the spin-event from the user interface, backend, and 'event with noise'perspectives. These three types of data-captures comprise our ‘Event Capture’ protocol:
'App Event Capture' Protocol
- User Capture ('in-game event' -- see Figure 1)
- Capture data around entire animation (spin and reward)
- 5 second capture
- Event from the perspective of the user (i.e. what we have an interface screen capture for)
- Procedural Capture ('in-app event' -- see Figure 2)
- Capture data around the entire animation (spin and reward) + data that compliles afterwards
- 20 second capture
- Event from the perspective of the app/developer (i.e. what we have a backend screen capture for)
- Noise Capture ('post-event')
- Capture data around entire animation (spin and reward) + data the compliles long afterward (i.e. What other types of background information are being gathered? How is the app trying to prompt the user out of sitting idle?
- Arbitrary 1 minute capture
- Event from the perspective of the app/developer
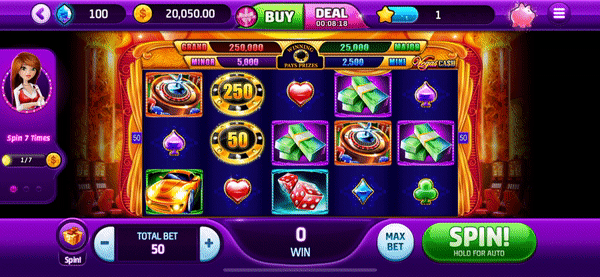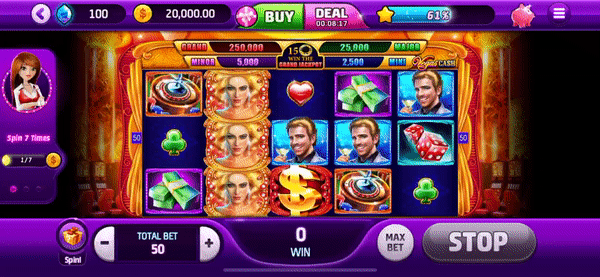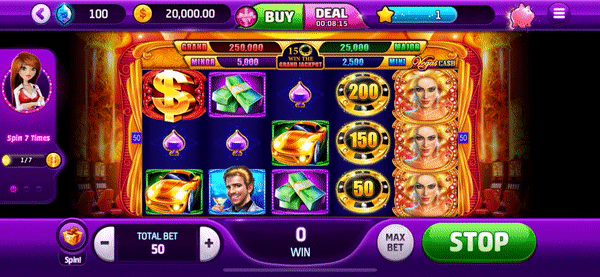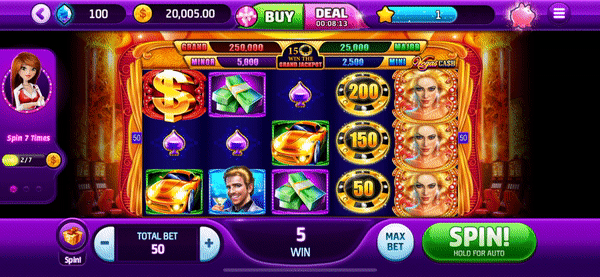 Figure 2: 'In-App Event'
Figure 2: 'In-App Event'

Findings
Applying our 'App Event Capture' protocol to the Slotomania 'spin-event' revealed that the developer/app is capturing and communicating 'contextual information' around spins. The 'winners' data that it retrieves is on you, the individual player/user, AND other players/users. This includes IDs for users, slot machine, jackpot, pool, as well as prize and ratings of players betting at the same time (Figure 3). It appears that players' bets are regulated and authenticated through a shared 'ledger' which keeps track of all other player/users in your cluster, their progression, and winings through a shared set of IDs. Figure 3: 'Spin Event' incoming & extracted data To put more simply, we found that the individual player/user is clustered and placed in a 'room' with other players, and that the other inhabitants of this cluster/room act as a barometer for individual player/user outcomes. Important to note, the only place where the 'room' architecture is hinted at on the user's end/user interface, is on the screen where the various slot machines are displayed and if they click the < button on the top left hand side of the screen, which reads "return to lobby". Otherwise the inherent sociality of the game is hidden from the user/player on the front-end, giving the impression that this is a solitary experience.
To put more simply, we found that the individual player/user is clustered and placed in a 'room' with other players, and that the other inhabitants of this cluster/room act as a barometer for individual player/user outcomes. Important to note, the only place where the 'room' architecture is hinted at on the user's end/user interface, is on the screen where the various slot machines are displayed and if they click the < button on the top left hand side of the screen, which reads "return to lobby". Otherwise the inherent sociality of the game is hidden from the user/player on the front-end, giving the impression that this is a solitary experience.
Discussion
Our findings suggest that the individual player/user of Slotomania acts as 'router' which developers can learn from using a constant comparitive approach to furthur develop the game AND in order to identify traits and create useful categories, like 'rooms' and 'pools', to mediate the outcome of the player's spin via hidden in-game mechanics. This latter system is likely in place to govern players/users -- to ensure that they can't cheat ('game the system') or win too big. "Fishy behavior" then, depends on the norms/behaviors of other players you have been clustered with. This system may additionally mediate player/user trajectories differently as they progress through the game. For example earlier on, it is easier to win in-game money and prizes, while later on it becomes more difficult. Typically mobile games are designed to reward players/users more frequently in the begining in an effort to 'hook them' and to make the possibility of spending their real money ('micro-transactions') later on more appealing. In this way the app is 'socialising' interactions to ensure that the "house always wins", and that the casino app is as profitable as possible for it's stake holders.Conclusion
Methodologically speaking, we found the Charles proxy to be useful for making the concealed sociality of the game (Slotomania)and the app event ('the spin') visible. From the user's point of view, the game isn't inherently social -- it appears and feels as though ones interaction with the slot machine ('the spin') alone shapes the outcome (prize allocation). However, by examining what is going on in the back-end, it becomes apparent that the user is not alone and is actually assigned to a 'room' populated by other players/users where the other players/user's interactions with the game, in your same room, come to shape your spin outcome (prize allocation). To us, this demonstrates that 'being online' is not just an app authentication procedure. Instead the flows of data about 'the social' feed the game's algorithms, and in doing so, shape individual and aggregate outcomes to ensure that 'the house' maintains it's privledge. Additionally this data is likely sent to, utilized by, and valuable to app developers' efforts to modify the game over time in order to maximize it's efficiency, profitability, or whatever other goals they may wish to pursue. In this way, Charles made the 'contingent commodity' visible -- revelaing, in real time, Slotomania as "malleable and modular in design, and informed by datified user feedback, open to constant revision and recirculation" (Nieborf and Poell, 2018, pg. 2).3. Art & Performance
Performance title: CONNECT.CONNECT.CONNECT.
Performance script: available here.
Performance video: available here.
Concept and goals for the performance
-
Creative methods (like performance, scripting, metaphors, images) are useful formats to express, explain, feel and understand complicated analyses, difficult questions, and concepts with more than one answer; we want the play to manifest and contribute to the research findings;
-
It can visualize findings of research in an embodied, affective, complex way in space and time and can be received as such;
-
It is a powerful form to undo and redo logics that drive information disorder, recharging affective charges that have been used to manipulate users.
Creation process
1. Background and beginnings
We started from:
-
Research findings and key questions (compiled here)
-
The fictional characters and research personas developed during previous sessions.
2. World-making
-
Select characters, materials, stories, ideas to work with (from 1)
-
Articulate a play structure & situations that embodies concept and intended effects on the audience based on the selections made
-
Write the dialogue & stage directions (the affect bot was used for text generation, as were some basic improvisation prompts)
-
Script reading & revising
3. From play to performance
-
Assign roles to performers
-
Blocking & staging (led to script modifications due to certain staging restrictions -- for instance, some of the actions were described by the Narrator instead of being performed live onstage by the performers)
-
Rehearsals
-
Performance presentation.

Image: Play structure & roles assignment
The Affect Bot
The Affect Bot is a project for the Beyond Verification research group, an algorithm where you can choose an affect (culled from this lexicon) from a dropdown menu and it constructs fragments based on what is selected. Each time a new phrase is generated, the old ones are stored on the right side of the screen. They are erased when you refresh the page.
The bot was used in our play as a character that interacts with our research personas Joao and Carina. For the purpose of the play, we have “fed” the original bot with new poems that echo sentiments related to refugees, war, gender and sexuality. The result was a different set of expressions that illustrates the sentiments we wanted our robotic character to express. For more information on the bot’s code and how to feed it more information, please refer to Roopa Vasudevan’s GitHub repository.References
- Dieter M, Gerlitz C, Helmond A, Tkacz N, van der Vlist FN and Weltevrede E (2019, June 7). Multi-situated app studies: Methods and propositions. Social Media + Society, 5(2), 1–15. DOI: 10.1177/2056305119846486.
Slides
- Final presentation: https://docs.google.com/presentation/d/196ASaRUhz3zPFHoJ8x95-zQ7d-auy_3z7s2JgSKO330/edit?usp=sharing
- Book chapter: Bounegru, L., Devries, M., & Weltevrede, E. (2022). “The Research Persona Method: Figuring and Reconfiguring Personalised Information Flows“. In Figure: Concept and Method, C. Lury, W. Viney & S. Wark (eds). Singapore: Springer. [open access]
Ideas, requests, problems regarding Foswiki? Send feedback