Bots and the black market of social media engagement
Team Members
Lead: Janna Joceli Omena, Jason Chao & Elena Pilipets. Participants: Bence Kollanyi, Bruno Zilli, Giacomo Flaim, Horacio Sívori, Kim van Ruiven, Lieke Rademakers, Mengying Li & Serena Del Nero (alphabetical).
Slides:
- Project pitch: https://docs.google.com/presentation/d/1GwW0cFrGg4w9a1y1NATyjnXJGpHwmszjII1IQdwyjJk/edit?usp=sharing
- Final presentation: https://docs.google.com/presentation/d/1qH2E6QLohCHjn-8I-Y8fgVR9tLyiJPK7R3_9vsRZXns/edit?usp=sharing
Contents
Summary of Key Findings
In our project we explored the involvement of bots in the black market of social media attention economy. Based on our investigation of various intensities and qualities of automated engagement on Instagram and Tumblr, we developed a situated understanding of this market as an ensemble of software affordances, human interests and techniques of mediation. In doing so, we primarily focused on the overlapping dimensions of web applications, bot imagination and bot agency.
Web apps selling automated engagement provide us with the entry points for investigating the means by which commercial value is generated on social media (1) the promise of authentic, involved and targeted audiences, (2) the redistribution of engagement aimed at generating more organic activity, and (3) the continuous aggregation of data. Besides simulating ‘realness’ and authenticity, web applications feed the black market of engagement by ‘hijacking’ social media accounts to discreetly follow and like other accounts ‘on behalf’ of the users. Additionally, they take advantage of software and social media affordances to steal money from those who are eager to get attention easily. As services, web applications add value to all kinds of social media activity by using marketing strategies and terminologies. Seen through this lens, the quality of automated likes, comments and followers always has its price.
In this context, a wide range of attitudes and dispositions that we describe as ‘bot imagination’ adds another layer of complexity: By tracing #bots on Instagram and Tumblr, and exploring the variations in its positioning and stance, we detected two spheres: ‘expectations’ and ‘frustrations’. Bot expectations correspond with the promotional promise of rapid growth in the name of social media visibility (see chatbots on Instagram) and confirm the main narrative of web applications celebrating fake followers as “real” users. Bot frustrations are oriented towards debunking this narrative (through users’ screenshotting practices) and give us insights into the role that automated engagement plays in the transition and moderation of platform environments (see pornbots in the context of Tumblr Purge).
Bot agency on Instagram and Tumblr has different platform-specific articulations. Characteristic of bot accounts that we think in terms of visibility are rhythmic, repetitive patterns of content distribution shared by multiple accounts sequentially (one after another within a short timeframe).
These patterns may reveal persistence over time (Instagram) or assemble actors into bot farms with multiple accounts sharing the same imagery and links (Tumblr). Automated accounts that operate in more discreet ways are designed to remain invisible and unrecognizable as bots. These are the main actors in what we call ‘the black market of social media engagement. By shifting back and forth between visibility and invisibility, they enact different forms of engagement: from bot agency that can be easily detected by purchasing engagement or using the affordances of digital methods to more ambiguous constellations of redistributed attention that can stick to platforms or flow across the web.
1. Introduction
Social bots have been around since the early days of social media. These software agents have helped us in better understanding web platforms infrastructure and showing how vulnerable social media are to large scale-infiltration (Wang, 2010; Boshmaf et al. 2011). Social bots promptly respond to the purchase of fake followers/likes to promote politicians, they spread misinformation during elections, proliferate social media advertising, and subtly attempt to manipulate public opinion, among other abnormal activities (see Chu et al. 2010; Boshmaf et al. 2011; Woolley, 2016; Woolley and Howard, 2016; Murthy et al 2016). Often with a bad reputation, social bots are part of our everyday life and deserve our attention. Over the past years, the power of automation combined with the affordances of social media APIs have changed the way we see, interact with and study social media platforms.
Scholars have developed different techniques to approach social bots; from taking advantage of platform graph and content-based features through creation and use of bot accounts to the adoption of machine learning classifiers (see Wang, 2010; Wagner et al. 2012; Wald and Sumner, 2013; Omena, 2017; Sen et al. 2018, Yang et al. 2019). Following these studies, a good understanding of bots functioning and agency requires equally a good perception of the platform functioning and its programmable infrastructure. In this project, we approach the involvement of Instagram and Tumblr bots in the black market of social media engagement through Gerlitz & Helmond’s notion of social media attention economy. In doing so, we aim to repurpose hashtag-based data collection and the adoption of boost engagement applications to understand how Instagram and Tumblr bots create specific relations between "the social, traceable, and the marketable" (Gerlitz and Helmond 2013, 1362).
Situating the black market of engagement through bots
In a general view, the black market of engagement implies the drive of fake followers, likes and comments to accomplish a particular purpose - namely popularity, the spread of political ideas, demonstration of influence, etc. These hidden automated practices are part of our everyday digital life thanks to Internet-based software affordances and social media APIs. As a response to the complications caused by bots, social media platforms present clear rules to avoid malicious use of automation. However, Terms of Use, Community Guidelines, etc are often ignored. Users, companies, organizations, developers (including boost engagement applications) do not always abide by platform data policies (see Omena, 2017). To provide an in-depth view into this, the interrogation of the black market of engagement requires a platform-sensitive approach that takes into account the hidden/invisible and visible practices attached to it. In this context, we focus on three interconnected dimensions:
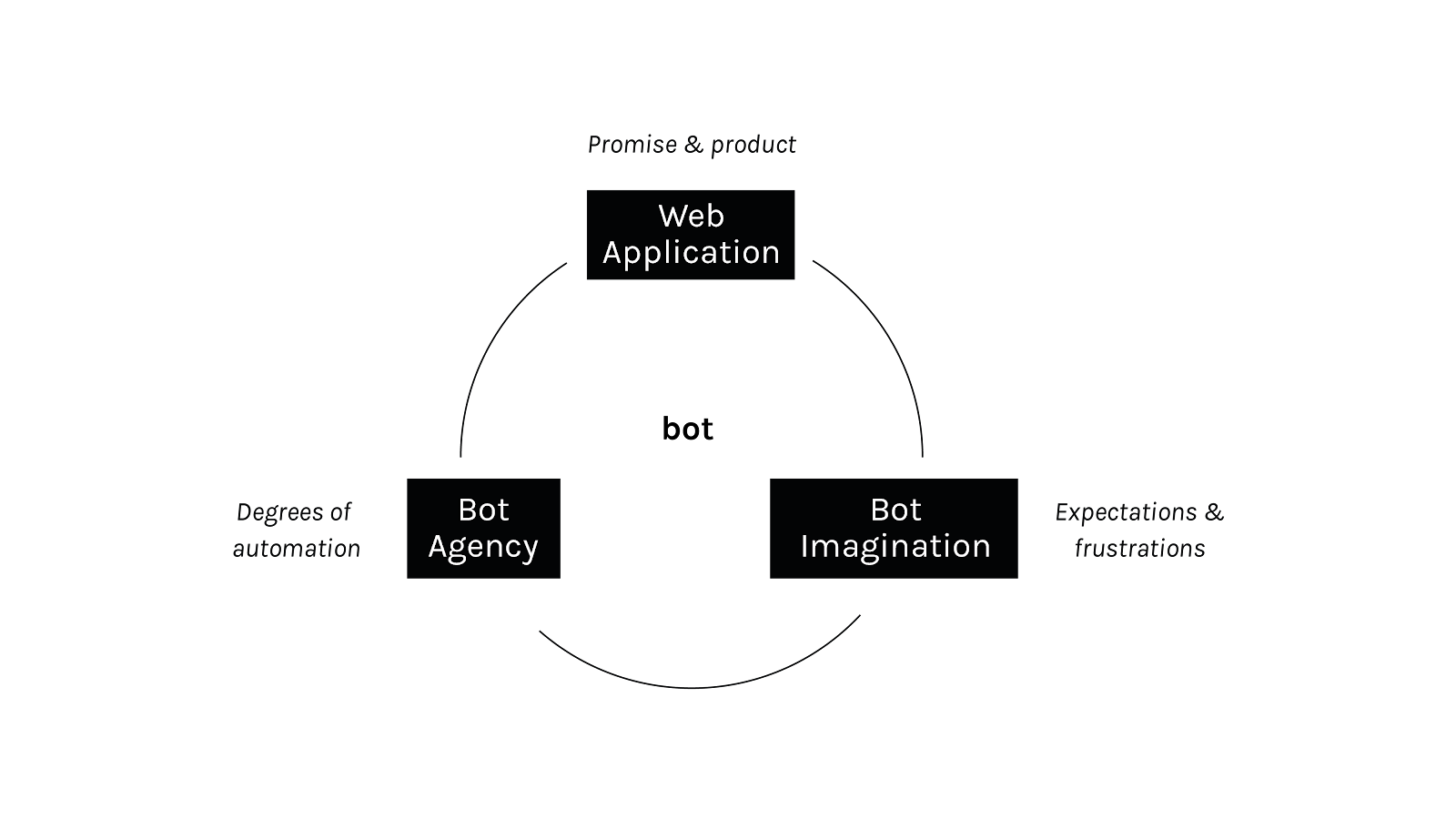
i) web applications*: thick descriptions of mobile or web applications that support bot activity (e.g. app description, forms of payment, minimum requirements) combined with a grasp of social media APIs, terms of services and data policy (How platforms may legally allow botting? How platforms may contradict or not abide their only principles to avoid fake accounts? How they prevent or stimulate automation?).
*While mobile applications had a notable reduction since the update of Instagram Platform API to Instagram Graph API, the availability of web apps for selling comments, likes and followers seem to remain intact.
ii) bot imagination: the exploration of platform- and subculturally specific ways of understanding, imagining and engaging with different forms of automated agency. For instance, how do Instagram and Tumblr users relate to the issue of bots? How do they imagine what bots do? What can we learn from the exercise of tracing memetic visualitity and textutality of #bots? How do bots affect and are affected by users’ platform interactions?
iii) bot agency: the exercise of tracing, describing and analysing automated beings in action. How does a bot profile look like? How do bots behave? What visual and text content do they share? How does bot-generated content flow across platforms? How do they ‘fit’ into the platform ecologies of social media engagement?
Instabots
Botted accounts on Instagram are usually associated with celebrities, photographers, marketing and influencers (Wilson, 2017; Maheshwari, 2017; Ref), and more recently these accounts have also appeared in the context of health studies, politics and demonstrations. For instance, the detection of botted accounts in the dominant and ordinary voices in Zika Virus and Dengue hashtag-related content (Rabello et al. 2018) or when conservative, right-leaning and far right botted accounts take a high-visible place over Brazilian protests in 2016 (pro- and anti- impeachment of Dilma Rousseff) and in 2017 (stay- and get out- Michel Temer) (see Omena et al. 2017; Omena, Mintz and Rabello, forthcoming) or in the exploration of hashtag networks and image circulation in the context of Brazilian presidential elections in 2018. In so doing, instabots not only intervene in hashtag studies but in the public and political debate (see Murthy et al. 2016; Woolley 2016; Woolley and Howard 2016; Omena, 2017).
The agency of bots on Instagram, which is facilitated by third-party applications, can be summarised by the traceability of hashtags (to boost or promote visual content) and by different types of botted accounts. These latter are programmed to automatically create content or reply comments, engage with hashtags’ lists by liking publications and following other accounts. On the basis of previous exploratory research and the affordances of Instagram Platform API, we were able to identify two types of botted accounts and, consequently, better understand their logic of functioning.
Tumblr (porn) bots
On Tumblr, bot accounts are part of a diverse subcultural ecology known for being intensely engaged in the distribution of pornographic content (see change.org, Coletto et al. 2016). Most recently, in the wake of the so-called “Tumblr purge”, the conditions of how user- and otherwise distributed content circulates on the platform have changed (for an exploration Tumblr’s previous policies in this context see Gillespie 2013, 2018). In December 2018, after being suspended from Apple’s App Store over child pornography issues, Tumblr banned all sexually explicit images from its users’ Tumblogs in a move that not only transformed the environment of bot engagement but also negatively affected multiple body-positive platform subcultures (see e.g. Duguay 2018; Paasonen, Light & Jarrett 2019). In this context, especially the failure of automated filtering tools (aka “censor bots”) on the one hand and the proliferation of porn bots on the other have attracted major criticism (see Arora 2019). Whereas, previously, bots were mainly operating by appropriating/hijacking trending hashtags (both NSFW-related and random), the main components of Tumblr bot agency after the purge are that of following and posting content without using hashtags (Pilipets 2019).
Addressing different forms of bot detection on Instagram and Tumblr
Visible (or purchased) bots that can be detected through buying engagement via web/mobile apps and using lists of hashtags correspond with these qualities:-
Real or fake accounts that rely on automation to boost engagement or to make particular content more visible (e.g. most active users in political-related content)
-
Usernames can either be weird (e.g. swph965, _beta__1, awesome.vs.amazing) or try to mimic ‘real people’ (e.g. sabrinaejr, williamc_clarke, b.ianca.); thus hard to differentiate from non-automated accounts in a dataset.
-
Actions are visible in the user-end interface, but usually difficult to identify in a dataset
-
Promptly respond to the adoption of a hashtag list by liking the post (and sometimes commenting)
Tumblr
-
Fake accounts detected through purchasing engagement
-
Use standardized avatars and random names also (but not always) in combination with numbers like williamhammilton1, davintaylor, gabriellaglittner
-
Can be used to boost engagement around particular topics/posts without sharing content
-
Respond to the adoption of a hashtag list by liking the post (and sometimes commenting)
Invisible (or hypothetical) bots that can be detected through the process of data collection, username patterns, hashtag engagement & visual network analysis and (for Tumblr only) manual exploration of image archives and note sections correspond with these qualities:
-
An army of fake profiles created to automatically like hashtagged content, (un) follow accounts, create content and make comments
-
Wired usernames often constituted by a sequence of numbers accompanied or not by letters, underscore or names among other atypical combinations (e.g. 6151, 98.00715, ______160.0cm, 6.13kkk, _0318_m)
-
Actions are invisible in the user-end interface, but technically simple to identify in a dataset
Tumblr
-
Weird or sexy usernames with numbers indicate automation or semi-automation (e.g. jaclyn2000admirable, translover6969691, dixon2546) but are not reliable in terms of differentiation from the non-automated accounts on Tumblr (e.g. xxxshanshanxxx, zeldafan42, zodiac709, zan-77) and hence difficult to identify in a dataset
-
Detection in the process of data analysis often requires manual verification
-
Image archives are characterized by rhythmic, repetitive patterns of posting
-
Similar account names that appear one after another in the note section and share similar images indicate a bot farm
2. Initial Data Sets
WEB APPLICATIONS
The initial list contained 50 web applications identified through investigating the possibilities of purchasing engagement on Tumblr. Since all sources from the list were also offering engagement on other platforms (including Instagram), we took it as a starting point for our explorations during the first day of the sprint. At the end, we extended the list up to 97 unique web apps, analysing thus a total of 127 different URLs (several web applications that were added provide services only for one of the platforms in question).
BOT IMAGINATION
The data was extracted by querying #bots through Instagram Scraper (max. 1000 most recent posts; choice corresponding with the specifics of the Instagram Scraper) and DMI Tumblr Tool (3145 posts covering one year of engagement in 2018; choice corresponding with the exploration of user-bot issues before and during the announcement of Tumblr’s new community guidelines).
BOT AGENCY
Data collection was based on the API calling followed by the scraping of botted accounts that were detected through:
i) the purchase of engagement through mobile and web applications. In addition, we also created research accounts on Tumblr (alex_ash_ash; my-dear-sexy-bot) and Instagram (@mary__loo025);
ii) the process of analysis and visualization of different hashtag datasets, and;
iii) the act of engaging with Tumblr hashtags and profiles.
| Unique Visible Botted Accounts | Unique Invisible Botted Accounts | Parameters for Data Analysis | |
| 281 (detected through the purchase of engagement via web/mobile apps) |
460* (hypothetical: detected through the process of data collection and analysis via hashtag engagement and username patterns)
|
The selection of the 30 most recent publications uploaded by each botted account and its related metadata |
|
| Tumblr | 241 (detected through the purchase of engagement via web apps) |
442** (hypothetical: detected through the act of engaging with Tumblr profiles - note section, and tracing hashtags)
|
** data extraction based on #sfw, #kinky, #bored, #selfie, and manual following of related blogs through comment/note sections
3. Research Questions
Digital Methods: How can we study bots and their agency as constitutive parts of the black market of Instagram and Tumblr engagement?
Web applications: What can we learn from web apps that support bot activity? (Who are the companies/developers/technologies behind it? What can we learn from apps descriptions, forms of payment and minimum requirements for buying engagement?)
Bot visuality and subcultural ecology: What can we infer from the visual analysis of botted accounts and their respective modes of activity and related visual and textual content? How can we understand bot visuality in the context of social media subculture ecology and attention economy? What can user-bot interactions tell us about the specificity of platforms?
Bot agency: What do the different types (agencies) of botted accounts and their relationship with tags tell us about the platformed specifics of automated engagement? [repurposing hashtags lists to categorise bots usernames and to identify the platformed specifics of bot behaviour]
4. Methodology
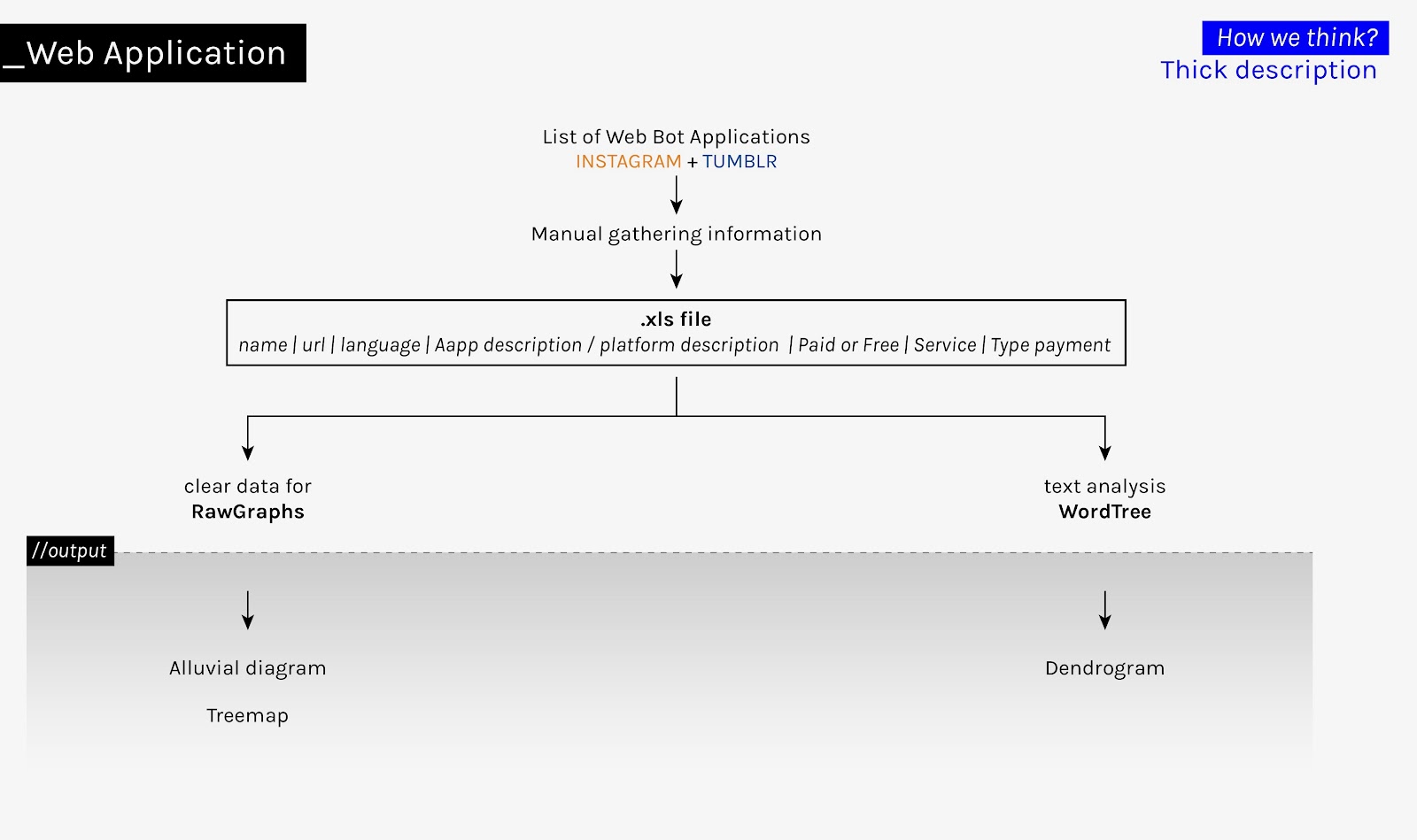
To provide a thick description of Instagram and Tumblr web apps, we built an expert list of 97 unique web apps that support automation out of a total of 127 different URLs covering app descriptions, forms of payment and minimum requirements to purchase fake engagement. The thick description of the web apps was conducted by 8 people with different national backgrounds, language and expert skills. The following attributes were considered: web app description, platform description (Instagram and Tumblr), is the service paid or free?, what is offered? (likes, notes, followers, comments, views, etc.), and forms of payment. In addition, we engaged with the services of web apps during the DMI Summer School. To do that, we used an Instagram research account that was created on 18 June 2019, named @mary__loo025. While building the expert list of web apps that boost engagement on Instagram and Tumblr, we tried out some free trial offers by allowing these applications to access Mary Loo Instagram account; thus providing the account name and the respective password. We also relied on paid services to get comments (paid 🤑, but never received 😡). The results of our explorations were visualised and analysed with Wordtree and RawGraphs.
Wordtree procedure
-
Google search for Instagram and Tumblr automated engagement generation web apps (130+)
-
Organize search results in a Google spreadsheet, listing a variety of attributes, among them the one relevant to this exercise: app description, as presented to the user at its homepage. A significant amount was lost due to the absence of a meaningful description or lack of thorough examination.
-
Eliminate duplicates (it is common for web apps to multiply domains to become available in different countries, in different languages, or to different user profiles).
-
Extract an assemblage of the app descriptions in English, by also eliminating descriptions in other languages. Result: 75 valid apps; one unformatted text containing 11,185 words.
-
Eliminate the occasional stop-word or symbol that generates semantically irrelevant results.
-
Select keywords to generate word trees (considering word frequency and proximity). The semantic fields were explored through 12 word trees, we took into account the following words: words such as “boosting/bots”, “active”, “engagement”, “real”, “fake”, “people”, “likes”, “followers”, “money”, “value”, and “benefit”.
RawGraphs procedure
-
Treemap to visualise the different types of payment offered by web applications.
-
Alluvial diagram to detect the relation between the range of services (e.g. the purchase of likes, comments, followers) and whether these are for free or paid for Instagram and Tumblr.
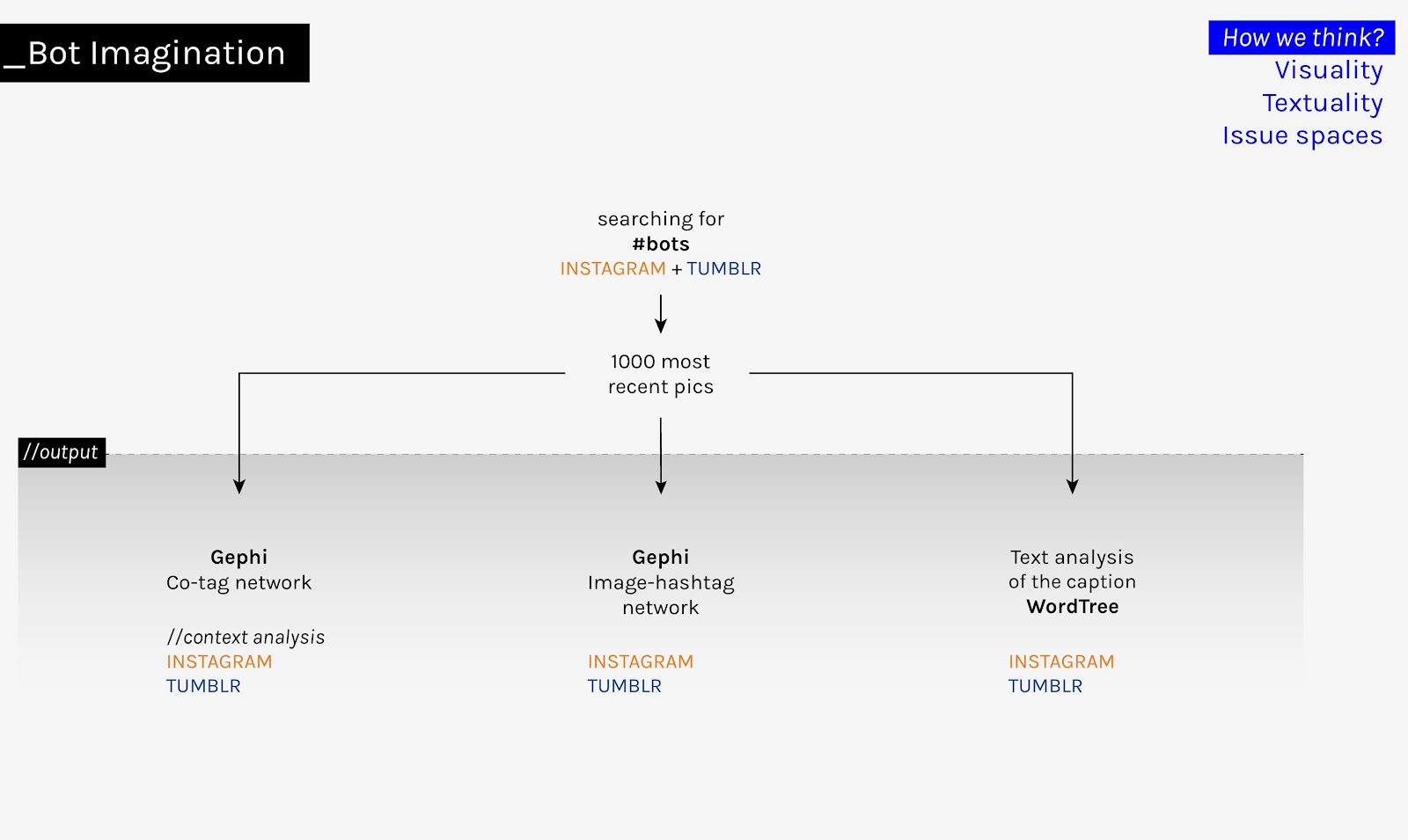
To explore the dimension of bot imagination, we extracted data by querying #bots on Instagram and Tumblr. Taking into account the multiple layers of hashtag engagement on social media platforms (Burgess & Matamoros-Fernández 2016; Omena, Mintz & Rabello, forthcoming) we combined different methods of data visualisation and analysis to better understand the qualitative platformed and subcultural context of user-bot issues.
In the first step, we worked with co-tag networks to map the discussion around #bots on both platforms. Using Gephi network visualisation and analysis, we chose “occurrences count” for node size and ran the “modularity class” algorithm for node colour. For a better visibility, we opted for deleting the main node “bots” in both networks.
In the second step, the text extracted from the captions of Instagram and Tumblr posts has been used as input to work with text analysis (through tag clouds, word trees and WORDij). In this way, patterns in users’ associations with what bots do on Instagram and Tumblr could be discovered and connected with other analytical insights to interpret the dataset.
In the third step, visual content extracted from 611 Instagram and 916 Tumblr posts (other posts were either text-based or contained images with broken links) was analysed through ImageSorter (to discover arrangements of repetition/variation in the visuality of bot imagination) and bipartite Gephi image-hashtag networks (to explore the situatedness of this visuality in users’ hashtagging activities and respective platformed environments).
By drawing these methodological steps together, we produced material to analyse the visual, textual and platformed entanglements of association and concern related to #bots on Instagram and Tumblr.
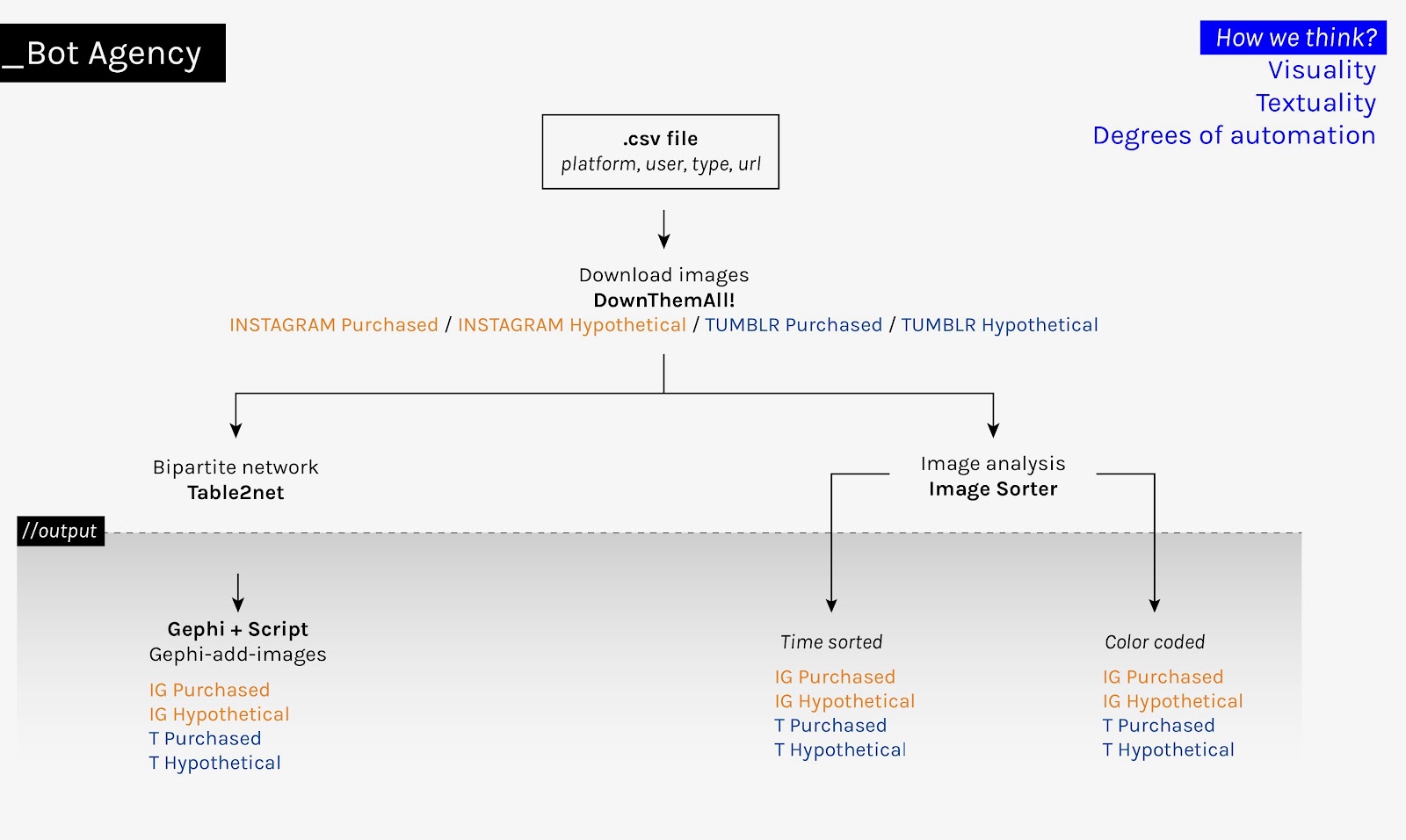
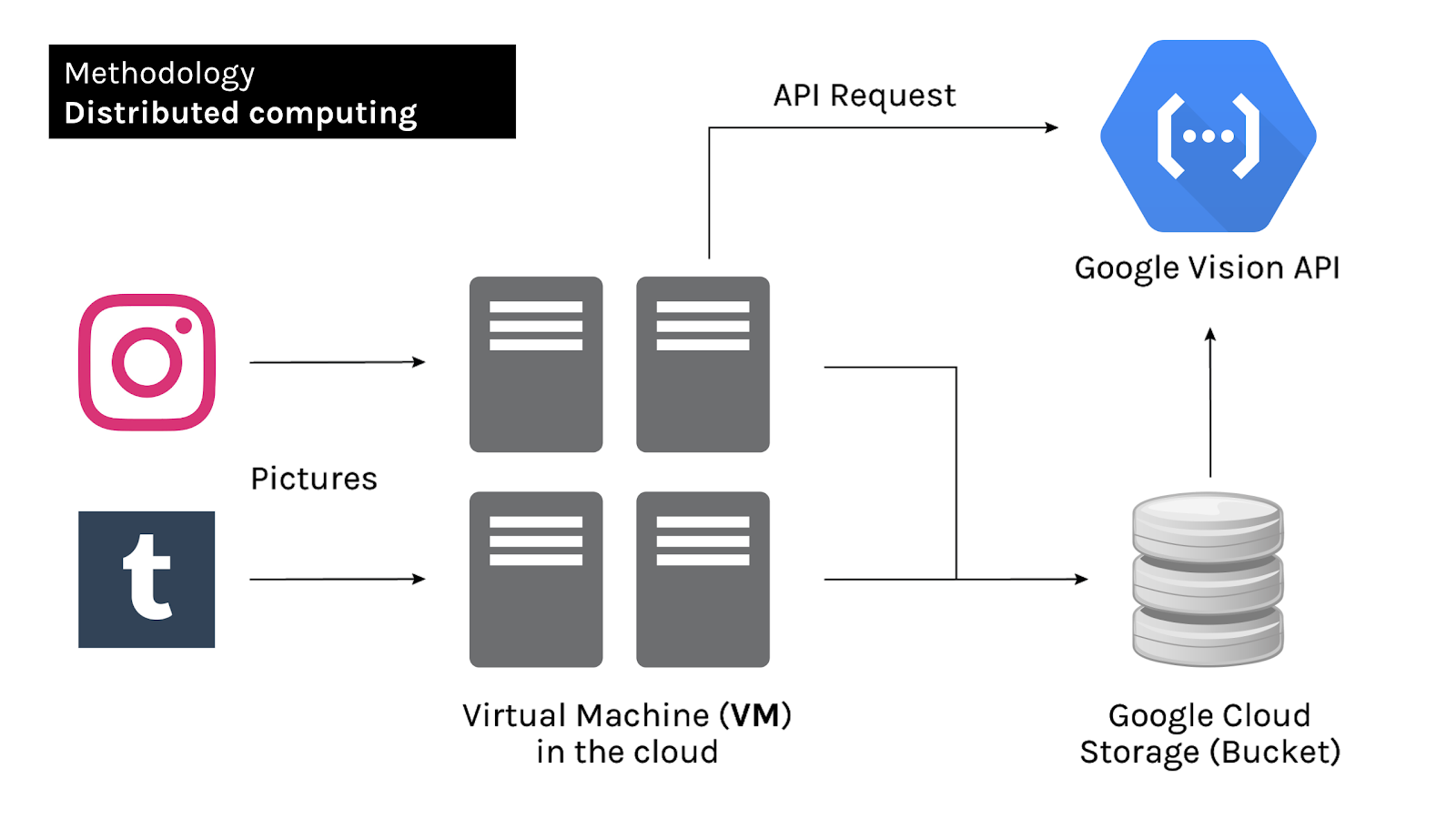
The analysis of bot agency was grounded by distributed computing and the use of a virtual machine in the cloud. With basis on 741 Instagram botted accounts (281 visible, 460 invisible) and 663 Tumblr botted accounts (241 visible, 442 invisible), more close to five hundred thousand media items were scraped from public bot profiles. Data was then kept in Google Cloud Storage since ordinary computers could not handle such a large amount of data. In order to make this project practically viable, and take into account the time constraints, we opted for the last 30 images uploaded by each botted account to date as the parameter to select the dataset. As a result, a total of 11.635 Instagram images and 19.175 Tumblr images served as the starting point to explore the dimension of bot agency (see below).
| Media Items | |||
| Visible Botted Accounts | Invisible Botted Accounts | Total | |
| 4056 | 7579 | 11635 | |
| Tumblr | 7082 | 12093 | 19175 |
For the analysis of the visible botted accounts (purchased) on Instagram and Tumblr, two complementary methods were adopted: the technique of visualising a collection of images, plotted by ImageSorter and organised by time of publication and colour; in parallel with the scrutiny of actor(bot)-image networks (advanced by Table2Net, Gephi and its Image Preview plug-in). In so doing, we were able to in-depth explore the relations between bot visuality and its corresponding owner accounts. Particularly for Tumblr, we also looked at avatar images (a number close to 1000).
For the analysis of the invisible botted accounts (hypothetical), we built three image-domain networks: one combined network for Instagram and Tumblr and two others separating the platforms. In so doing we took advantage of the narrative thread of the spatialisation (see Omena & Amaral, forthcoming) of the network to verify how images travel across platforms (what sticks within the platform and what flows out), and also to verify what visualities are particularly attached to Instagram and Tumblr. The image-domain network was built under the affordances of Google Cloud Vision API, specifically the feature web entities and pages: full matching images. This latter precisely informed us where a given image has circulated across the web. We took into account at maximum 10 different URLs.
Before starting the process of reading the networks, we selected only those images that hit 10 different URLs in order to verify the unique link domains and, consequently, their frequency of occurrence (see this list here). We used DMI Harvest Tool to build the list of hosts names. In this list, beyond social media and image repositories, the porn domains popped up with a high frequency of occurrences. We then turned to ‘porn’ and ‘sex’ to query the full URLs and, among the total of 4.249 unique hosts, we detected 125 porn hosts. After that, and when building the bipartite image-domain networks with the help of Table2Net, we took advantage of this information to add the node attribute isPorn into the bipartite network. The other node attributes were chosen as follows:
-
Node type 1: image. Attributes: full_matching_image_count (1 to 10) to size the images within the network and username to identify the user responsible for uploading a given (or more) image(s)
-
Note type 2: link domain. Attribute: isPorn in order to use a different colour for porn websites
5. Findings
WEB APPLICATIONS: PROMISES & PRODUCTS
The promise of web applications relies on the “realness” of engagement; automation is then presented as “real people”. The ambivalent message thus is: “there are no bots here” but organic activity, so is the claim of web apps. In this narrative people are active and targeted; a sort of engagement which is humanly unattainable, as described in the apps self-presentation. The denial of bot agency is confirmed by the absence of the term “fake” in the web apps descriptions, and their value is attributed to the idea of an extraordinary power to target publics and maximize profit or popularity. In this sense, bots are actually super people!

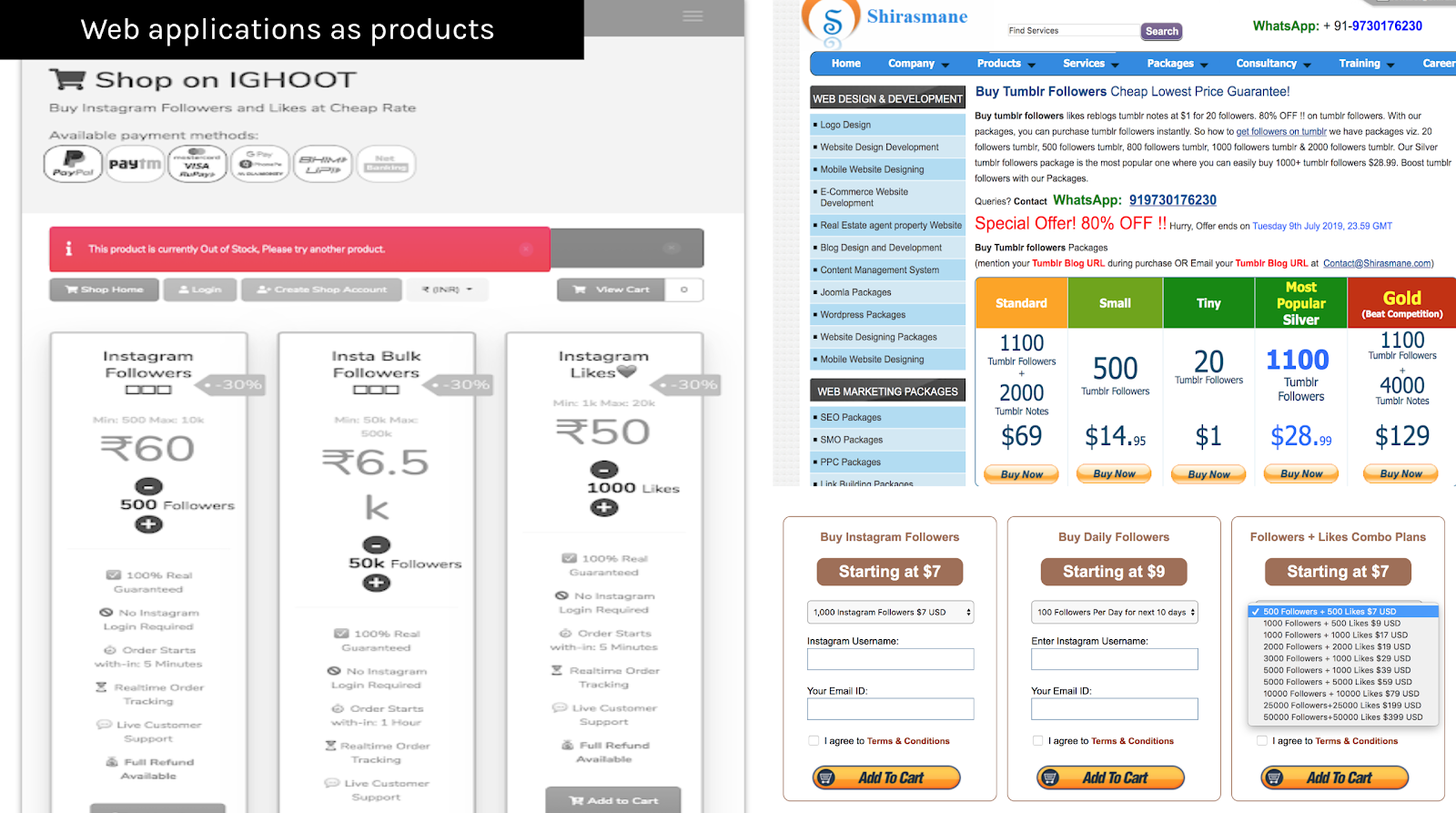
Within the promotional framework of web applications, attention has different degrees and its quality has a price. One may opt for standard, small, tiny, silver, gold services, and sometimes the most required products (e.g. followers and comments) just go out of stock. On the one hand, web applications would use the marketing terms and its cliche slogans, assuring “fast and accurate results at the most reasonable rates” and, in case of dissatisfaction, they would offer “100% money-back guarantee”. On the other hand, there is a lack of professionalism when it comes to the user-end interface of these applications; their presentation is often unsophisticated and not well designed. However, payment navigation is usually quick and unproblematic.
(Using FREE services offered by Web Apps to boost Instagram Engagement).
Engagement as a product is universally attached to its monetized value. Within one click, the user would access platform-specific price lists and for those more hesitant, the free trials as a strategy to convince them about the credibility of the service. Web applications also emphasize the need of any business or public entity to promote itself by enlarging its online following. “Everyone else is doing it, making online commerce and popularity very competitive---an idea of survival of the fittest”.
The rules of this market are “the more the cheaper!”. What is offered? How do people pay for that? We identified followers and likes as the dominant engagement values for both platforms, while comments and views pertains to Instagram particularities. The traditional forms of payment (credit card, debit card, PayPal), including cryptocurrencies such as Bitcoin (BTC), Litecoin (LTC), Ethereum (ETH), XRP, Bitcoin Cash (BCH), are also possible for both platforms. However, the free trials for getting engagement are out of the question for Tumblr; that is exclusively for Instagram.

In this context, and during the DMI Summer School, we have also relied on free trials and paid services to interact with a few web applications. We thus shared the same user name and password for trying out Instagram’s free engagement (see the image below). In order to receive likes and followers, Mary Loo would receive an email to confirm her free boost engagement requirement (and so we did!). It took more than 24 hours to start getting a few likes and followers. We noticed, however, that Mary Loo had actually started following a long list of other accounts; summing up to more than 200 very likely to be botted accounts (before our experiment with web apps, Mary Loo followed only one person: @richardrogers12). As a consequence of sharing her username + Instagram password with different applications, right after the Digital Methods Summer School 2019, Mary Loo was prohibited to log in on Instagram. It took almost three weeks to get her back on the platform (see twitter.com/JannaJoceli/status/1150124727945576448). Regarding paid services, we purchased 50 comments from HashLabb. Although paid with a credit card, the comments never arrived at Mary Loo’s account (see the image below).
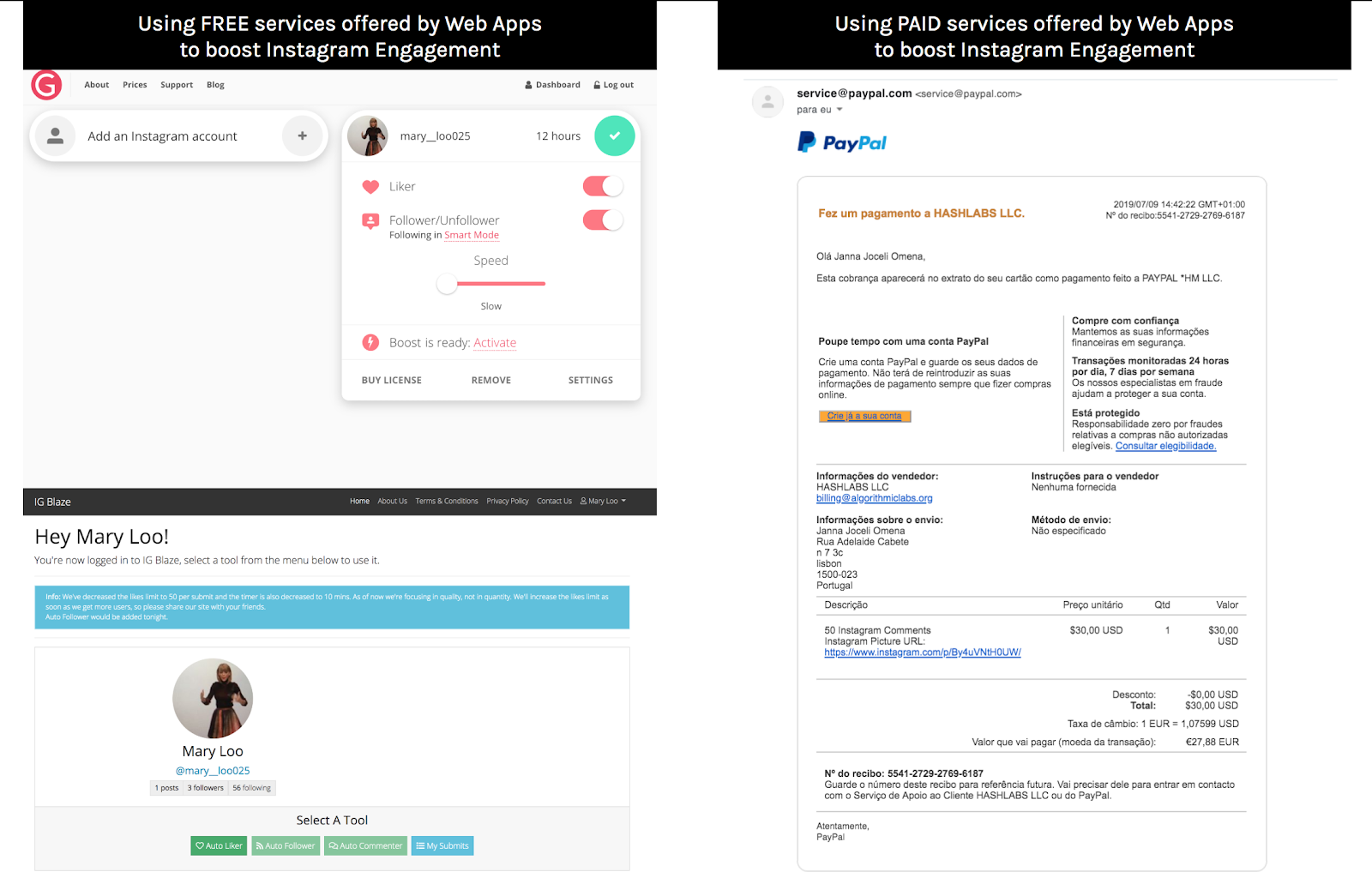
As a result of the free trials for boosting Instagram engagement, we concluded that web applications tend to partly deliver what is promised (e.g. likes) while, at the same time, they hijack real accounts in order to feed the black market of digital economy; by acting on behalf of the user to start following other Instagram accounts. As a result of paying to get engagement, and based on previous similar experiments, we may say that some web applications are intentionally created to “steal money” from those who are eager to easily get likes, comments and followers. Other applications, especially those that are more expensive, partly deliver what is promised.
BOT IMAGINATION: EXPECTATIONS & FRUSTRATIONS
In the dimension of bot imagination, a range of user-bot issues could be identified by situating user- and otherwise distributed visual content in the platform-specific relations of tagging. Composed by shared and singular concerns, subcultural affinities, and various scenarios of hashtag and image appropriation, these issues divide the Instagram and Tumblr #bot networks in the following alignments of interest, critique and association:
By cross-reading cotag and image-tag networks for #bots on Instagram, we observed three major clusters which are respectively related to gaming, business/marketing, and products/services. In addition, a less densely connected grouping of hashtags in the middle of the network contains user-generated robot-themed art randomly associated with ‘‘cyberpunk’, 'spacerobot', 'dragonart', 'sports', 'graffiti', etc.).
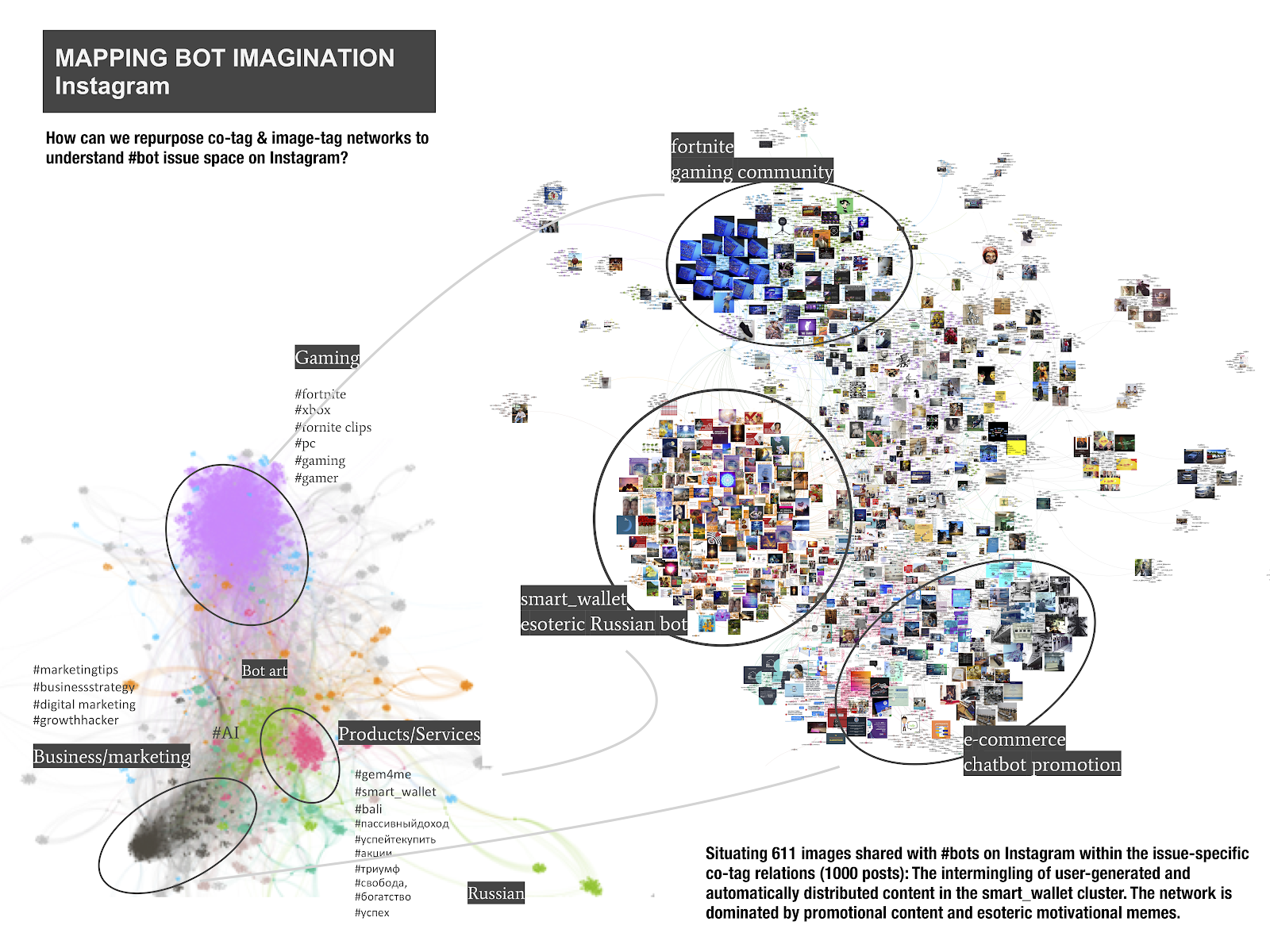
Among the hashtags most used in connection to e-commerce and marketing (in dark-grey), we identified 'marketing tips', 'businessstrategy', ‘chatbotdesign’ and 'growthhacker'. Promoting the idea of acquiring as many followers/users as possible with minimal human resources, the visuality of this cluster is characterized by combinations of marketing slogans with bot icons and colourful backgrounds. In pink, another big cluster focuses on the promotion of products and services such as ‘gem4me’, a messenger service that commits to earning money for users through add-ons such as ‘marketplace’ and ‘smart_wallet’. Both cotags are related to the promises of wealth ('rich', 'wealth', ‘genius', etc.) as well as a series of tags in Russian celebrating the ideas of freedom, success and good life. Interesting about this cluster is that it builds a distinct image-tag sphere. Supported by a stylized esoteric visuality, motivational text-based memes, and repetitive use of the same tags/captions (reading in Russian, e.g. “I am beautiful and strong”), it uses automation to spread gem4me content. The gaming cluster in violet at the top of the network is dominated by the ‘fortnite’ tags, an online video game community, in which “bots” is a common expression used to describe new inexperienced players. Connected to other fandom-relevant tags such as 'xbox', 'fortnite clips', 'pc', 'gaming', 'gamer', the images in this cluster are mostly dedicated to avatar screenshots.
The main particularity of Instagram #bot imagination therefore can be observed in the promotional stance of the main clusters revolving around automation for purposes of rapid social media growth. Here, unsurprisingly, text analysis of image captions corresponds with the main promise of web applications.
Associated with influencer marketing and brand promotion, Instagram chatbots are considered to “become increasingly popular” because of their ability to “productively interact with audiences” and “discover most qualified sales opportunities”. In this context, users’ expectations of bots are high, for what bots apparently provide us with is social media visibility.

Tumblr
Tumblr’s subcultural ecology revolves around art-related, body-positive, and politically engaged communities with a strong emphasis on identity and sexuality issues (see e.g. Tiidenberg 2015, Cho 2015, Pilipets 2019 forthcoming). The exercise of exploring the network of user-bot issues on Tumblr reveals these particularities in a specific way. The most visible cluster in the image-hashtag network comes from an automated account sharing geometric art imagery with a series of associated hashtags. In the main co-tag network, another visibly automated activity is provided by a text-based fan bot account “Roxxi-Android” dedicated to “shitposting” about popular American drag queen reality competition series RuPaul ’s Drag Race. Together, these easily identifiable automated beings showcase different articulations of bot agency interfering in Tumblr’s platform ecology. Beyond that, Tumblr bot imagination is engaged with the following issues:
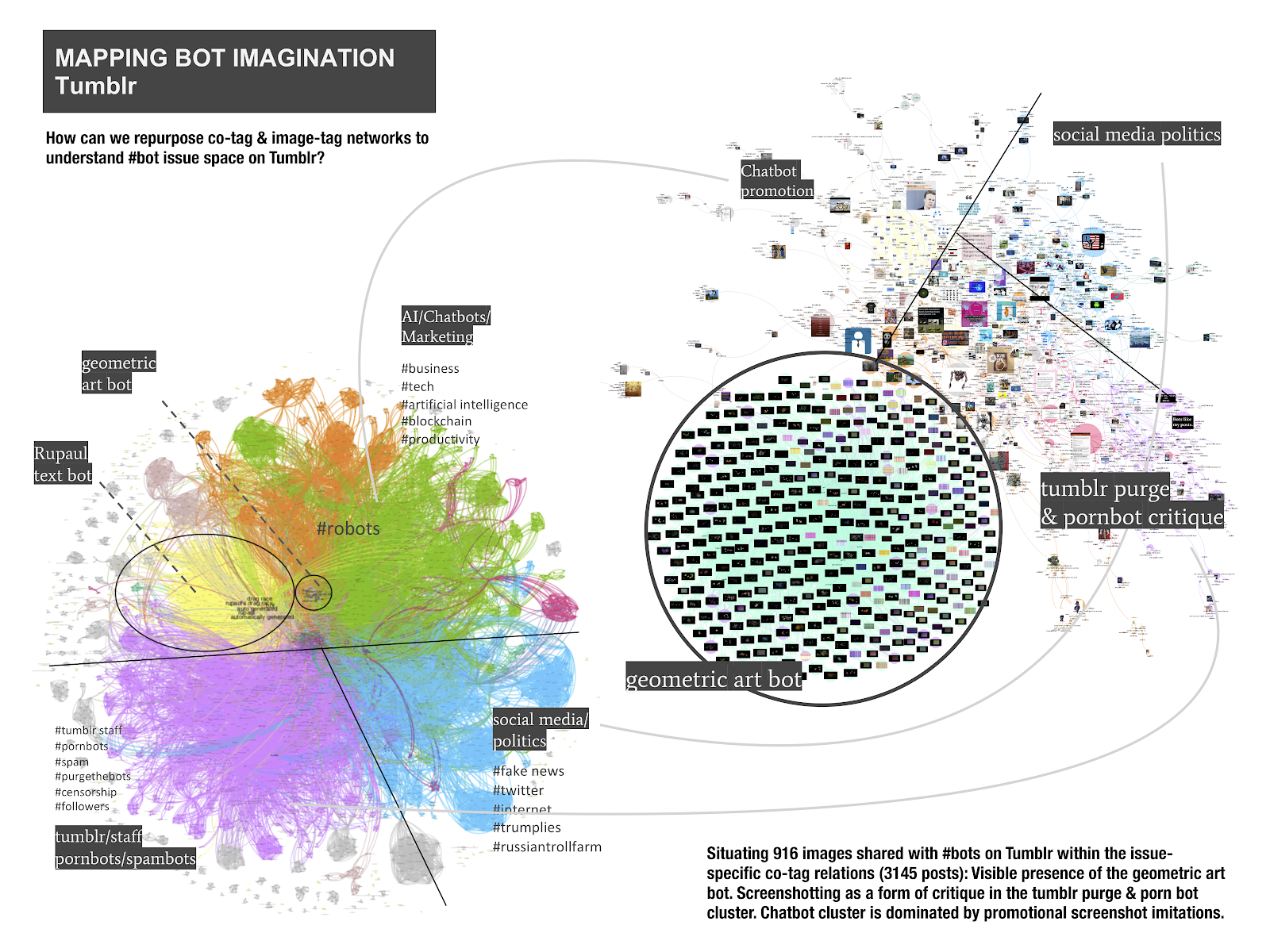
The first is represented by an Instagram-like chatbot marketing cluster containing a series of promotional screenshot imitations (chatbot templates for Facebook messenger). Next to it, a small image-hashtag space (in orange) is dedicated to bot illustrations and digital art. The social media politics cluster (in blue) is dominated by the discussion of social media manipulation in the context of political campaigning and elections (#fake news, #elections, #russiantrollfarm). While, like on Instagram, the first two clusters are focused on imagining bot agency as something powerful and generally productive, the third appears to be a space of critique directed against the notion of bot farms and fake news.
The third and biggest cluster (in violet) is dedicated to crique of automation in the context of Tumblr’s recent adult content ban, also known as “Tumblr purge”. Here, hashtags such as “purgethebots”, “tumblr”, “staff”, “pornbots”, “censorship” and “tumblrpurge” indicate a platform controversy, which plays out between two main sources of concern:
The first is related to Tumblr’s ethically challenging decision to ban all NSFW (not safe/suitable for work) and adult imagery (including “female-presenting nipples”) by relying on machine-learning classification. In this context, the fact that Tumblr algorithm was not well trained (for a short discussion see Tarleton Gillespie’s Twitter feed) provoked outraged reactions of those whose content was ‘classified’ in a wrong way. Starting December 2018, the use of the hashtags “censored” and “flagged” resulted in a notable dynamic of sharing screenshots containing images that were automatically hidden from public view because Tumblr would identify them as porn (see the rhythm of users complaining about being censored over time in this image plot). Bringing together anime illustrations, traditional sculpture and art imagery, drawings of fictional characters, cat photos, erotic selfies, text-based memes, and lingerie model photography, these contributions emphasize the failure of algorithmically driven image recognition when it comes to the understanding of context. A quick view on the image-label network for #flagged provided by the affordances of Google Vision API annotation gives us an idea of this dynamic: Only 16 out of 331 user-reported images that were flagged on Tumblr in December 2018 are labelled by Google as “likely adult”. Against this background, another important possibility for future research is that of tracing how the notion of platform moderation in the context of Tumblr Purge has shifted towards the use of the term “censor bots”. Introduced during the implementation of new community guidelines in December 2018, it repositions the notion of ‘bad’ platform moderation by reimagining censor algorithms as ‘bots’ and bots as ‘dumb’ in a series of memes. Both ephemeral and subculturally saturated, the value of these dynamics in the context of digital attention economy unfolds in relation to memetic content circulating beyond Tumblr and shaping the controversy across platforms (see Pilipets 2019).
The second concern comes along with the problem of porn and spam bot accounts which would continue invading users’ comment sections after the purge without being censored by Tumblr. Through text analysis of post captions, we were able to identify multiple references to pornbots getting “out of control”, “more aggressive” and “more intelligent”. This also corresponds with the findings coming from the explorations of #bots visuality through Image Sorter and image-hashtag network:
The image-tag cluster containing frequent mentions of #tumblr, #pornbots, and #staff is dominated by screenshots documenting and reporting pornbot accounts that interact with and follow users. What these posts suggest is that, while censor bots act dumb, pornbots are getting smarter. Another interesting insight in this context derives from the exercise of cross-reading text and image-hashtag networks: On Tumblr, the common practice of screenshotting and recaptioning pornbots “in action” inverts the promise of fame and attention catered by web applications. Here, bots are definitely no longer imagined as “real people”. They are revealed as “fake followers”.

While exploring different articulations of bot imagination, we followed the proposition of taking into account the mediating role that platformed visual and textual objects play in the negotiation of specific issues (Marres 2015; Niederer 2018; Rogers 2018). Instead of emphasizing the logic of engagement metrics and content popularity (the frequency of use of a particular image/hashtag), it allows to explore the shifts in relations of relevance and visibility as they unfold in networks of natively digital objects and platformed practices of cultural appropriation. By paying attention to the resonance of tagging practices with images that they distribute, we discovered a complex ecology of associations feeding into how Instagram and Tumblr users understand, imagine and engage with different forms of automated agency. In doing so, we identified different trajectories of association and concern, which raise important questions about the interference of bots in two spheres of social media attention economy: The first is related to the idea of influence scores, facilitated through platformed arrangements of hashtag appropriation, following and liking (see Messias et al 2013; Leistert 2017). The second derives from the multiplicity of communities, institutions and publics that add value to these arrangements through their cultures of use (Wooley et al. 2016; Etsivah 2018).

Thinking about the entanglements of bot imagination and bot agency goes hand in hand with the necessity to engage with the sociotechnical embeddedness and the manifold functions of platformed automated beings. The main advantage of this approach is that it can be used to produce a relational view on how bots are perceived in their capacity to interact and shape the communicative dynamics on social media.
BOT AGENCY: DEGREES & QUALITIES
Visible botted accounts (purchased)
The visuality of Instagram visible botted accounts suggests two modes of existence: one for commercial and advertising purposes; and another that try hard to imitate ‘real/ordinary’ accounts. After analysing the actor (bot)-image network (see below), we unpacked these activities and identified what sort of products are often promoted by instabots: cars (@world_fastest_cars), clothes (@buster.shop), eyebrow treatment/shaping (@saramagicbrows), makeup (@allisongirodaymakeup), gastronomy (@leettyskitchen), barbershop (@concept_barbershop_siracusa). The promotion of services or products leads us to online shopping websites. For instance, the publications of @shopkubikaonline always point to its website and we can even locate this shop on Google maps. Beyond marketing goals, most of the images attached to instabots are actually photos of ordinary people in an everyday context, such as selfies, kids laughing, tourist photos, friends having fun etc.

However, when we look back at the actor- image network, we see a clear pattern; that is each bot account is posting pictures and selfies of the same person over and over again. Consequently, it suggests that botted accounts try to present themselves as ordinary people. Furthermore, what struck us in this context was realising that some of these accounts no longer exist.
Given this background, and to provide a good example to illustrate bots disguised by ordinary people, we followed @ginakasimir. At first glance, this Instagram account may give one the impression that Gina is a human being. However, this account responded to a given web application at the very moment we had required engagement from this latter. Thus, Gina Kasimir may either be fully or partially automated account. What is also interesting is that, by searching the same id, we found a Facebook account posting the same images we have found on Instagram (see above and also slides 44 and 45 of our final presentation). By lurking on Gina Kasimir’s Facebook profile we found a link to a Tumblr post, which says “this girl will never forget to turn off the webcam again”. From Instagram to Facebook, from Facebook to Tumblr and back and forth, what we see is how botted accounts lead us to navigate cross-platforms to others, probably, automated accounts.
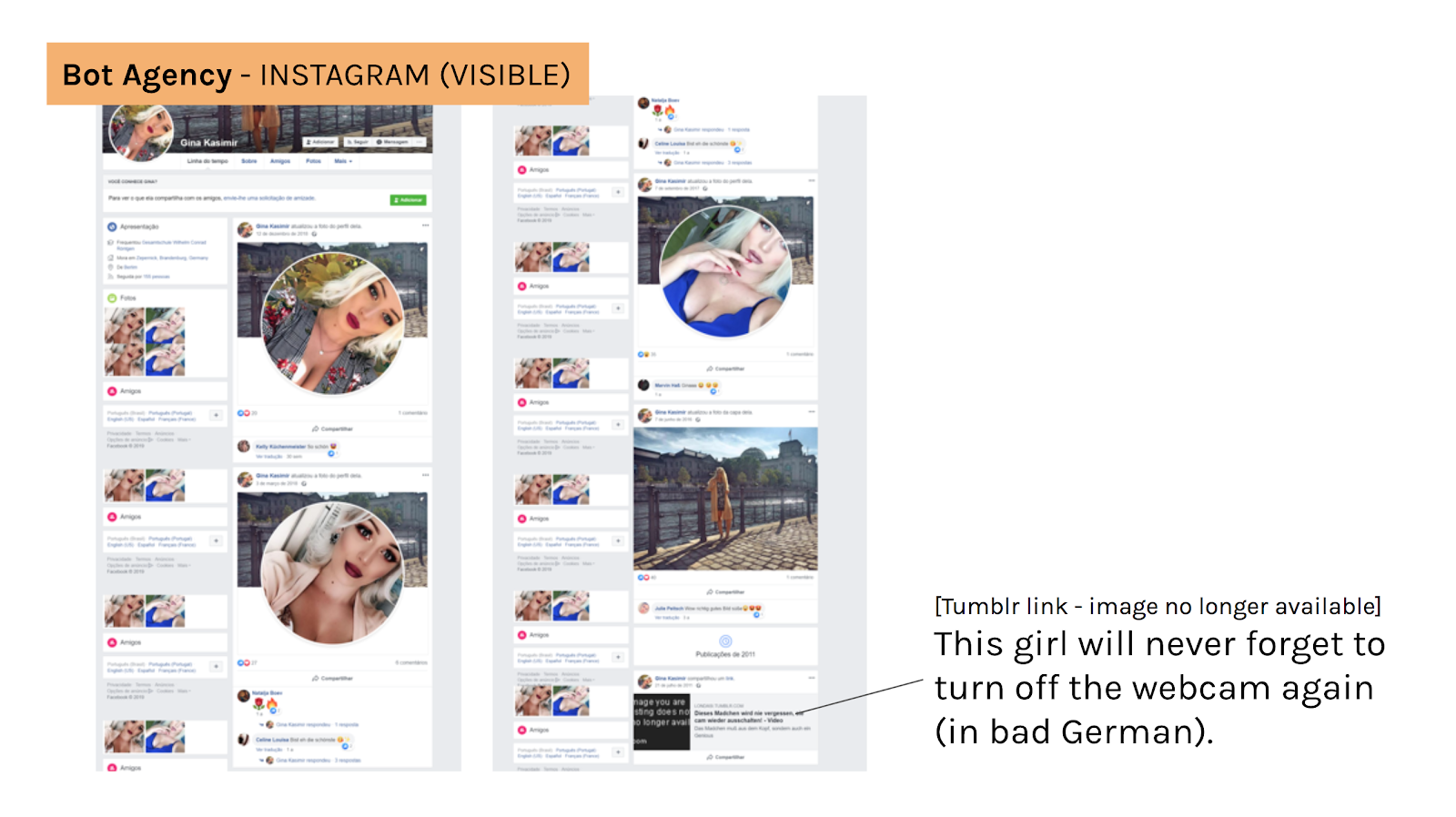
We may say that visible botted accounts on Instagram either stand for business accounts (better saying the consumption of services or products) or the effort to mimic ordinary people. Additionally, we are also aware of how difficult is to measure or to be sure about the degrees of automation attached to botted accounts.
Tumblr
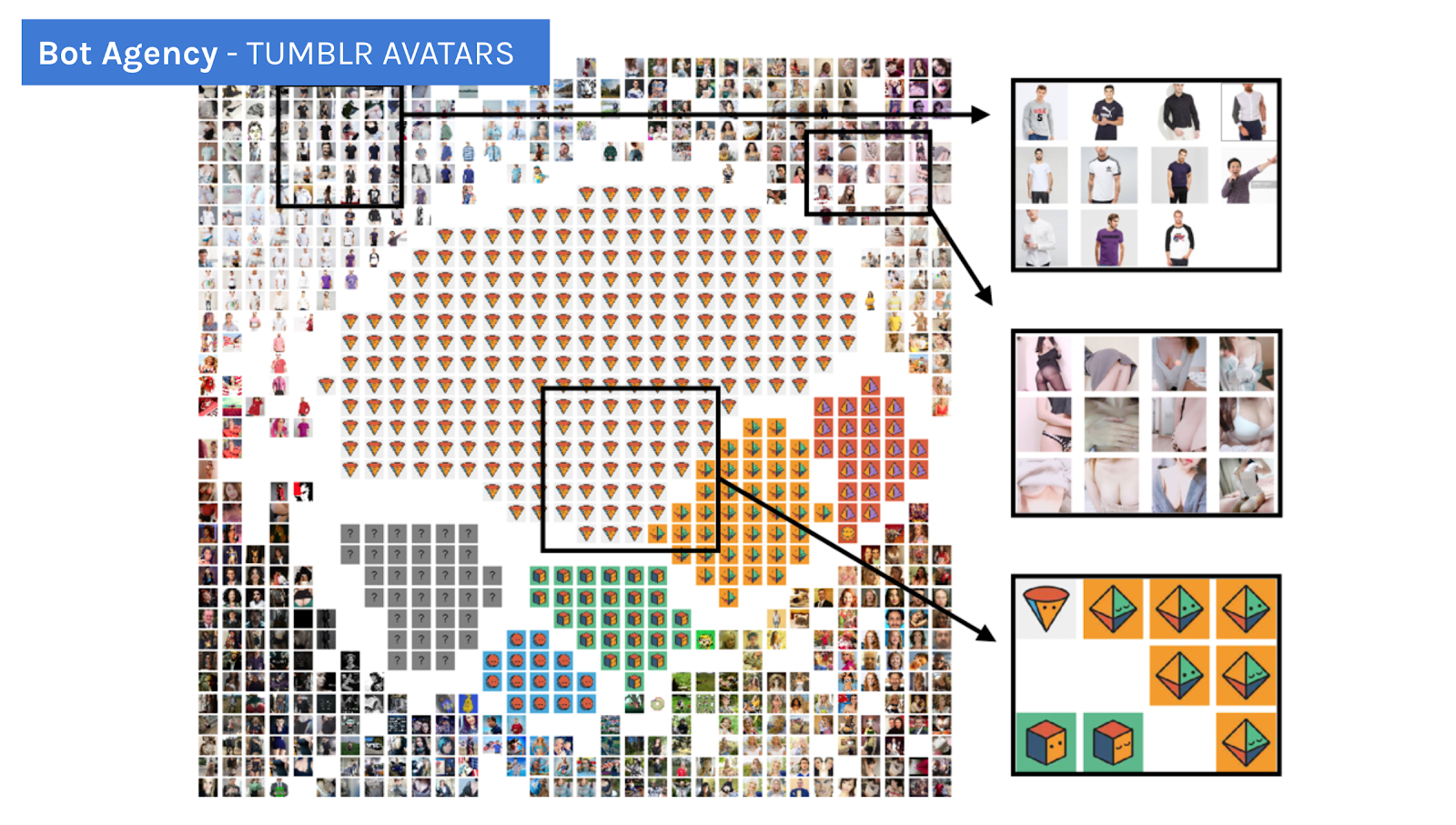
By exploring a collection of almost 1000 profile avatars (see below) through ImageSorter, we detected a large number of Tumblr blogs that use the default avatar visuality of geometrical shapes provided by the platform. Other botted accounts rely on stock image websites which, we believe, can be an attempt to make these Tumblr blogs look as if they were owned by ‘real’ people. The “sexy female” avatars (at the top right) are mostly connected to the distribution of porn content or links. At the top left, we were surprised by discovering an even larger number of the “handsome guys” avatars that (against our expectations) turned out to be entirely porn-unrelated. Instead, they either feature no content (or links) at all (and hence are used exclusively for purposes of following and liking) or share content for promotional purposes.
In the next step, we combined methods of visualising large collections of images (organised both by the time of publication and colour in the ImageSorter) with the affordances of an actor-image network. The visualization below displays (at the top left) almost 8000 images posted and shared by botted accounts. The analysis with ImageSorter provided us with a series of repetitive patterns assembling images into singular clusters dedicated to art and drawings, screenshots, memes, inspirational quotes, and pictures of people in general, including also a marketing campaign for watches (at the top right). By revisiting the same material through the affordances of an image-actor-network (in the middle), we were able to confirm that the same images come from different botted accounts.
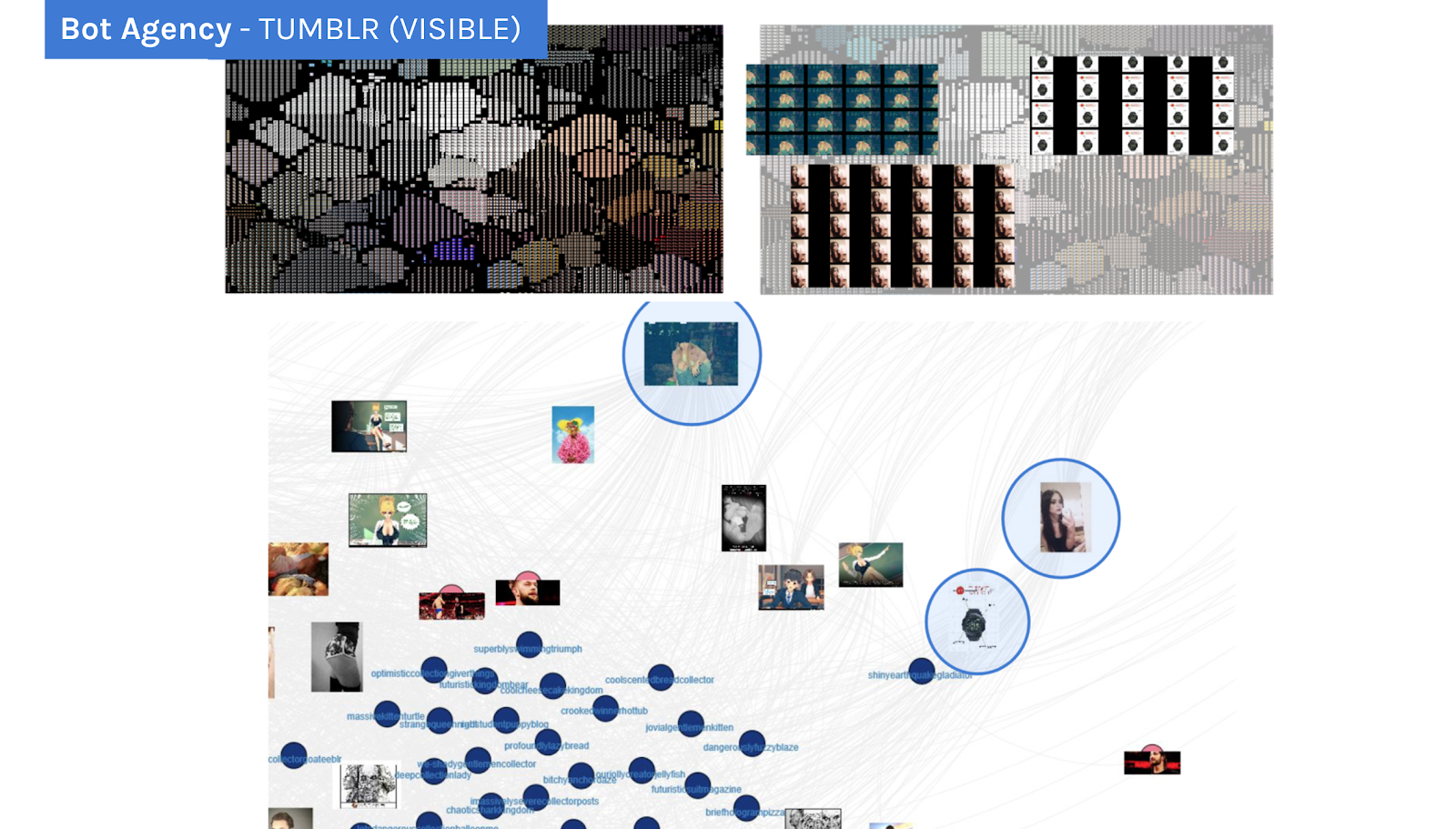
At the top left, the plot of 7082 images uploaded by Tumblr visible botted accounts. At the top right, the highlight of clusters constituted by the same images. In the middle, the screenshot of an actor (bot)-image network displays that different accounts share the same visuality.
However, and back to the plotted images (see above, at the top left), when looking into the spaces between the bigger clusters, we also discovered randomly occurring images that were not shared that much. These unique images include references to porn in the clusters dedicated to e.g. Black&White and blue art. Accordingly, we may conclude that Tumblr visible botted accounts that were detected through purchasing engagement from web applications mainly post ‘regular’ Tumblr images and, on a smaller scale, they share pornographic content.
Invisible botted accounts (hypothetical)
For the analysis of the invisible botted accounts (hypothetical), we built a combined image-domain network for Instagram and Tumblr and two separate networks for each platform. In so doing, we took advantage of the narrative thread of network spatialisation to verify how images travel across platforms (what sticks within the platform and what flows out) and explore what visualities are attached to Instagram and Tumblr. In practice, we analysed the image-domain networks and their narrative thread through “fixed layers of interpretation with multiple forms of reading” (see Omena & Amaral 2019, forthcoming, and also Omena & Pilipets, 2019).
The bipartite network below displays the relations between images and link domains to one another, responding to the question: Where do images uploaded by Instagram and Tumblr botted accounts (both visible and invisible) appear on the web (different URLs and domains)? It also gives us some valuable information about the specificity of the platforms, directing our attention towards whether the images stick within the platform or flow out of it. For example, on Tumblr, a great number of images uploaded by bots tend to stick within the platform while those images that flow out of the platform hit social media (Twitter, Pinterest, Blogspot) and porn websites (highlighted in red). On Instagram, a comparably small number of mages remain on the platform while the images that flow out are seldom pornographic. A first overview of what flows out of Tumblr reveals mainstream porn images and also hot pics connected to porn websites.
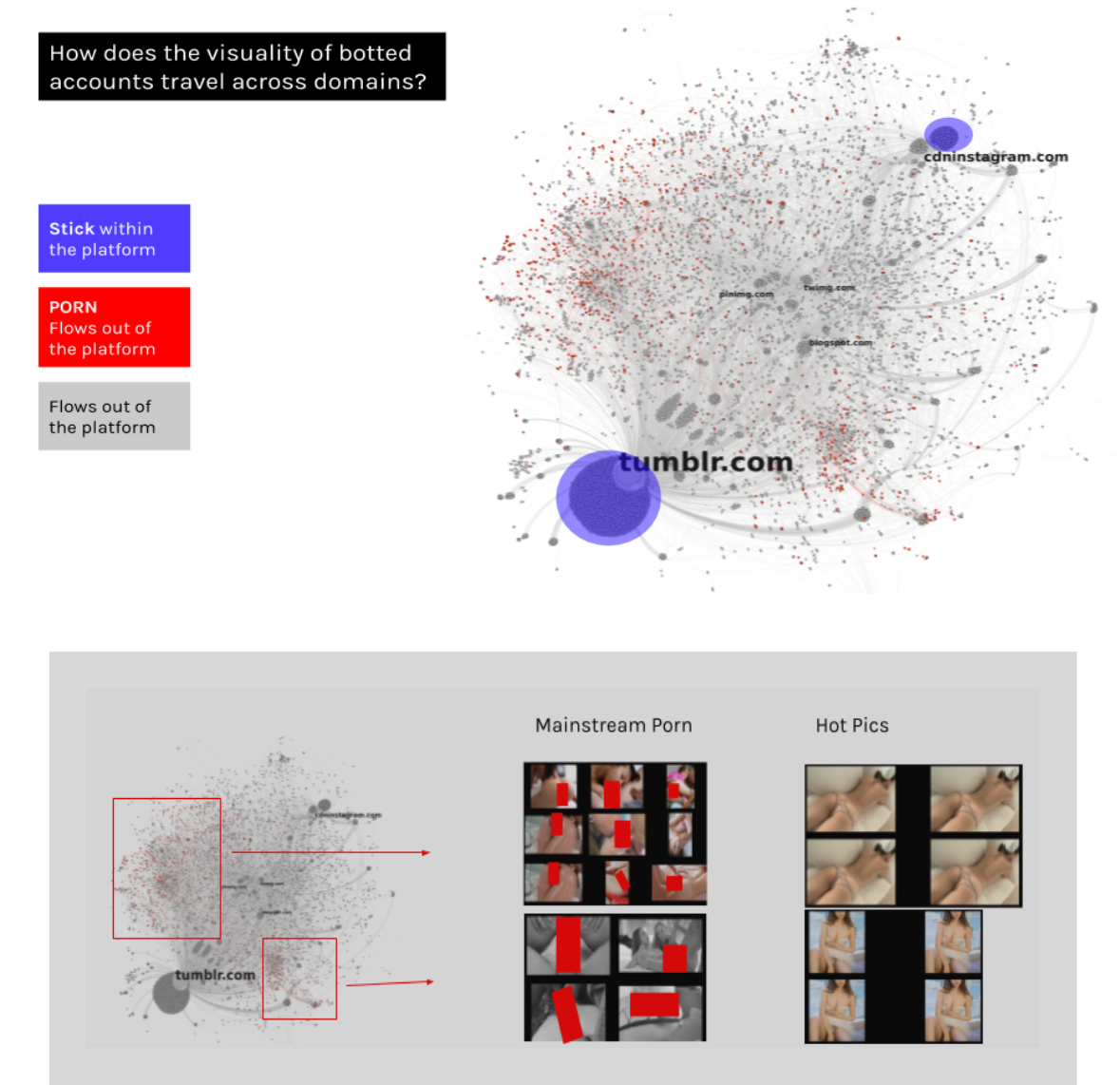
What visuality sticks within the platform? What flows out the platform? The image-domain network of Instagram and Tumblr botted accounts. Nodes are images and link domains (a total of 14788), edges (a total of 33.503) indicates whether a given image happened to appear in different domains.
The findings in this section have a basis on the affordances of digital networks, platforms and data. By taking into consideration images, domains and actors (Instagram profile names), we suggest focussing on what sticks within Instagram and what flows out of the platform as a form of understanding bot agency.
What are the relations among images, domains and actors and what do they tell us about bot activity on Instagram? Through reading the image-domain network, we noticed a dual-mode of existence of hypothetical bots on Instagram: discrete and imitative (see below). The former refers to private or public accounts with no content or profile picture, ghost accounts, while the latter reflects public accounts sharing diversified content. These ways of being, thus, shape the bots’ form of agency. On the one hand, they give likes (sometimes they follow others) but do not create content; serving the purpose of boosting engagement without attracting attention, which thus relates to a discrete mode of existence. On the other hand, they imitate real people by distributing mainstream content; serving as aggregators of followers or following, as well as for giving or receiving likes. This army of bots, consequently, imitate human interaction. The bot discrete mode of existence is shared by the triangle of social media domains: Instagram, Facebook and Twitter, while bot imitative modes of existence belong to the platform specificity (see below).
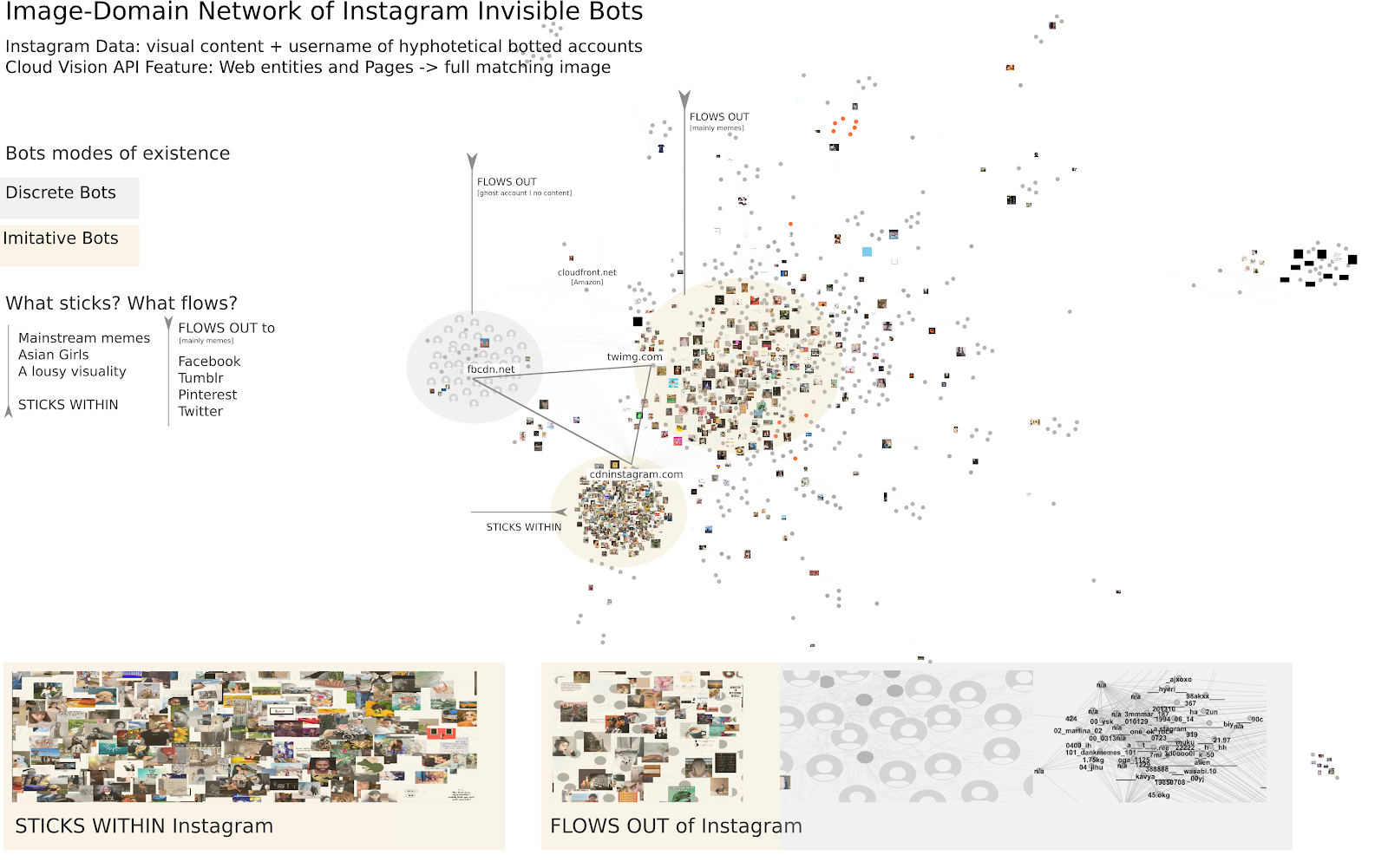
Image-domain network of Instagram hypothetical bots built upon the Google Cloud Vision API feature: web entities and pages, in particular relying on full matching images. Node type 1: image. Note type 2: link domain (host). Attributes: full_matching_image_count (1 to 10 different URLs ) to size the images within the network and username to identify accounts responsible for uploading a given (or more) image (s).
The imagery that sticks within Instagram is very diverse: Asian girls, babies, dogs, food, selfies, cars, including some memes, nature and promotion. A lousy visuality for Instagram has definitely called our attention, except for the girl images still relying on the use of filters or playing around with the typical “duck faces” & “boob selfies”. On the left side, there is a “domain-triangle” of Facebook, Instagram and Twitter; this is where we deal with the shared visuality of Instagram ghost accounts (which username pattern is numbers and underscores) across social media platforms. Accounts with profile icons and no content are not exclusive of Instagram. This background indicates that Instagram bots’ discrete mode of existence is shared cross-platforms, as well as the act of boosting of engagement exclusively via likes or follower/following accounts. Content creation is out of the question. That is to say, discrete bots take part in public conversations or debate without being noticed or detected; they hide under engagement metrics and go unnoticed in the research process. Unlike the prominent actors, discrete bots are nothing but ordinary.
What flows out of Instagram circulates among different social media (Facebook, Tumblr, Pinterest, Twitter, and in a minor scale Reddit), image repositories (including meme and clickbait sites) and other domains. This visuality is dominated by memes. When closely looking at the botted accounts linked to Tumblr and Pinterest in the centre of the network (see the visualization here), we detected a particular bot visuality which is attached to these platforms. From small business imagery to memes, only girls and erotic gay boys pictures. An interesting finding here was to note that the occurrences of full matching images of gay boys (by @88lovelove88) is higher on Tumblr than Pinterest. Additionally, the visuality attached to this latter reflects images created by small bot business accounts. Both cases suggest that botted accounts are not only programmed to upload content or to follow trending hashtags in order to reach visibility, but automation seems to also follow and respect social media usage culture.
Tumblr
The imagery of invisible botted accounts that sticks to Tumblr (the main area of the network) is dominated by vagina pics, erotic and pornographic images focusing on female bodies, and erotic anime mixed with hentai porn. Several accounts using combinations of letters, foreign names and numbers distribute pictures of Asian female lingerie models and young women wearing traditional Muslim headgear (hijab) next to the explicitly pornographic images of the same women (in the latter case no links, captions, or hashtags are used).
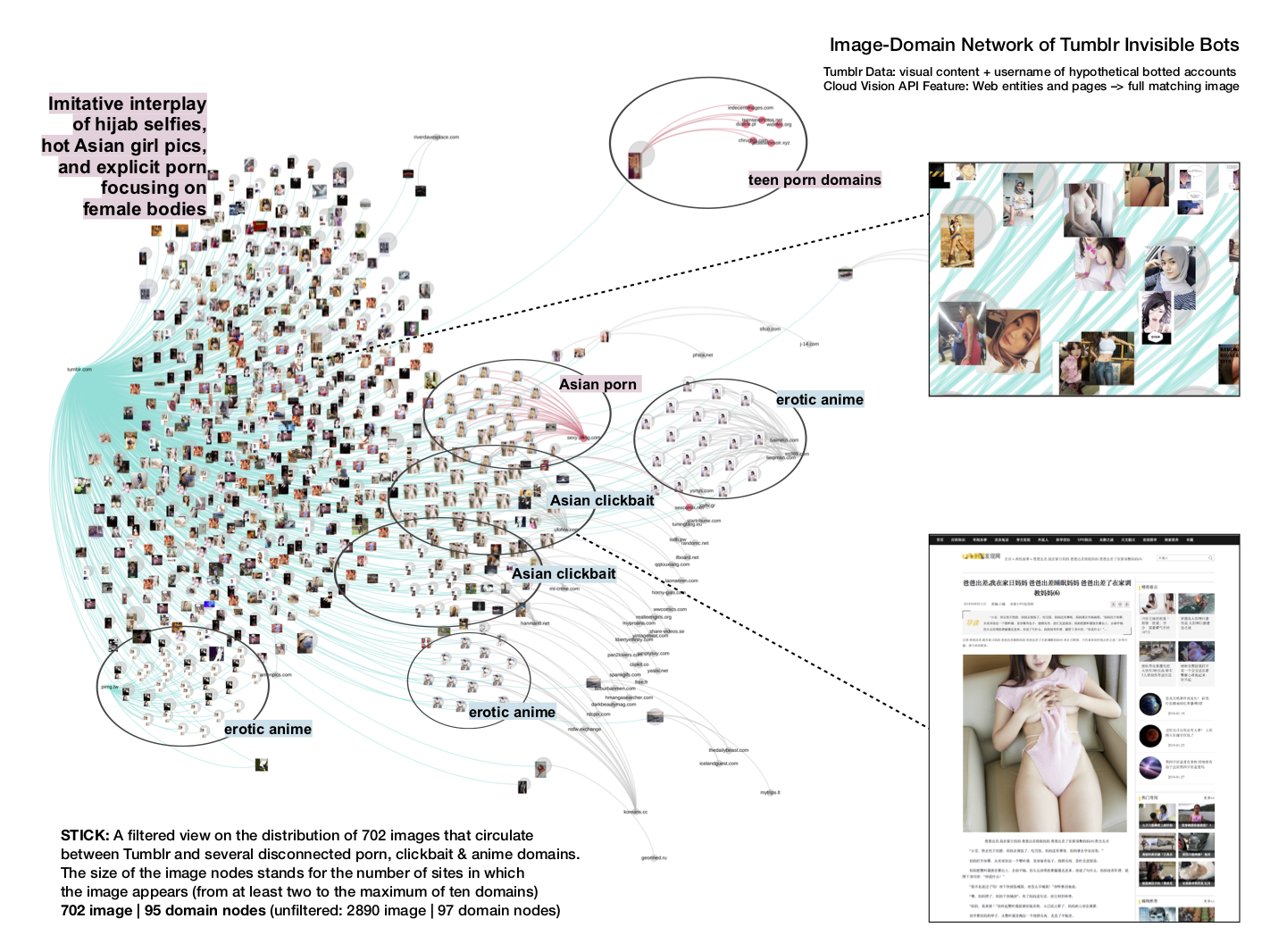
There is a whole farm of Tumblr blogs sharing this content which can be manually traced through the exploration of note sections and confirmed through the patterns in visual repetition within the network. An important finding coming from this exercise is the necessity to consider the intermingling of mutual pornbot liking activities with the comments and likes from non-automated “daddy dom” blogs or blogs revolving around other erotic trends. In this case, porn bots are part of the subcultural communities of the platforms that they inhabit. Their mode of being is integrated into what some of these communities search for.
The ethical concerns raised by this content are related not only to its semi-automated distribution but also to the specifics deriving from its partly ‘innocent’ visuality (young women either making selfies or posing in lingerie or ‘at work’). Expressed through repeated use of the same visual scenarios, this discrete or ‘safe for work’ mode of bot existence is designed to be peculiar enough to catch attention but not explicit enough to be censored by the platform (see e.g. red-coloured images in the main cluster of the network).
Constitutive of this capacity is the use of embedded links suggesting to “CLICK HERE!” without any other indications of the destination site. In some cases, the links lead to Asian clickbait platforms with diverse content topics ranging from aliens and UFO to softporn storytelling and ‘shock’ events. In other cases, the sites are explicitly NSFW or pornographic (see e.g. the cluster around sexy-pang.com; or clusters around erotic anime sites). Here, the operationality of links in combination with images collapses in a repetitive visual pattern shared by multiple accounts sequentially (one after another within a short timeframe). What this mixed mode of Tumblr bot agency suggests, is the involvement of a bot farm programmed to distribute the same imagery and links across multiple Tumblr blogs. If we assume that the main goal of these blogs is to drive clicks to porn websites, then we should ask about their capacity to get around the platform strategies of automated detection.
In the context of Tumblr purge, the combination of links and innocent visuality presents us with a tactic of escaping both algorithmic image recognition and word filtering, confirming the frequent description of pornbots in their role as clickbait-machines designed to remain unrecognisable as bots. Sometimes, though, especially if one image was shared multiple times by the same account (and especially in the case of teen porn), Tumblr algorithms seem to react faster than expected: Many blogs that were publicly accessible during the phase of data extraction in June 2019 were no longer on Tumblr by the end of July. In both cases, the use of hashtags was avoided, suggesting the ephemeral nature of automation and its involvement in the black market of the attention economy. Noteworthy at this point is also the invisibility of gay porn in the network although the note sections of at least 50 automated or semi-automated thematic blogs containing hundreds of blog names were used as entry points for data collection. This suggests that most blogs of this kind were hidden from public view or purged within a very short period of time.
In the second part of the network, the relations between images that flow out of Tumblr and circulate across different domains point to a strong presence of intensely distributed heterosexual mainstream porn and erotic imagery. Additional image clusters assembled around domains such as imgur.com contain internet memes, duck faces, cats and celebrity images. The mode of bot existence connected to these accounts can be described as that of sharing neutral popular content in order to maintain a resemblance of legit engagement not violating community guidelines. In the network, it is distributed across the social media domains, including Twitter and Instagram.
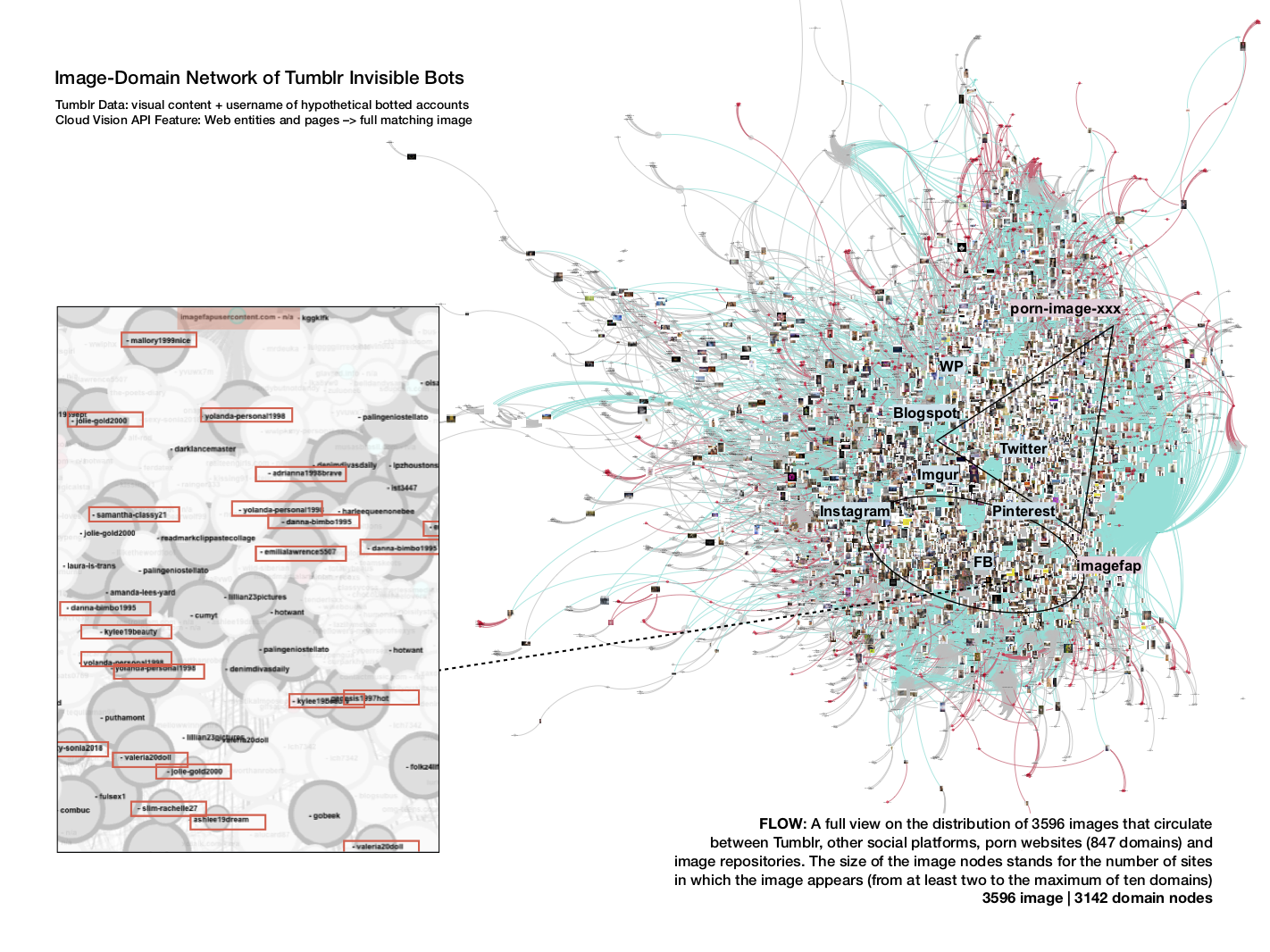
From the blogs featuring images appearing on at least five external sites, most blog names contain artificial female names (“ashlee19dream”, “adrianna1998brave”, “yolanda-personal1998” or “samantha-classy21”) and other name-number variations in combination with selfie avatars, other neutral avatars or no avatars at all. These Tumblr blogs share sexy girl pics mixed with heterosexual porn, circulating between other social media (especially Pinterest) and the free adult image hoster imagefap.com. Another densely connected cluster of porn bot images is dedicated to Asian porn. Distributed by blogs such as “japan--beauty--girls--navi--81” and “sexygirlbuzz88”, it is linked to porn-image-xxx.com and other similar domains.
On Tumblr, therefore, the exercise of shifting the perspective from the images that stick and flow to the accounts and sites of distribution that drive these movements, provides us with the possibility of exploring two qualities of bot agency: The images that flow out of Tumblr appear to connect porn domains with other social media platforms. What sticks to the platform, on the other hand, are the repetitive patterns of distributing the same image sequentially across multiple blogs.
6. Discussion
The value of automated engagement within the attention economy of social media platforms is attached to the capacity of botted accounts to boost visibility while remaining invisible and unrecognisable as bots. Since bot accounts on Instagram and Tumblr do not last long and continue to be replaced by new accounts, one important entry point for future research can be the exploration of username patterns, pointing towards the involvement of bot farms. Supported by the packaged offers of web applications, these patterns can be investigated through the possibility of tracing the relations of following and being followed. While this technique is still afforded by the Instagram API, the analysis of follower relations on Tumblr requires further experimentation.
Although the qualities of bot agency vary depending on different platform ecologies, what seems to connect bot accounts on Instagram and Tumblr within the black market of engagement is their capacity to redirect attention and subtly intensify engagement through automated acts of following and liking. In both cases, bringing traffic to external websites feeds into the logic of “affiliate marketing” – every click on a link that leads to an external domain translates into monetary value for those involved in managing multiple bot accounts. At the same time, every new like has its price on the side of those receiving engagement.
In this context, while the promise of social media visibility remains constant across platforms, the ways in which bots are imagined shift in relation to the capacity of botted accounts to interfere in the communicative cultures of Instagram and Tumblr. Assembling a number of associations and concerns, #bots operates as an issue space that is not stable, but dynamic and co-emergent with what bots actually do.
Addressing this question through the technicity and visuality of botted accounts on and across platforms, we produced our main insights in the process of unpacking and describing the affordances of image-domain networks: Densely connected with the respective cultures of platform engagement, the images that tend to stick to Instagram and Tumblr point towards the qualities of automation shared by multiple accounts within the platforms. At the same time, the high number of image occurrences in different external link domains (including other social media) can tell us a lot about the imitative dynamics that these images unfold in relation to one another and the sites of their circulation.7. Conclusions
Finally, it needs to be said that the resulting analysis of bot agency on Instagram and Tumblr is shaped by our strategies of data extraction and the affordances of the platforms. For instance, our exploration of pornbots in this dataset is clearly restricted to the particularities of Tumblr and can be expanded to other platforms and Instagram specifically (where porn and clickbait are flourishing along with influencer communities). At the same time, the restrictions of datasets also reflect the specifics of platformed attention economies (promotional, erotic, political, subcultural, etc.). Especially on Instagram, bots are mainly used to boost visibility through increasing likes and followers, which confirms both web applications’ promises and Instagram users’ expectations. This is why we see Instagram bots focus more on imitating real human behaviour than distributing content, as it is the acts of liking and following that are considered as engagement and can be monetised. By comparison, on Tumblr, bots work through spreading particular attention-grabbing content to direct user attention to external websites. Here, it is the clicks on external links that generate money. This explains why we observed a pattern of different botted accounts sharing the same image rather than pretending to be ‘real human’ as Instagram bots do.
Drawing on these explorations, we can conclude that bot engagement on Instagram corresponds with ‘the like economy’, while Tumblr bots relate more to ‘the link economy’. In any case and regardless of the platform, the process of investigating these relations raises ethical challenges when dealing with the semi-automated (and sensitive) entanglements of content and context. In this regard, the experiment with cross-reading the dimensions of web applications, bot imagination and bot agency may be considered our first step towards investigating the role of automation in the black market of social media engagement.8. References
Boshmaf, Yazan; Muslukhov, Ildar; Beznosov, Konstantin; Ripeanu, Matei (2011). “The socialbot network: When bots socialize for fame and money,” ACSAC ’11: 9/18/2018
Burgess, Jean & Matamoros-Fernandez, Ariadna. (2016). Mapping sociocultural controversies across digital platforms. Communication Research and Practice (2)1, 79-96.
Cho, Alexander (2015). Queer Reverb: Tumblr, Affect, Time. In: Hilis, K., Paasonen, S. and Petit, M (ed.) Networked Affect. Cambridge, MA: MIT, 43-58.
Coletto, Mauro, Aiello, Luca M., Lucchese, Claudio & Silvestri, Fabrizio. (2017). Pornography Consumption in Social Media. Cornell University Proceedings. Retrieved from https://arxiv.org/abs/1612.08157
Dhiraj Murthy, Alison B. Powell, Ramine Tinati, Nick Instead, Leslie Carr, Susan J. Halford, Mark Weal (2016). “Bots and Political Influence: A Sociotechnical Investigation of Social Network Capital”. International Journal of Communication 10 (2016), 4952-4971.
Etsiwah, Bennet. (2018). Social Bots. Turing for the Masses. Institute of Network Cultures. Retrieved from http://networkcultures.org/longform/2018/03/22/turing-for-the-masses/
Gerlitz, Caroline and Helmond, Anne (2013). The like economy: Social Buttons and the data-intensive web. New Media and Society 15(8): 1348-1365.
Gillespie, Tarleton. (2013). Tumblr, NSFW porn blogging, and the challenge of checkpoints. Social Media Collective. Retrieved from https://socialmediacollective.org/2013/07/26/tumblr-nsfw-checkpoints/
Gillespie, Tarleton. (2018). Custodians of the Internet. Platforms, Content Moderation and the Hidden Decisions that Shape Social Media. New Haven: Yale University Press.
Leistert, Oliver (2018). Social bots as algorithmic pirates and messengers of techno- environmental agency. In: Robert Seyfert and Jonathan Roberge (ed.) Algorithmic Cultures Essays on Meaning, Performance and New Technologies. Lodon: Routledge.
Marres, N. (2015). Why map issues? On controversy Analysis as a Digital Method. Science, Technology, & Human Values. DOI: https://doi.org/10.1177/0162243915574602
Messias, J. et al. (2013). You followed my bot! Transforming robots into influential users in Twitter. FirstMonday. 18(7). Retrieved from https://firstmonday.org/article/view/4217/3700
Niederer, S. (2018) Networked images: visual methodologies for the digital age. Amsterdam: Hogeschool van Amsterdam.
Omena, J.J. (2017). Instabots and the black marketing of engagement. The Social Platforms (site). Available at https://thesocialplatforms.wordpress.com/2017/12/21/insta-bots-and-the-black-market-of-social-media-engagement/
Omena, J.J., Mintz, A. and Rabello, E. (2020). Digital Methods for Hashtag Engagement Research. Social Media & Society, special issue “Studying Instagram Beyond Selfies” (forthcoming).
Omena, J.J. and Amaral, I. (2019). Sistema de leitura de redes digitais multiplataforma. In: Métodos Digitais: Teoria e Prática (e-book), organised by Janna Joceli Omena, ICNOVA: Lisbon, Portugal (forthcoming).
Omena, J.J. and Pilipets, E. (2019). Networks, Hashtags, Memes: A quali-quantitative approach for exploring social media engagement. CAIS Workshop. Bochum, 24.07.2019. Available at: https://www.slideshare.net/jannajoceli/networks-hashtags-memes-a-qualiquantitative-approach-for-exploring-social-media-engagement
Paasonen, Susanna, Light, Ben & Jarrett, Kylie (2019). The Dick Pic: Harassment, Curation, and Desire. Social Media + Society 1-10.
Pilipets, E. (2019). The Platformed Value of Engagement. Affect, Control, and Participation on Tumblr (and beyond). CAIS Colloquium. Bochum, 18.05.2019. Available at: https://www.slideshare.net/pilipetz13/the-platformed-value-of-engagement-affect-control-and-participation-on-tumblr-and-beyond
Pilipets, E. (2019 forthcoming). Contagion Images: Faciality, Viral Affect and the Logic of the Grab on Tumblr. In: Schober-de Graaf, A. (ed.) Popularisation and Populism through the Visual Arts: Attraction Images. London: Routledge.
Rogers, Richard. (2018). Otherwise Engaged. Social Media from Vanity Metrics to Critical Analysis. International Journal of Communication 12: 450-472.
Tiidenberg, Katrin. (2015). Boundaries and conflict in a NSFW community on Tumblr: The meanings and uses of selfies. New Media & Society. 1-16.
Wagner, Claudia., Mitter, Silvia., Körner, Christian, & Strohmaier, Markus. (2012). When social bots attack: Modeling susceptibility of users in online social networks. In Proceedings of the 2nd Workshop on Making Sense of Microposts held in conjunction with the 21st World Wide Web Conference 2012 (pp. 41-48).
Wald, Randall and Sumner, Chris (2013). Predicting Susceptibility to Social Bots on Twitter. 2013 IEEE 14th International Conference on Information Reuse & Integration (IRI). DOI: 10.1109/IRI.2013.6642447
Woolley, Samuel C. (2016). Automating Power: Social bot interference in global politics. First Monday 21(4).
Woolley, Samuel C. and Philip N. Howard (2016). “Political Communication, Computational Propaganda, and Autonomous Agents”. International Journal of Communication 10(2016), 4882–4890.
Woolley, Samuel et al. (2016). How to think about bots. Points. Retrieved from https://points.datasociety.net/how-to-think-about-bots-1ccb6c396326
Yang, K.C et al. (2019). Arming the public with artificial intelligency to couter social bots. Human Behavior and Emerging Technologies. DOI: https://doi.org/10.1002/hbe2.115.
Z. Chu, S. Gianvecchio, H. Wang, and S. Jajodia (2010). “Who is tweeting on Twitter: Human, bot, or cyborg?” ACSAC ’10: Proceedings of the 26th Annual Computer Security Applications Conference, pp. 21–30. doi: http://dx.doi.org/10.1145/1920261.1920265, accessed 8 March 2016.
Acknowledgement & Funding
The use of Google’s Cloud Vision API during the DMI Summer School 2019 was supported by a grant from UT Austin I Portugal Digital Media Program to the project ‘Social Media Technicity’. This project (proposed by Janna Joceli Omena) aims to study automated accounts on social media and to develop tools that may allow researchers to verify botted accounts on Instagram Platform. Also, we would like to acknowledge the Center for Advanced Internet Studies (CAIS) in Bochum, Germany, for providing the context for further project cooperation.
-- JannaJoceliOmena - 13 Jul 2019Ideas, requests, problems regarding Foswiki? Send feedback