Mapping Regimes of Data Access: inquiring practical and epistemological implications of Twitter and YouTube API access modalities
Team Members
Erik Borra (facilitator), Elena Fernández Fernández, Stephanie Garaglia, Linxin Liu, Suay Melisa Oezkula, Alexia Miehm, Martin Trans
First draft bij Linxin Liu, Alexia Miehm, Martin Trans
Summary of Key Findings
-
Location (sometimes) matters when accessing Application Programming Interfaces (APIs). E.g. Twitter’ APIs will not return withheld tweets queried from the country from which it is withheld.
-
Twitter’s API version 2 does not have a search for popular tweets. Version 1 does, but it is language and time dependent, whereas location did not matter.
-
YouTube data obtained through the API and a research browser differ despite consistent settings. As such, data retrieved through APIs are not entirely “authentic” of a user’s experience even when logged out and using a clean research browser .
-
YouTube data collected for research purposes are (to varying degrees) affected/altered by several variables including region, language, and means of access.
-
Some preliminary knowledge of platforms is essential for researchers wishing to use their data.
1. Introduction
For over a decade, researchers have been using web scraping and APIs to gather data from social media services to further their knowledge of both the platforms themselves and the social and cultural phenomena they are implicated in. Due to a variety of factors, this has often happened under problematic, precarious, and even tumultuous conditions. But other than stand-out events that have received considerable attention, such as the 2019 ‘APIcalypse’ (Bruns, 2019) or the relatively recent introduction of Twitter’s Application Programming Interface (API) version 2 (V2), which is distinct to the API version 1.1 (V1) (Cairns & Shetty, 2020), there are many open questions concerning the practical and epistemological implications of existing access modalities.
This study sought to combine several methodological approaches to fill in some of the gaps in understanding the neutrality, reliability, and variation in API-mediated social media research. Since researchers are typically bound by platform-provided API access options, full/unlimited access has been hailed as the golden standard for research access and representativeness. Researchers often assume that gathering data via APIs just returns all the data that is available (i.e. it is exhaustive). However, some research already suggests that platform APIs (e.g. Twitter and YouTube API) are far from neutral tools in that they are not “simple intermediaries, or entities that only transfer information” (Bucher, 2013). Even so, the nuances and degrees of this neutrality remain to be determined, an issue exacerbated by the black box of mechanics.
In response to this issue, this project investigated the extent to which location, language, date, user, or API versions may significantly influence the scope, type, quality and exhaustiveness of the returned data, and thus the corpus for researchers to work with. It does so by combining a historical comparison of API versions, a review of API documentation, and a series of testing exercises that compare results based location-tied settings (e.g. region, language) and modes of access (i.e. API vs. research browser; see Rogers, 2019, p. 33) for platforms Twitter and YouTube. The nuances identified in this exploratory work may, and are hoped to, be of epistemological value to the wider scientific community relying on social media data for empirical research.
2. Methodological approach
Research Questions
The main research question is as follows:
- To what extent do location, language region, user profiles, or other means through which platform data is accessed influence the resulting corpus, if at all?
To answer this overall research question, we devised the following sub research questions:
- YouTube: How do location- and language-settings affect the differences in the results obtained from the YouTube API and browser?
- Twitter: What variables inform the resulting corpus when querying the Twitter APIs according to popularity?
The rationale for these questions was the underlying assumption that data collection through API access would produce “authentic” data, i.e. data representative of what users in a given region and without personalized results would see. These questions were therefore selected to question and test these assumptions.
Initial Data Sets (API documentation)
As our project addresses the epistemological implications of gathering datasets, we purposefully did not use any pre-formed sets of data. Instead, we opted to inductively produce ad-hoc datasets from queries designed to accommodate countless hypotheses derived from observations made prior in the project. This way of approaching our overall research questions was opted for to accommodate the timeliness of a data sprint, where the adaptive abilities to iterate and pivot quickly took precedence over exhaustivity. As a starting point for these explorations, we read and reviewed API documentation for the chosen platforms (Twitter & YouTube). The exploration of this API documentation aided towards obtaining a more contextualized understanding of API access options, settings, and variables. This resulted in a comparative spreadsheet that listed relevant variables (along with their description), filter options, limitations, and access levels. For Twitter this was done for versions 1 (v1) and 2 (v2), which we could then compare. For YouTube we exclusively analyzed version 3 (v3).
YouTube API v3
YouTube provides access through two types of API: (1) the YouTube Data API, which enables users to manage their accounts, and (2) the YouTube Content ID API, which enables interactions with YouTube 's rights management system (The YouTube API Services Team, 2021). For researchers, access is provided through the Data API, currently version 3 (v3). The Data API v3 was the entry point for this project. While a comparison across versions would have been preferable, no options currently exist for querying or comparing previous versions. Individual differences between versions only become identifiable through researcher accounts (oral or in publication), which have for example shown that quotas have been decreased over time. However, these remain anecdotal. Another pathway for identifying discrepancies is through the API version history. While this is in itself comprehensive, the account is chronological and does not provide a comparison by version. As such, version histories were not comparable for YouTube within the scope of the data sprint.
In the absence of reviewable version histories, YouTube ’s API documentation was read on general settings, variables, and access limitations. Compared to more strictly regulated API access (e.g. Twitter’s profile-based access limits and Facebook’s more controlled and channeled access options through Facebook-created tool CrowdTangle), YouTube ’s documentation suggests that API access is more open and “egalitarian”. While options for “authorized access” exist, these apply exclusively to private user data and their access is granted by the owning users (through the OAuth 2.0 protocol: an authorization request to user mediated by Google). As such, API access is neither granted nor limited by users’ profiles/types or intents. Other limitations persist in, for example, the at times, limited or binary filtering options, as well as the quotas. The quota of 10.000 units a day applies across the board of users. Although the API documentation mentions that this allocation exceeds the needs of the majority of users, it remains questionable whether this limit produces comprehensive datasets across queries, particularly in cases where the API is queried by wider audiences through a single tool (e.g. YouTube Data Tools; see Rieder, 2015).
Other issues lay in the framing of certain variables. While the API documentation is fairly comprehensive, some opacity persists around how certain variables are generated and interlinked. For example: Options exist for filtering by topic or video category, but how these are chosen/allocated and to what extent they vary across regions, remains obscure. As such, the obscurity of the black box of mechanics applies not only to how platform contents are collected and shared, but also to how certain platform features translate into API variables and settings. Overall, these features suggest that YouTube data collected through the API is to a lesser degree (than e.g. Facebook or Twitter) subject to digital or sampling bias (see e.g. Marres, 2017), skewed representations arising from (among other limitations) incomplete data or merely snapshot-based data collected from platforms. These assumptions were further tested in the comparative analysis later in this document.
Twitter API v1 & 2
When it comes to the Twitter API versions 1 and 2, it was fairly easy to find information on the different access limitations, general settings, variables, etc. Comparing both, however, was more challenging due to the sometimes minute differences.
As indicated in the previous section, API access is much more stringently regulated on Twitter than on Youtube. With the introduction of Twitter API v2, access levels were added for different kinds of use. The newly added Academic Research track means that profiles are verified both in identity, research interest, and intent. Researchers that get approved are then able to use the Twitter API with higher tweet caps/rule limits and higher rules rate limits. The research track also means access to more advanced filter operators, and perhaps more importantly, the access to the API’s full archive of tweets. This last option means a large step for many researchers. For now, the full-archive lookup is only available for within the v2 academic track, however, Twitter is currently working on also making it available for the new “elevated+” track as well. This indicates the will to extend this transparency more and more. Just as for the Youtube API, both Twitter versions also limit certain kinds of information based on whether or not the tweets and information requested originate from your account or somebody else’s.
Queries in v1 and v2 differ in the way they are inputted (see parameter elaborations in v2, change in available metrics and the v2 addition of the ‘space’ entity). They also differ in their outputs. These differences not only lie in the description or build-up, but also in the basic information that is offered. (V1 automatically returns information on the aesthetics of the profile by, for example, including extensive color and image information.) Refetching previously collected tweets to check for changes, aka ‘rehydrating’, also showed differences between the v1 and v2 display of unavailable tweets. (V1 only shows whether or not the tweet is available, while v2 gives more insight by indicating a possible reason for unavailability, e.g. whether the account was suspended.)
The joint observations from this review were used towards testing variables that may affect results across (a) the version histories (Twitter v1 & v2), and (b) researcher choices and settings chosen in API queries (for both Twitter and YouTube). The subsequent section outlines the resulting research protocols, findings, and discussion by platform (#3 Twitter and #4 YouTube) before joint conclusions.
3. Twitter protocols & findings
Research protocols (Twitter)
Access to the Twitter APIs is granted to one of three access levels (Twitter Dev, n.d.-a): ‘Essential’ which only has access to the API V2 without access to the full archive and are subject to strict limitations; ‘Elevated’ which has access to both V2 and the full V1, without access to the full archive and subject to loosened limitations; and finally ‘Academic Research’, introduced in January 2021 (suhemparack, 2021), which has full access to all iterations and versions of the APIs, as well as the full archive (Twitter Dev, n.d.-b) along with generous limits.
Our overall practical approach to the data sprint, when querying Twitter, consisted of interrogating relevant API documentation, and building case-specific tools and scripts to accommodate ad-hoc hypotheses and fashioning queries. Working from a script provided by Edward (2021) allowed us to retrieve Twitter data across multiple modalities, adapting to observations and findings. We were able to keep future researchers in mind as a guiding heuristic when designing these tools and imagining use-cases, by being able to confer in real time with PhD -candidates about their actual research needs.
Our original queries and keywords were determined based on internationally trending keywords, as a way of being able to query across languages and localizations. Once a set of data was derived from the selected keyword, we found that there was often data missing for certain locations and languages. To test if this issue was only associated with certain keywords, we, as an example, changed from [metoo], as derived to accommodate another group, and entered one that we assumed to be trending universally, [covid].
It is possible to define the sorting of tweets returned when querying the V1 tweet-search endpoint, in terms of either popularity, recency or a mix (Twitter Dev., n.d.-c). Creating a tool to retrieve data with this endpoint in mind, we discovered that this parameter is not accounted for in V2. We thus pivoted from a hypothesis going “what are the differences between the returned corpora when querying V1 and V2 with identical parameters” (see script notebook under heading ‘Search functions’) into “what are the differences in the corpora from scraping the web-interface from a depersonalized research browser with sorting set to ‘top’ and querying the V1 with the sorting parameter set as ‘popular’ given identical queries, accessed from different locations, querying different languages, at the same time?” (see script notebook notebook under heading ‘V1 compared to scrape’ and ‘Twitter data API vs Browser across lang and location’ dataset). Through this pivot we were able to gain insight in how parameters within both versions work, while also exploring how changes in location and language affect the same query.
At that point we were confronted with a scenario we did not expect, as querying non-English languages did not return the minimum-count value specified by the API documentation; we found that sorting with popularity does not act solely as ranking a corpus through an arbitrary metric, but that there in fact exists what we term a popularity-‘threshold’, or a ‘glass-ceiling’ in terms of query or keyword popularity. We then pivoted once again and rephrased our working research question into “what does the popularity-parameter mean?”. Then a script was designed to query different keywords across all recognized languages on Twitter (@tm, 2015), which was run from multiple locations within the same relative short timeframe (see script notebook under heading ‘Language Iteration on V1 popularity’ and ‘Twitter Popularity’ dataset).
Findings (Twitter)
Twitter: Rehydrating data sets
When working with Twitter, refetching previously collected tweets to check for changes, also known as ‘rehydrating,’ it was found that there were differences between how V1 and V2 display unavailable tweets. In Twitter V1, tweets are either available or not. Twitter V2 gives more insight on the matter as unavailable tweets appear in one of two variations: the message “Could not find” is displayed for deleted tweets when searched for manually through web- or app-access; “Not authorized” appears if the account that the tweet was made from has since been suspended. This preliminary finding provides a means of estimating how many tweets had been deleted versus the number of suspended or deleted accounts in a given corpus.
Twitter: Withheld parameter changes based on access
A general interest in the workings of withheld tweets, led us to questioning what information researchers would get returned when querying them. The front-end (what Twitter users see when using the platform) shows differences between tweets that are withheld in certain locations and not in others. This made us query the same tweet, from different locations using a vpn, and in both API v1 and v2. This revealed that, in certain cases, a researcher’s location may limit their access to a tweet or account by way of a country’s request for that content to be withheld. For example, a tweet withheld in India may be viewable by those in Belgium, however the tweet will be unavailable for those located in India (see figure 1). When accessing such a tweet through Twitter’s web-interface, a message will appear in replacement of the original tweet text, that also provides the countries that the tweet is withheld in, and a link that presents users with a generalized overview on why the tweet may be withheld in their country (Twitter Help Center, n.d.). Similar behavior is found when requesting the tweet from the API, but via a VPN. With a VPN located in India, said tweet could not be retrieved, while it could with a VPN located in Belgium,
In contrast to our hypothesis, this way of presenting a withheld tweet in a country in which it is withheld thus appears to be mirrored when rehydrating the tweet via the API. More information about a withheld tweet or account can be gained from reviewing the key-value pair ‘withheld’ found in both V1 and V2 API data sets. The data points ‘withheld_in_countries,’ in V1, and ‘withheld.country_codes’ in V2, list the countries where a given tweet or account is withheld. Furthermore, the value ‘withheld_scope’ informs researchers if the withheld content is a single tweet or the entire authoring account. The tweet that is queried via the API, shows the same censoring that the front-end does. (The tweet text will show if the API was queried in a country from which the tweet hasn’t been withheld. If querying the tweet in a flagged country, the standard ‘withheld’ message appears and the researcher will not be able to see what the tweet originally contained.)
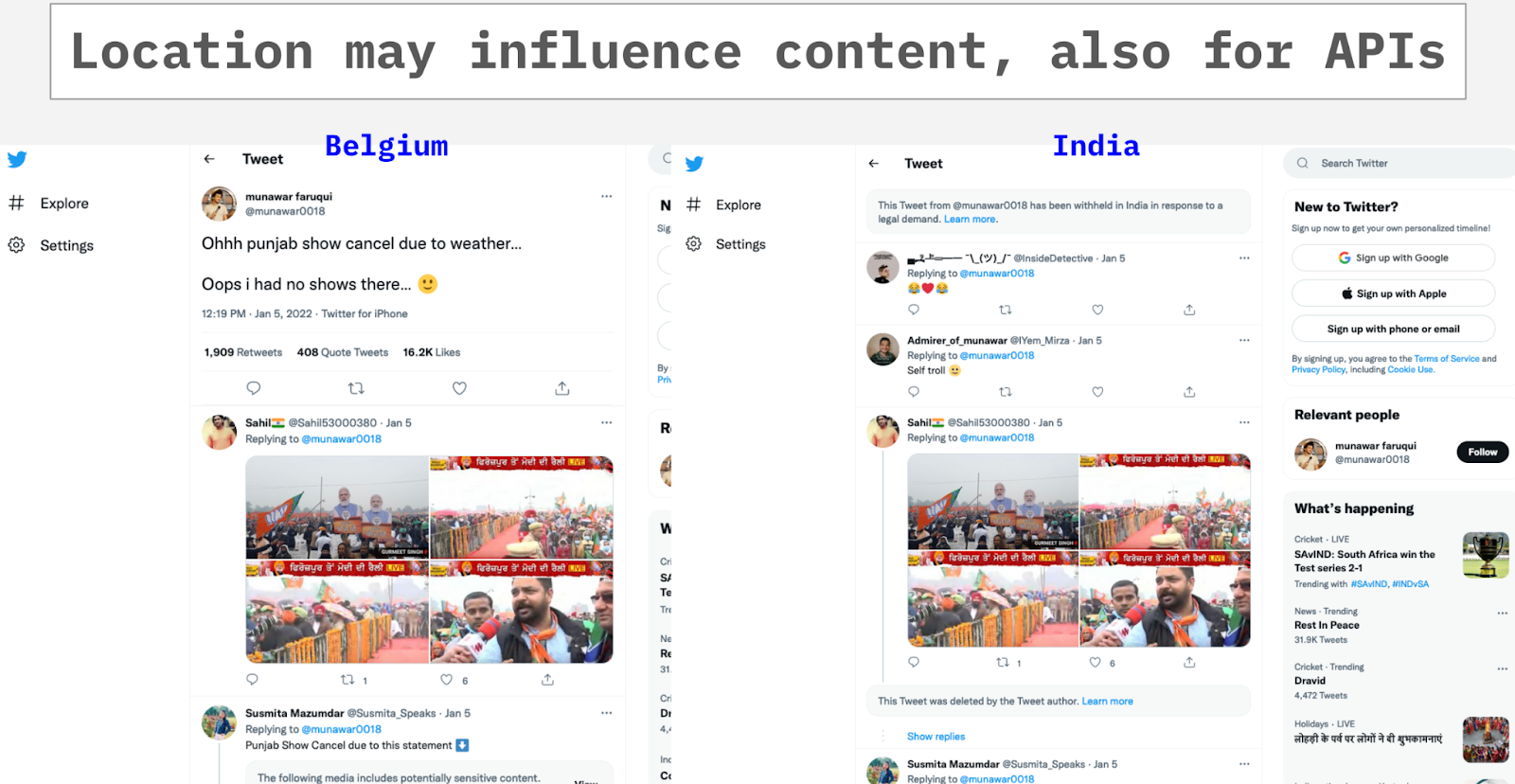
Figure 1 – a tweet, as viewed from a research browser with location in Belgium versus India via a VPN, being withheld in India
Twitter: language settings influence popular content, location doesn’t
The query [covid] was used to determine how language affects the data set results of the result type ‘popular’. Preliminary results indicate that one’s language settings make changes to the content that one views on Twitter, irrespective of location (see figure 2). Many languages are found to not have popular results because they may be written in a different alphabet, for example, the Cyrillic alphabet.
To view the popularity of keyword [covid] across the various languages supported by Twitter, the V1 parameter ‘result_type’ was set to ‘popular’. When querying the term [covid], it was found that the ‘popular’ result setting limits the number of tweets collected per language to a maximum of 15. However, the result types ‘mixed’ or ‘recent’ do not yield the same results as they are not confined to the same metric threshold. When querying V2 for the same keyword, it was found that data could only be collected in chronological order. This limits the ability for researchers to find popular and trending subjects.
Figure 2 – Language may influence the popular, even though location doesn’t, for a query in all languages that Twitter recognizes
Discussion (Twitter)
Our preliminary findings and observations suggest that there is more than marginal difference in the resulting corpora when querying the Twitter API V1 and V2 with the same query. The above mentioned research findings not only revealed that they offer entirely different data points, but also that some key values are formatted differently. We believe it is in the interest of the scientific community to become aware of the important differences between both versions, which in turn may determine the version that fits their project best. E.g. projects using critical discourse analysts may benefit from access to v2 if they need a historical insight in discourses, or legal analysts may prefer to use v1, or v2 depending on what they want to research, when taking a look into censuring practices on twitter within different countries. Further research efforts might be directed towards developing guidelines to help researchers independently determine the differences of queries important to their own project.
For accessing Twitter data, the different APIs appear to be offered to different types of publics, and the level granted has considerable implications for conducting research. Accessing the full archive of tweets depends on being granted the academic level of access, although a researcher seems to be able to compare the legibility of the different Twitter API versions towards their research project from an elevated access-level.
In relation to Digital Methods as a research field, we assume that in many fields much of the Twitter data are collected via ready-to-install platforms like TCAT (Borra & Rieder, 2014) and 4CAT (Peeters & Hagen, 2021). These industry standards are, as an example of the relevancy of these findings, built on top of specific Twitter API versions. We therefor suggest that a researcher’s choice between pursuing either of these is not as simple as choosing which interface one’s more comfortable with, but has far-reaching epistemological implications before data capture and analysis can even begin.
Regarding our finding on the estimation on deleted tweets versus deleted accounts on a given query, this insight might be leveraged by other researchers going forward bound to study the scale and effects of Tweet Decay. This is a phenomenon described in detail by Bastos as “a key metric to identify problematic content, including influence operation and false amplification on social media” (2021, p. 759), articulating the heightened epistemological challenge of ephemerality to researchers wanting to address “public deliberation around matters where the issue being deliberated on is constantly disappearing from public scrutiny” (2021, p. 769).
Our preliminary finding regarding Twitter’s withheld policy illuminates how one’s location is an important factor in content accessibility. This obstacle persists at a web-interface and an API level. This cannot be bypassed based on the API access level, although this is yet to be tested for in-house access. (We do want to underline that it can, however, be bypassed by using a vpn.) When attempting to view a withheld tweet from the web- or app-interface, all content, including social metrics, such as the like or reply count, are blocked from view. Such social measures can be accessed through both V1 and V2 API data sets, however, the text will remain blocked from view. To access any withheld content, one must change their IP address to that of a different country using a Virtual Private Network (VPN). Without making these artificial location changes it will not be possible to collect data on withheld tweets.
Following the discussion surrounding the importance of the location of a researcher regarding withheld tweets, language appears to play a much more critical role than location when querying Twitter across access modalities, as our method of querying top popular tweets for [covid] across all languages recognized by Twitter suggested. As ‘popular’ tweet counts differ, some languages may not have popular tweets for a given query at a given time, which is interesting as the method yields near-identical results irrespective of location, e.g. Romania versus Israel vs Italy. The small differences in our results are, at this point, attributed to the temporal nature of manually changing VPNs in between gathering data. In YouTube ’s case, both the location and language seem more deterministic than anticipated. For instance, querying [metoo] with various browser settings and API-settings set to Italian, English or German videos are returned. This might propose a slightly enhanced focus in future research towards the effects of language-localization and the importance of designing language-efficient queries.
4. YouTube protocols & findings
Research protocols (YouTube Data Tools)
Data was collected through YouTube Data Tools (YTDT, for overview see Rieder, 2015) and a research browser (i.e. a depersonalized version of a browser that is more representative of collectively viewed contents; see Rogers, 2013) for comparison. The aim was to use a set of variables (language region, location, and means of access) to identify potential differences in results. For this purpose, the ‘video list’ module was chosen, which interfaces with the search endpoint using the YouTube API v3 (for more information see Rieder et al., 2018). The search query on YTDT was keyword [metoo]. Parameters were set to order by ‘relevance’ without a date indication. In a range of consecutive runs, datasets were collected with different languages (English, Dutch, and Italian) and region codes (Netherlands, Belgium, and Italy - based on the locations of participating researchers). Equivalent settings were chosen in the research browser.
For pragmatic reasons, metadata of only the top ten video entries were collected (for each pathway - YTDT & browser). Data were analyzed through a set of comparative statistics, in which list contents were compared based on access point (browser vs. YouTube Data Tools) and across language areas and access locations (see attached YouTube Research Protocol). Contents were compared on (a) video match (i.e. how many of the same videos appeared in the list), and (b) video order/ranking (i.e. how many videos appeared in the same exact ranking). The purpose was to explore whether the selected variables affected the results, and, if yes, to what extent. Of particular interest was whether the same selection of region-bound settings across YTDT and browser would differ (significantly) towards gaining a sense of the “authenticity” of data collected through API access.
Table: Variables
| Variable | Options (tested) | ||
| Mode of access: | YouTube Data Tools (API) | Browser (YouTube direct view) | |
| Location | Netherlands | Belgium | Italy |
| Language | English | Dutch | Italian |
The final sample consisted of 15 video lists with 10 video entries each (total = 150 video entries) and an additional run of 2 lists (total = 20 video entries) for hypothesis testing. Since the project aim was not to explore video content, but variables affecting access (i.e. an epistemological rather than a traditional empirical focus), this sample was judged adequate for research purposes.
Note on limitations: YouTube ’s API documentation was read prior to data collection towards understanding differences in settings. While the documentation is relatively comprehensive, contextual information on certain variables is limited. For example, the precise logics through which video categories and topics are generated and viewed remain relatively opaque. For the purpose of this project, variables were limited to more transparent variables (i.e. region and language settings).
Findings & discussion (YouTube)
The video lists showed a set of generally popular videos across regions (regardless of region-tied settings). Even so, differences in results were found based on language and region settings in both the browser and on YTDT, and across both the selection of videos and their order. Discrepancies appeared across the comparisons (exception: YTDT API access across countries with no region or language settings; cf. next page), including:
In the research browser:
-
Different language versions within the same region (Belgium, Netherlands, Italy)
-
Different locations (comparison between Belgium, Netherlands, Italy) within same language setting (Dutch or English)
In YTDT:
-
Different region settings (without language setting; comparison between Belgium, Netherlands, Italy)
Browser-YTDT comparison:
-
Different means of access (YTDT vs. browser) without region setting but with differing language setting
-
Different means of access (YTDT vs. browser) without region setting (default: Netherlands) but with identical language setting
The results differed to varying degrees, both in terms of the content and order of content (even where the same videos appeared). Discrepancies applied, for example, between the browser and API when no region was chosen in both YTDT (which defaults to the Netherlands) and the research browser and the language codes were identical. In this case, the top 10 results matched to only 30-40% in video selection with even lower similarity in the video rankings. As such, API access did not provide an exact replica of in-country YouTube views despite identical region-tied settings (i.e. no region and identical language across means of access). This raises a range of implications about the neutrality and authenticity of API access. In particular, it suggests that APIs are not, in fact, interfaces to the ‘ultimate’ or a ‘universal’ data backend as they are often seen. The results indicate that platforms continue to govern data access based on location, language, as well as mode of access.
One of the most significant results were the discrepancies between the browser and API when region and language settings were identical. The expectation was that identical region settings on the browser (here: Netherlands) and YTDT (here: defaulted to the Netherlands) with identical language settings (here: English) would lead to the same results in video selection and order. This expectation arose from settings being region-specific (rather than region-neutral/region-indifferent). Results differed nevertheless, suggesting that regional specificity does not produce equal results across differing means of access.
The exception to variances was a comparison of region influence in YouTube Data Tools when no region or language was selected, but researchers were based in different countries. Here, the results matched entirely. Since YTDT defaults empty region settings to the server location (i.e. The Netherlands), this result was expected and merely used as a point for cross-referencing other variations (i.e. a point of control).
Some of these findings were, to an extent, expected, as region and language settings are known to affect search results for users. However, these differences in results suggest that region-tied settings play a significant role in the data obtained through both a research browser and the API, including for regions where (in part) the same languages are spoken (here: Belgium & Netherlands). To some extent, this makes regional differences a particularly significant area for comparative research. It does, however, additionally highlight the sensitivity of platform data to these regional settings and researcher location. It suggests that both browser and API results are tied to regional entry points. Whether these are necessarily representative of coherent demographics or identifiable communities remains questionable, an issue exacerbated in level- or quota-based API access options.
These results were, to an extent, influenced by the black box mechanics (also the rationale for the testing exercise in the first place), for example in the opacity of variable description in the YouTube API documentation. The scope of the data sprint also meant that the findings presented here are largely exploratory and form part of a pilot phase. In terms of future research, more comparative statistics are therefore needed towards confirming and further determining the precise ways and extent to which the individual variables affect the data available to researchers.
5. Discussion: Inductive Reasoning, Deductive reasoning and Hypothesis formulation using big data
In the age of information, social media and big data are capturing the attention of scholars interested about cultural change across disciplines that may not necessarily be related to computer science. Oftentimes, research methodologies are field specific, which complicates the formulation of hypotheses using new objects of study (such as social data) outside one's own native domain area.
The Digital Methods Winter School Program is a highly interdisciplinary space where a variety of people with different academic backgrounds gather. Our exploration of platforms as deterministic objects of data production that, as mentioned, not only act as passive containers of data, but actively contribute to its shape; has been followed by the reflection on whether platform literacy is necessary to formulate accurate scientific hypotheses that predate data analysis.
Researchers holding backgrounds in Humanities are for the most part trained in traditional hermeneutics research methodologies (i.e., close readings of texts followed by subjective interpretation). In a sense, it could be argued that this type of mindset allows one to formulate a hypothesis following a deductive way of reasoning (broadly speaking characterized by transforming general observations into specific assumptions). However, big data analysis has a strong component of empiricism. Inductive reasoning, that could be defined as the generalization of concrete observable phenomena, is the preferred method of inference in the natural and technical sciences.
This situation creates an intellectual crossroads for scholars whose background lies in Humanities yet are interested about incorporating social data into their research ventures, and more specifically, at the hypothesis formulation stage. Even if it may be possible for this community of academics to adapt to empiricism by doing some preliminary data analysis, understanding platform agency in data generation is for the most part an overlooked step in this process.
We believe that this situation creates a research gap that we hope to fill with our analysis of Twitter and Youtube API access modalities. As we have shown, factors such as API version (in the case of Twitter, v1. Versus v2), geographic location, or, in the case of Youtube, ranking algorithms; do determine data outputs delivered by APIs. So, a same query may produce substantially different outcomes whether those parameters are (or not) taken into account. These are essential aspects that should be taken into account into the hypothesis formulation of research questions, as a corpus of data should not be considered as a mere medium where to perform computational methodologies, but as an object of study in itself.
Consequently, we argue that some literacy in platform studies is a prerequisite for scholars interested in incorporating social data into their research agendas. Moreover, we propose that hypothesis formulation in New Media lies at an intermediate stage in between inductive and deductive reasoning. While exploratory data analysis (inductive reasoning) may provide some useful orientation in testing preliminary conjectures based on un-empirical observations (deductive reasoning), there is one more element that should be taken into account in this equation: platforms as deterministic containers of data.
We trust that our Wiki article has contributed to shed some light into this process with some specific examples that provide clear evidence of the importance of platform literacy. Moreover, we hope that our analysis of Twitter and Youtube APIs will help researchers with low literacy levels in computer science to gain an understanding about the role of platforms (and, by extension, of data), as one new layer of analysis in the academic field of New Media.
6. Conclusions
Spatiotemporal modalities and access-level do indeed affect the resulting corpus, according to our initial exploration across API versions and the web-interfaces of Twitter and YouTube. Uncovering that tweets that are withheld in various countries are also withheld when queried through the API suggests that researchers potentially must integrate VPNs into their workflows, as APIs are thus not the interfaces to the ‘ultimate’ or a ‘universal’ data backend as platform owners might position them to be. Platforms govern data access, not only on the levels of access, but also based on location, language, and mode of access. Data collections will differ depending on where, how, who and by whom access is provisioned. Things that might influence the data output are, among others, the API endpoint, the location, language, and mode of access of the researcher.
When conducting scholarly work empirically with data gathered from YouTube, our exploratory study suggests that location matters less than expected, as language settings proved to have more influence over query results. It is, however, noteworthy that the differences between the returned corpus are significantly different when searching the API and browser with identical variables. The reason for this seems to be related to the ranking algorithms on YouTube, although it proved difficult to ascertain the exact reasonings through simple querying.
Further work should be directed towards uncovering and delineating the potential for new research affordances from these APIs, for example in terms of withheld tweets, and deleted or suspended tweets and users. The Twitter API V1’s ‘popularity metric’ appears as an excellent candidate to seek further understanding of the complex relationship between trends, geolocation and language-localization on Twitter, as a way of repurposing platform affordances into research methods, a concept suggested by Rogers (2019, pp. 17–18).
7. References
Bastos, M. (2021). This Account Doesn’t Exist: Tweet Decay and the Politics of Deletion in the Brexit Debate. American Behavioral Scientist, 65(5), 757–773. https://doi.org/10.1177/0002764221989772
Borra, E., & Rieder, B. (2014). Programmed method: Developing a toolset for capturing and analyzing tweets. Aslib Journal of Information Management, 66(3), 262–278. https://doi.org/10.1108/AJIM-09-2013-0094
Bruns, A. (2019). After the ‘APIcalypse’: Social media platforms and their fight against critical scholarly research. Information, Communication & Society, 22(11), 1544–1566. https://doi.org/10.1080/1369118X.2019.1637447
Bucher, T. (2013). Objects of Intense Feeling: The Case of the Twitter API. Computational Culture, 3. http://computationalculture.net/objects-of-intense-feeling-the-case-of-the-twitter-api/
Cairns, I., & Shetty, P. (2020). Introducing a new and improved Twitter API. https://blog.twitter.com/developer/en_us/topics/tools/2020/introducing_new_twitter_api
Edward, A. (2021, June 17). An Extensive Guide to collecting tweets from Twitter API v2 for academic research using Python 3. Medium. https://towardsdatascience.com/an-extensive-guide-to-collecting-tweets-from-twitter-api-v2-for-academic-research-using-python-3-518fcb71df2a
Joseph, K., Landwehr, P. M., & Carley, K. M. (2014). Two 1%s Don’t Make a Whole: Comparing Simultaneous Samples from Twitter’s Streaming API. In W. G. Kennedy, N. Agarwal, & S. J. Yang (Eds.), Social Computing, Behavioral-Cultural Modeling and Prediction (Vol. 8393, pp. 75–83). Springer International Publishing. https://doi.org/10.1007/978-3-319-05579-4_10
Morstatter, F., Pfeffer, J., & Liu, H. (2014). When is it biased?: Assessing the representativeness of twitter’s streaming API. Proceedings of the 23rd International Conference on World Wide Web - WWW ’14 Companion, 555–556. https://doi.org/10.1145/2567948.2576952
Morstatter, F., Pfeffer, J., Liu, H., & Carley, K. M. (2013). Is the sample good enough? Comparing data from twitter’s streaming api with twitter’s firehose. Seventh International AAAI Conference on Weblogs and Social Media.
Peeters, S., & Hagen, S. (2021). 4CAT Capture and Analysis Toolkit (v1.21) [Computer software]. Zenodo. https://doi.org/10.5281/ZENODO.4742622
Rieder, B. (2015). YouTube Data Tools (1.22) [Computer software]. https://tools.digitalmethods.net/netvizz/youtube/
Rieder, B., Matamoros-Fernández, A., & Coromina, Ò. (2018). From ranking algorithms to ‘ranking cultures’: Investigating the modulation of visibility in YouTube search results. Convergence: The International Journal of Research into New Media Technologies, 24(1), 50–68. https://doi.org/10.1177/1354856517736982
Rogers, R. (2019). Doing digital methods. SAGE.
suhemparack. (2021, January 26). Introducing the new Academic Research product track. Twitter Developers. https://twittercommunity.com/t/introducing-the-new-academic-research-product-track/148632
The YouTube API Services Team. (2021). YouTube API Services Terms of Service. Google Developers. https://developers.google.com/youtube/terms/api-services-terms-of-service
@tm. (2015). Evaluating language identification performance. Twitter Engineering. https://blog.twitter.com/engineering/en_us/a/2015/evaluating-language-identification-performance
Twitter Dev. (n.d.-a). Getting Started with the Twitter API. Retrieved 18 January 2022, from https://developer.twitter.com/en/docs/twitter-api/getting-started/about-twitter-api
Twitter Dev. (n.d.-b). Search Tweets introduction. Retrieved 20 January 2022, from https://developer.twitter.com/en/docs/twitter-api/tweets/search/introduction
Twitter Dev. (n.d.-c). Search Tweets: Standard v1.1. Retrieved 7 February 2022, from
https://developer.twitter.com/en/docs/twitter-api/v1/tweets/search/api-reference/get-search-tweets
Twitter Dev. (2021). Twitter Developer Platform Roadmap. https://trello.com/b/myf7rKwV/twitter-developer-platform-roadmap
Twitter Help Center. (n.d.). Understanding when content is withheld based on country. Twitter Help. Retrieved 20 January 2022, from https://help.twitter.com/en/rules-and-policies/tweet-withheld-by-country
8. Funding Acknowledgments
Elena Fernandez Fernandez has received funding for this project from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie (MSC) grant agreement No 101024996.

| I | Attachment |
Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
Shortened Research Protocols for Wiki Attachment.pdf | manage | 72 K | 08 Feb 2022 - 19:33 | ErikBorra |
Ideas, requests, problems regarding Foswiki? Send feedback