A field guide to using LLMs for online conflict analysis
Google doc version hereTeam members in alphabetical order
Erik Borra (assistant professor at University of Amsterdam / Digital Methods Initiative) Penelope Bollini (MA student at University of Amsterdam) Laura Caroleo (PhD at Universita' degli Studi "Magna Græcia" di Catanzaro) Benjamin Cerigo (developer at datavaluepeople) Roeland Dubèl (MA student at the University of Amsterdam) Fatima Gaw (PhD at Northwester University) Beatrice Gobbo (assistant professor at the Polytechnic University of Milan and researcher at Density Design Lab) Davit Janezashvili (independent developer) Emillie de Keulenaar (PhD at the University of Groningen / OILab / Digital Methods Initiative) Ivan Kisjes (research staff at the University of Amsterdam)Diana Moret i Soler (PhD at Universitat Jaume I)
Kris Ruijgrok (postdoctoral researcher at the University of Amsterdam)
Janjira Sombatpoonsiri (assistant professor at the German Institute for Global and Area Studies)
Contents
- Case study I: The conflict in Nagorno-Karabakh: ethnic and State violence online
- Team members
- Methodology and initial datasets
- Findings
- Conclusions
- Case study II. Attitude and norm polarization in US Christian leadership on Twitter
- Case study III: The Filipino Maharlika funds controversy on Facebook and Twitter
- References
Results in a nutshell
- Google flan-5, GPT 3.5 and davinci-004 are all prone to language-specific biases when prompted about conflict-related topics, e.g. to whom Nagorno Karabakh belongs (Armenia or Azerbaijan), who were the first inhabitants (Armenians or Azerbaijanis), how many victims they were in prominent massacres. The report goes on the examine the underlying biases of a small part of GPT 3.5's training data in Armenian and Azerbajiani (e.g., Wikipedia and WebText2) — here, here, here, here, here and here. One could find similar patterns for the Israelo-Palestinian conflict.
- One can use LLMs to advance methods for analysing dialogue and reconciliation processes on social media data. We experimented a method that goes as follows: (1) we extract conditions for peace laid out by ~10K Facebook posts, namely ~5K Armenian-speaking posts vs ~5K for Azerbajiani-speaking posts. (2) We transform results into prompts directed at a given group's opposition; for example, if a condition for peace expressed by Armenian users is "for the Azerbajiani military to obey a ceasefire in Nagorno Karabakh", then that becomes a prompt that we run on Azerbajiani-speaking posts as follows: "Does this Facebook post state or agree that the Azerbaijani military should obey a ceasefire in Nagorno-Karabakh?". The results show the extent to which Az and Arm-speaking posts from this dataset agree with these peace conditions.
- Since so few conditions of peace were reciprocated across Armenian and Azerbajiani-speaking posts, we used midjourney to represent the top 10 most engaged condition (Armenian here, Azerbajiani here).
- To mitigate biases, the report goes on to discuss how one could consider training datasets for peacebuilding practices — e.g., datasets that translate, mix and retrieve data from different languages, depending on the prompt.
- Outside of this report, we detail a few ways that one could design conflict zone-specific content moderation policies & techniques.
- Google FLAN and GPT 3.5 performed at par when classifying positions towards an issue, GPT 3.5 performed better at extracting arguments or providing conceptual summary from small texts such as tweets.
- LLMs are arguably better at granular tasks, namely when it comes to differentiating between a “constructive” post (which would contribute to the quality of online debate) and a hate speech post (which would contribute to the opposite effect).
- Conflict analysis of social media discourse could use zero-short classifications to get a subset of relevant data.
Introduction
Since ChatGPT was released in December of 2022, all sorts of existential questions regarding the future of qualitative work quickly creeped into research-related sectors. There have been important objections posed against LLMs as products of private monopolies on large language training models (Denkena and Luitse, 2021), as well as “stochastic parrots” (Bender et al., 2021) that, as if in another iteration of modern nihilism, only repeat everything that has already been said.
Nevertheless, the presence of LLMs in digital methods and computational social sciences creates a noticeable elephant in the room. As of now, research has tended to “prove” the effectiveness of LLMs in things that such disciplines did painstakingly in the recent past, such as manually coding thousands of social media posts, detecting or scrutinizing certain kinds of rhetoric, or making complex estimations about public opinion, political leanings and other attributes inferred from social media data (see, for example, Chu et al., 2023).
Yet, the question posed by digital methods – and increasingly more so by computational social sciences – has always had to do with the relation between the “data” and the “tool”. In other words, we want to inquire about what interpretations of the world LLMs replicate based on its broader technical rationale and the data it has been trained on. There is room for scrutinizing LLMs as a technique and for exploring the affordances it brings to the interpretative sciences of Internet studies as a research tool. What else do LLMs do that NLP, network analysis and other forms of processing large amounts of textual data haven’t done before? And how does one approach LLMs with the same critical eye as with any other research tool?
These questions are vast, and there are many ways to explore them over a long period of time. In the meantime, this study focuses on what LLMs can do for the analysis of conflict on the Web, which is sometimes referred to as “controversy mapping” and other times as “conflict monitoring” in online peacebuilding ventures. In this research context, the questions posed above become more specific. One recurrent question has to do with methodology. What place do LLMs have amidst the in-house practices of conflict monitors, online peacebuilders and mediators? We have mentioned how LLMs may simplify the painstaking process of filtering, annotating and processing large amounts of textual (and other) data. But we may as well think of tasks that involve several complex iterations, such as measuring something like “consensus” between groups A and B in what concerns controversial issue C. Many other examples from conflict mediation may come to mind. Indeed, by conflict mapping or monitoring, we often refer to digital and computational social science methods that operationalise peacebuilding and political and social conflict analysis into a variety of computational methods. Some of these methods are well-known to digital methods researchers (issue and controversy mapping including projects like Contropedia, as well as various analyses of “extreme” online behavior – see for example Borra et al., 2014; Marres, 2015; Venturini and Munk, 2021), while others remain experimental, as possibilities to operationalise the expertise and practices of conflict monitors are still wide.
One way to explore these questions is to put LLMs to the test of three conflict monitoring case studies. Each of these case studies would require more or less procedural methods – query design, data collection, analysis in the form of hate speech detection, coding posts, etc – that, as we will see, may be complemented, condensed, or altogether altered by the intervention of different LLMs. These case studies touch upon three types of conflicts on the Web. Decades old, the conflict in Nagorno Karabakh can be seen as a case study for ethnic, political and territorial conflict waged by States and in public opinion (e.g., misinformation and hateful language exchanged between Armenians and Azerbaijanis online). Here, LLMs can be used to measure escalation between groups based on their online rhetoric, or measure conciliation in the form of increased dialogue or shared information. Another case is polarization between left- and right-learning Christian communities in the US. In US history, Christian discourse has been used both for insulating and universalising causes – for example, the discourse of Christian White identity in contrast to that of civil rights. As we will see, LLM prompts can be operationalised into a sort of “questionnaire” to gauge at the extent to which online Christian discourse is more or less divisive or conciliatory, based on a number of cues described by the theories of affective and normative polarization. Finally, to test a more classic form of controversy mapping, we look at a four-day controversy tied to the Maharlika funds, a project advanced by Bongbong Marcos’ new government to boost Filipino investment without significant checks and balances to prevent corruption. LLMs can be used to gauge the stances of users partaking in the debate for or against the funds, as well as the quality and evolution of their arguments.
From preliminary analyses, we suspect that LLMs can support a number of crucial tasks: classification of posts per actor, issue, theme, vernacular, political affiliation or other classification; detecting differences between arguments, stances and more granular information from a group of users A and group of users B (or more); and more subtle analyses, such as tracing the history and underlying premises of arguments or ideas proposed by groups of users; pointing to information silos between two or more groups; and building upon these analyzes by providing insights on polarization, rhetorical escalation, hate speech and expressions of conflict (Davit Janezashvili, Lia Chkhetiani, and Emillie de Keulenaar, 2023). But we also see how, because LLMs are trained on already conflicted data, they will perpetuate their biases and ultimately partake in the very conflict they are instructed to analyze.
Finally, this report can be read as a tentative “field guide”, in the sense that it does not argue in favor of one or another method, but explores several methodological avenues that may be tailored to a case study in conflict analysis. It comments on the shortcomings of each avenue, and comments, in sum, on some of the inherent potentials and limitations of LLMs for conflict analysis.
Research Questions
What can we do with LLMs that existing NLP and digital methods couldn’t do before in conflict analysis?
How can we highlight discrepancies within and between LLMs (e.g., differences between LLMs, low probabilities in prompt answers, content moderation interference…) as a form of tool critique?
Case study I: The conflict in Nagorno-Karabakh: ethnic and State violence online
Nagorno-Karabakh is an enclave situated in Azerbaijan, and is the object of a long ethnic and territorial armed conflict between Azerbaijan and Armenia. The enclave has been inhabited, until at least 1989, by a majority of ethnic Armenians (BBC, 2023). During the fall of the Soviet Union, conflict between the Republic of Azerbaijan and ethnic Armenians, supported by the Armenian state, arose in what was then considered the first Nagorno-Karabakh war (1988-1994). A second war in 2020 ended with a ceasefire brokered by Russia, whose peacekeeping forces have remained in Nagorno-Karabakh until recently. By September of 2023, Nagorno-Karabakh was de facto ruled as the autonomous Republic of Artsakh despite being internationally recognised as part of Azerbaijan. Later that month, all Armenians had been evacuated from the enclave and the Republic of Artsakh was dissolved. The conflict in Nagorno-Karabakh is still considered “frozen”, in the sense that military violence and pogroms are susceptible to bad diplomatic relations between the Azerbaijani and Armenian governments, as well as poor public relations between Armenian and Azerbaijani populations.
The Nagorno Karabakh conflict has been marked by numerous humanitarian tragedies in which both Azerbaijani and Armenian civilians suffered a plethora of war crimes, internal and regional displacements. What remains from these episodes is a profound sense of distrust and firm conviction in favor of state narratives, according to which each country is the original (or rightful) inhabitant of the Nagorno-Karabakh province. Online, relations between Azerbaijani and Armenian speakers have been complicated by polarized sources of information, worsened by state-sponsored social media campaigns and poor content moderation (see, for example, our previous research on Nagorno Karabakh in de Keulenaar et al., 2023). During the second Nagorno Karabakh war (2020), Armenian and Azerbaijani speakers seldom shared the same sources of news and historical references on social media (be they due to linguistic differences or otherwise) (ibid). As we will see later on, Wikipedia articles in Armenian, Azerbaijani or English contain nearly opposite sets of facts relating to the demographics, historical events and war crime responsibilities of Armenia and Azerbaijan in the enclave, and YouTube and Google results for controversial queries (relating, for example, to historical massacres in each language) tend to return results that are largely supportive of state narratives, and even at times historical revisionism.
Until the week of the 18th of September 2023, it had been three years since the ceasefire took place. There have been efforts from peacebuilders and online campaigns to push for conciliation, particularly by pushing narratives of historical coexistence, cooperation and solidarity between Armenians and Azerbaijanis (United Nations Development Programme, 2023). Some analysts find recent developments promising for long term peace (Mirovalev, 2023), but fears of ethnic cleansing from Armenians are evident on social media and beyond (Armstrong and Zotova, 2023; Mirovalev, 2023; Solovyov, 2023). It remains to be seen whether conciliation has taken place in some form, and if it has, what methods serve to examine it.
In this sense, the question we seek to answer in this case study is: how does one detect and measure conciliation in social media and the Web, and is there evidence of it happening in Azerbaijani and Armenian social media spheres?
Team members
Emillie de Keulenaar (PhD at the University of Groningen / OILab / Digital Methods Initiative) Ivan Kisjes (research staff at the University of Amsterdam) Davit Janezashvili (independent developer) Erik Borra (assistant professor at University of Amsterdam / Digital Methods Initiative) Beatrice Gobbo (assistant professor at the Polytechnic University of Milan and researcher at Density Design Lab)Methodology and initial datasets
Query design
Before we go over the methodological aspects of this study, we should first paint a clearer picture of the data we used and how we obtained it.
Because of recent changes to the Twitter API, and because Crowdtangle affords satisfactory geolocation and language filtering, we decided to collect posts from Facebook groups and pages that contain language related to the Nagorno Karabakh war. By this, we mean a smaller set of (initially) 200 words or phrases in Armenian or Azerbaijani that mention (1) hateful language (in Armenian, against Azerbaijanis and vice-versa); (2) historical massacres having affected a majority of Azerbaijanis or Armenians; or (3) battles or territories under military occupation. 92 keywords can be considered pro-Armenian, and 103 pro-Azerbaijani, in the sense that they express concepts, policies or ideas proper to each national cause. The remaining keywords are labeled as “bipartite” because they can be understood as key issues for Azerbaijani-Armenian dialogue; we have taken as examples the recognition of historical massacres affecting each side. To check for evidence of acknowledgment of such issues, these keywords are written in the language of its opposing side. For example: “Khojaly massacre” or “Khojaly genocide” – a massacre of hundreds of Azerbaijani civilians by Armenian armed forces in 1992 – is written in Armenian to check for evidence of Armenians mentioning that event. Likewise, “Baku massacre” or “Baku pogrom” – the massacre of dozens of Armenian civilians in Baku of 1990 – is written in Azerbaijani, and so are other equivalent terms.
Data collection and sampling
The time frame chosen for data collection was from January 2020 (the beginning of the year in which the second Nagorno Karabakh started) to July 2023 (the month in which this study was carried out). These queries yielded a total of 100,000 posts in Azerbaijani and Armenian.
LLMs, particularly GPT 3.5 and up, can be costly to run on more than 10,000 posts (DocsBot AI, 2023). We decided to sample our Nagorno Karabakh dataset by:
-
Keeping 10% of the most and least engaged Facebook posts, per month;
-
Filtering posts that had less than 10 characters and more than 2,000 characters;
-
Keeping the top 50 Tweets per language (if that many existed);
-
Selecting 50 random Tweets from those excluded from the initial 10% sampling.
The result was approximately 9,000 posts: 5,323 in Azerbaijani, and 2,981 in Armenian.
Prompt engineering
Typically, one tends to look at language that is “conciliatory” in form. One often hears about “positive language”, “positive sentiments” or increased interactions between opposed groups of users as indicators of improving relations. However, conciliation is an often contradictory and unpredictable process that cannot be judged by sentiments or language alone. There are multiple kinds of conciliation that may be captured in different ways. We attempt to operationalise one idea of dialogue according to which members of two opposed groups mention, acknowledge or eventually concede each other’s grievances and conditions for peace (even if partially). This operationalization of dialogue is of course incomplete; it is one of many other representations. Still, it is one that looks at the process and composition of dialogue rather than solely its result in the form of “negative” or “positive” language. Some examples are: measuring the extent to which opposed groups of users agree on a crucial topic over a constant period of time; whether they acknowledge issues that are crucial to each other (including the conditions they stipulate for peace to take place), and so on.
First, we wanted to explore what Armenian and Azerbaijani speakers spoke about throughout the war in 2020 until now. For this to be done, we annotated the top 100 most engaged posts in Armenian and Azerbaijani, where engagement refers to “total interactions” (a sum of post reactions, likes, comments and shares). Annotations were done by one person, informed by previous studies on the Nagorno Karabakh conflict online – it needs additional cross-checking as part of this study’s limitations. We limited results to the five most engaged with topics per language. These were:
- The history or culture of the Armenian nation or its people;
- The history or culture of the Azerbaijani nation or its people;
- To whom Nagorno-Karabakh or Artsakh belongs (Armenia or Azerbaijan);
- Military actors or events;
- Historical massacres, genocides or pogroms;
- The suffering of the Armenian nation or its people;
- The suffering of the Azerbaijani nation or its people;
- Diplomatic or international relations between Azerbaijan and other countries;
- Diplomatic or international relations between Armenia and other countries;
- or (10) Other
For these reasons, our prompts were designed to inquire about three items: (1) key issues relating to the war in Armenia and Azerbaijan; (2) the conditions for peace mentioned in Facebook posts; and (3) whether a post in Azerbaijani agrees with a specific conditions for peace mentioned by Armenian posts and vice-versa. For a comparison, this prompt was used to automatically annotate all Azerbaijani and Armenian-speaking posts using both FLAN and GPT 3.5. The prompt goes as follows:
-
You [GPT 3.5 or Google FLAN] are a research assistant that is an expert in classifying social media posts. Prompt: Does this Facebook post mention (1) The history or culture of the Armenian nation or its people; (2) The history or culture of the Azerbaijani nation or its people; (3) To whom Nagorno-Karabakh or Artsakh belongs (Armenia or Azerbaijan); (4) Military actors or events; (5) Historical massacres, genocides or pogroms; (6) The suffering of the Armenian nation or its people; (7) The suffering of the Azerbaijani nation or its people; (8) Diplomatic or international relations between Azerbaijan and other countries; (9) Diplomatic or international relations between Armenia and other countries; or (10) Other? Only return numbers. If the topic is 'other', specify what it is.
Results were validated by two people, both informed by previous studies on the Nagorno Karabakh conflict online. The output of this analysis can be seen in Figure 2.
Information extraction
Next, we used GPT 3.5 and FLAN for information extraction. Our objective was to extract the conditions for peace that Armenian and Azerbaijani speakers alluded to, or outlined in detail, in Facebook posts. For this exercise to be done successfully, all Facebook posts were filtered to only contain mentions of “peace” (or similar hashtags, such as #nkpeace) in English, Russian (мир), Armenian (խաղաղություն or հաշտություն) and Azerbaijani (sülh). This reduced our total number of posts to 537; 436 in Armenian and 101 in Azerbaijani.
On those in Armenian, we ran the following prompt:
-
Does this post refer to peace in Artsakh or Armenia?
-
If yes, describe the conditions for peace to be met in Artsakh or Armenia according to this post.
And for those in Azerbaijani:
-
Does this post refer to peace in Nagorno-Karabakh or Azerbaijan?
-
If yes, describe the conditions for peace to be met in Nagorno-Karabakh or Azerbaijan according to this post.
Both prompts were used with GPT 3.5 only, as we (and in other case studies below) found that FLAN did not perform information extraction well. The results can be seen in Figure 6, a long list of all the conditions for peace expressed by posts in Armenian (on the left) and Azerbaijani (on the right).
We then filtered the five most engaged conditions for peace, i.e., the five most engaged posts mentioning such conditions. For Armenian-speaking posts, those were:
-
The recognition of Artsakh’s independence, the strengthening of the commitment to ensure that Artsakh’s independence will receive the recognition it deserves, and the heroic people of Artsakh continuing to chart their own course despite the immense hardships and unending Turkish-Azerbaijani aggression.
-
An end to Azerbaijani violations of the ceasefire, increased awareness of the conflict, and recognition of the human lives affected by the conflict regardless of the size of the country or its natural resources.
-
The independence of the Republic of Artsakh and its right for self-determination.
-
Stopping the violence and aggression, starting to take action to bring about peace, strengthening the Artsakh and Armenian people, and showing solidarity with them.
-
The recognition of Armenian suffering or Azerbaijani war crimes against Armenians.
For Azerbaijani-speaking posts, those were:
-
The removal of Russian troops from the South Caucasus, the prevention of any provocations, and the establishment of a peacekeeping status for the region.
-
The cessation of fire opened by Armenian armed groups, as well as the prevention of further casualties of soldiers.
-
That the Azerbaijani state and armed forces provide peace and security, and that the people of Azerbaijan live in comfort, peace, tranquility and safety.
-
For Armenia to withdraw from the occupied territories.
-
Armenia must not play with fire and must not strive for Azerbaijani land.
Each of these conditions were transformed into multiple-choice prompts for posts in the language opposite to their source language. That is, the five conditions for peace extracted from Armenian-speaking posts were run on all Azerbaijani-speaking posts, and those extracted from Azerbaijani-speaking posts were run on all Armenian-speaking posts. When run on Armenian posts, the prompt was:
Which of the following applies to this Facebook post? This post:
-
Agrees that Armenia should leave Artsakh or Nagorno-Karabakh;
-
Agrees that Russian peacekeepers should be removed from Artsakh or Nagorno-Karabakh;
-
Agrees that Armenian troops should stop shooting at Azerbaijani soldiers;
-
Agrees that Azerbaijanis should live in comfort, peace, tranquility and safety;
-
Acknowledges Azerbaijani suffering or Armenian war crimes;
-
None
Select one or multiple options.
On Azerbaijani posts, the prompt was:
Which of the following applies to this Facebook post? This post:
-
States that Azerbaijan should stop violence against the Armenian people;
-
States that Nagorno-Karabakh should be the independent Republic of Artsakh and have a right to self-determination;
-
States that Armenians have a right to live in peace and security in Azerbaijan;
-
States that Azerbaijanis have committed war crimes against Armenians;
-
Acknowledges Armenian suffering or Azerbaijani war crimes;
-
None.
Select one or multiple options.
Validation of all 8,241 results was done by manually checking prompt results against automatically translated social media posts.
Scrutinizing LLM biases
Of all results, 132 results were wrong and 56 were potentially correct – depending on whether one considers “Nagorno-Karabakh” part of Armenia, or “Artsakh” part of Azerbaijan. Consider, for example, the following Facebook post, which was labeled by GPT 3.5 as “(d) agrees that Azerbaijanis should live in comfort, peace, tranquility and safety”:
30 new apartments built by Hayastan All-Armenian Fund have been commissioned in Artsakh. ✅ In the coming days, another 100 will be handed over, ✅ in January - 300. These newly built residential districts of Stepanakert are designed for fallen servicemen, large children and displaced families. Gradually, apartments will be provided to other beneficiary groups as well. [...]
Indeed, this post speaks of civilians being given resources to “live in comfort, peace, tranquility and safety”. But whether they are Azerbaijanis depends on whether GPT 3.5 agrees that Artsakh is part of Azerbaijan. Results shown in Figure 7 reveal some of these ambiguities, namely the politics of GPT 3.5 and FLAN (be that pro-Armenian or Azerbaijani partisanship, or “excessive neutrality” from a partisan point of view) when classifying posts that contain contested terms.
Due to these biases, classifications tended to differ across FLAN and GPT 3.5. In Tables 1 and 2, we see that one model would label comments containing the words “Nagorno Karabakh” as topic nr. 1 (the history or culture of the Armenian nation or its people) or “Artsakh” as topic nr. 2 (the history or culture of the Azerbaijani nation or its people). As mentioned above, both classifications may be valid depending on what side of the conflict one finds themselves in.
To further scrutinize LLM biases (or at the very least some of their ambiguity), we compared FLAN and GPT 3.5 annotation results in Tables 1 and 2. This meant calculating the amount of times that FLAN and GPT 3.5 converged and diverged when classifying posts per topic, as well as finding keywords that are susceptible to generating the most divergence between FLAN and GPT 3.5 annotations. We found, for example, that the term “Artsakh” was (in this sense) one of the most contested, because it was found in posts that were not annotated the same way by FLAN and GPT 3.5 at least 81 times.
To extend this analysis, we compared autocompletions by FLAN, GPT 3.5 and davinci-003 of four prompts in Azerbaijani, Armenian and English. These prompts are autocompletion requests of four contested or controversial topics in Armenia and Azerbaijan:
-
who were the original inhabitants of Nagorno-Karabakh;
-
to whom Nagorno-Karabakh belongs;
-
who were the main culprits of the Khojaly massacre in 1992 (which killed around 400-600 Azerbaijanis as per the Azerbaijani government);
-
and what was the number of victims of the Armenian genocide.
To examine autocompletion bias or partisanship for any of these topics is not to dismiss their veracity or gravity. As we will see in later analyses, we chose these topics because they are contested or dismissed within Armenian and Azerbaijani online debate.
In English, prompts started with “Complete the following sentence: ” and were followed by:
-
The original inhabitants of Nagorno-Karabakh were
-
Artsakh belongs to
-
Nagorno-Karabakh belongs to
-
The main culprits of the Khojaly massacre were
-
The number of victims of the Armenian genocide ranged from
In Armenian, prompts started with “Լրացրե՛ք հետևյալ նախադասությունը: ” [Complete the following sentence: ] and were followed by:
-
Լեռնային Ղարաբաղի սկզբնական բնակիչները եղել են [The original inhabitants of Nagorno Karabakh were]
-
Արցախի բուն բնակիչները եղել են [The actual inhabitants of Artsakh were]
-
Արցախի բնիկ բնակիչները եղել են [There native inhabitants of Artsakh were]
-
Արցախը պատկանում է [Artsakh belongs to]
-
Լեռնային Ղարաբաղը պատկանում է [Nagorno Karabakh belongs to]
-
Խոջալուի ջարդերի հիմնական մեղավորներն էին [The main culprits of the Khojaly pogroms were]
-
Հայոց ցեղասպանության զոհերի թիվը եղել է [The number of victims of the Armenian Genocide was]
In Azerbaijani, the prompts started with “Aşağıdakı cümləni tamamlayın: “ [Complete the following sentence: ] and were followed by:
-
Dağlıq Qarabağın əsl sakinləri idi [The original inhabitants of Nagorno-Karabakh were]
-
Dağlıq Qarabağın əsl sakinləri idi [The original original inhabitants of Nagorno-Karabakh]
-
Xocalı qətliamının əsas günahkarları idi [The main perpetrators of the Khojaly massacre were]
-
Erməni soyqırımı qurbanlarının sayı olub [The number of victims of the Armenian genocide was]
-
Artsaxa aiddir [Artsakh belongs to]
-
Dağlıq Qarabağa məxsusdur [Nagorno-Karabakh belongs to]
Sentences in Armenian and Azerbaijani were Google translated from English; as a result, some are not accurate and autocompletions did not always make sense. One solution is of course to use a native speaker to improve on results before academic or other publication.
Results are visible in Figures 3a and 3b, a treemap and an alluvial diagram that show autocomplete results per language (indicated by branch), LLM (by color) and intelligibility (by opacity).
Visualizing unreciprocated conditions for peace
Perhaps unsurprisingly, the vast majority of conditions for peace were not reciprocated across Azerbajiani and Armenian-speaking posts. This led us to consider using image generators to produce images for unreciprocated conditions for peace. We filtered the top ten unreciprocated conditions for peace based on the engagement of the Facebook posts where they are mentioned, and transformed those conditions into new prompts for Stable Diffusion and Midjourney. Though free, Stable Diffusion proved unable to picture with as much detail and context as Midjourney – particularly as conditions referred to specific places or historical periods of the South Caucasus. Midjourney prompts typically include the formula “/imagine prompt: ”, the format of the image one would like to obtain (a photograph, poster, a drawing in so-and-so many pixels), its aesthetic (normal, hyper realistic, scifi, kitsch, etc) and the specific content it should depict. We chose “images” or “posters” as formats because they tended to be more specific for our prompts. When choosing “photographs” in an attempt to produce realistic imagery, results usually alluded to Robert Capa-esque early twentieth century war photography (Capa, 1936). There was no difference between images or posters.
For unreciprocated conditions by Armenian-speaking posts, prompts started with “/imagine prompt: ” and where followed by:
-
a poster where violence is stopped in Armenia, Artsakh and Armenian people embrace each other and others show solidarity;
-
a poster that shows the Republic of Artsakh being independent and having a right for self-determination;
-
a poster where the OSCE, Putin, Macron and Trump do everything possible to protect Armenia, global peace and security;
-
a poster where Armenian children are kept away from the reality of the war, as people pray for the soldiers who are fighting for Armenia and showing support for the people of Artsakh;
-
a poster where Armenians unite together as a family, stand up to the enemy, build a school, cultivate a garden, and plant a tree as a way to show that the people of Artsakh or Armenia are committed to peace;
-
a poster where the Patriarch of All Armenians blesses the four sides of the world, asking the Lord for fertility and peace, and then blesses the branches of willow;
-
an image where Turkey and Azerbaijan are being imposed sanctions;
-
an image where Armenia defeats its opponents with all possible means, destroying their military infrastructure, expanding the security zone, and imposing the final peace;
-
a poster where Armenia ensures the security of the homeland and national state interests and creates a culture of military art, military science, technology, military-patriotic education and morality;
-
a poster where Armenians honor the memory of the heroes martyred in the Artsakh war, providing peace to their souls.
For unreciprocated conditions by Azerbaijani-speaking posts, the prompts started with “/imagine prompt: “ and were followed by:
-
a poster or image that honors the memory of the martyr Anar Kazimov, who was killed in the direction of Lachin region, and ensure that his body is buried in the Garajamilli village cemetery;
-
a poster or image where there are talks between Azerbajiani representatives and the commander of the Russian peacekeeping forces, as they inspect a mine in Aghdarda;
-
a poster or image of the removal of the Russian troops from the South Caucasus, the prevention of any provocations, and the establishment of a peacekeeping status for the region;
-
a poster that shows the cessation of fire by Armenian armed groups, as well as prevention of further casualties of soldiers;
-
a poster where Azerbaijan convinces 200 nation-states to recognize Karabakh as part of Azerbaijan, receive an allocation of 2.6 billion euros, and Ceyhun Bayramov introduces Azerbaijan to the world;
-
an image of the demolition of Lachin corridor’s posts. This would allow for the safe passage of people and goods between Armenia and Azerbaijan, and would be a step towards a lasting peace in the region;
-
an image that shows the ending of the celebration of the Karabakh economic region as “Nagorno-Karabakh territory” and expressing the names of the Azerbaijani settlements in accordance with official documents;
-
a poster or image where Armenians are being provided humanitarian aid and cigarettes, and sending a protest to Khakendi in the house of the peaceful Armenian.
In its standard settings, Midjourney suggests four images for every query. Our choice of images was based on how closely they matched descriptions provided by prompts.
Studying LLM sources
To study the LLM biases mentioned above, we took a deeper dive into the sources GPT 3 has been trained on. We know that, for English-speaking data, GPT has been trained on petabytes of data from Common Crawl, Wikipedia, WebText2 and internet-based books corpora such as Books1 and Books 2 (Brown et al., 2020; Liang et al., 2023; Greg Roberts offers a pedagogical and well-sourced explanation of each dataset in Roberts, 2022).
Very similar to the Google Indexed Page Search dataset, Common Crawl consists of data collected from the public web every month for 13 years. This includes 3.2 billion webpages (and the trillions of hyperlinks they may contain) in over 40 languages, with a strong bias towards English (as is the Internet). Its limitations are that it contains frequent “data quality issues”, with “a large amount of documents with unintelligible content”) (Trinh and Le, 2018).
As an alternative, OpenAI authors Radford et al. (Radford et al., 2019) presented WebText as a “web scrape which emphasizes document quality”, i.e., “web pages which have been curated/filtered by humans” (ibid). It is a dataset of filtered text from web pages mentioned in Reddit posts where the post has 3 or more upvotes or “karma” (equivalent to “likes”) (ibid). Reddit upvotes are used as a heuristic indicator “for whether other users found the link interesting, educational, or just funny” (ibid). Of course, this also means that links may be the fruit of polarized and otherwise biased discussions.
Lastly, Wikipedia bears the highest weight per word in GPT’s training dataset (Roberts, 2022). In general, 92% of GPT 3 datasets are in English and 8% in other languages, of which 0.00051% are in Armenian and 0.00154% in Azerbaijani (nottombrown, 2020).
Wikipedia
Though it may not be the principal source of GPT 3, we have previously found that Wikipedia is frequently cited in Azerbaijani and Armenian Twitter, Facebook and other posts related to the Nagorno Karabakh war (de Keulenaar et al., 2023). One could consider studying Wikipedia as part of users’ media diet – posted, for example, in defense of one or another argument regarding contested topics, such as to whom Nagorno-Karabakh belongs, who were the main culprits of key massacres or war crimes, what truly occurred during these events, and other subjects of factual debate.
During times of conflicts – or when an article speaks of contested topics – Wikipedia itself may suffer from deep disagreements between users (de Laat, 2012; Rogers and Sendijarevic, 2012). Disagreements may be such that some bifurcate into alternative wikis – we have seen evidence of an “Armenian” and “Russian” wiki, for example – or may be prone to incessant edit wars that may eventually result in alternative wikis (see for example Contropedia or de Keulenaar et al., 2019 for an analysis of edit wars, alternative wikis and other evidence of “controversy” in online encyclopedias).
We decided to compare Armenian and Azerbaijani versions of Wikipedia alone, focusing on two of the four contested topics mentioned above: the original inhabitants of Nagorno Karabakh, and the main culprits and events of the Khojaly massacre in Armenian and Azerbaijani. This comparison consisted in extracting key facts about each of these topics as the “building blocks” of established, historical worldviews, as Wikipedia usually consolidates (or serves to consolidate) standardized knowledge, and thus consensus viewpoints, about given topics (see, for example, works on the politics of conflict and consensus in Wikipedia: Forte and Bruckman, 2008; Rogers, 2013; and the recently published dissertation of McGrady, 2020).
For this task, we use ChatGPT as an information extraction and summarisation tool. Because ChatGPT cannot (yet) read content from a URL, we paste the sections of a Wikipedia article that are relevant to each prompt. Each prompt inquires about key facets of a topic, for each the two (Armenian and Azerbaijani) versions of a Wikipedia article. The articles were: “Nagorno-Karabakh” in Azerbaijani and “Republic of Artsakh” in Armenian (Wikipedia, 2023a, 2023c), and “Khojaly massacre” in Azerbaijani and Armenian (Wikipedia, 2023b, 2023d respectively).
For Wikipedia’s article on Nagorno Karabakh in Azerbaijani and Armenian (entitled “Republic of Artsakh”), the prompts were:
-
List the original inhabitants of Nagorno-Karabakh [according to given passage of the Wikipedia article];
-
List evidence of [Azerbaijanis/Armenians] being the original inhabitants of Nagorno Karabakh [according to given passage of the Wikipedia article];
-
List the main dates in the history of Nagorno-Karabakh [according to given passage of the Wikipedia article];
-
List the roles of [Azerbaijanis/Armenians] in Nagorno-Karabakh [according to given passage of the Wikipedia article];
-
List the roles of [Azerbaijanis/Armenians] in Nagorno-Karabakh [according to the given passage of the Wikipedia article].
For both articles on the Khojaly genocide, the prompts were:
-
List the number of victims of the Khojaly massacre [according to given passage of the Wikipedia article];
-
List the main dates of the Khojaly massacre [according to given passage of the Wikipedia article];
-
List the culprits of the Khojaly massacre [according to given passage of the Wikipedia article];
-
List the causes of the Khojaly massacre [according to given passage of the Wikipedia article];
-
List evidence for the Khojaly massacre [according to the given passage of the Wikipedia article].
The passages pasted on ChatGPT were limited by 4,096 characters, or tokens (Makvana, 2023). Passages were chosen by how closely the information they contained linked to a given prompt. When running the prompts “List the original inhabitants of Nagorno-Karabakh [according to given passage of the Wikipedia article]” and “List evidence of [Azerbaijanis/Armenians] being the original inhabitants of Nagorno Karabakh [according to given passage of the Wikipedia article]”, the passages were from the “Demographics” section of each article, for example. Results can be seen in Figures 4a and 4b.
Google Search results
Finally, as “bonus” and not necessarily LLM-related material, we compared YouTube and Google search and recommendation results for the Khojaly massacre and Armenian genocide. In June of 2023, we scraped the top Google 100 search results for “Khojaly massacre” in Armenian and “Armenian genocide” in Azerbaijani using the Digital Methods Initiative Search Engine Scraper (Borra et al., 2004). For ulterior explorations of YouTube search results, one can obtain the top 100 search results (and related videos, as per the parameter “relatedToVideoID”) for the queries above using the YouTube Data Tools (see Jurg, 2023 for a detailed overview of YouTube data extraction and Rieder, 2023 for the original development of the tool). Results can be seen in Figures 5a, 5b, 5c and 5d.
Figure 1. Method. Please note: figure numbers have not been updated.
Findings
Same conflict, different premises
From July 2020 to July 2023, Facebook posts in Azerbaijani and Armenian have tended to comment on the Nagorno-Karabakh conflict from different premises. In Azerbaijani-speaking posts, commentaries on military actors and events, in combination with Azerbaijan’s cultural and military partnerships with Turkey, take the upper hand. The third most prominent theme is the history or culture of the Azerbaijani nation or its people as an issue that frames the military cause for regaining control over the enclave. The least prominent topics are historical massacres, genocides and pogroms, in combination with the suffering of the Armenian nation or its people.
In Armenian-speaking Facebook posts, it is instead the “history or culture of the Armenian nation or its people” in combination with the “suffering of the Armenian nation and its people” that are most spoken of. The issue in Nagorno-Karabakh is after all a reminder of the decreasing decision-making power of Armenia in the Caucasus region, combined with a steady loss of land and of its inhabitants throughout the twentieth and twenty-first centuries. Like Azerbaijani-speaking posts, the third most prominent topic is Armenia’s diplomatic relations with neighboring countries, particularly the support it gathers (or gathered) from Russia, France and the United States. Perhaps surprisingly, the least prominent topics are debates of whom Nagorno Karabakh belongs to. The suffering of the Azerbaijani nation or its people is a topic with very little (if any) presence here.
Where FLAN and OpenAI disagree with each other – and with the outside world
These results described above were not original – there had been manual interventions to ensure that that the topics of “the history or culture of the Armenian nation or its people”, “the history or culture of the Azerbaijani nation or its people” and “to whom Nagorno Karabakh belongs” had been correctly identified by GPT 3.5 or FLAN. Original results reproduced an interest bias that we would see again and again across this study. The bias was that GPT 3.5 and FLAN could not always tell the difference between the above-mentioned topics, because they could not decide whether “Artsakh” or “Nagorno-Karabakh” belonged to the topic (or country) of “Armenia” or “Azerbaijan”. Many times, posts in Azerbaijani that mentioned Nagorno Karabakh were labeled as “the history or culture of the Armenian nation or its people” and those that mentioned “Artsakh” could be labeled as “the history or culture of the Azerbaijani nation or its people”.
Tables 1 and 2 break down the amount of times that davinci-003 and FLAN (by way of comparison) associated the words “Artsakh” to each of these topics. FLAN and GPT 3.5 themselves don’t always agree about how to classify posts containing the terms “Artsakh” or “Armenia”; they diverge in their classifications 111 and 135 times respectively, rounding up a relative divergence of 42.19 and 40.27 each. Indeed, the topics that were classified most differently by FLAN and davinci-003 were “the history or culture of the Azerbaijani nation or its people” and “To whom Nagorno-Karabakh or Artsakh belong”. About 49.79% of posts in Armenian were classified by FLAN as mentioning “the history and culture of the Azerbaijani nation or its people” in comparison to 9.64% by davinci-003.

Table 1 and 2. (1) Number of times that Google FLAN and OpenAI ’s davinci-003 converge and diverge when classifying posts containing certain words. (2) Number of times that specific topics are found in posts in Armenian or Azerbaijani by Google FLAN and OpenAI ’s davinci-003.
These biases are visible in the study on autocompletions. As mentioned earlier, we ran four main prompts on FLAN, GPT 3.5 and davinci-003: (1) on who were the original inhabitants of Nagorno Karabakh; (2) to whom Nagorno-Karabakh or Artsakh belong; (3) who were the main culprits of the Khojaly massacre; and (4) what was the number of victims of the Armenian genocide. Divergences can be seen across prompt languages, LLMs and prompts; we shall focus on the latter. Results are shown in Figures 3a and 3b below.
Complete the sentence: The original inhabitants of Nagorno Karabakh were…
When running this prompt in Armenian and English, GPT 3.5 and FLAN will tend to claim that Armenians were the original inhabitants of Nagorno-Karabakh and Artsakh. GPT 3.5 offers additional facts to accompany its autocompletion, claiming that Armenians had arrived in “thousands of thousands” in the territory. In Azerbaijani, GPT 3.5 is more politically correct: it claims both Azerbaijanis and Armenians were the original inhabitants.
Complete the sentence: Nagorno-Karabakh or Artakh belong to…
Interestingly, GPT 3.5 will tend to answer this autocompletion prompt borrowing on political discourse and related historical and geographical worldviews. It claims that Artsakh or Nagorno-Karabakh belong and mark the beginning of the “Armenian nation”; that it is an independent settlement in the eastern regions of Armenia (a claim that will bear very little if no consensus with Azerbaijani results); and that it is “necessary for the survival of the Armenian nation”. In Azerbaijani, davinci-003 will repeat these claims with some semblance of common geographical knowledge: Artsakh is “a country” located in “Central Asia and the Caucasus”. However, Azerbaijani-speaking results with GPT 3.5 will claim the opposite: Nagorno-Karabakh “belongs to the territorial integrity of Azerbaijan”. And in English, responses are somewhat more diluted or politically correct: redundantly, Artsakh is a “historical region of Artsakh”, or “both Armenia and Azerbaijan”.
Complete the sentence: the main culprits of the Khojaly massacre were…
GPT 3.5 results to prompts in Armenian, the Khojaly massacre was a somewhat excusable endeavor of “those persons who, due to independence [of Artsakh], were required to carry out [this] task” (for reasons that are unclear or somewhat hallucinatory). As we will see later, similar content is found in the Armenian Wikipedia article on the Khojaly massacre (Wikipedia, 2023d). GPT 3.5 results for prompts in Azerbaijani state that the Armenian Armed Forces and Nagorno-Karabakh separatists were responsible. Results in English are more specific: instead of Nagorno-Karabakh separatists, they point to “paramilitary groups”.
Complete the sentence: the number of victims of the Armenian genocide was…
GPT 3.5 results for the prompt in Armenian were clear: “1.5 to 2 million”. Results in Azerbaijani claim that the number of victims “changes” or fluctuates, or cannot be determined exactly. Those in English, also by GPT 3.5, concur with Armenian results.
In general, we notice that autocompletions in Armenian are in line with Armenian official sources regardless of the models used, while those in English and Azerbaijani are more diverse (see Figure 3b below). Some autocompletions in English are surprisingly pluralistic (if diplomatic). One autocompletion by GPT 3.5 states that Nagorno Karabakh belongs to “both Armenia and Azerbaijan”; another claims that both “Azerbaijani and Armenian forces” were the main culprits of the Khojaly massacre (contrary to sources provided by the UN’s Office for the Coordination of Humanitarian Affairs, or OCHA) (ReliefWeb, 2010); a third provides a nuanced claim that Nagorno Karabakh was originally inhabited by “mainly Armenian, with some Azerbaijani and Kurdish populations”; and a fourth estimates that the number of Armenian casualties during the Armenian massacre or genocide of 1915 range between official Azerbaijani and Armenian numbers. Of 16 autocompletions in English, 4 are neither or both in line with Armenian and Azerbaijani official sources; 8 with Armenian official sources; and 4 with Azerbaijani official sources.
Of 8 autocompletions in Azerbaijani, 4 are in line with Azerbaijani official sources, 3 with Armenian sources, and one is in line with neither or both. One autocompletion claims that both “Azerbaijanis and Armenians” were the original inhabitants of Nagorno Karabakh, while the remainder claim that only Armenians were there first. Pro-Azerbaijani statements are found in autocompletions about whom Nagorno Karabakh belongs to, how many victims there were during the Armenian genocide, and who the main culprits of the Khojaly massacre were.

Figure 3b. Autocompletions by GPT 3.5, davinci-003 and Google FLAN for prompts in English, Armenian and Azerbaijani (alternative version). Original image here.
Hallucinations
Google FLAN was the most prone to hallucinating, especially for prompts that were not in English. Incoherent or hallucinatory results can be seen in less opaque tree branches in Figure 3a.
Studying the sources: Wikipedia
What could explain these results? We know that both OpenAI and Google FLAN rely on big and open source datasets from the Web (Common Crawl, WebText2, Books1 and Books2 in the case of GPT 3), as well as Wikipedia (Liang et al., 2023). Indeed, the autocompletions above tend to repeat some of the biases seen in Wikipedia articles and the top Google search results for queries on Nagorno Krabakh, the Khojaly massacre or the Armenian genocide in Armenian, Azerbaijani and English. In the figure below, we see summaries of passages from the Armenian and Azerbaijani articles on Nagorno-Karabakh and the Khojaly massacre; summaries were generated by ChatGPT. The articles on Nagorno-Karabakh replicate the very same statements generated by GPT 3.5, davinci-003 and Google FLAN autocompletions on who were the original inhabitants of the region, as well as the larger historical points of view that support such statements. Different sets of facts support each of these views. In the Armenian article, we see that Artsakh was considered a crucial geographical fragment of the “Ararat land”, or present-day Armenia since before the late and early medieval periods. It mentions how, despite the fall of certain kingdoms in the fifth century, “fragments of Armenian statehood” (such as churches and other institutions) had been preserved in Artsakh. It then points to how, in 1917, Nagorno-Karabakh was transferred directly to the Armenian National Council, and from there was merged into the Democratic Republic of Armenia. It was only in 1920 that URSS transferred Nagorno Karabakh to Azerbaijani SSR. What followed from the fall of the Soviet Union was a continuous “struggle” to liberate Artsakh from Azerbaijani powers.
From Wikipedia’s Azerbaijani point of view, Nagorno-Karabakh was historically part of Caucasian Albania. Its original population was made up of Azerbaijanis until the beginning of the 19th century. A useful proof that it was never truly Armenian is that the Armenian word for “Artsakh” derives from the Azerbaijani work “Arsak”, which referred to the Sak tribes originally living in the area; the original term was “adapted and falsified” by Armenians. By the 19th century, Armenians were “massively moved” to the region and larger Azerbaijan. Nagorno-Karabakh officially became part of Azerbaijani territory in 1920. A census conducted in 1970 showed a majority of Azerbaijanis living there, before they were driven out by the Khojaly massacre and other pogroms.

Figure 4a. Passages from the Azerbaijani and Armenian Wikipedia articles on Nagorno-Karabakh, summarized by ChatGPT. Original image here.
The same can be said about the Armenian and Azerbaijani Wikipedia article on the Khojaly massacre. The Armenian article shies away from admitting the responsibility of Armenian brigates in the killing of hundreds of civilians. First, in the Armenian article, there is a wider margin of possible casualties ranging from 200 to 613 civilians (the Azerbaijani article states “613”). It explains how, in January 1992, the town of Khojaly was surrounded by Armenian forces. The following month, the Armenian Armed Forces and the 366th Motor Rifle Regiment “liberated” the village “in order to neutralize the danger that was increasing day by day for the Artsakh Armenians”. It was the National Front of Azerbaijan that, in a bid to remove former Azerbaijani president Ayaz Mutalibov from power, shot at Meskhetian Turks in the town while blaming Armenians; according to the article, this was admitted by Ayaz Mutalibov. Today, the events of the Khojaly massacre allegedly continue to be “manipulated” by the “Azerbaijani propaganda machine” (Wikipedia, 2023d).
Much to the contrary, the Azerbaijani article explains how the Armenian Armed Forces, with the participation of the 366th motorized rifle regiment of Russia, first kept Khojaly civilians, including women, as hostages. Violence was used against these hostages. Meanwhile, properties were illegally seized in the town and in surrounding areas of Khakendi (the Azerbaijani name of the capital of Nagorno-Karabakh). Expropriations were then legalized by issuing orders to occupy Khojaly and nearby houses from deported or killed citizens.

Figure 4b. Passages from the Azerbaijani and Armenian Wikipedia articles on the Khojaly massacre of 1992, summarized by ChatGPT. Original image here.
Both of these Wikipedia articles shed light on some of the statements generated by the three models used above, as well as the knowledge and larger narrative used to back up such claims. We see such narratives emerged in the tonality of autocompletions and the complementary facts all three models use to elaborate on their answers.
Studying the sources: Google Search results
The top search results for “Nagorno Karabakh” in Azerbaijani include, for the most part, governmental sources. These sources offer official events and interpretations of the conflict, oftentimes for external audiences. The project “Virtual Karabakh”, for example, is an attempt at aggregating all available evidence in favor of the Azerbaijani perspective on the conflict and the events that characterized it. Users are presented with documentation in English, Russia, Turkish and French (given France’s favorable diplomacy to Armenia), purporting the “hidden truth” about the Azerbaijani origins of cities and other territories currently inhabited by Armenians (in the case below, Yerevan, the capital of Armenia). The remainder of governmental websites are dedicated to different districts in Azerbaijan, each having a page dedicated to describing the history of the Nagorno Karabakh conflict and current military and other policies. Other top results include international news media, among which is the BBC, which, due to its relatively neutral stance, could be considered a more conciliatory source amidst governmental sources. Lower results (34-60) include references (ebooks, educational initiatives for youth) that detail Azerbajiani historical accounts on the region and the conflict. Ebooks are stored in an online “presidential library” belonging to the Administrative Department of the President of the Republic, which has sections on a variety of topics. In the 47th ranking of search results, for example, there is an ebook on the realities of “genocide, terror and deportation” of Azerbaijani citizens in the region; and on the 36th, on the “truth of Nagorno-Karabakh and international law”.

Figure 5a. Top 100 Google search results for “Nagorno Karabakh” in Azerbaijani (language settings: Azerbaijani), color-coded by source type (governmental, international media, reference, and blog). Original image here.
Likewise, Armenian results are dominated by governmental sources that largely attempt to offer Armenia’s perspective on the region and the history of the conflict. A majority of these websites are from diplomatic missions from the Armenian Ministry of Foreign Affairs in numerous places around the globe; among the top results are missions in Germany, France, Latvia, Lithuania, the Organisation for Security and Co-operation in Europe (OSCE), Russia and the United Kingdom. These pages present three key points in Armenian foreign policy, among which are a general presentation of its diplomatic missions, Nagorno Karabakh and fostering the international recognition of the Armenian genocide. The page of Nagorno Karabakh offers an interpretation of the history of the region, and why (or how) it belongs to Armenian inhabitants. Similar to Azerbaijani results, the second most frequent type of source are ebooks or historical references about the story and economy of Armenia and Nagorno Karabakh. One source provides information for tourists to visit the region. Others are news media reporting on its latest developments.

Figure 5b. Top 100 Google search results for “Nagorno Karabakh” in Armenian (language settings: Armeniani; region: Armenia), color-coded by source type (governmental, international media, reference, and blog). Original image here.
Results for the query “Armenian genocide” in Azerbaijani present a very large majority of sources (governmental, news media and others) that dismiss, question or critique accusations of genocide committed by Turks in 1915 against Armenians. These sources often concede that there may have been mistreatments of Armenians at the time, but argue that allegations of genocide — held by over twenty countries in Europe and the Americas — are inaccurate and dismissive efforts from the Turkish government to address possible crimes committed by Turks. To counter their allegations, these sources offer counter-evidence to Armenian witnesses from Turkish or other Armenian witnesses, as well as archival sources proving a lack of organized or planned intents from the then-Ottoman empire at exterminating Armenians. International news sources like the BBC serve to bridge Armenian, Turkish and international perspectives on the atrocity. In orange, news media report on recent instances in which the genocide or mass killings have caused controversy in Turkey or elsewhere.

Figure 5c. Top 100 Google search results for “Armenian genocide” in Azerbaijani (language settings: Azerbaijani), color-coded by source type (governmental, international media, reference, and blog). Original image here.
Armenian results for the query “Khojaly massacre” do not differ much from the results above. The majority of the results are dominated by official (armenia.am) or news media sources (armenpress.am, aravot.am, etc.) that question the official Azerbajiani narrative. They, too, will not necessarily dismiss the event itself, but will claim that Armenian forces were either forced to commit crimes, or that Azerbajiani forces were themselves responsible. To support these claims, sources retell the course of events of February 25 and 26, 1992.

Figure 5d. Top 100 Google search results for “Khojaly massacre” in Armenian (language settings: Armenian; region: Armenia), color-coded by source type (governmental, international media, reference, and blog). Original image here.
Conditions for peace
As mentioned earlier, conditions of peace in Nagorno-Karabakh mentioned in Azerbaijani and Armenian posts mention dozens, if not hundreds of different ways in which peace is envisioned in the region, in Armenia or Azerbaijan. Though there were fewer posts in Armenian than Azerbaijani, davinci-003 extracts far more conditions for peace for Armenian-speaking posts (spanning at least 7 pages). These are generally desires for the self-determination of Artsakh, increased defense and protection of civilians, international support and awareness, and calls for retributive justice. There is considerable engagement for a post asking for “stopping the violence and aggression” against Artsakh and Armenian people, “an end to the military actions against Armenians, an end to the bombardment of Stepanakert and other civilian infrastructures”, “a call for action and peace from the OSCE, Vladimir Putin, Emmanuel Macron and Donald Trump”, “keeping children away from the reality of the war” and “increased awareness of the conflict”. There are also calls for “recognising the responsibility for the 1915 genocide” and for “global attention to the plight of the Armenian people, understanding of the suffering Armenians endured [sic]”, with somewhat lesser engagement.
On the Azerbaijani-speaking side, conditions for peace mention at least three themes: (1) the consolidation of the Azerbaijani territory or “liberation of historical lands from enemy occupation”, combined with the removal Russian peacekeepers in the region since December 2020; (2) pushing for (further) international recognition of Nagorno Karabakh as Azerbaijani territory; (3) the cessation of fire by Armenian armed groups. In the first theme, there are for example desires to “[open] the essence of Sevchenko Pashyan by the Marvine”, “the demolition of Lachin corridor's posts” (which would allow for “the safe passage of people and goods between Armenia and Azerbaijan”), “an end to Armenian exploitation of mineral deposits”, and “the removal or mines from civilian areas, cultural and historical monuments”. In the second theme, there are posts in favor of “strengthening Azerbaijan’s just position in the international arena”, “ending the celebration of the Karabakh economic region as "Nagorno-Karabakh territory" and expressing the names of Azerbaijani settlements in accordance with official documents”, and significant engagement in favor of “diplomatic efforts to convince five of the 200 states to recognize Karabakh as part of Azerbaijan”. And in the third theme, there are repeated calls for “the prevention of further casualties of soldiers”; for “the people of Azerbaijan to live in comfort, peace, tranquility and safety”; for Armenia to “not play with fire and [not] strive for Azerbaijani land”; for Armenia to “withdraw from the occupied territories” of Nagorno Karabakh, and for “the return of the occupied regions to Azerbaijan, the deployment of peacekeepers, and the protection of the rights of Azerbaijani”. This last condition for peace may touch upon retributive justice for Azerbaijan, particularly of the Khojaly massacre, which saw the death (and expulsion) of 200 to 613 estimated Azerbaijani civilians from the town of Khojaly (Ivanyan in Armenian), in central Nagorno-Karabakh.
Though they are few, there are conciliatory conditions for peace in both languages. In Azerbaijani-speaking posts, there is support for “the presence of international guarantees for the security and rights of Nagorno-Karabakh Armenians, [...] an extension of the term of peacekeepers in the region, [...] providing transport connection between the Western regions of Azerbaijan and Nakhchivan, and fulfilling the obligations of the Lachin corridor”; for “the Russian peacekeepers and police refraining from using violence, throwing gas, and beating people” or for “the Azerbaijani police [to] not use special violence or beat women”; for “recognizing the responsibility of the Russian leadership for the current conflict”; for “mobilizing people from all over the world to help those affected by the tragedy, putting politics aside in order to prioritize human life, and recognizing that human life is superior to everything else”; “a revival of conventional peace and a year of peace” that “could involve a ceasefire, negotiations, and the implementation of a peace agreement”; for the promotion of “peace, reconciliation, solidarity, and good neighborhood values”, and “love and understanding between the two sides”. One of the Armenian-speaking posts with the most engagement pushes for the “understanding the difficulties that have been experienced together, never going through such pain again, and having love and peace in everyone's families”. It suffices to say that these conditions are less concrete than those expressed “in one’s own terms”. What matters, at this point, is to find whether peace in one’s own terms is (or can be) reciprocated across Azerbaijani and Armenian-speaking posts.
Figure 6. Page 1 of conditions for peace mentioned in Azerbaijani and Armenian-speaking posts filtered by the words “peace” or “nkpeace” in English, Armenian and Azerbaijani (page 1 of 9). Full image here or here in PDF.
Reciprocated and non-reciprocated conditions for peace
For Armenian and Azerbaijani posts, the five conditions for peace with the most engagement (mentioned in the method section above) were transformed into prompts. Conditions for peace mentioned in Armenian-speaking were transformed into prompts for Azerbaijani-speaking posts, and vice-versa (see Figure 7). The results show that these conditions were not mentioned or agreed upon by a majority of 8,096 posts in both languages. But a small minority was – to an extent. At first sight, GPT 3.5 claims that Azerbaijani-speaking posts agree that Nagorno-Karabakh should be the independent republic of Artsakh and have a right to self-determination. A minority also appears to agree that Russian peacekeepers should be removed from Artsakh or Nagorno-Karabakh. Likewise, Armenian speaking posts appear to acknowledge Azerbajiani suffering or Armenian war crimes, and agree that Armenian troops should stop shooting at Azerbaijani soldiers.

Figure 7. Alluvial diagram depicting the process of converting conditions for peace into prompts and obtaining results for which conditions were reciprocated and unreciprocated in Azerbaijani and Armenian-speaking posts. Original image here.
The catch is that GPT 3.5 again does not know which country to associate “Artsakh” and “Nagorno-Karabakh” with, nor can it tell the difference between posts that incite and acknowledge violence. According to GPT 3.5, posts in Azerbaijani “agree” that Nagorno-Karabakh should be independent, but only in the condition that they consider Nagorno-Karabakh to be integral to Azerbaijan’s sovereignty – not Armenia. Likewise, GPT 3.5 considers that an Azerbaijani-speaking post that claims that “an Armenian corpse should go from Karabakh to Armenia every day so that people there come to their senses” acknowledges “Armenian suffering”. This may be technically correct, but it does not express remorse or any attempt at reconciliation – on the contrary.
/imagine prompt: peace in my own terms
Given the lack of reciprocity between Azerbaijani and Armenian-speaking posts, we transformed the ten most engaged conditions for peace in Azerbaijani and Armenian into illustrations. We used Midjourney to generate images or posters for each of the prompts. The results showcase a wall of unreciprocated desires for justice, peace, communion or recognition of Armenian and Azerbaijani sovereignty.
Figures 8a and 8b. (8a) Midjourney representations of the top ten conditions for peace expressed by Armenian-speaking posts. Original image here. (8b) Figure 8b. Midjourney representations of the top ten conditions for peace expressed by Azerbaijani-speaking posts. Original image here.
Conclusions
LLMs as toolkits
Studies on the state of the conflict (or potential dialogue) online, be it in social media or in the wider Web, have until now relied on hate speech detection using word lists, media diet analysis that compares URLs posted by each group, and more broadly compares the topics and tonality of conversations in (and between) opposite groups from a variety of social media platforms. The problems these methods encounter are usual: sifting through hundreds of thousands of posts to look for specific themes, topics or types of rhetoric is a painstaking process that can only be done manually or to a limited extent; false positives emerge because, inevitably, expressions of disagreement are far too rich and varied to be captured by a list specific words; training models specialized in conflict-related content is costly and requires technical and domain expertise; existing Natural Language Processing techniques are not always optimized for so-called “minority” languages, be it because of a lack of resource or interest from NLP studies, or because such languages defy the grammatical structures on which most NLP techniques are constructed; and so on. For these reasons, it is easy to see why LLMs may come across as an attractive solution for online peacebuilding projects.
The case studies above have experimented with five methods that can be replicated in other conflict monitoring cases. These are:
1. Multiple-answer prompts for classification or categorisation of complex data in multiple languages. This method involves designing multiple-choice prompts for GPT 3.5 or Google FLAN to characterize the theme, topic, issue, rhetoric or other characteristic of a social media post. It can be used as a “data questionnaire” or survey, as it were, which translates a series of questions (informed, for example, from conflict research) into prompts. These prompts will inquire whether elements mentioned in the prompt are or are not present, or whether there are additional characteristics that the prompt may not have captured (in the form of a “other” category, for example). We have found, with the Christianity and Maharlika case studies, that multiple choice prompts with very specific examples work best with both GPT 3.5 and its free alternative, Google FLAN. We have also found that Google FLAN – which has failed to be as precise and instructive in non-English languages as GPT 3.5 – can perform in this task relatively well in the condition that multiple-choices are clear of ambiguous definitions and options. One good example are prompts designed by Build Up, which transform a range of characteristics from affective and norm polarization into a variety of prompts. Though they were originally designed for the Christianity case study, these prompts were used such as successfully on a translated set of Azerbaijani and Armenian-speaking posts about Nagorno Karabakh, using Google FLAN. Results can be seen here. Of course, the limitations of multi-choice prompts is that they are deductive. That is: they will tend to superimpose premade categories into debates, conversations and other social media data that do or cannot always fit them. Nevertheless, multiple-choice prompts can be informed by inductive prompts designed to extract arguments, ideas, beliefs, stances and other characteristics that can then be abbreviated into broader categories. For example: one may inquire about the main arguments made in favor of the Maharlika funds on Twitter, and find that they generally fit into two broader categories: statements against corruption, or statements in favor of economic development. These categories can then be used in multiple-choice prompts in a variety of ways. 2. Information extraction. Inductive analyses can engineer prompts to extract a variety of information from social media posts. That information may be arguments, ideas, beliefs, rhetoric, stances, facts, media and any other information relevant to one’s case study. As mentioned above, such information may then be used for multiple-choice prompts or other analyses. For the Nagorno Karabakh study, we extracted the conditions that Armenian and Azerbaijani-speaking posts expressed for peace to last in Nagorno Karabakh or their respective countries. Results were then transformed into multiple-choice prompts directed at both sides. Other examples are the extraction of “factual” material posited by social media users in defense of one or another argument, as a way to study political stances or beliefs. For example: one may want to know what evidence is posted by social media users who claim that certain Ukrainian lands belong to Russia. Results may point to links, quotes from political officials, scientific articles, books, Wikipedia articles, or even religious figures, which altogether weave a larger web of political beliefs useful for the study of online public opinion. This was done in the analysis of Wikipedia articles on the Khojaly massacre and Nagorno Karabakh in Armenian and Azerbaijani. We have found that Google FLAN performs poorly with this task, and may require, as of today, the more costly usage of GPT 3 and above as an alternative. 3. Argument extraction. As the Maharlika case study shows, one can use GPT 3.5 or other models to extract arguments about a given issue. We have seen how prompt engineering plays a significant role here, where the clearer the prompt — preferably with examples — the more accurately an LLM may extract arguments made by noisy social media posts. Given their noisy nature, it is important, in this sense, to define clearly what one means by arguments in social media debates. One way to do so is to give prompts a variety of examples, from the most constructive to the most abbreviated, based on a close reading of the most engaged posts from one’s dataset. 4. Stance detection. From this close reading, one could also inquire about the stances of each post or user. Stances may be pre-defined (as, for example, for, against or neutral to a given issue), or may be found in a selection of most engaged with post, and then transformed into multiple-choice prompts. To simplify this task, Prompt Compass (Borra, 2023) contains a few stance detection prompts from peer-reviewed papers. 5. A combination of all the tasks above. One example is the analysis done in the Nagorno Karabakh study, where we first perform information extraction (i.e., we extract the conditions of peace outlined by Facebook posts in Azerbaijani and Armenian), and then transform such information into prompts for their opposition. They may be, in this sense, “mediation prompts”, because they translate requirements, desires, beliefs as other constituents of an actor’s position into questions for their opposition. This technique can be used in other situations, or with other data. For example: we may extract popular concerns about the COVID-19 vaccine from Twitter and Facebook posts and check whether they are being answered in online government vaccination FAQs.What conflicts do to LLMs — and what LLMs do with conflicts
Rather than outlining a critique of LLMs, we outline below a few ways in which LLMs can be both used and studied as part of online peacebuilding practices. To do so, it is useful to recapitulate some reflections on the relations between LLMs and conflict, as it is expressed or perpetuated online. One oft-repeated point in public debate is that machine learning technologies trained on skewed data will inevitably reflect the biases of the data it has been trained on. The findings above, particularly of the Nagorno Karabakh study, show how data in Armenian and Azerbajiani are highly skewed in favor of their official (and local) sources, particularly with regards to controversial issues linked to decades of wars in the Caucasus. From the perspective of a peacebuilder, this means that whatever tasks LLMs are going to be used for will inevitably perpetuate the very conflicts they seek to study or observe.
We have seen that when trying to detect what issues or topics Azerbaijani and Armenian-speaking posts have been debating on Facebook from July 2020 until 2023. GPT 3.5 and Google FLAN were confused with the terminology of prompts inquiring about mentions of Nagorno Karabakh as belonging to Azerbaijani and Armenian culture and history, because Nagorno Karabakh may be considered part of one or the other country. We also saw biases in autocompletions in Armenian, Azerbaijani and English. In Armenian, autocompletions were largely skewed in favor of Armenian official sources. In Azerbaijani and English, sources were somewhat more balanced — but still perpetuated biases in the form of limited or partial perspective on Nagorno Karabakh as an arguably complex historical issue. Partial takes on the conflict are reflected by the sources on which LLMs have been trained — namely, Wikipedia and other prominent results from Google Search, likely repeated by WebText 2’s Reddit posts.
What we also found is that LLMs may be in conflict with one another. Given different training parameters, Google FLAN and OpenAI ’s GPT 3.5 and davinci-003 disagreed on who were the first inhabitants of Nagorno Karabakh, which country Nagorno Karabakh belongs to, who were the main culprits of the Khojaly massacre or how many casualties there were in the Armenian genocide. Naturally, LLMs are not expected to be consistent, unless when probed about highly controversial topics that call for a unilateral normative position, or sometimes a more diplomatic take. The former can be seen in responses to prompts about slavery, race, the Holocaust, and the latter was occasionally found in some autocompletions about Nagorno Karabakh. These responses may be frequently seen in LLMs probed about key historical issues from European and American history, but not so much, as we have seen, from regions of the world under-represented in LLM training datasets.
Some of the underlying reasons why LLM prompt results perpetuate the conflicts they are asked to probe, or why LLMs may be in conflict with one another, are fundamentally epistemological. The data that LLMs are trained on perpetuate and unresolved disagreements by multiple conflicting voices. Conflicts will always present epistemological challenges to machine learning because they reside at the crossroads of two or more opposite or antagonistic systems of values, thinking and other relevant knowledge criteria. An LLM will not know how to balance such voices, nor estimate their normative coherence, without active interventions on the level of their training data or in the fine-tuning of their models.
LLMs as an object of study
In this sense, LLMs are a worthy object of study for any attempt at conflict monitoring — at least for two reasons. Though they may be recent, LLMs have become sources of knowledge and reference for many users (not exclusive to students needing a hand to write their essays). They have or will become integrated with other sources of knowledge, as they are in Google search and other products (Reid, 2023). But they are also great reflections of what voices and political cultures tend to dominate the Internet and other sources of knowledge (books from the datasets Books2 and Books3, for example) as training datasets. Thus, to look at LLMs in conflict analysis is to scrutinize the level of balance, pluralism and mediation that exist between all the voices present within training datasets, be they predominant or minor. Two ways in which we studied LLMs was by looking at some of their open-source datasets, which one can sift through in WebText2, CommonCrawl and Wikipedia. Another is by studying autocompletions as perpetuations of standardized knowledge, i.e., common sense, stereotypes, or even moderated (“politically correct”) statements.
Training LLM models for peacebuilding purposes
Finally, what can one do to level the inequality of voices present in LLM training datasets? If peacebuilding missions are often centered in conflict zones around the globe, the same could be said about online peacebuilding. Below, we outline a few suggestions of how “online conflict zones” may benefit from certain forms of mediation related to large language model training.1. Foster consensus in LLM training datasets, such as Wikipedia. Wikipedia is an important ground of conflict on the web; in conflict spaces such as those of the Armenian and Azerbaijani-speaking Web, and more obviously Arabic and Hebrew-speaking equivalents, it may used as a source of facts to defend or reflect partisan or partial historical viewpoints. It is often futile to tackle articles about controversial historical events, beliefs and other tropes through the prism of misinformation, because factual errors and other types of “information disorders” are first and foremost the product (or amplifiers) of highly conflicted viewpoints. Articles may be edited to bridge or reflect conflicting viewpoints on a given topic, in a bid to achieve consensus between them. Should one take the case of Armenian-speaking articles on historical events having affected Azerbaijani populations, they may consider complementing (but not countering) them with evidence, testimonies and the larger historical context of official Azerbaijani sources – and vice-versa.
2. Complement training datasets of minority languages with data from other (translated) languages. As most of the Internet is in English (Streger, 2023), training datasets for minority languages are much smaller and may tend to suffer from a lack of political balance and diversity. One solution may be to train models to respond to prompts about contested topics with datasets in (translated) languages or sources involved in that controversy. For example: if a prompt asks whether Nagorno Karabakh is Armenian or Azerbaijani, it could output translated responses from datasets in Armenian, Azerbaijani, Russian and Turkish. In this sense, one would invite voices linked to a controversy to altogether respond to a prompt, which may present such responses in a pluralistic fashion. This would amount to a sort of “mediation” training dataset, in the sense that it contains voices engaged in solving or debating a common controversy, and may, in this sense, help prevent the marginalization of voices that are excluded by dominant languages, narratives and histories by default.
Case study II. Attitude and norm polarization in US Christian leadership on Twitter
Team members
Benjamin Cerigo (developer at datavaluepeople) Penelope Bollini (MA student at University of Amsterdam) Roeland Dubèl (MA student at the University of Amsterdam) Diana Moret i Soler (PhD at Universitat Jaume I) Beatrice Gobbo (assistant professor at the Polytechnic University of Milan and researcher at Density Design Lab)Introduction
This case study focuses on polarizing language in the US Christian diaspora, specifically Christian leadership (ecclesiastical, online influencers, or other). There have been instances in which this leadership has sought to conciliate highly partisan debates about “hot button” issues (reproductive rights, identity and wealth distribution) through the language of Christian communion, though the same can be said about the frequent use of hyper partisan rhetoric in defense of Christian identity. This phenomenon could be studied as a form of attitude and norm polarisation. In attitude polarisation, disagreement becomes more extreme as an effect of confirmation bias (i.e., the tendency to reinforce current beliefs or attitudes while encountering new evidence about a given controversy). In norm polarisation, defined here by Kaufmann (1998) as “normative conflicts”, “there is a question not only of conflicting interests but also of conflicting ‘principles’ that permit no compromise” as they are rooted in “different values and, arising from this, different evaluations of the situation, which prevent the rivals from recognising one another’s point of view.” (Kaufmann, 1998, p. 85)
The goal of this case study was to explore attitude polarization in left and right Christian leadership on Twitter, looking in particular for exceptions, such as conciliatory language of counter-speech. By “right” and “left”, we refer to Christian Twitter influencers or leaders that were either affiliated to the Democratic or Republican party, or expressed sympathies for Democratic or Republican policy or ideology. In this setting, LLMs are used to process large amounts of textual data (being Tweets from Christian leadership) for evidence of polarizing rhetoric, defined in a list of prompts written by attitude polarization experts. Each prompt – as we will see later – inquires about specific ways in which attitude and norm polarization is done. For attitude polarization, prompts inquire about perceptual shifts towards stereotype, vilification, dehumanization, or deindividuation of others (in general or towards Christians); while for norm polarization, they inquire about combative norms of interaction that displaces empathy or curiosity and reifies the erosion of trust between people – besides incitement to hatred, harm or violence towards others. Having obtained a number of results, this case then focused on comparing the effectiveness of these prompts in Google FLAN and GPT 3.5.
Dataset
We used a dataset of 8,000 tweets from ~20 Twitter accounts between 2023-04-01 to 2023-07-01. These Twitter accounts regularly express Christian identity across two spectrums – polarizing vs. pluralizing, democrats vs. republicans – and were selected by a peacebuilder from the Build Up NGO with expertise in this conflict.
From these 8,000 tweets, we selected 93 Tweets of interest. We did this by:
-
Randomly ordering the list;
-
Dividing the list into 4 in relation to the type of account (across spectrums).
Annotated dataset
To be able to gauge the accuracy of a classification, we annotated the 93 hand-selected Tweets with four different people by classes related to Christianity and polarization outlined in the prompts below. This data was then used as the annotated or validation dataset.
Defining classes
To define classes, an initial definition of Christianity and polarization was developed by an expert in polarization that is a part of Build Up NGO. We simplified and adapted such definitions by:
-
Applying granular classes for each sub-definition, e.g. Christian figures are equivalents of mentions of figures like Jesus;
-
Simplifying norm and attitude polarization into one class.
Models Testing
For each Tweet in the annotated dataset, we computed completion results for 2 models (i.e., the results given by those models) and ~6 prompt variations. The two LLM models were Google FLAN (open source and free) and GPT 3.5 (closed source and paid). We chose to compare these two LLMs because it is useful for understanding the extent to which LLMs are up for this specific task, as well as which of the two would perform better. In alignment with open science principles, we also wanted to verify whether an open source and free LLM could be replicated for this kind of research. We assume from Ziems et al. (2023) that Google FLAN is almost as good as GPT 3 for detecting “ideology” in textual data. GPT 4 might perform better than FLAN and GPT 3.5, but we opted to use version 3.5 due to costs.
Prompt engineering
We developed 4 variations of prompts:
-
Prompts in the form of a short and general question:
-
Link 1.3 Short [label = Christ_sort]: Christianity - LLMs classification validation - Report
-
Link to 2.3 Short [label = Polar_sort]: Christianity - LLMs classification validation - Report
-
Prompts containing a detailed definition of Christianity without examples, in two versions:
-
Link to 1.1 Without example [label = christ_no_examples]: Christianity - LLMs classification validation - Report
-
Link to 1.2 Without example V2 [label = christ_no_examples_v2]: Christianity - LLMs classification validation - Report
-
Link to 2.1 Without example [label = polar_no_examples]: Christianity - LLMs classification validation - Report
-
Link to 2.2 Without example V2 [label = polar_no_examples_v2]: Christianity - LLMs classification validation - Report
-
Prompts containing a detailed definition of Christianity, with examples:
-
Link to 1.1 With example [label = christ_with_examples]: Christianity - LLMs classification validation - Report
-
link to 2.1 With example [label = polar_with_examples]: Christianity - LLMs classification validation - Report
-
Prompts with a detailed definition of Christianity that asks for reasoning with and without JSON script:
-
Link to 1.1 With reasoning [label = chirst_with_reasoning]: Christianity - LLMs classification validation - Report
-
Link to 1.2 With reasoning and JSON [label = christ_with_reasoning_JSON]: Christianity - LLMs classification validation - Report
-
Link to 2.1 With reasoning [label = polar_with_reasoning]: Christianity - LLMs classification validation - Report
-
Link to 2.2 With reasoning and JSON [label = polar_with_reasoning_JSON]: Christianity - LLMs classification validation - Report
The prompts were developed in an ad hoc iterative method in which we tested different prompts, looked at the output, how the output was processed, and what its F1 score was. We would then apply small and large changes to prompts.
We started from Build Up’s original classifications and gave LLMs a persona knowledgeable about the context.
Then, we decided to shorten each category and condense them into statements. We noticed that Tweets also included emojis and places (e.g. a Church or cathedral) and included them as categories, such as:
# (c-emojis) The text includes ✝, ⛪ , ☦ or 🙏.
Emojis did not work well: FLAN classifies any emoji as religious and tagged Tweets that did not include emojis in this specific category. Thus, we decided to discard this category.
Places were used as categories in the following formula:
# (c-places) The text mentions Christian places such as Churches and Cathedrals.
This category seemed to perform decently on FLAN. However, it misses nuances, as Church and Cathedral can be mentioned in a non-Christian context.
Then, we wrote the instruction for returning the categorization. We tested three different formulations:
# Please, answer with either c-doubtful or c-none, or answer with c-identities, c-person, c-texts, c-rituals, c-figures, c-holidays, c-places, or a combination of them. V3
# Please, answer with c-identities, c-person, c-texts, c-rituals, c-figures, c-holidays, c-places, or a combination of them, else answer with either c-doubtful or c-none. V4
# Please, answer with c-identities, c-person, c-texts, c-rituals, c-figures, c-holidays, c-places, c-doubtful, c-none or a combination of them as a comma-separated list. V5
We noticed that FLAN did not return more than one output in any case, while ChatGPT did. We decided to keep the last one (V5).
Model capabilities for processing completions
During the development of the prompts we noticed a number of capabilities of the each model:
Flan-large
Flan was not able to return more than one classification id and was not able to add a reason for why they had chosen the classification id.
ChatGPT3.5
ChatGPT was able to return a list of classification ids. It was also able to return the reason for choosing the classification and the classification ids in one completion result. We had the best results in processing these completions that included reasons when we ask for the result to be formatted in JSON. See (link) for how this was prompted. Pre-processing of the model outputs
While we asked the two LLMs to classify the dataset based on very specific prompts, we present here the results of a binary classification of if a tweet was classified as positive about christianity or containing polarization. This was done so that we could compare prompts that give multi label results and single label results.
Accuracy test
For testing each model’s accuracy, we used an F1 score, which compares manual annotations with the output of each model prompt combination (see Table 1 below). As described in sklean, the F1 score works as follows:
Intuitively, precision is the ability of the classifier not to label as positive a sample that is negative, and recall is the ability of the classifier to find all the positive samples.
The F-measure (Fbeta and F1 measures) can be interpreted as a weighted harmonic mean of the precision and recall. A Fbeta measure reaches its best value at 1 and its worst score at 0. With beta = 1, Fbeta and F1 are equivalent, and the recall and the precision are equally important.
After obtaining outputs, an F1 score analysis was executed comparing manual annotation to the output of each model prompt combination (Table 1 below).
| model type | prompt_name | Christianity f1_score | Polarization f1_score |
| google/FLAN-t5-large | no_examples | 0.60952 | 0.6383 |
| google/FLAN-t5-large | with_reasoning | 0.66667 | 0.64583 |
| google/FLAN-t5-large | with_examples | 0.70492 | 0.65823 |
| google/FLAN-t5-large | short | 0.94118 | 0.60215 |
| gpt-3.5-turbo | no_examples | 0.87234 | 0.68293 |
| gpt-3.5-turbo | with_reasoning | 0.68293 | 0.58065 |
| gpt-3.5-turbo | with_examples | 0.8932 | 0.73418 |
| gpt-3.5-turbo | short | 0.68354 | 0.71795 |
| model type | prompt_name | Christianity f1_score | Polarization f1_score |
| google/FLAN-t5-large | no_examples_v3 | 0.72727 | 0.61682 |
| google/FLAN-t5-large | short_second_run | 0.90909 | na |
| gpt-3.5-turbo | with_reasoning_JSON | 0.86957 | 0.57627 |
Table 1: Christianity- LLMs classification validation - Results
Costs
The cost of running each model should also be considered as peacebuilders generally have small budgets of tens to (low) hundreds of dollars for supporting technical tools.
gpt-3.5-turbo
At the time of writing, GPT is priced by OpenAI for each 1K tokens that are processed. For a single run of one of the larger queries OpenAI processed around 72136 tokens, (63,066 input, 9,070 output). This was at a cost of $0.003 / 1K tokens for input and $0.004 / 1K tokens for output. Resulting in a cost of around (0.192 + 0.04) $0.232. It is then estimated that it would then be around $20 for the processing of the full data set.
google/FLAN-t5-large
Google FLAN was run on a server of 24GB GPU (NVIDIA GeForce RTX 4090) but had no cost attached to each specific run. There was no cost of running the server during the experiment. To get an estimate of the cost, a comparable server from AWS g4ad.2xlarge at $0.67662 p/h for the around 2 days that we ran the experiment would cost: $32.47. This cost would cover any amount of data that we ran through the model.
Results
- Regarding the accuracy of the model in comparison to the human validation set, Google Flan is 81% accurate in predicting Christianity but 66,2% accurate in predicting Polarisation. Chat GPT is 86,6% accurate in predicting Christianity and 84,9% in predicting Polarisation.
- Short prompts were 90% accurate in predicting Christianity in Google FLAN, but only 60% accurate in predicting polarisation in Google Flan.
- There are differences between both models: ChatGPT works better than Google Flan with complex concepts such as “polarisation”, but not significantly so.
- The most used categories within the Christianity class were Google FLAN: c-text; Chat GPT: c-none. And within the Polarisation: in both models: ‘none’ category.
- Differences between prompts: there are no substantial differences between the results for the prompt with and without examples (zero-shot vs multi-shot prompting), in both models.
- For small amounts of data Chat GPT 3.5, is a low cost solution. Using Google FLAN would be a low cost solution for large amounts of data.
Findings
Firstly, it could be that zero-shot classification using LLMs can classify tweets about Christianity well. Also, it could be that zero-shot classification using LLMs has more problems with complex ideas like polarization and GPT performs better than FLAN but not remarkably better for Christianity. Moreover, prompt design matters and it is hard to predict the effect. Our last finding is that if you don’t ask for specific classes as an output it is almost impossible to process the output correctly and asking for results in JSON format seems to be one usable option.
Limitations and pitfalls
Due to the small annotated dataset the results most likely contain biases that mean it would be unwise to generalise the accuracy of these specific classification across other classifications or the full dataset.
Furthermore the code that processed the completions and analysis was not unit tested and could contain mistakes that could affect the accuracy score.
Also known is that ChatGPT4 is generally considered to perform better but due to access it was not possible to use the API for this model.
Conclusions
Peacebuilders and analysts that do conflict analysis are increasingly interested in looking at social media platforms as sites in which conflicts are articulated and enacted. However, social media offers data of a magnitude that is difficult to handle manually. Computational methods have been employed to face this challenge of scale, and while traditional machine learning techniques seem to be performing well in certain cases, their usefulness when it comes to conflict analyses is limited because the nuances of discourses get lost. LLMs are arguably better at granular tasks, namely when it comes to differentiating between a “constructive” post (which would contribute to the quality of online debate) and a hate speech post (which would contribute to the opposite effect).
In this project, we do not confront machine learning techniques to LLMs but we test LLMs versus a manually annotated dataset, a step that is necessary as research on how LLMs performs at classification tasks is only in its infancy – although first results are promising (See e.g. Gilardi et al., 2023; Møller et al., 2023; Reiss, 2023; Törnberg, 2023; Ziems et al., 2023). Conflict analysis of social media discourse could use zero-short classifications to get a subset of relevant data. This smaller set could then be analyzed for further computational or qualitative methods. Since it is hard to predict which prompts work better than others, it is recommended to design the prompt with a small, representative, annotated dataset.
Case study III: The Filipino Maharlika funds controversy on Facebook and Twitter
Team members
Fatima Gaw (PhD at Northwester University) Kris Ruijgrok (postdoctoral researcher at the University of Amsterdam) Janjira Sombatpoonsiri (assistant professor at the German Institute for Global and Area Studies) Laura Caroleo (PhD at Universita' degli Studi "Magna Græcia" di Catanzaro) Beatrice Gobbo (assistant professor at the Polytechnic University of Milan and researcher at Density Design Lab)Introduction
In the Philippines, the Maharlika funds controversy refers to the passing of a bill that would have established a sovereign wealth fund to revitalize economic growth and allocate infrastructure funds outside of bureaucratic and legal frameworks. Those opposing the bill have argued that the fund is just another means for corruption and is susceptible to abuse and mismanagement (Rivas, 2023), and those supporting it argue that it would adhere to the Santiago Principles and other internationally- accepted standards of transparency and accountability, beside bringing in substantial wealth to the country (Heinrich Böll Foundation, 2023).
This case study was used as a more traditional form of controversy mapping on Twitter. There are two or more clear sides to the conflict with relative levels of commitment, different sets of arguments, as well as users engaged in “disinforming” the debate through trolling, bad or exceedingly noisy argumentation, or spreading false or partial information to the debate. Here, LLMs are used to detect positionality and different kinds of argumentation to a cause. As we will see, prompts are designed to detect the stances of users engaged in the debate (pro, against, neutral or other), and eventually the kinds of arguments used by each stance – including noisy ones.
Method
We analyzed a subset of 16,000 tweets talking about the Maharlika fund, from May 29 to 31, which covers two days before the passage of the bill and the day it was passed. Our initial approach was to identify actors and arguments from the data using Google FLAN, but this approach was abandoned because there was little point in identifying actors without their respective arguments, and because arguments extracted by LLM models were generally inaccurate or made-up (See Prompts A.1 and A.2 in the table below).
One of the foremost steps to using LLMs for conflict analysis is prompt engineering. Methods differed slightly from case study to case study, but can be summarized as a succession of prompts designed to inquire about different aspects of a given post, namely their stance and their argument. Thus, different case studies developed different prompts. We outline these steps in two “rounds”.
Stance classification
Tweets were categorized based on their position towards the Maharlika funds. Stances are: (a) supportive of the bill; (b) opposing the bill; (c) neutral to the bill; or (4) other (See Prompt B.1 in the table below).
Prompts had multiple choices or persona-instruction-format (i.e., the LLM is given a “persona” such as a researcher or other, an instruction, and a desired format for output). LLMs were instructed to categorize news media as having a neutral, which might warrant further revision.
Argument classification
We categorize Tweets based on arguments expressed for or against specific issues related to the Maharlika funds, such as (1) investment, (2) corruption, (3) implementation, (4) open to experimentation, (5) others (See Prompt B.2).
Prompts had a persona-instruction-format and multiple choices, as well as an option to identify arguments that did not fall into predefined categories. Prompts were run on Google FLAN and GPT 3.5 based on a sample of 50 tweets. We also created a version of the dataset with manually labeled categories to validate the output of the model.
In a second round, we instructed LLMs to extract arguments in order to derive more granular data without a priori assumptions from researchers. This more open-ended extraction process then informed new prompts for argument classification.
This was done by creating a subset of data from Tweets labeled as “support” or supportive of the Maharlika fund by Google FLAN (n= 845). We ran an argument extraction prompt in GPT 3.5 (given its better performance in sample tests) to identify emergent arguments in support of the Maharlika fund with a sample of the data (n= 80) (See Prompt C.1).
When done, we used a simple word frequency tool (i.e., Voyant Tools) to identify the top words for each argument, and then proceeded to manually classify each argument. We then developed an argument classification prompt that asks GPT 3.5 to categorize a Tweet based on its reason for supporting the Maharlika fund, namely: (A) to curb corruption; (B) to attract investment; (C) to promote good governance; (D) to create jobs; (E) to support infrastructure; or (G) unsure. This time, the prompt asks GPT 3.5 to identify multiple arguments from each tweet, if applicable (See Prompt C.2).
Choosing what LLM to use
Different LLM models are predisposed to perform better at different things. By testing GPT 3.5 and FLAN, and from secondary literature, we know that FLAN is better at processing clear multi-choice prompts in English for English-speaking data (such as, “does this post mention topic a, b or c”), while GPT 3.5 and above are malleable enough to process prompts in different languages with different situations, but are far more costly.
Results from round 1
Prompt design for stance detection
-
The first set of prompting of just persona-instruction-format labeled the sample tweets inaccurately around 20% of the time using Google Flan
-
In the round of prompting, we added to the prompt some words that may be mentioned related to the category (up to 5 words), and the inaccurate labels were only 8-10% of the sample data for both models using the sample tweets
-
We find that adding more cues to the prompt increases its capacity to label the tweets correctly
-
Comparing the two models, Google FLAN (8% errors) performed slightly better than GPT 3.5 (10% errors) using the sample tweets (n = 50) based on the manually labeled categories by someone by local and issue knowledge.
Prompt design for argument detection
-
Learning from the stance prompting, we also added in the prompt some words related to the category (up to 5 words) and ran the prompt with the same set of sample tweets (n=50)
-
The two models performed significantly different from each other: GPT 3.5 (8% errors) and Google FLAN (34% error)
-
This might indicate that ChatGPT is far more adept at more conceptual categorization tasks than Google FLAN. The similar results in the stance prompt labels may be because the task is more simple and straightforward, taking into account sentiment and not concepts. Google Flan is trained on sentiment detection
Results from the full dataset
Because Google FLAN performed slightly better than ChatGPT for stance identification, we use that model for the full dataset. Below is the breakdown of the results (n=16225):
-
Support: 845
-
Opposition: 10,082
-
Neutral: 5036
-
Others: 262
We first find that there are a lot of tweets in the sample of model-labeled support tweets (n=116) that are not accurately tagged
-
Correct: 13
-
Incorrect: 24
-
Media reports: 67 (which should be tagged as neutral, if the prompt is followed)
-
Others: 12 (unclear)
Even if the prompt called for categorizing “news” tweets as neutral, there are still news tweets categorized as positive. We suspect that it may be because these tweets include supportive terms earlier in the text (first couple of words in the sentence) before it is able to detect that it is from a news account or article.
Qualitatively, we find that there is not a lot of variety in the arguments expressing support towards the Maharlika fund. Generally, supportive posts argue that the fund would instigate economic development.
We also wanted to check the same characteristics in the tweets tagged as “others” and “neutral” by Google FLAN:
-
Others: Generally accurate; a lot of tagged posts were deleted;
-
Neutral: We sampled 5,036 tweets for manual validation (n =115). In general, Google FLAN correctly identified neutral posts, but of those it labeled mistakenly, there are conceptual and technical limitations that restricted the model from labeling it properly. These limitations were:
-
The exported data only captures text from the quoted tweets and not that of the original tweet (i.e., a news article or any other attachment);
-
The exported data failed to capture emojis (these were replaced with question marks), so the model labeled these as “neutral”;
-
Passive aggressive remarks, which usually include lots of question marks (i.e., “thank you so much???”), were tagged as “neutral”;
-
Results from round 2
Argument extraction prompt results were applied to all 845 supporting tweets tagged by Google FLAN. We ran the argument extraction prompt on that sample using GPT 3.5. The model derived multiple arguments per tweet. These arguments were subjected to a basic word frequency analysis to determine the top argument, which informed our revised argument classification prompt.
Argument classification prompt results were applied to supportive tweets only. We sampled tweets (n= 50) from the total of 845 supporting tweets tagged by Google FLAN. We then ran the updated argument classification prompt derived from the argument extraction exercise on that sample using GPT 3.5. The following results were generated to compare the GPT 3.5 labeled arguments and the manually label categories: correct (32) or incorrect (18).
Cases of incorrect labels involve:
-
Wrong inference: Inference from the text is incorrect
-
Overinterpretation: Some labels that were tagged with multiple labels had some additional label that the researchers think is already beyond what the text implies
We observed the following about GPT 3.5:
-
Tweets with longer text are more accurately labeled than the other tweets;
-
The model made logical inferences about the argument of a tweet for tweets with minimal texts (i.e., mentions of millions means economic development).
See Google Doc for Table 1. Task and prompt summary for the Maharlika fund LLM analysis
Methodological findings
-
When running the stance classification prompt, Google FLAN (8% errors) performed slightly better than GPT 3.5 (10% errors) using the sample tweets (n = 50) based on the manually labeled categories by someone by local and issue knowledge.
-
When running the argument classification prompt, the two models performed significantly different from each other: GPT 3.5 (8% errors) and Google FLAN (34% error), indicating that GPT 3.5 is far more adept at more conceptual categorization tasks than Google FLAN.
-
On making decisions about classification, we observed three things: (1) Order of words in a text might matter in the labeling, (2) Tweets with longer text are more accurately labeled than the other tweets, (3) With limited textual cues, GPT 3.5 tend to overinterpret the texts
-
In general, better performing prompt design involve more direct and simple-worded instructions that avoid conceptual load on the model
-
Google FLAN was successfully able to identify the actors in the text, both the actors with proper names (i.e., politician’s name, agency’s name) and common names (i.e., farmer, government). However, it had issues with identifying arguments. Its results can generally be described as: (1) verbatim copy paste of an argument made in a Tweet; (2) a result mildly related to the original Tweet but too long and incoherent; and (4) unrelated or made-up argument that is not in the text (i.e. hallucinations).
Controversy mapping findings
-
Stance-wise: Opposition to the bill is a dominant trend (62.13%), while support is only 37% of the Twitter data. Despite this, the state agenda still prevailed. This directed us to investigate the select tweets advancing Maharlika fund.
-
Arguments-wise: Among pro-Maharlika tweets, the majority of the tweets were labeled as “none of the above” (523/845 or 61.89%), while those tweets that were labeled as investment (270/845), allowing for multiple labels per tweet. Those labeled outside of the listed arguments are mostly news reports and tweets that identify factual information about the Maharlika fund.
Conclusions
While the two models performed at par when classifying positions towards an issue, GPT 3.5 performed better at extracting arguments or providing conceptual summary from small texts such as tweets. For a controversy analysis, we conclude that either the timeframe or the platform was not the target of state propaganda and exploring other timeframes or platforms might reveal more meaningful insights.
References
Borra, E. (2023). PromptCompass. Zenodo. https://doi.org/10.5281/zenodo.8359916
Radford, A. et al. (2019) ‘Language Models are Unsupervised Multitask Learners’.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
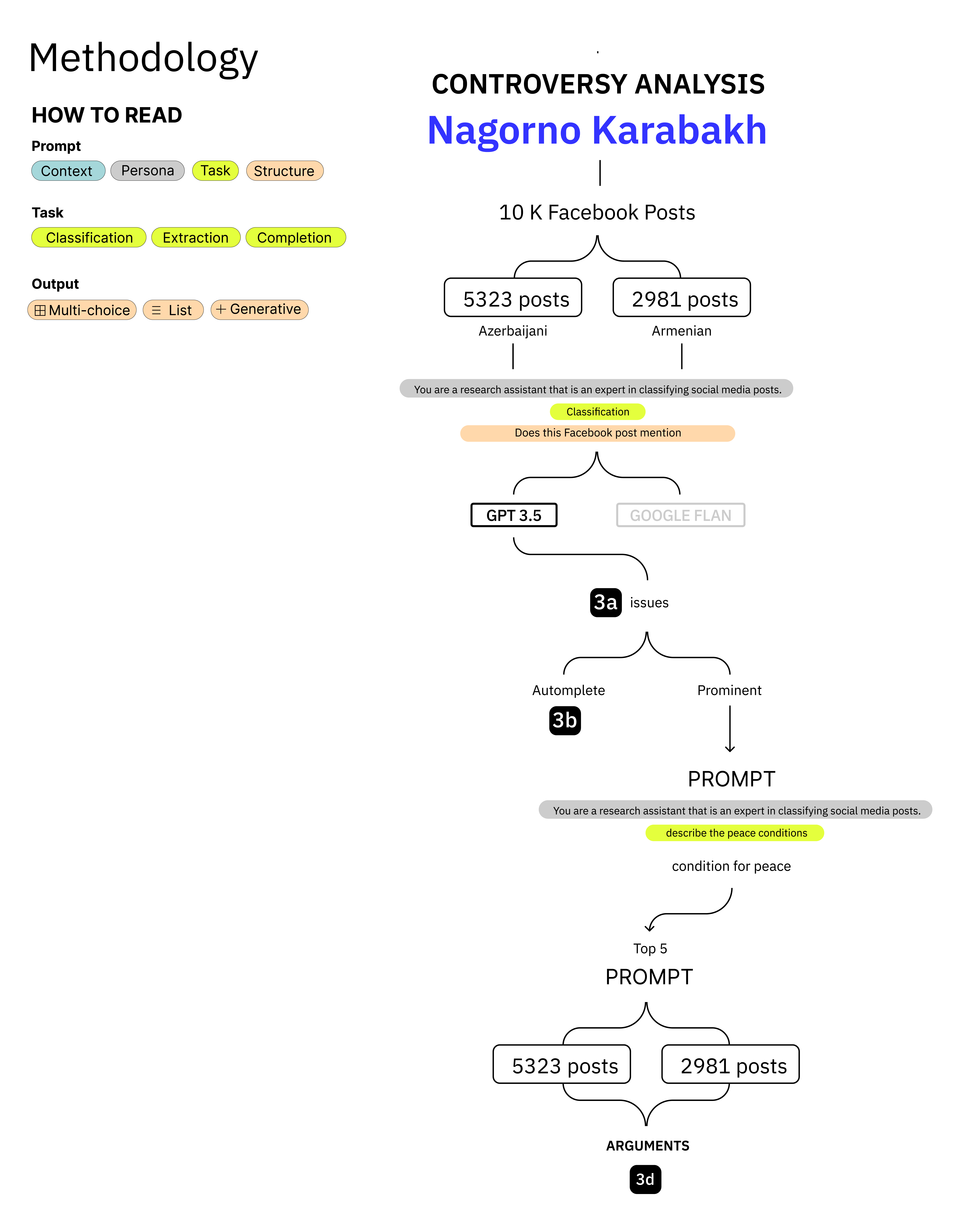{kind=link}
{kind=link}
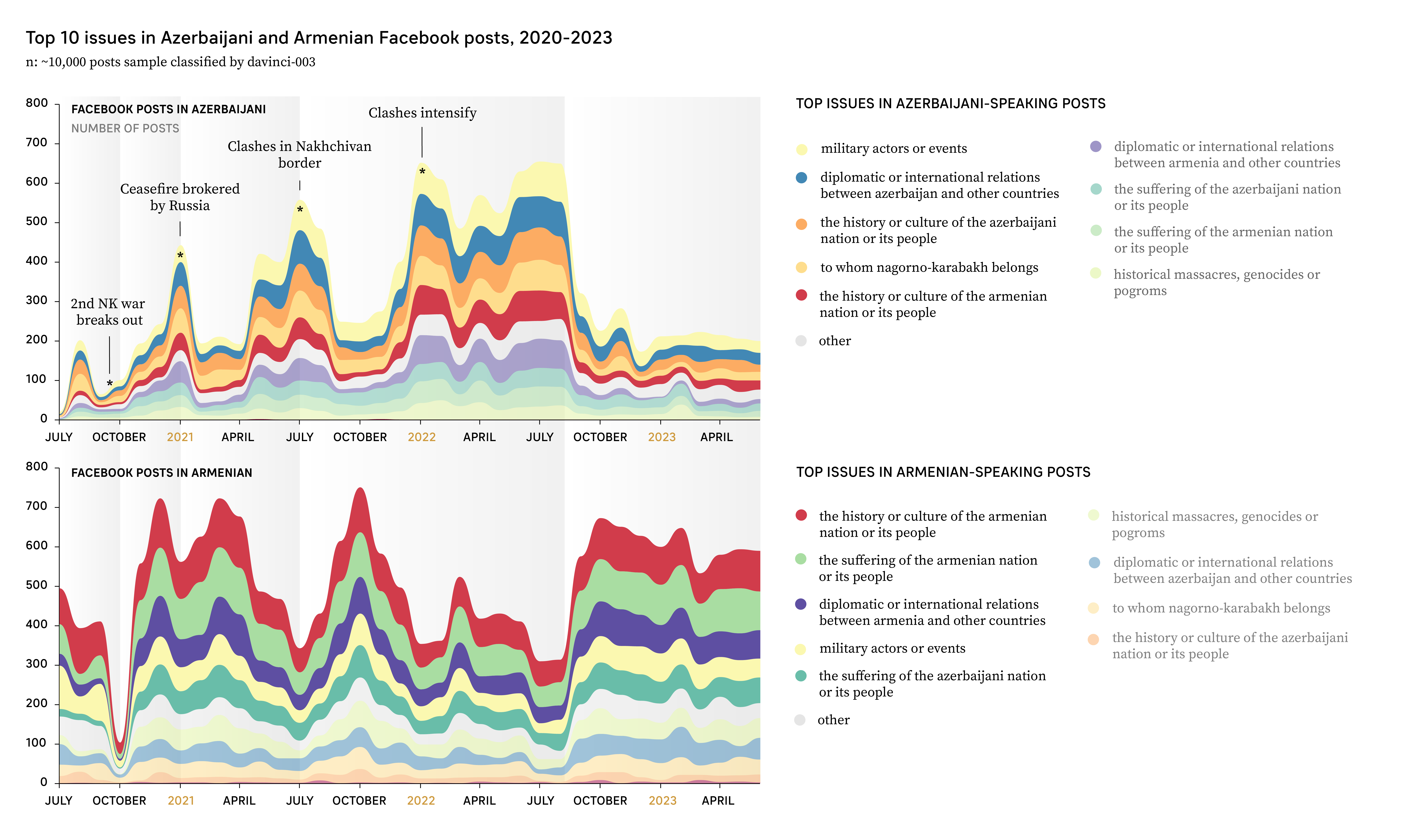{kind=link}
{kind=link}
{kind=link}
{kind=link}
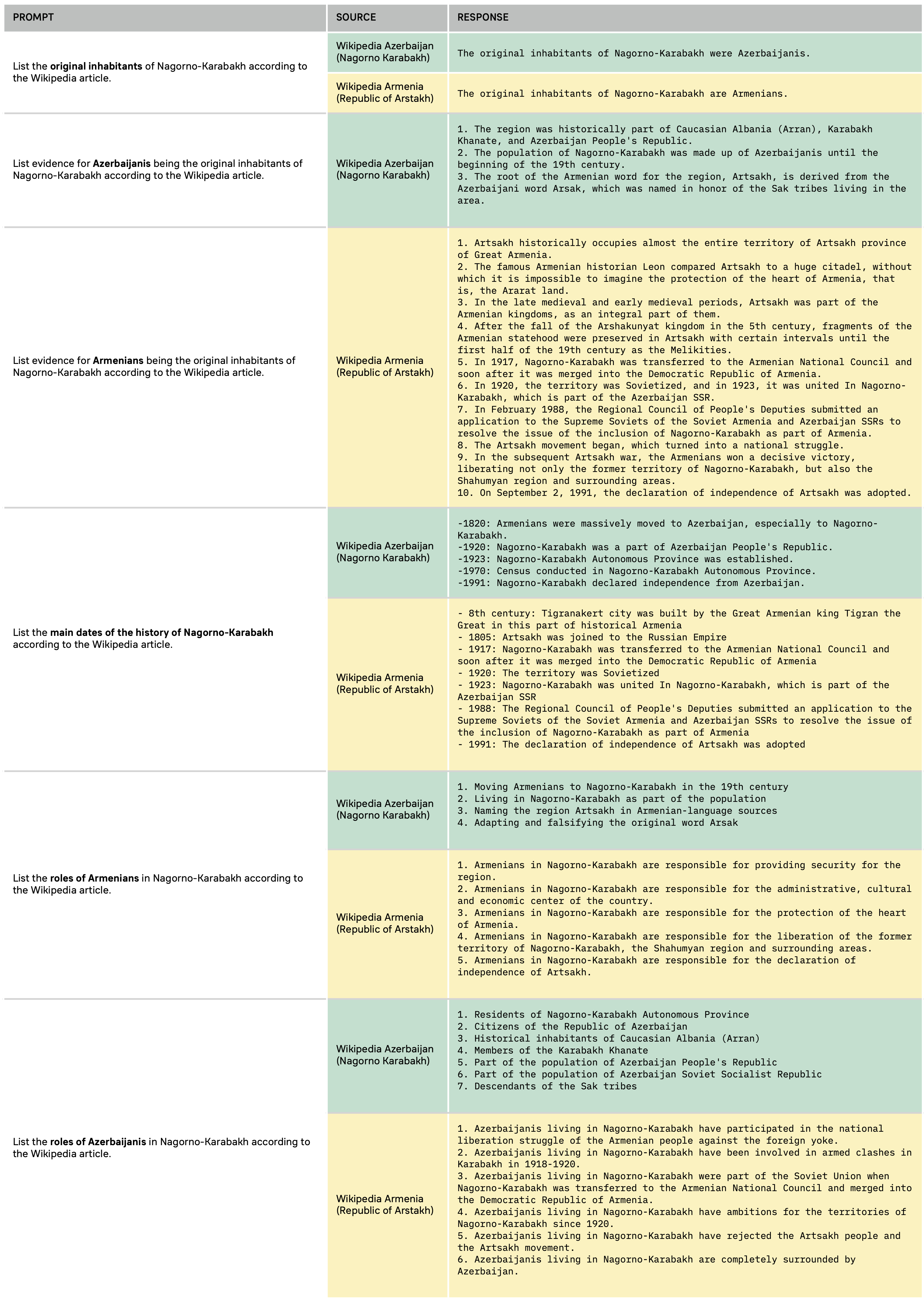{kind=link}
{kind=link}
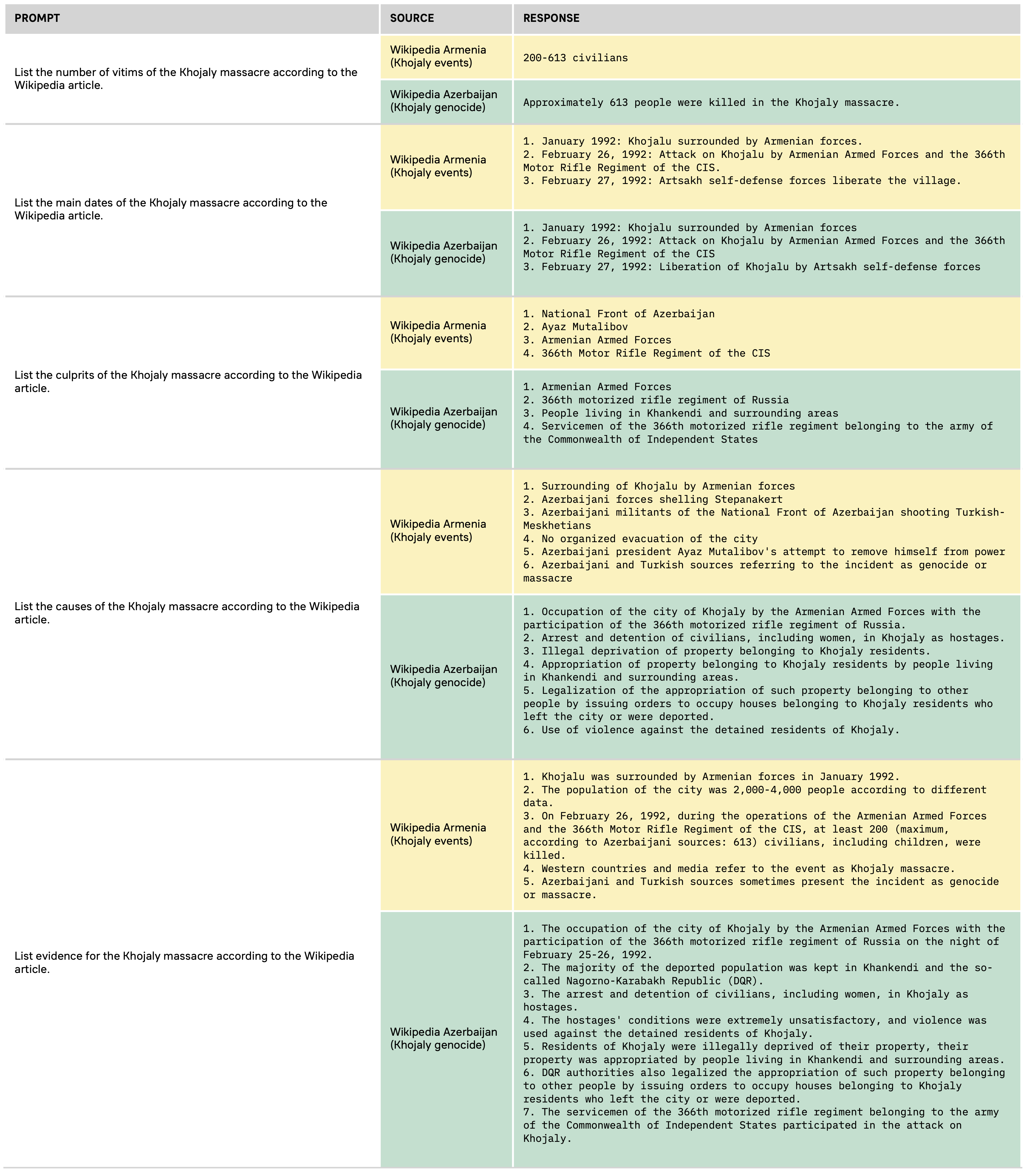{kind=link}
{kind=link}
{kind=link}
{kind=link}
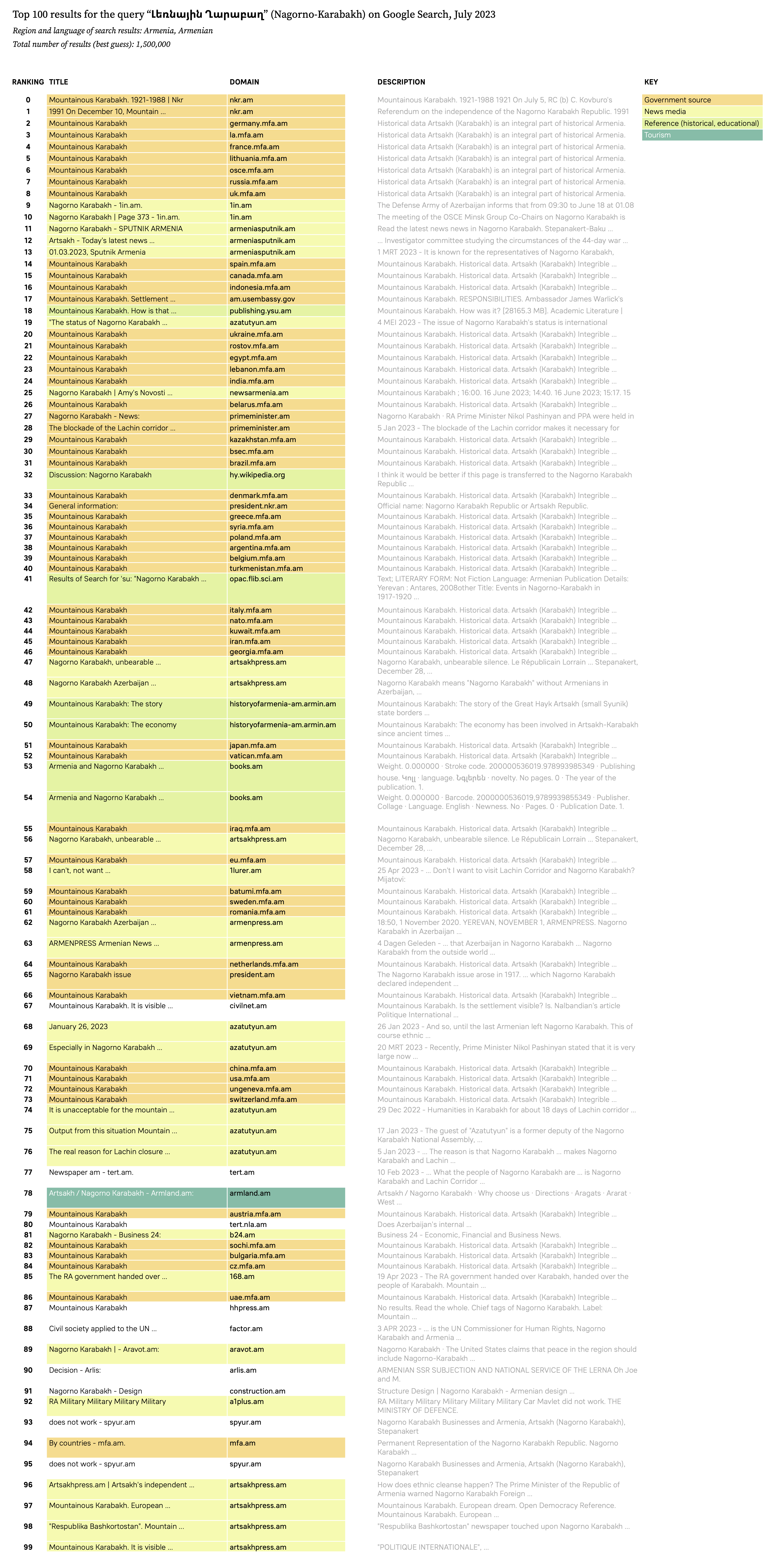{kind=link}
{kind=link}
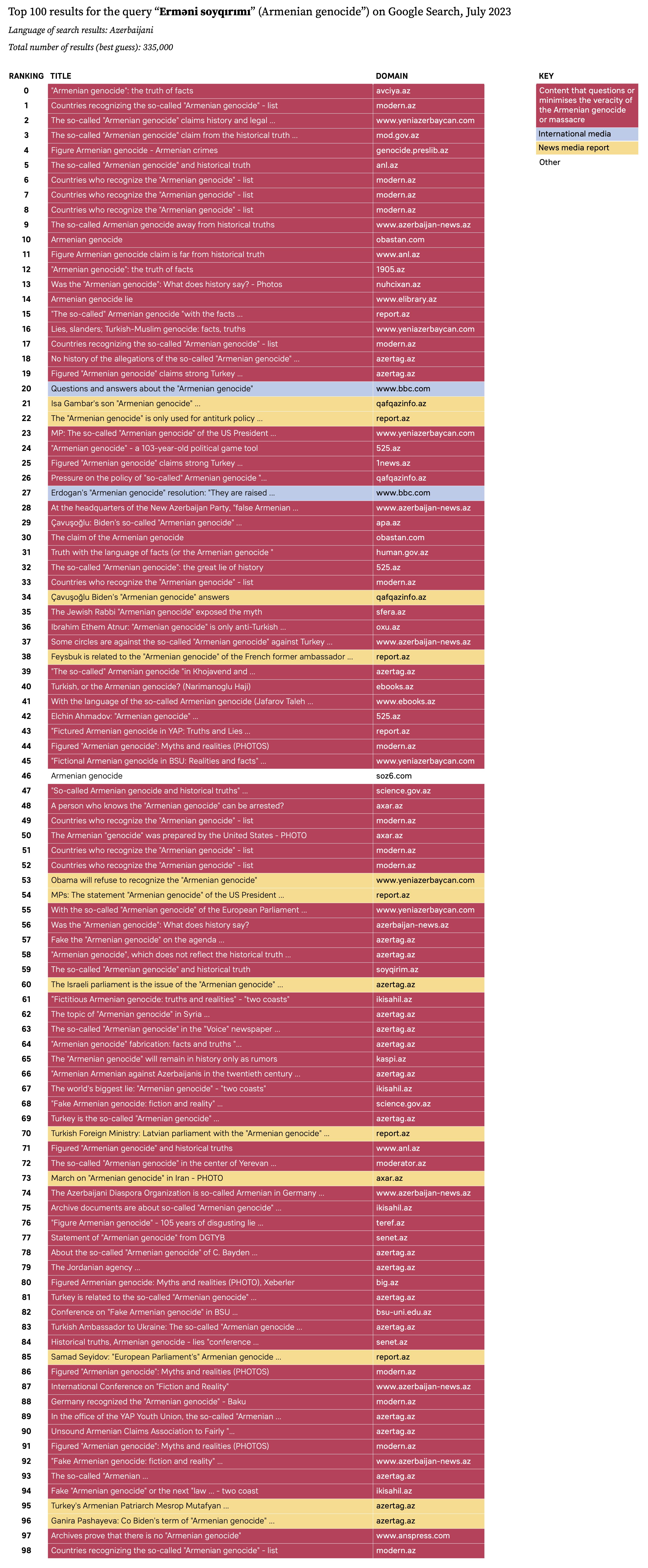{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
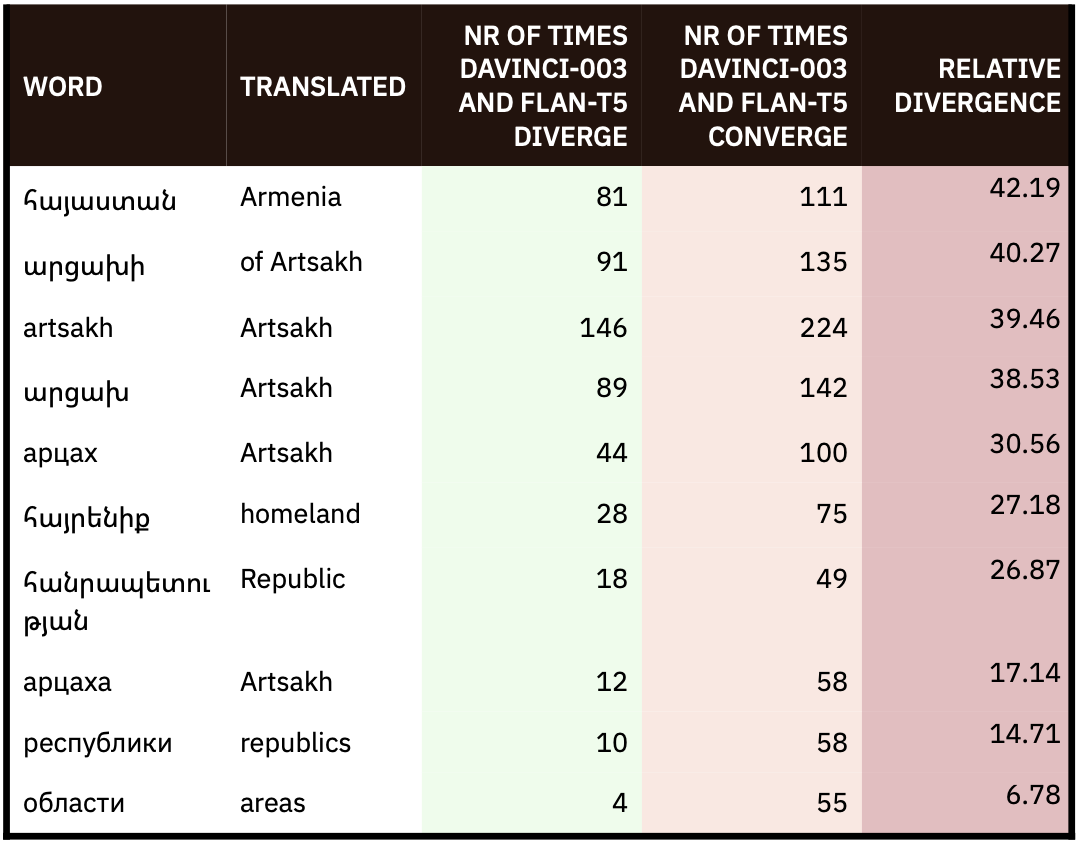{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
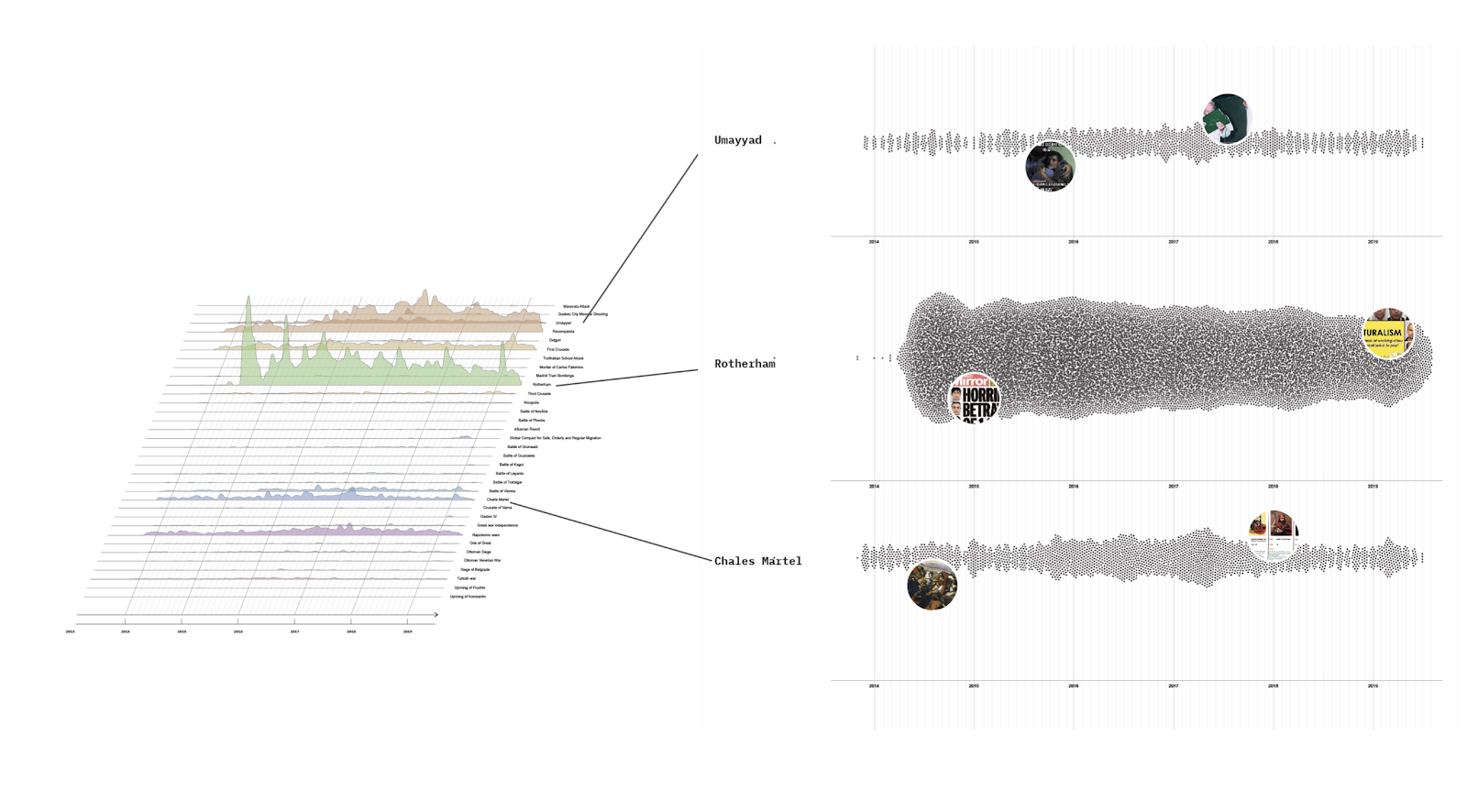{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
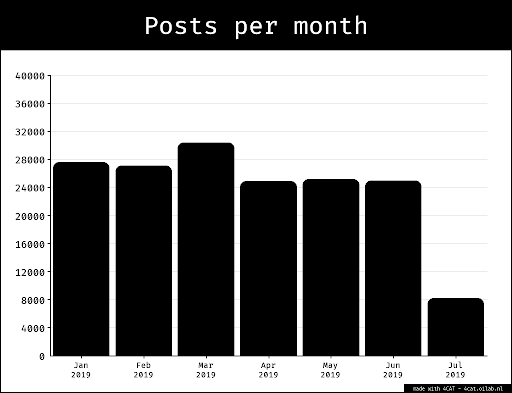{kind=link}
{kind=link}
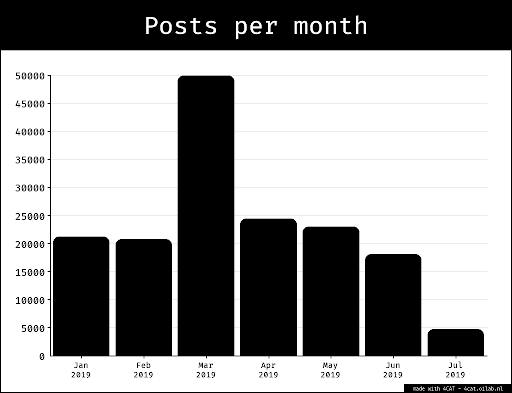{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback