Nofollow / Indexing Issues in the Blogosphere
Introduction: Indexing and Ranking
Search engine critiques generally focus on either the allocation of pages to be searched (indexing) or the algorithms used to determine the order of search returns (ranking). Central to both areas of study, however, is the hyperlink. The link is necessary for page discovery, and is used in PageRank and derivative methods as an indicator of reputation among a set of linked documents. Roughly speaking, the debate around search engines in the late 1990s and early 2000s centered on indexing, with search engines displaying with pride the number of pages indexed and the introduction, by search engine critics, of the ominous notion of a 'dark Web,' an unindexed Web not discoverable through search engines. More recently, with the rise of Google, focus seems to have shifted to the question of relevance among results. The Nofollow case study raises both issues and, by taking the link as a starting point, questions the conventional practice in search engine studies to separate the two. Indexing, as will be seen below, is not always a straightforward act, and in some cases requires link-interpretation on the part of the crawler. Alongside the many editorial decisions embedded in ranking algorithms, this inevitably affects search engine return. The Nofollow tag specifically affects the indexing of links embedded in blog comments. After briefly introducing the tag and assessing its prevalence, here we present a case study investigating the returns from Google, Google Blog Search, and Technorati for links to the Masters of Media weblog. Rather than question the extent to which the devices provide blogosphere 'coverage' (an indexing question), we speculate on how editorial decisions in both indexing and ranking combine to construct different blogospheres among the various devices.Nofollow
Working alonside Yahoo!, MSN and blog platforms such as Wordpress, Google introduced the no_follow attribute in 2005 to prevent comment spam and trackback spam. According to Wikipedia,nofollow is an HTML attribute value (no_follow) used to instruct search engines that a hyperlink should not influence the link target's ranking in the search engine's index. It is intended to reduce the effectiveness of certain types of spamdexing, thereby improving the quality of search engine results and preventing spamdexing from occurring in the first place. (Link)While the aim is to prevent the manipulation of site rankings, no_follow also affects indexing, as indicated by the different variations on the attribute and interpretations of it: 1. Robots (don't follow link)
The robots exclusion standard, also known as the Robots Exclusion Protocol or robots.txt protocol is a convention to prevent cooperating web spiders and other web robots from accessing all or part of a website which is, otherwise, publicly viewable. For example: "Do not follow any of the hyperlinks in the body of this document." (Wikipedia)2. Search Engines (don't count link)
How the attribute is being interpreted differs between the search engines. While some take it literally and do not follow the link to the page being linked to, others still "follow" the link to find new web pages for indexing. In the latter case rel="nofollow" actually tells a search engine "Don't score this link" rather than "Don't follow this link." (Wikipedia)These inital considerations led us to a few research questions, focusing on measuring the prevalence and effects of no_follow, as well as the broader effects on blogosphere coverage when devices treat the tag differently:
- How prevalent is the nofollow tag?
- What percentage of a given network may be excluded from an internet search due to nofollow?
- What are the social/political implications of this sort of segregation?
- What do we lose by dividing our primary access to the web into two primary entry frames, blogs and not-blogs?
Prevalence of the no_follow html attribute
To guage the prevalence of no_follow, we consulted relevant policies from blogging platforms and search engines. Among the major blog services, no_follow is a standard addition (with some caveats):- WordPress: default setting, can be disabled with an additional do_follow plugin.
- Blogger: default setting, can be disabled with a series of advanced steps.
- Typepad: "For TypePad subscribers, implementation will be automatic. Links from commenters will be flagged automatically in the next update, which will be deployed within the next 24 hours." (Six Apart - Support for Nofollow)
- Movable Type: "For Movable Type users, we’re shipping a plugin today to enable support on Movable Type-powered sites. The Movable Type website has full details, including a download link." (Six Apart - Support for Nofollow)
- LiveJournal: "LiveJournal also plans to implement the specification for comments from other members who are not friends." (Six Apart - Support for Nofollow)
| rel="nofollow" Action | Yahoo | MSN Search | Ask.com | |||||
|---|---|---|---|---|---|---|---|---|
| Follows the link | Yes | Yes | Not proven | Yes | ||||
| Indexes the "linked to" page | No | Yes | No | Yes | ||||
| Shows the existence of the link | Only for a previously indexed page | Yes | No | Yes | ||||
| In SERPs for anchor text | Only for a previously indexed page | Yes | No | Yes |
- Google’s regular ranking factors
- Scrape Gmail for links
- Frequency of Clicks
- Blogrolls
- Social Bookmarking
- Feed Readership
- Other factors
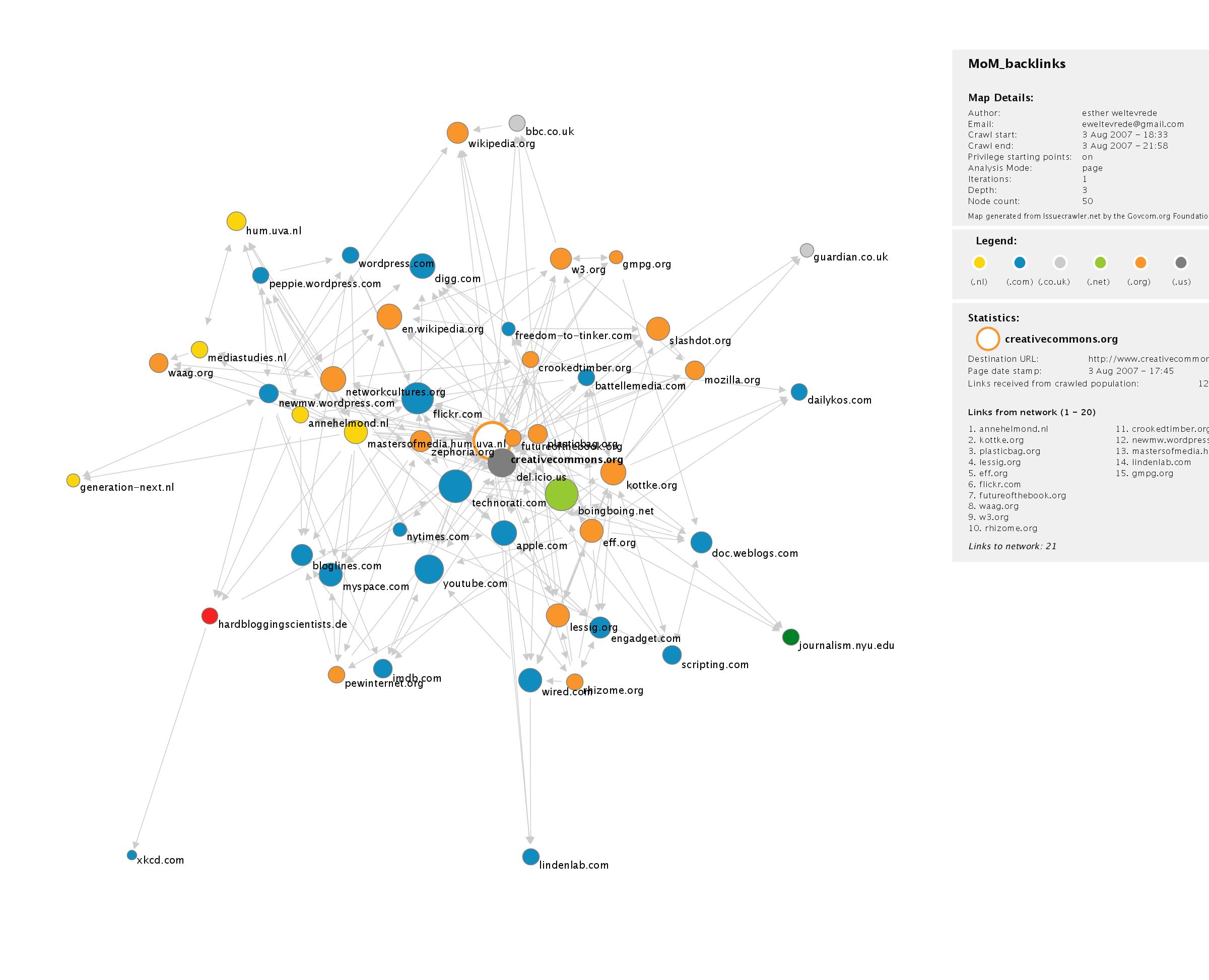
Indexing Issues Case Study: Google vs. Google Blogsearch vs. Technorati
How does Google segregate the static web and blogs? Do noindex and nofollow play a role? See here for speculation on how their blog search works. From About Google Blogsearch:- Which blogs are included in Blogsearch? The goal of Blogsearch is to include every blog that publishes a site feed (either RSS or Atom). It is not restricted to Blogger blogs, or blogs from any other service.
- How do I get my blog listed? If your blog publishes a site feed in any format and automatically pings an updating service (such as Google Blogsearch Pinging Service), we should be able to find and list it. Also, we will soon be providing a form that you can use to manually add your blog to our index, in case we haven't picked it up automatically. Stay tuned for more information on this.
Starting point:
We will compare the results of the query "link:mastersofmedia.hum.uva.nl" in google, google blogsearch and technorati. We will use 3 tagclouds for speculation.- Google Blogsearch
- Technorati
Creating a tag cloud for inlinks to Masters of Media Blog in Google.
Question Who links to http://mastersofmedia.hum.uva.nl, according to Google? Tools:- Google scraper
- tag cloud to svg tool
- Illustrator
- Use Google scraper with query "link:mastersofmedia.hum.uva.nl"
- Google search result for "link:http://mastersofmedia.hum.uva.nl", on 27.07.07: 126 results
- Now manually count and list the results per domain like this
- Use the tag cloud to svg tool to produce a svg file, that can be opened in Illustrator.
-
- Open the file in Illustrator and manually rescale the results to A4 and organize the svg file into a tag cloud. Adjust transparency according to number of links to MOM blog:
- 1 = 30%
- 2 = 40%
- 3 = 50%
- 4 = 60%
- 5 = 70%
- 6 = 80%
- 7 = 90%
- 8+ = 100%

Creating a tag cloud for inlinks to Masters of Media Blog in Google Blogsearch.
Question Who links to http://mastersofmedia.hum.uva.nl, according to Google Blogsearch? Tools: Method:- Query Google Blogsearch with "link:mastersofmedia.hum.uva.nl". Since there is no tool to scrape all the results, we manually copied all the URLs of the titles of the results.
- googleblogsearch.txt: Google Blogsearch Masters of Media blog inlink results (27-07-07).
- Tally results per domain.
Google Blog Search MOM inlink results googleblogsearch.txt
- Use the tag cloud to svg tool to produce a svg file, that can be opened in Illustrator. Result
-
- Open the file in Illustrator and manually rescale the results to A4 and organize the svg file into a tag cloud. Adjust transparency according to number of links to MOM blog:
- 1 = 30%
- 2 = 40%
- 3 = 50%
- 4 = 60%
- 5 = 70%
- 6 = 80%
- 7 = 90%
- 8+ = 100%

Creating a tag cloud for links to Masters of Media Blog in Technorati.
Question Who links to http://mastersofmedia.hum.uva.nl, according to Technorati? Tools:- [[http://service.openkapow.com/artonice/technoratipostsearch1.rest][Technorati Scraper]
- tag cloud to svg tool
- Illustrator
- Query Technorati (advanced search) with "link:mastersofmedia.hum.uva.nl". result Since there is no tool to scrape these results, we manually copied all the URLs of the titles of the results.
- Results: MoM_technorati_inlinks.txt: technorati inlink search-mastersofmedia.hum.uva.nl - 27.07.07: 231 results
- Tally results per domain.
- Use the tag cloud to svg tool to produce an .svg file, that can be opened in Illustrator. Result
-
- Open the file in Illustrator and manually rescale the results to A4 and organize the svg file into a tag cloud. Adjust transparency according to number of links to MOM blog:
- 1 = 30%
- 2 = 40%
- 3 = 50%
- 4 = 60%
- 5 = 70%
- 6 = 80%
- 7 = 90%
- 8+ = 100%

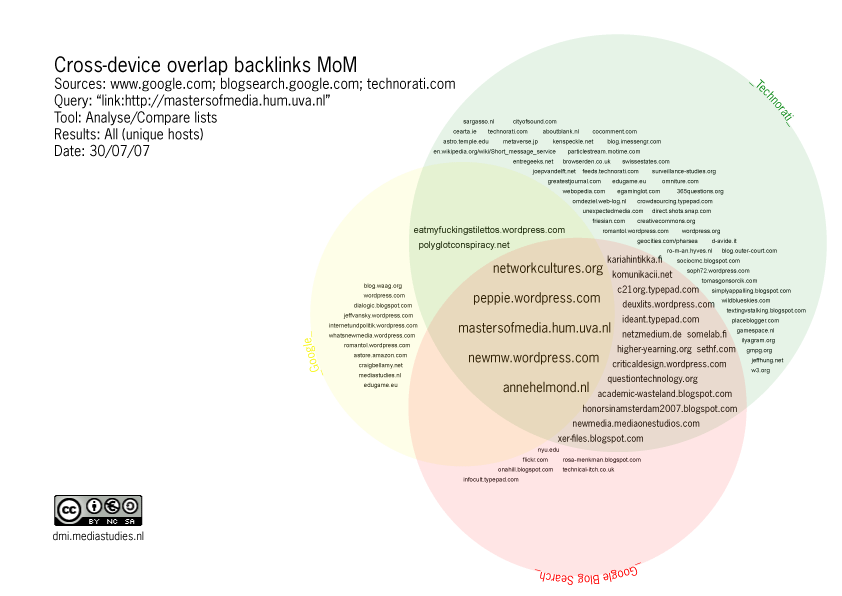
Results: Comparing the three tagclouds
To see which blogs are included/excluded within the spheres of the three devices we compared the results as found in 1 2 3 we used the Compare Lists tool. Update: The tool Triangulation is the advanced version of Compare Lists The results can be found here. The results were visualized in a cross-device tag cloud:- nofollow_all.ai: nofollow_all.ai

- See A wishlist of tools for semi-automating the cross device tag cloud.
Findings
- It is remarkable that Google returns mostly blog results (hardly any static web results). Are there very few static websites linking to MOM?
- Google returns blog results that cannot be found in Google blog Search.
- Nofollow has little to do with the difference in returns in the 3 devices. The permalink has no nofollow tag, only comments have a nofollow tag by default and are excluded from results. This has consequences for the results returned in that there are no links to DmiMoM returned that are in placed in comments. This is however not a defining factor in the difference in returns. The difference is in the algorithm of the engines.
Tags: , view all tags


{kind=link}
{kind=link}
{kind=link}
| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
27julidmi.doc | manage | 57 K | 03 Aug 2007 - 10:03 | UnknownUser | list of urls from all devices that link the mom blog |
| |
Desktop.rar | manage | 72 K | 27 Jul 2007 - 15:00 | UnknownUser | cross-device overlap google googleblogsearch technorati |
| |
Google_search_for_link-mastersofmedia.hum.uva.nl.rtf | manage | 58 K | 27 Jul 2007 - 11:44 | MichaelStevenson | Google search for "link:http://mastersofmedia.hum.uva.nl" 27.07.07 155 results |
| |
MoM_technorati_inlinks.txt | manage | 9 K | 27 Jul 2007 - 12:13 | UnknownUser | masters of media techno-inlinks |
| |
MoMcluster_map.jpg | manage | 282 K | 04 Aug 2007 - 17:51 | UnknownUser | cluster map MoM inlinks |
| |
NoFollow.ppt | manage | 164 K | 18 Sep 2007 - 11:39 | AnneHelmond | Nofollow presentation 18-09-07 PPT |
| |
cross-device_MoM_tagcloud(2).svg | manage | 279 K | 30 Jul 2007 - 14:47 | UnknownUser | origineel cross-device MoM tag cloud overlap google googleblogsearch technorati |
| |
cross-device_MoM_tagcloud(2.gif | manage | 39 K | 30 Jul 2007 - 14:49 | UnknownUser | cross-device MoM tag cloud overlap google googleblogsearch technorati |
| |
googleblogsearch.gif | manage | 21 K | 27 Jul 2007 - 13:57 | UnknownUser | Google Blog Search MOM inlink results TAG CLOUD |
| |
googleblogsearch.txt | manage | 4 K | 27 Jul 2007 - 12:47 | UnknownUser | Google Blog Search MOM inlink results |
| |
nofollow_all.ai | manage | 361 K | 18 Sep 2007 - 11:36 | AnneHelmond | |
| |
nofollow_all.pdf | manage | 384 K | 18 Sep 2007 - 11:35 | AnneHelmond | |
| |
nofollow_all.png | manage | 73 K | 18 Sep 2007 - 11:36 | AnneHelmond | |
| |
nofollow_google.pdf | manage | 323 K | 18 Sep 2007 - 11:46 | AnneHelmond | |
| |
nofollow_google.png | manage | 53 K | 18 Sep 2007 - 11:45 | AnneHelmond | |
| |
nofollow_googleblogsearch.pdf | manage | 345 K | 18 Sep 2007 - 11:46 | AnneHelmond | |
| |
nofollow_googleblogsearch.png | manage | 49 K | 18 Sep 2007 - 11:45 | AnneHelmond | |
| |
nofollow_technorati.pdf | manage | 426 K | 18 Sep 2007 - 11:45 | AnneHelmond | |
| |
nofollow_technorati.png | manage | 78 K | 18 Sep 2007 - 11:45 | AnneHelmond | |
| |
nofollowpresfin.pdf | manage | 80 K | 23 Aug 2007 - 09:53 | UnknownUser | Nofollow presentation 23-08-07 PDF |
| |
tagcloud_3devices.ai | manage | 173 K | 30 Jul 2007 - 14:39 | UnknownUser | Backlinks Masters of Media. Illustrator Tagcloud 3 devices |
| |
tagcloud_googleblogsearch.gif | manage | 24 K | 30 Jul 2007 - 14:20 | UnknownUser | Backlinks Masters of Media. Tagcloud Blog Google Search |
| |
tagcloud_googleblogsearch.pdf | manage | 218 K | 30 Jul 2007 - 14:19 | UnknownUser | Backlinks Masters of Media. Tagcloud Google Blog Search PDF |
| |
tagcloud_googlesearch.gif | manage | 30 K | 30 Jul 2007 - 14:35 | UnknownUser | Backlinks Masters of Media. Tagcloud Google Search |
| |
tagcloud_googlesearch.pdf | manage | 224 K | 30 Jul 2007 - 14:19 | UnknownUser | Backlinks Masters of Media. Tagcloud Google Search PDF |
| |
tagcloud_technorati.gif | manage | 44 K | 30 Jul 2007 - 14:21 | UnknownUser | Backlinks Masters of Media. Tagcloud Technorati Search |
| |
tagcloud_technorati.pdf | manage | 219 K | 30 Jul 2007 - 14:20 | UnknownUser | Backlinks Masters of Media. Tagcloud Technorati Search |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r46 < r45 < r44 < r43 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r45 - 12 Dec 2008, EstherWeltevrede
Ideas, requests, problems regarding Foswiki? Send feedback