Prompting for biodiversity: visual research with generative AI
Team Members
Participants: Piyush Aggarwal, Bastian August, Meret Baumgartner, Maud Borie, Tal Cohen, Sunny Dhillon, Alissa Drieduite, Xiaohua He, Julia Jasińska, Shaan Kanodia, Soumya Khedkar, Fangqing Lu, Helena Movchan, Janna Joceli Omena, Jasmin Shahbazi, Bethany Warner, Xiaoyue Yan.
Facilitators: Gabriele Colombo, Carlo De Gaetano, Sabine NiedererLinks
Contents
1. Introduction
The concept of biodiversity, which usually serves as a shorthand to refer to the diversity of life on Earth at different levels (ecosystems, species, genes), was coined in the 1980s by conservation biologists worried over the degradation of ecosystems and the loss of species, and willing to make a case for the protection of nature – while avoiding this “politically loaded” term (Takacs, 1996). Since then, the concept has been embedded in the work of the Convention on Biological Diversity (CBD, established in 1992) and of the Intergovernmental science-policy Platform on Biodiversity and Ecosystem Services (IPBES, aka ‘the IPCC for biodiversity’, established in 2012). While the concept has gained policy traction, it is still unclear to which extent it has captured the public imagination. Biodiversity loss has not triggered the same amount of attention or controversy as climate change globally (with some exceptions). This project, titled Prompting for biodiversity, investigates how this issue is mediated by generative visual AI, directing attention to both how ‘biodiversity’ is known and imagined by AI and to how this may shape public ideas around biodiversity loss and living with other species.
2. Research Questions
Where do we find diversity when prompting visual generative AI for biodiversity?
Sub-questions:
-
Which species are associated with biodiversity by generative AI text-to-image models (e.g., Midjourney, Stable Diffusion)?
-
Which species are foregrounded and which are left out?
-
Are there differences in the species represented for the topic of biodiversity across languages, seasons, cities, ecosystems and continents?
-
Which styles, artists and adjectives dominate in the representation of biodiversity by generative visual AI models? Do models have dominant visual and affective styles?
-
How does the interpretation of the generated images differ between image-to-prompt tools and machine vision?
3. Methodology
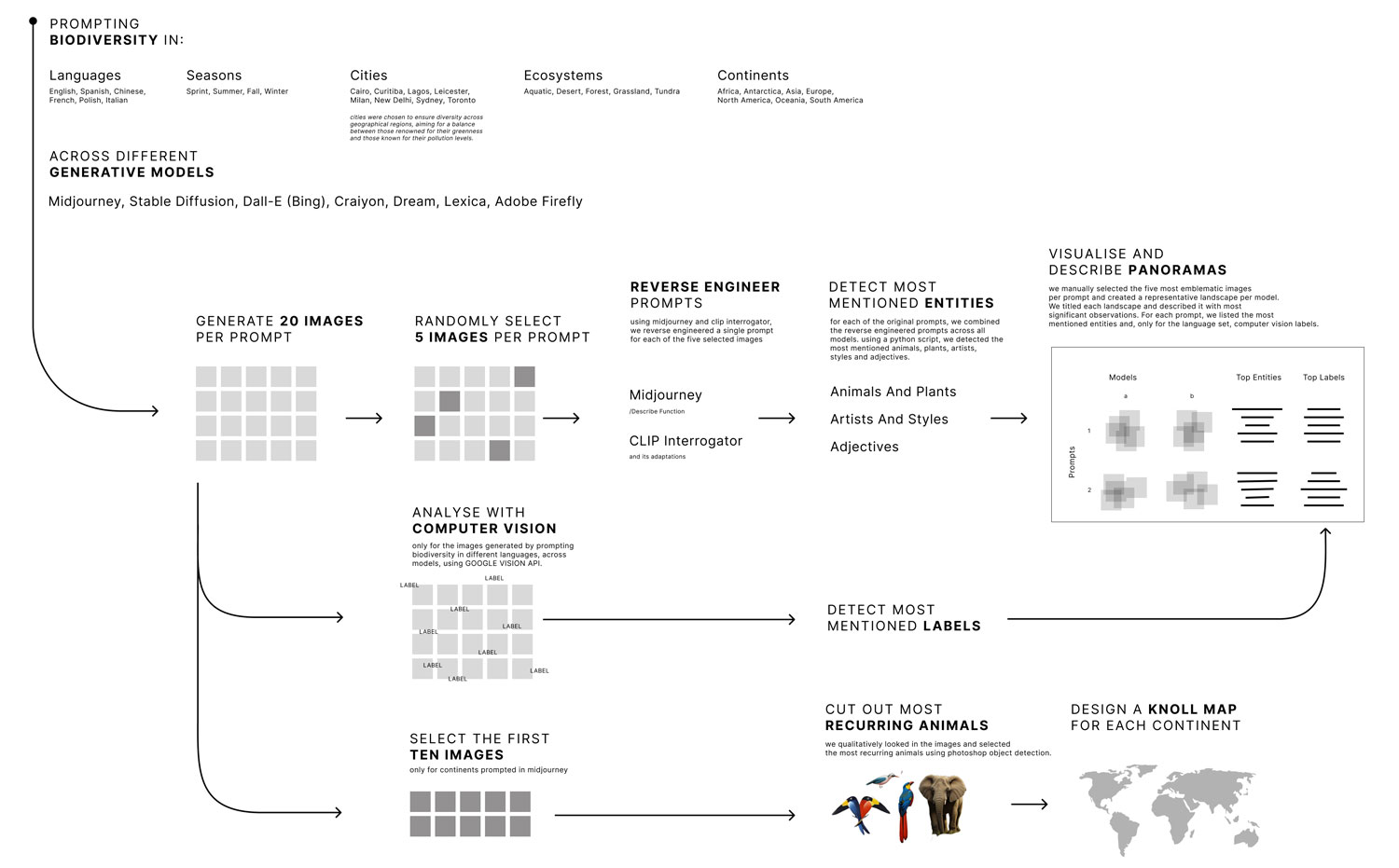
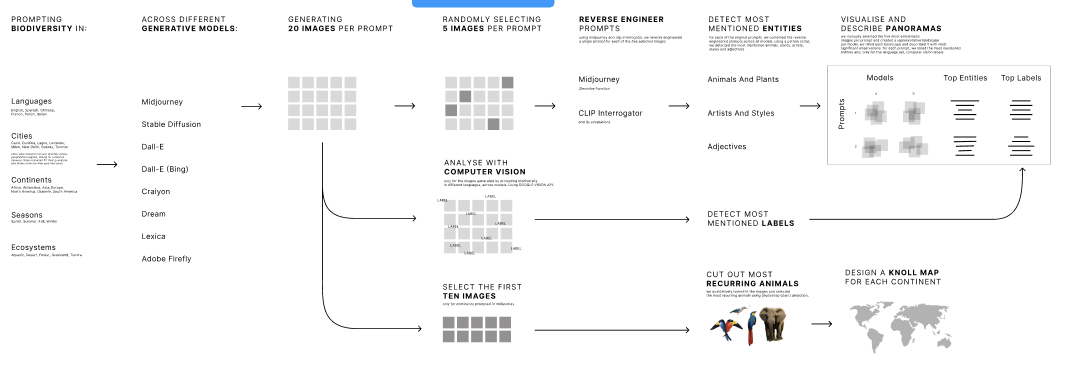
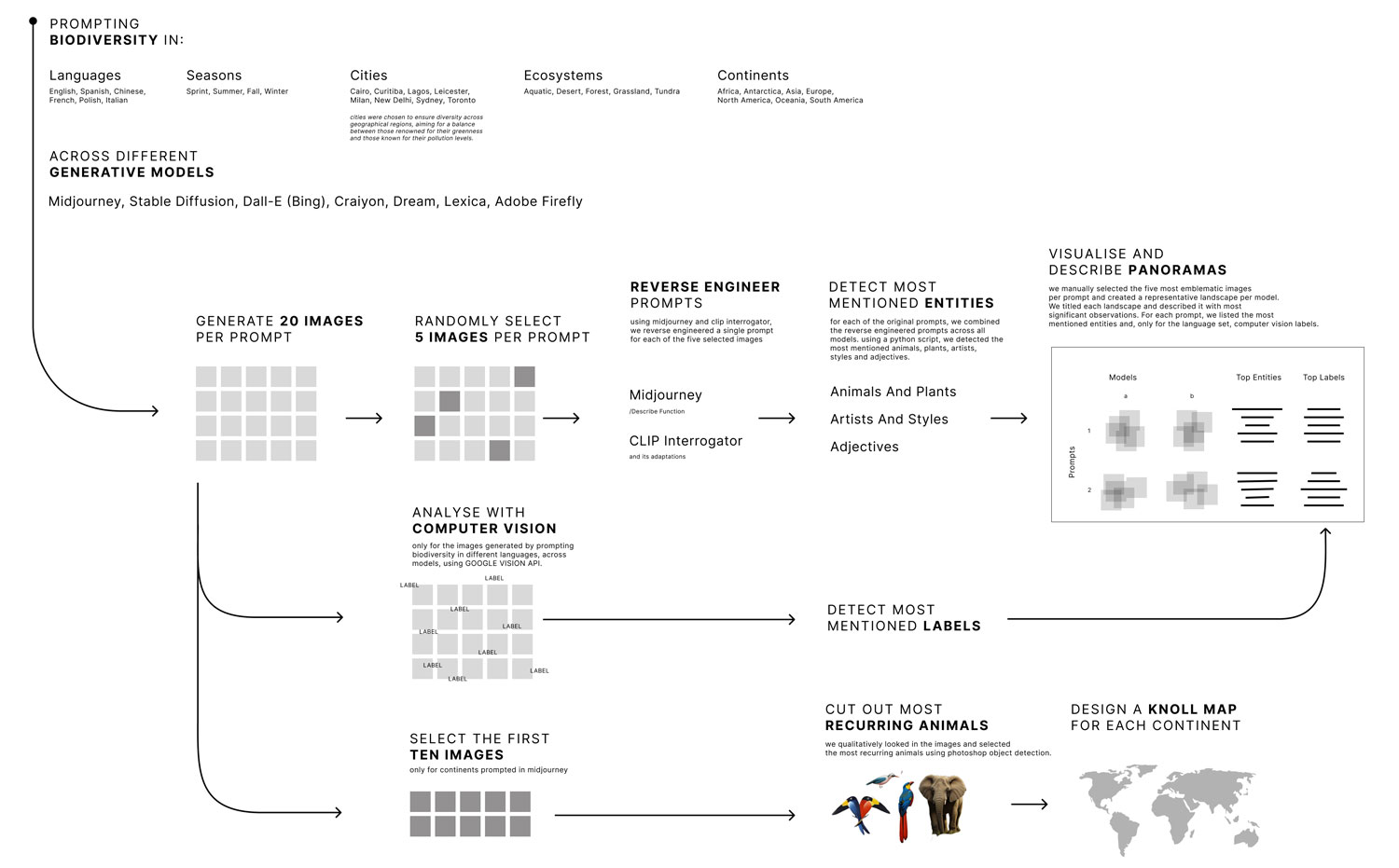
For the topic of biodiversity, we designed prompts to enable a comparative analysis of different generative AI models for biodiversity across languages, cities, seasons, ecosystems, and continents, as described in detail below. As a next step, a random sample of 5 images per prompt was selected and fed into an image-to-prompt tool to reverse-engineer prompts by letting AI read and describe the images. In order to analyze the reverse-engineered prompts, we used a simple script to extract the most occurring word groups of a certain length (e.g., "a lush green forest"). We then analyzed the most occurring words and word groups and categorized them as belonging to the categories of animals and plants, styles and artists, and adjectives.
Biodiversity Across Languages
Research Question
-
How does the representation of biodiversity differ across languages when using generative visual AI models?
-
Do certain languages exhibit unique patterns or associations with biodiversity-related images when processed through AI visual models?
Methodology
Language Selection: English, Spanish, Chinese, Italian, French, and Polish.
AI Visual Models: Midjourney, Dall-e bing, Stable Diffusion, Craiyon, Dream, Lexica, Adobe Firefly.
Data Collection: The term "biodiversity" was used as the prompt for each language (for example: “biodiversidad” for Spanish). The first 20 images generated by the AI visual models were downloaded for each language.
Image Analysis: image-to-text tools (/describe command on Midjourney and img2prompt tool on Replicate) were employed to reverse engineer the generated images to new prompts, five images from each language and model were randomly chosen for this process.
Frequency Analysis: A Python script was used to find the most frequent words in each language (in all the models together). The five most frequently occurring words\labels were chosen to represent each language on the following subjects: animals and plants, artists and styles, and adjectives.
To formulate findings, we proceeded to
-
describe the frequency analysis results for each language separately. Provide a summary of the most common words associated with biodiversity-related images in each language.
-
compare the findings across languages to identify any similarities or differences in the representation of biodiversity.
-
discuss any noteworthy patterns or associations observed in the extracted labels and descriptions for each language.
-
consider highlighting any unique cultural or linguistic perspectives on biodiversity that emerged from the analysis.
Across languages:
-
Polish: showed more of building and urban environments (for stable diffusion) on some models and people on others (for Dream)
-
Chinese: the images frequently showed people.
Across models:
-
Dall-e bing: there are almost no differences in the images (the style, objects, colours).
-
Crayon:
-
Stable Diffusion and Dream: with Chinese and Polish it seems to recognise the language and show images associated with the language, but they do not represent the topic “biodiversity”.
-
Lexica: there is a similarity in artistic style, but not necessarily similar in objects that appear in the images.
-
Midjourney and dream: represent a more complex understanding of what is “biodiversity”, by showing complex ecosystems and different species.
-
Dream: the style of dream can be described as more artistic
-
Adobe Firefly: In the FAQ of the model it is stated that it supports only English

Biodiversity Across Cities
Research Questions
-
How is biodiversity represented in different cities when prompting visual generative AI for biodiversity?
-
Do certain cities exhibit unique patterns or associations with biodiversity-related images when prompting visual generative AI for biodiversity?
Method
In this sub-project, we explored the representation of biodiversity in cities across the world using six different visual generative AI models. This approach was intended to test the ability of the models to recognise and generate images specific to different cities, and to explore what the models interpreted as biodiversity with each prompt. The prompts for each image were as follows: “biodiversity in (insert city)”. We generated 20 images per prompt per model in order to have a larger, more generalizable dataset, which resulted in a total of 800 images.
When selecting cities we cast a wide net of the urban environment around the globe. Our aim was to capture a wide array of cities representing each continent, as well as differences in the conditions of the environment. We thus selected our cities based on two key facets: (1) geographical representation: ensuring each continent was covered; and (2) pollution levels: selecting cities with low and high pollution levels. For feasibility purposes we selected eight cities by opting for a city in each continent that could be used to explore how and to what extent geographical differences would be visible in the generated images. The final cities we selected were: Toronto, Sidney, Lagos, Leicester, New Delhi, Curitiba, Cairo, and Milano. These cities were not intended to be fully representative of each geographical area but rather represent a sample to generate discussion and further exploration. Furthermore, New Delhi was chosen as a very polluted city (Rampal 2022), while Curitiba is known for being very green (Barth 2014).
Following the image generation, we then fed the images back into an AI prompt generator to investigate which terms would be used to describe the images the AI models created. For the city Toronto, we generated prompts for all 20 images in order to get a fully representative sample for one city. Due to time constraints, for the remaining cities, we randomly selected five images to reverse prompt per city. We used the prompt generation tool, img2prompt, for this process. img2prompt is an open-access tool based on CLIP interrogator by pharmapsychotic. From the generated prompts, we used a Python script to identify the most common single words and phrases used per city.
Findings
We analysed the results of this sub-project both per city and per model in order to explore the differences between the interpretation of biodiversity between cities and the consistency, or not, of the models across the cities.
Per city
-
Toronto: The set of images for Toronto frequently highlighted the cityscape, in particular, the CN tower. The images produced by the Midjourney model showed graffiti surrounded by concrete fixtures (e.g., buildings, roads, pedestrian walkways). The images from Crayion did not include architectural features, and evoked park-like settings, highlighting insects and birds. Compared to other cities, the set of images for Toronto emphasised urban and suburban landscapes surrounded by nature, as opposed to centring the image on nature.
-
Sydney: The Sydney image set features several icons of the city, including the Sydney Harbour Bridge and the Sydney Opera House. The animals tend to be reptiles, especially in the Craiyon model, which might play to dangerous stereotypes of poisonous reptiles in Australia. Large water bodies also came in a few images but are not as consistently featured as in other city sets.
-
Lagos: Lagos is one of the few cities in which pollution is shown in the images, especially in the Midjourney image set. Also featured are water, birds, animals native to the region (elephants and giraffes) and trees in the style of the Acacia variety, which are native to Nigeria. There are also more people in the Lagos image set in comparison to the other cities, generated by the Midjourney, Craiyon and Dream models. The people shown are all people of colour.
-
Leicester: The generated images of Leicester feature many instances of local nature; foxes are highlighted, orange butterflies, and moths. There are also many churches and cathedral buildings included, potentially inspired by Leicester Cathedral. There is significantly less water than in other city examples, despite the River Soar running through part of the city. The included people are in a more family setting.
-
New Delhi: The images generated by the Generative AI platforms depicting the biodiversity in New Delhi have a few elements which resemble the local landscape, including the iconic Parliament Building. A few images subtly portray the haze that signifies the pressing issue of air quality in the national capital. A few images generated by MidJourney show a bit of graffiti, including flowers and birds. One of the GenAI models also came up with Taj Mahal in the background, picking the popular Indian monument among others.
-
Curitiba: The set of images for Curitiba tended to display a binary between the city and the greenery. In some photos, the greenery was foregrounded, but the city was in the background. The set of images for Curitiba contained fewer animals compared to other cities. Curitiba is considered the greenest city in the world, yet the creatures which inhabit this green space are not depicted by the generative models.
-
Cairo: Cairo being in Egypt, which is known for its iconic pyramids, was seen in some of the generated images (Stable Diffusion and Dream). The overall impression conveyed is that Cairo is located in a relatively dry area with some bodies of water, given its arid surroundings and the absence of lush greenery. In the generated images by Bing Palm trees that are native to Cairo are shown, and there is a strong imagery of a dry area.
-
Milano: Midjourney generated empty roads, while the roads were always full of animals, objects, or people for other cities. Across models, buildings primarily have Roman architecture styles, and the Victor Emmanuel Gallery seems to be referenced multiple times. Nature is manicured, with architecture and human intervention being highlighted. An example of this is an image generated by Adobe Firefly, which shows a hand shaping a patch of dirt and plants.
Per model
-
Midjourney: Midjourney predominantly generated images with murals and graffiti of animals and plants in urban and industrial settings. These often depict elegant birds, flowers, and deer, and are depicted from a pedestrian view. Some scenes even look apocalyptic, a post-human world where nature is recovering or taking over cityscapes, but the subjects themselves are never threatening, maintaining a harmonistic view between city and nature.
-
Stable Diffusion: Stable diffusion had a tendency of giving an aerial/elevated view of the given prompt. Within this aerial view image, there would be landscapes of colonies and creatures. The majority of pictures generated had an absence of human activity, with the exception of Cairo. With the generated images, they all had a similarity of being very busy and crowded images of the indistinct colonies of creatures.
-
Dall-e (Bing): The Dall-e (Bing) model has a very distinct and clear template for images. It tends to emphasise a water body in the foreground and backgrounds the image with greenery or cityscape. The images are predominantly landscape shots and do not feature animals or people. While the sky colour and buildings vary, the images generally look quite similar across the different cities.
-
Craiyon: The Craiyon images produced more close-up shots of creatures compared to landscape images. The Craiyon images often pulled potentially stereotypical aspects of a location, such as poisonous creatures in Australia or filling New Delhi’s images with safari-type creatures (i.e., covered in a tiger or cheetah print). The location may weigh heavier when interacting with the “biodiversity” prompt to generate an image. Last, many of the animals depicted through Craiyon were indescribable, for instance, a sort of combination of a cheetah and giraffe.
-
Dream: Images generated by Dream are very idyllic and polished. It is the only model that generates different lighting, and there are no sharp etches. Much like Disney art styles, the images have a positive mood and evoke feelings. Dream is the only model that creates infographics.
-
Firefly: On prompting Adobe’s GenerativeAI tool to generate images depicting biodiversity in popular cities across the globe, Firefly came up with pictures that had a postcard-like quality with a few animals and birds. From intimate close-up shots to aerial views, the images captured nature in a beautiful way. Interestingly, birds are often found perching on trees and branches. Also, a lot of focus was on wildlife and on the earth. Apart from that, there were a few mid-images as well.
Prompt findings
Across the reverse-engineered prompts for the cities data sets, two artists were most prevalent. Bholekar Srihari came up across different cities and models, and Ram Chandra was in a lot of the reverse-engineered prompts of the images generated by Craiyon. The phrase "Shutterstock contest winner" came up a lot, as well as "a river running through a lush green forest", the specific camera type "nikon d750", and "ecological art". Apart from general terms like "forest", "trees", or "birds", there were relatively few terms relating to plants or animals. This gives an insight into the kinds of vocabulary the prompt generation model has, along with the data it was trained on, particularly given the high number of references to Shutterstock.
Overall the models are consistent in their style, irrespective of the location. Each model positively frames biodiversity in the present; the human degradation or decline of biodiversity is not depicted in any of the images.

Biodiversity Across Seasons
Research Question
-
What are the similarities and differences among images representing biodiversity in different seasons? (all models as a whole, different seasons)
-
What are the similarities and differences among images representing biodiversity in seasons generated by different models? (all seasons, different models)
Methods
In the present study, we generated four prompts pertaining to biodiversity across the four seasons, namely, “Biodiversity in Spring”, “Biodiversity in Summer”, “Biodiversity in Autumn”, and “Biodiversity in Winter”. We selected seven generative AI models, which are Midjourney, Dall-E Bing, Craiyon, Dream, Lexica, stable diffusion, and Adobe Firefly. Each prompt was used to generate 20 images across the selected models, resulting in a total of 560 images.
To investigate our research questions, we conducted a random sampling of the images and selected five images for each prompt from each model. These randomly selected images were then input into an image-to-text tool - img2prompt, to generate reversed prompts. The reversed prompts were subsequently analyzed to identify the most mentioned entities, including animals, plants, artists, styles, and adjectives. On the other hand, the randomly selected image samples were fed into the Google Vision algorithms to detect labels for each image which will be compared with the entities in the subsequent analysis. Finally, we visualized the results in a poster.
Findings
In response to RQ1, we compared different seasons generated by AI, which means we viewed all the models as a whole in this analysis. According to the generated images, the most mentioned entities (animals, plants, artists, styles, and adjectives), and labels extracted by google vision, we then figured out the following similarities and differences.
In terms of the similarities, there are mainly three findings. Firstly, no matter what the season is, insects, birds, and butterflies (even in winter) are always the most frequently illustrated animals, and there are few depictions of large animals. Secondly, when illustrating biodiversity in seasons, AI focuses more on plants rather than animals. This connects to the first finding, which indicates that the biodiversity in seasons is rather reflecting the diversity in plants instead of animals. Thirdly, the images in three seasons (excluding winter) are labeled as “people in nature” by google vision, while there is no representation of people in these images and entities.
As for the differences, here also comes three findings. The first one is that the general colour for autumn and winter is different. In most situations, they use (dark) orange in autumn, and white and black in winter. And compared with autumn and winter, the difference between spring and summer is not so significant – both of them are colourful. Also, different from the other three seasons, large carnivores only appear in winter. Lastly, AI prefers to show landscapes and surroundings rather than individual animals in autumn compared to other seasons. In the meantime, animals are less illustrated in autumn than others.
When comparing the seasonal biodiversity images generated by different models (response to RQ2), several similarities and differences were observed. With respect to similarities, all models generated pictures in a similar style when illustrating Autumn and Winter. For instance, Autumn images featured dark orange leaves and grass, while winter images depicted snow covering the land, the branches of trees, and animals' heads.
In terms of differences across models, Stable Diffusion and Adobe Firefly generated more photographic images rather than paintings, while other models produced more paintings or realistic paintings. Craiyon, Lexica, and Adobe Firefly tend to generate images with close-up and macro angles, focusing on single elements or objects rather than landscapes. Midjourney, Lexica, and Adobe Firefly tend to generate pictures in similar styles even when different prompts were used. In contrast, the pictures from other models sometimes have diverse results, and they would differ across seasons in styles and perspectives. The pictures from Lexica, Dream were characterized by bright and luminous colors, while images from Midjourney and Dall-E featured softer color palettes.

Biodiversity Across Ecosystems
Research Questions
-
In which ecosystem can we find biodiversity when prompting visual generative AI for biodiversity?
-
Which species are foregrounded by various text-to-image models, and which are left out across different ecosystems?
-
Are there elemental differences between generative AI models when prompting for biodiversity within different ecosystems?
Method
In order to get an understanding of how different ‘Image AI Modells’ interpret biodiversity within different ecosystems we align our research with Rogers' digital methods (2019). To be more specific, with Rogers' 'search as research'-approach to identify an algorithmic bias within the selected models (2019). The aim of this method is to get an understanding of how the different AI Models work since their algorithms are considered ‘black boxes’.
The ecosystems prompted were selected based on the popularly known five biomes: aquatic, grassland, forest, desert, and tundra. Every prompt would therefore be repeatedly written as “Biodiversity in (biome) ecosystem”. Ecosystems are generally defined as complex group of living organisms and how they interact in their environment. It could therefore be expected that the generated images responding to the prompts would feature a diverse group of life (flora/fauna) within the biomes.
For every prompt within every ‘Image AI Model’ 20 images would be generated. Giving us a total of 700 images. Five of each set of 20 images would then be randomly selected to reverse engineer these. With this technique, we would not only have images of what each model interpreted as the prompts but also a descriptive text. To generate the reverse engineered text we used for the images of Midjourney their reverse engineering prompt affordance and for all the other models since they did not have a built-in reverse engineering affordance so we used replicate (https://replicate.com/methexis-inc/img2prompt).
Findings
For our findings, there are three main questions to address. First, the extent of the biodiversity when prompting visual generative AI across different ecosystems. Based on the different ecosystems we found the most biodiversity in the aquatic ecosystem across AI models. In addition to generative visual images of multiple species of fish, the models visualised different corals and aquatic plants. The ecosystem that prompted the least biodiversity across AI models is the tundra ecosystem. Within the tundra ecosystem, patches of grass are accompanied by snowy mountains, water, and rarely an indistinct species of animal. With regards to the grassland, forest and desert ecosystems the biodiversity was irregular across prompts. The grassland ecosystem prompt illustrated large grassfields with occasionally species of leopards, lions, foxes, cows and birds. Significant to note is that there were rarely other plants than grass, with the exception of Midjourney. In relation to the forest ecosystem, the prompts viewed mostly thin trees and bushes. Adobe Firefly and Midjourney provided more biodiversity within the forest ecosystem. The desert ecosystem had a bigger biodiversity for Midjourney, Adobe Firefly and Stable Difusion, which provided birds, mammals, and an array of different cacti and plants. The other models were mainly illustrating sand dunes and rarely an animal or cacti.
Secondly, we address which species are foregrounded and which are left out by the generative AI models across different ecosystems. The grasslands had many generated images without animals, but each model produced images featuring animals, birds, butterflies and a resemblance of antlered animals. Forest ecosystems feature the same animals (antlered animals and birds) as well as other mammals that are fairly distorted/unidentifiable/imagined. Aquatic life by far only featured animals in almost all images (except for Dall-e bing). Animal life there was limited to diversity of fish, rather than animal species for example not featuring other animals such as crustaceans or molluscs. Desert ecosystems featured birds only, with the exception of Craiyon and Dream, generating almost alien creatures. Finally the tundra ecosystem didn’t feature any animals, except for Dream which generated wolves, foxes and birds in versatile perspectives of a tundra (close-up shots, landscape shots). Craiyon and firefly also attempted to generate animals, but with heavy distortion, making them unidentifiable. The most noticeable exclusion of life were insects featured, except for a few instances of butterflies in the grasslands.
Midjourney generated the most visually distinctive biodiversity, including flora and fauna, with clearly identifiable species (e.g. deer, butterflies, daisies) and elemental variation. These were more imagination oriented, showing a flourishing biodiversity in each ecosystem Stable Diffusion generated largely homogenous, photo-realistic images for most prompts, with slight variation in flora, but almost no animals in any ecosystem other than the aquatic ecosystem. With Craiyon, we observed that while several animals were generated across ecosystems, they were not identifiable as a specific species, and often showed distorted faces. These were also primarily photo-realistic, with the exception of the desert ecosystem. Adobe Firefly generated simple digital drawings, showing mostly flora and landscapes, with the exception of the aquatic and grasslands ecosystems which contained some fauna. Across ecosystems, Lexica generated digital drawings that were focused more on sunsets and visually pleasing elements, rather than specific types of biodiversity. Similar to Lexica, Dream also generated mostly digital drawings, but had more attempts at adding some biodiversity across ecosystems, with some animal portraits visible. Microsoft Bing Generator (Dall-E) created homogeneous images across prompts, where colours and flora would vary to a small extent.

The Animals of Biodiversity Across Continents
Research question
-
Which animals are represented by generative visual AI, for the issue of biodiversity across continents?
Method
Midjourney was prompted for biodiversity in [name of the continent]. For each prompt, the first 10 rendered images were retained. In Photoshop, all prominent animals and insects in the pictures were cut out with the ‘select object’ functionality, through a manual editorial process. The cut-out animals were laid flat in the shape of the continents to compose a Knolling world map.
Knolling is the practice of laying out objects on a flat surface and photographing them from above. It originated in the late eighties in the studio of Frank Gehry, who was then designing furniture for the brand Knoll. The studio janitor, Andrew Kromelow, coined the term in 1987. At the end of the work day, Kromelow would collect all stray tools lying around the studio, arrange them and take a picture from above, a practice that was quickly adopted by others. Knolling, aka ‘Flat lays,’ are a popular aesthetic in visual social media such as Instagram.

Findings
For the different continents, Midjourney associates biodiversity with different species; in some cases, certain species dominate the continent. Antarctica is solely populated by penguins and South America by colourful tropical birds. North America is comprised of butterflies and eagle-like birds and some hybrid mammals. Oceania is about fish and birds.
The continents of Africa, Europe, and Asia show the most diversity in animal species. Africa features elephants, zebras, giraffes, and a flock of birds. Europe holds mostly birds, butterflies, and some mammals, including platypus. Asia shows diverse animals, from tigers and elephants to birds and butterflies. Overall, we see that the only insects that appear are butterflies, and only Oceania contains fish. Birds and butterflies are the most prominent species across continents associated with biodiversity.
4. Findings
-
Which species are associated with biodiversity by generative AI text-to-image models (e.g., Midjourney, Stable Diffusion)?
-
Primarily plants: trees, flowers, cacti,
-
Animals: insects, butterflies, and a lot of birds. Some deer, wolves, giraffes, elephants, tigers, frogs, snakes, rodents, corals, aliens, unrecognisable.
-
-
Which species are foregrounded and which are left out?
-
Butterflies, birds, unrecognisable/distorted foregrounded.
-
Domesticated and agricultural animals were left out.
-
-
Are there differences in the species represented for the topic of biodiversity across languages, seasons, cities, ecosystems and continents?
-
Languages: we can see significant differences in the visualisation of biodiversity across languages, also with significant variations between models. Overall queries in English, and to some extent in French, Spanish and Italian, retrieve visualisations which correspond to stereotypical visions of biodiversity (lots of birds, plants, flowers) whereas queries in other languages (Polish, Chinese) retrieve images which are less focused on the natural world.
-
Seasons: Most of the animals are insects, birds and butterflies. Large animals appear more often in Winter, such as wolves and deer. As for the plants, fruits and mushrooms appeared more often in Autumn, especially in Midjourney.
-
Ecosystems: Out of the five prompted ecosystems, the image models responded with most biodiverse entities regarding the aquatic ecosystem. All images featuring a large and crowded diversity of fish, corals, or aquatic plants. The generative AI otherwise gave more landscape captures of the ecosystems, sometimes featuring the resemblance of a mammal/bird.
-
Cities: yes, differences across cities are mainly tourist, postcard-like representations.
-
-
Which styles, artists and adjectives dominate in the representation of biodiversity by generative visual AI models? Do models have dominant visual and affective styles?
-
Computer/digital art, illustrations/infographic.
-
Midjourney: concept art/oil paintings.
-
Water colour.
-
Landscapes, close-ups, or aerial.
-
Photographic.
-
Ecological art/Environmental art
-
-
How does the interpretation of the generated images differ between image-to-prompt tools and machine vision?
-
The label of “people in nature” was extracted by Google Vision in images of biodiversity in seasons (excluding winter).
-
5. Discussion
Reverse Engineering
It seems like the results obtained from the img2txt tool might reflect the dataset that that model was trained on more than say anything about the models that produced the images that are being reverse-engineered. Across prompts and models, for example, the phrase "shutterstock contest winner" occurs a lot, which would suggest that the model was trained with a lot of shutterstock contest winner images.
-
Artists mentioned were included to train the model. Loosely connected to the artists using predictive language communication.
-
Models: issues with Chinese and Polish. English, French, Spanish, and Italian did better in image generation. Stable diffusions recognize the language, but did not recognize biodiversity. Chinese input of biodiversity == a Chinese person (nothing to do with biodiversity).
-
Ecosystems: The generative AI focused more on portraying an image of the ecosystem rather than its biodiversity. Furthermore, Tundra and forest prompts were returned with the most homogenous results across-generative AI models.
-
Seasons: (1) The pictures depict pictures of autumn related to the orange leaves, and did not take pictures without dried leaves. Also, the images about winter illustrate snowy landscapes and items coverd snow, such as snow covered trees, branches and birds. Northern hemisphere (away from equator) bias. (2) The styles of “ecological art” was mentioned a lot in the reverse engineering results.
-
More an ideal of biodiversity rather than a representation. In the cities group, the representation was more idyllic (rarely cases of pollution).
-
No censored images.
6. Conclusions
Overall, we have found that:
Prompting for biodiversity in different languages retrieve significantly different sets of images across models, with the exception of Dream. At the same time similar kind of species are foregrounded (birds, plants); humans are present in some datasets (Chinese) and largely absent in others (English; French). Midjourney provides the richest representations, while other models often foreground singular entities.
When prompting for biodiversity across seasons, the depiction of spring and summer are relatively similar, with green as the major colour and objects like birds and flowers appear repeatedly. The visual representation of autumn and winter are more distinctive, the colour orange and leaves are largely used in autumn images and white and snow dominated the winter images.
When prompting for biodiversity across cities, the models are consistent in their style irrespective of the location. Each model positively frames biodiversity in the present; the human degradation or decline of biodiversity is not depicted in any of the images.
When prompting for biodiversity across ecosystems, there is a focus on the depiction of the ecosystem rather than biodiversity itself. Midjourney was the most biodiverse model, the aquatic ecosystem was the most biodiverse prompt, and the overall biodiversity was present mainly in the flora rather than animal species.
For biodiversity across continents in Midjourney, that the issue is mostly associated with birds and butterflies that in certain continents crowd out other species entirely.
7. References
Barth, Brian. "Curitiba: the Greenest city on Earth" The Ecologist, 15th March 2014. https://theecologist.org/2014/mar/15/curitiba-greenest-city-earth
Kunal, Kumar. “The new abnormal: Air pollution is not just a winter thing in Delhi anymore | Deep Dive” India Today, 3 June 2022.
https://www.indiatoday.in/diu/story/delhi-new-normal-air-pollution-not-just-in-winter-1958072-2022-06-03
pharmapsychotic. "methexis-inc/img2prompt" Replicate, version 50adaf2d3ad20a6f911a8a9e3ccf777b263b8596fbd2c8fc26e8888f8a0edbb5. https://replicate.com/methexis-inc/img2promptRogers, Richard. Doing Digital Methods. London : SAGE Publications Ltd, 2019.
Data sets (links)
-- SabineNiedererDMI - 12 Jul 2023 

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
Screenshot 2023-07-07 at 12.15.03.png | manage | 57 K | 12 Jul 2023 - 09:47 | SabineNiedererDMI | |
| |
Screenshot 2023-07-12 at 11.44.44.png | manage | 1 MB | 12 Jul 2023 - 09:45 | SabineNiedererDMI | |
| |
Screenshot 2023-07-12 at 11.44.56.png | manage | 1 MB | 12 Jul 2023 - 09:45 | SabineNiedererDMI | |
| |
Screenshot 2023-07-14 at 11.05.42.png | manage | 4 MB | 14 Jul 2023 - 09:06 | GabrieleColombo | |
| |
Screenshot 2023-07-14 at 11.12.44.png | manage | 4 MB | 14 Jul 2023 - 09:20 | GabrieleColombo | |
| |
Screenshot 2023-07-14 at 11.22.20.png | manage | 4 MB | 14 Jul 2023 - 09:22 | GabrieleColombo | |
| |
Screenshot 2023-07-14 at 11.24.27.png | manage | 3 MB | 14 Jul 2023 - 09:24 | GabrieleColombo | |
| |
english-biodiv.jpg | manage | 71 K | 12 Jul 2023 - 15:24 | GabrieleColombo | |
| |
protocol.jpg | manage | 128 K | 12 Jul 2023 - 14:34 | GabrieleColombo |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback