WeScrape
Introduction
Several different applications have been developed to be able to extract and use data from the web. They are often refered to as Mashup's. Within the context of DMI the idea is to use one or more of these applications to provide users with the means to scrape, mine and mash the data they need for their research, without the need for indepth knowledge about programming as xslt/xquery, php or shell. Also, as the scrapers can be made into a REST web service, they can be used by everybody simultaneously. Besides their practical use, applications as these can help us understand the web, its data and the means to get information from of the web, thus providing insights in working with natively digital objects as data. Currently the five major applications are:
OpenKapow
Open what?
Openkapow.com is an open service platform, which means that you can build your own services (called robots) and run them from openkapow.com. These robots access web sites and allows you to use data, functionality and the user interface of other web sites. OpenKapow provides free software on their website they call Robomaker. With this application you can build your own scrapers without the use of extensive programming skills.The application
When you load a URL into the application it generates a DOM tree of the loaded site. It displays the DOM tree itself, the source code and a graphical display of the website which are all dynamically linked so that a click on each field will update the other. This gives the user a good overview of which particular part of the page is located in which part of the DOM tree and where it is located in the sourcecode.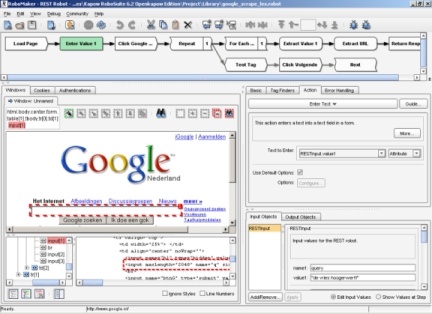 When you locate the part to be scraped, there are a variety of actions from which to choose. You can for instance extract the information or code from the site and load it into an output field or loop through tag path to gather lists, clusters of information or automate an action like a click on the search button or a selection from a drop down menu. All these actions are stored in steps which can be seen as point in the process which the application will walk through when it is activated. Some basic steps to create a personal scraper can be viewed in this video.
When you locate the part to be scraped, there are a variety of actions from which to choose. You can for instance extract the information or code from the site and load it into an output field or loop through tag path to gather lists, clusters of information or automate an action like a click on the search button or a selection from a drop down menu. All these actions are stored in steps which can be seen as point in the process which the application will walk through when it is activated. Some basic steps to create a personal scraper can be viewed in this video.
Sounds great, but...
Since Openkapow uses online servers to run the robots, the first limitation is the availability and capacity of their servers. Using the application for a while, there have been a couple of instances where either the server went down or that it lacked capacity to process the requests. There is also a limit to the number of returns which can be processed. So when the goal is to scrape hundreds of pages from for instance Technorati, the robot will time out. Although the application makes scraping much more accesible to people who do not have programming skills, a basic understanding of programming languages and the structure of the web will still be needed.So can be use Openkapow?
As the limitations have shown, Openkapow and similar applications do not (yet) provide the level flexibility and control which is needed for online analysis. It can however be used to automate parts of the scraping porcess so that the steps in the process which are vulnerable to the dynamics of the web can be managed and do not need to have the expertise present of programmers. In learning the structure of the web and to obtain digital skills, applications like these give insight into the underlying processes and logic of the web.Documentation and instructions
- OpenKapow quick start guide
- Robomaker Users Guide
- Creating a Google REST robot that return the first 20 results
Tags: , view all tags


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
openkapow.jpg | manage | 76 K | 30 Aug 2007 - 19:48 | UnknownUser |
{kind=link}
Edit | Attach | Print version | History: r7 < r6 < r5 < r4 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r7 - 03 Oct 2008, RichardRogers
Ideas, requests, problems regarding Foswiki? Send feedback