Digital Methods: Tools and Utilities
The various scrapers, crawlers, etc. listed below may be useful for different digital methods. For convenience, the list is loosely divided into tools and utilities, with the former denoting more complex operations that are either method- or device-specific, and the latter referring to relatively simple actions with multiple applications. Please note that of the prescribed uses for these tools and utilities, none are required.Tools
Issue Crawler and Allied Tool Set
- Issue Crawler - Enter URLs and the Issue Crawler performs co-link analysis in 1-3 iterations, and outputs a cluster graph. See Issue Crawler instructions of use, scenarios of use and FAQ.
- Extract URLs - Extracts URLs from an Issuecrawler .xml file. Useful for retrieving starting points.
- Actor Profiler - Calculates the top 10 nodes of an Issue Crawler network map, generates graphics of each node, showing types of inlinks received and outlinks given. It also queries Google for the issue you specify, and shows, on the graphic, the PageRank for those top 10 nodes. The colors for the actor profile are taken from the color scheme on the Issue Crawler map. >howto<
-
 Issue Geographer - Geo-locates the organizations on an Issue Crawler map, using whois information, and visualizes the organizations' registered locations on a geographical map.
Issue Geographer - Geo-locates the organizations on an Issue Crawler map, using whois information, and visualizes the organizations' registered locations on a geographical map.
- Compare networks over time - Compares Issue Crawler networks over time, and displays ranked actor lists. The over time module is best used in tandem with the Issue Crawler scheduler. The results may be plotted to line graphs, in software such as Excel.
- Google Network Cloud - Extracts the URLs from an Issue Crawler result, and allows the user to query all the URLs for key words. It outputs a tag cloud. Good for the analysis of the content of a network.
- Triangulation tool - Enter two or more lists of URLs or other items, and the triangulation tool finds commonalities among them.
- Harvester - Enter text that contains URLs (e.g., copy-and-pasted Google results, or Webpage source code) and the harvester extracts the URLs, and creates a clean URL list.
PageRank Tools
- Pagerank - Discover a website's Google Pagerank per issue/query.
- Issue Dramaturg - Scheduled list of websites' Pagerank per issue.
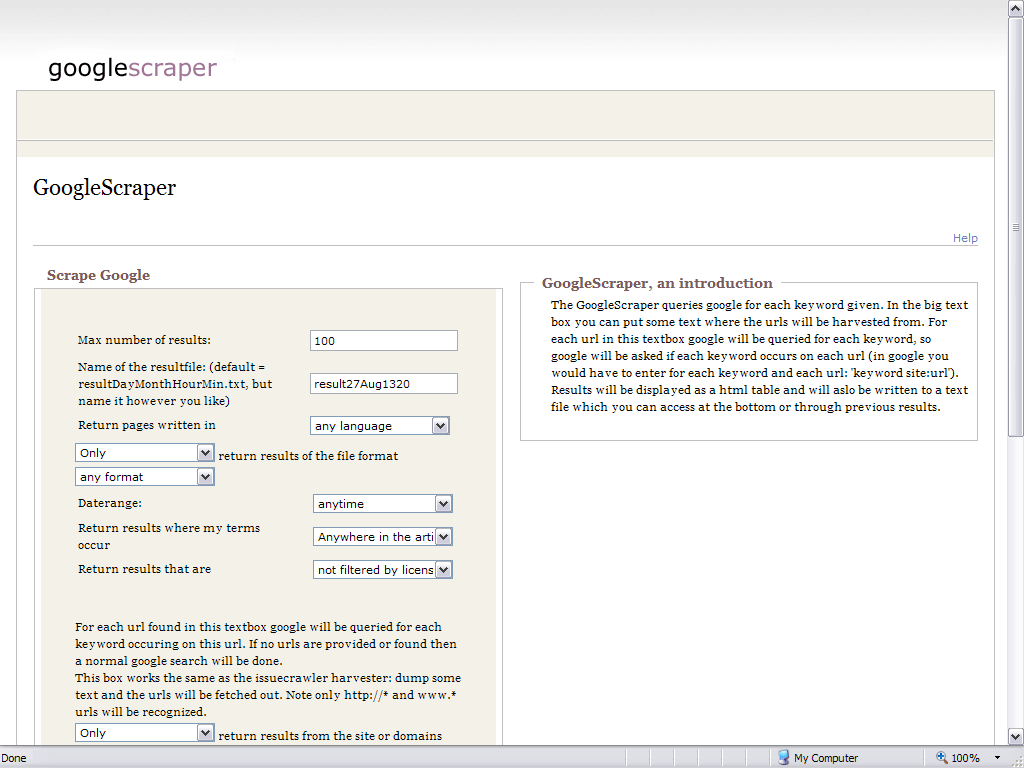
Google Scrapers
-
 Google Scraper - Query Google for a particular keyword/issue, possibly in particular sites.
Google Scraper - Query Google for a particular keyword/issue, possibly in particular sites.
- Google Scraper Frequency Tool - Use a results file from the Google Scraper and discover the frequency with which the original query appears in each individual host. (Tip: visualize these results in a tag cloud.)
- Google Teaser Text Ripper - Use a results file from the Google Scraper to get unique phrases from the teaser (or lead) text for each google search return.
- YouTube video discovery - Use a results file from the Google Scraper to discover, count, and rank YouTube, Ikbis, and Google Video links in the descriptions. Obtain such a result file by querying a set of sites for e.g. 'youtube.com/watch', 'ikbis.com', 'videoplay?'.
- Split Results - Split the results from Google Scraper into two lists (e.g. blocked and unblocked sites).
- Google News Scraper - Query news.google.* with one or more keywords. It's only possible to scrape articles of the last 30 days.
- Google Images Scraper - Query images.google.com with one or more keywords, and/or use images.google.com to query specific sites for images.
- Scrape Google Blogsearch (Open Kapow) - Scrapes titles and URLs for a google.nl/blogsearch query.
Technorati Scrapers
Other Tools and Scrapers
- Open Calais - Discovers the most relevant words and phrases among a set of websites, within a text, or within an issue network (i.e. an Issue Crawler .xml file). This tool is based on Reuters Open Calais.
- Issue Discovery - Discovers the most relevant words and phrases among a set of websites, within a text, or within an issue network (i.e. an Issue Crawler .xml file). >howto<
- Significance Measure - Enter a set of keywords. They will be scraped in various search engines and their specificity to eachother will be returned.
- RSS discovery - Discovers RSS/ATOM/RDF feeds in websites.
- YouTube Response Retworks - enter a <nop>YouTube movie and get all the responses to that video.
- Surfer Issue Pathways - Building upon Alexa's related sites feature, this tool determines which sites are likely to be in the actual surfer paths of other sites related to the same issue.
- Wikipedia Network Analysis - Find a hyperlink network around a Wikipedia topic (see here for more information).
- De.licio.us Related Tags Cloud Generator - Visualizes already scraped tag listings. (Create a tag cloud showing URLs and tags related to a specific issue or keyword.)
- WeScrape (Meta-Tool) - A howto guide for building your own scraper.
- Issue Feed - Issuefeed.net summarizes the content of a set of sites. Enter a list of Websites and give the list a name. Issuefeed.net finds the sites' feeds, analyzes them, and outputs a substantive summary of all the sites in key words, ranked according to specificity and frequency measures. It works for sites in English or Dutch.
Utilities
- Language Detection - Detects the language from websites.
- Link Ripper - Capture all internal and/or external links from a page.
- Compare Lists - Compare two lists of urls for commonalities and differences.>howto<
- Image Ripper - Scrape images from a single page.
- Robots.txt Ripper - Display a site's robot exclusion policy.
- Censorship Explorer - Check accessiblity of a URL through proxies located around the world.
- Text Ripper - Rip all non-html (i.e. text) from a specified page.
- Rip Sentences - Rip text from a specified page and force line breaks between sentences.
- Timestamp - Rips and displays a web page's last modification date (using the page's HTML header).
- Whois - Use a site such as http://www.whois.net/ to check who has registered a particular domain name.
- Counting Tag Cloud Generator - Takes and counts raw text or a Google result and returns an ordered, unordered or alphabetically ordered tagcloud. >howto<
- Tag Cloud Generator - Input tags and values to produce a tag cloud. Output is in html, svg, and pdf.
- Counting Tree Map Generator - Input a text and visualize the word counts in a Tree Map. Output is in svg.
- Tree Map Generator - Input tags and values to produce a Tree Map. Output is in svg.
-
 Dorling Map Generator, aka the Bubbles Generator - Input tags and values to produce a Dorling Map. Output is in svg.
Dorling Map Generator, aka the Bubbles Generator - Input tags and values to produce a Dorling Map. Output is in svg.
External Tools and Wish List
- External Tools - Useful tools from around the Web.
- DMI Tool Wish List - An internal list of tools desired by members of the Digital Methods team.
Using the tools
- On this page you can find some pre-DMI methods which use the tools. See also SummerSchool2007 and the DMI Course Outline
Tools categorized
ToolDatabase (work in progress)Tags: , view all tags


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r36 < r35 < r34 < r33 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r36 - 29 Oct 2012, ErikBorra
Ideas, requests, problems regarding Foswiki? Send feedback