Detecting misinformation on TikTok with a focus on teen users
Team Members
Armando Espinoza, Barbara Roncalli, Bruno Mauricio Mattos Martins, Chloe Sussan-Molson, Daniël Jurg, Duanni Yi, Duygu Karatas, Emanuele Ghebaur, Gabrielle Aguilar, Goran Kusić, Jingyu Zhang, Miazia Schüler, Ruiying Cheng, Zihang E, Tom Stolp, Luuk Ex, Inge de Wolf, Stijn PeetersPreamble
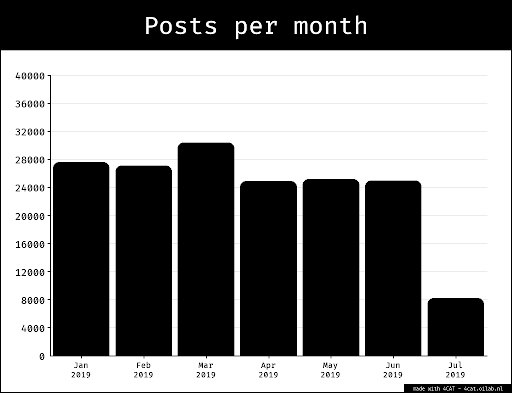
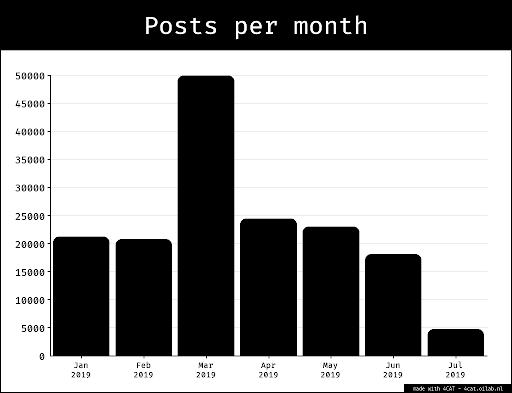
This document is the text report of the project. For a quick impression, take a look at the two posters that were used to present it:Introduction
The social media platform TikTok has rapidly become one of the most important - if not the most important - platforms globally over the past few years. While it was initially mostly known (inaccurately!) as a platform for 'dance videos', recent events have fostered a wider appreciation for the role the platform can also play as a general news and information source for its users. The 2022 escalation of the War in Ukraine in particular brought the platform to the attention of commentators who were quick to dub it 'the first TikTok war' (ignoring the many other conflicts which had been covered on it extensively; see e.g. Weimann & Masri 2020, Miao et al. 2021). With this came concerns about the accuracy of the information users might encounter; the platform makes it easy to (mis-)appropriate video footage to portray events in an inaccurate or misleading way.
Such concerns can be seen as part of a larger and broader debate on the 'infodemic' plaguing social media; and as an extension of that, a debate on how one might counter the spread of misinformation or 'inoculate' potential recipients of it. Given TikTok 's relatively young audience, worries that the platform could be a gateway to problematic information, conspiracy theories and/or extreme ideologies seem justified. In this project, we seek to inform attempts to answer such questions by offering a data-driven impression of what types of content a younger TikTok user might encounter, how one can map such content, and which parts of it may be cause for further scrutiny or require intervention from educators, institutions or policymakers.
Here TikTok needs to be situated in the broader social media ecosystem. The globalization of media technology has enhanced accessibility to various information sources, and thus lead to the segmentation of truth communities with differentiating values and beliefs. This renders the concept of truth a contextual negotiation within and especially between opposing ideological filter bubbles. Platforms such as TikTok have hence provided a space in which notions truth are affected by cultural and technological shifts, spaces which Harsin refers to as “truth markets” produced within “regimes of post-truth” (2018, 4). Truth or falsehoods thus become relational to the eye of the beholder, which TikTok users are well aware of. They are also, however, aware of the fact that they must comply to TikTok ’s community guidelines if they want their content to be visible. To avoid flagging, shadowbanning, and deplatformization, users who want to circumvent algorithmic detection when sharing their truth or purposeful falsehoods will obfuscate their content through the use of neologisms, as will be further discussed below. Obfuscation is used to deliberately insert noise to camouflage content from algorithmic detection, as a way of “mitigating and defeating” its surveillance (Brunton & Nissenbaum 2015, 1). Through the insertion of such noise, content is thus rendered “more ambiguous, confusing, harder to exploit, more difficult to act on, and therefore less valuable“ to the surveilling instance (ibid., 46). In summary, TikTok is already home to a sophisticated ecosystem of information, misinformation, counter-measures, counter-counter-measures, and users who navigate this with varying levels of skill. This is the context in which our project is situated.
The project is furthermore adjacent to a larger project that aims to reduce the spreading, viewing, and liking of fake news among adolescents. The Fake News Workshop by Beeld en Geluid aims to accomplish such a change in adolescents’ behavior. In turn, EducationLab evaluates whether that workshop actually causes adolescents to deal less with misinformation in real-life. To do so, it is necessary to observe and classify participants’ TikTok behavior before and after the workshop. The detection mechanisms and interpretation protocols designed in this project will therefore be used to inform an assessment of whether workshop participants actually view, like, and share less fake news after participation.
Our primary research question here is how we can recognize and classify problematic content on TikTok. This is a broad question, intentionally and necessarily so because one of our main objectives is exploratory: to better understand what affordances TikTok data can offer researchers and policymakers in the analysis of (the spread of) problematic information. From this broad main question, we then develop two more specific lines of research, one focused on finding misinformation from scratch, and one focused on finding misinformation in an existing dataset. We discuss this in section 3, after a brief discussion of how our understanding of 'misinformation' in this context is to be understood.
Context: Misinformation & TikTok
The breakneck speed with which TikTok’s popularity has risen, particularly among young users, is reason enough for other social networks to shake in their boots about their market share. TikTok has already surpassed Snapchat’s ad revenue, is predicted to surpass that of Twitter within this year, and by 2024 even that of YouTube (Sweney, 2022). The video-sharing platform has managed to create a user base of 1 billion users in just four years, halving the time it took Facebook, Instagram or YouTube to reach the same milestone (ibid.). The platform’s audience and affordances have also been crucial in developing various vernaculars now ubiquitous with TikTok (i.e.dances, newscaster style of commenting, video stitching, etc.). Considering the Covid-19 pandemic - during which TikTok exploded in popularity - one has to tackle the spread of information that only flirts with notions of truth. However, conceptualizing disinformation presents a difficulty as the term encompasses all content which is false, inaccurate and/or misleading with the intent of obtaining some form of benefit, to deceive or harm (Bautista et al. 2021, 89). The conceptual distinctions between the various forms of not-completely-truthful information are only the starting point in the attempt to limit the harmful potential misinformation can bring.
In her 2019 paper, Marquardt examined linguistic indicators to try and identify fake news; she follows Leonard Shedletsky’s claims which state that one must focus on the intent or character of a speaker, the text being examined and its intended audience, if one wants to understand how disinformation work (96). She further problematizes the conceptual distinctions between misleading information, deceptive news and fake news (ibid, 97). According to Marquardt, fake news is most difficult to pinpoint, as it can be used to describe any piece of information that is not entirely factual, or any piece of information that can be easily verified (e.g. financial or historical matters) (ibid).
It would be inaccurate to claim that social media platforms have invented the spread of falsehoods and misinformations, however, the viral potentiality, speed and reach of information technologies make for a perfect storm for them to be easily dissipated and packaged in forms which make it difficult to discover and curb the dangerous aspects of such content. After the 2016 US election and the Cambridge Analytica scandal, the conversation on platforms’ responsibility has changed, and it can be argued that in spite of the ease with which misinformation can spread, platforms now have to employ multiple strategies to curb the harms produced. Content flagging, removing and warning are just a few ways that we can see across social media platforms in their attempts at responsibility. According to Bautista, Alonso-López and Giacomelli (2021, 107) verification agencies being present on TikTok would be essential to reach users, especially younger populations which are highly susceptible to hoaxes and falsehoods. Furthermore, next to counting on reliable sources, they argue for the importance of media literacy and citizen responsibility in tackling the spread of fake news and misinformation (ibid).
The NewsGuard project performed several analyses on TikTok in their attempt to map how quickly a new user profile will be subjected to either false or misleading content. In their project on Covid-19, they have shown that within 35 minutes of opening an account and scrolling through the For You page, without engaging or searching for content, a large majority was shown misinformation about the virus and the vaccines to battle it (Cadier and Goldien, 2020). Their project on Russian invasion of Ukraine showed that within 40 minutes of opening a fresh user profile and with no engagement besides scrolling through the suggested videos, every analyst involved was shown misleading content about the war (Cadier et al, 2022). NewsGuard’s work corroborates how easily one is subjected to misinformation on TikTok.
In summary, misinformation is a broad concept, and it is not necessarily easy to demarcate what is and is not misinformation on TikTok. Nevertheless, even if one takes a holistic view and understands misinformation to encompass a variety of more specific categories - such as 'fake news', 'deceptive news' and 'misleading information', it is clear that this type of content is potentially problematic, and furthermore is endemic on many social media platforms, including TikTok. It is from this context that we do our case studies, which are described in the following section.
Method & Data
Project 1: Debunkers as Proxy
-
How can misinformation be detected on TikTok for teenagers?
-
How can debunkers or debunking videos be used as a proxy to detect misinformation?
-
What are the problems and practices in relation to debunking misinformation on TikTok?
This line of inquiry focused on the question of how TikTok as a platform engages with misinformation, and how it can be found. Rather than starting from a single, demarcated dataset, the goal here was to develop a protocol that can be used in any more specific context to identify types of problematic information in that context, as well as map the different practices that emerge around it (such as spreading or countering it).
A complication here is that there is no single characteristic that can identify a TikTok post as problematic or not. Whether content is problematic depends on its context; a particular video can be considered misinformation even when it is unedited, if it is framed in such a way as to represent something it is not - for example when footage of the aftermath of an earthquake is presented as footage from a warzone. This makes it difficult to use a deductive approach where one starts from a given dataset and then labels content. Instead, the approach here was to use 'the methods of the medium' (Rogers 2013), and benefit from the work TikTok users were doing in this area. Specifically, we looked into the practice of 'debunking' misinformation on TikTok, and reasoned that whatever content was considered worth debunking was likely to be a significant category of potentially problematic content on the platform. This approach was then operationalised as follows:
-
A fake TikTok account was created in an attempt to ‘sock puppet’ a Dutch teenager in order to review and analyze the TikTok video recommendation (algorithm) according to the behavioral activity during the initial phase. After 30 minutes of random viewing of any videos a sample of over 1,000 videos was scraped from TikTok with the Zeesschuimer tool (Peeters 2022) by using search terms in Dutch such as 'nepnieuws’ (“fake news”) & ‘misinformatie’ (“misinformation”) and its correlated to the hashtags.
-
The TikTok videos with the #misinformation, #fakenews and #disinformation hashtags, as well as Dutch variations thereof, were collected using 4CAT (Peeters & Hagen, 2022) to see which topics are being debunked or labelled as misinformation.
-
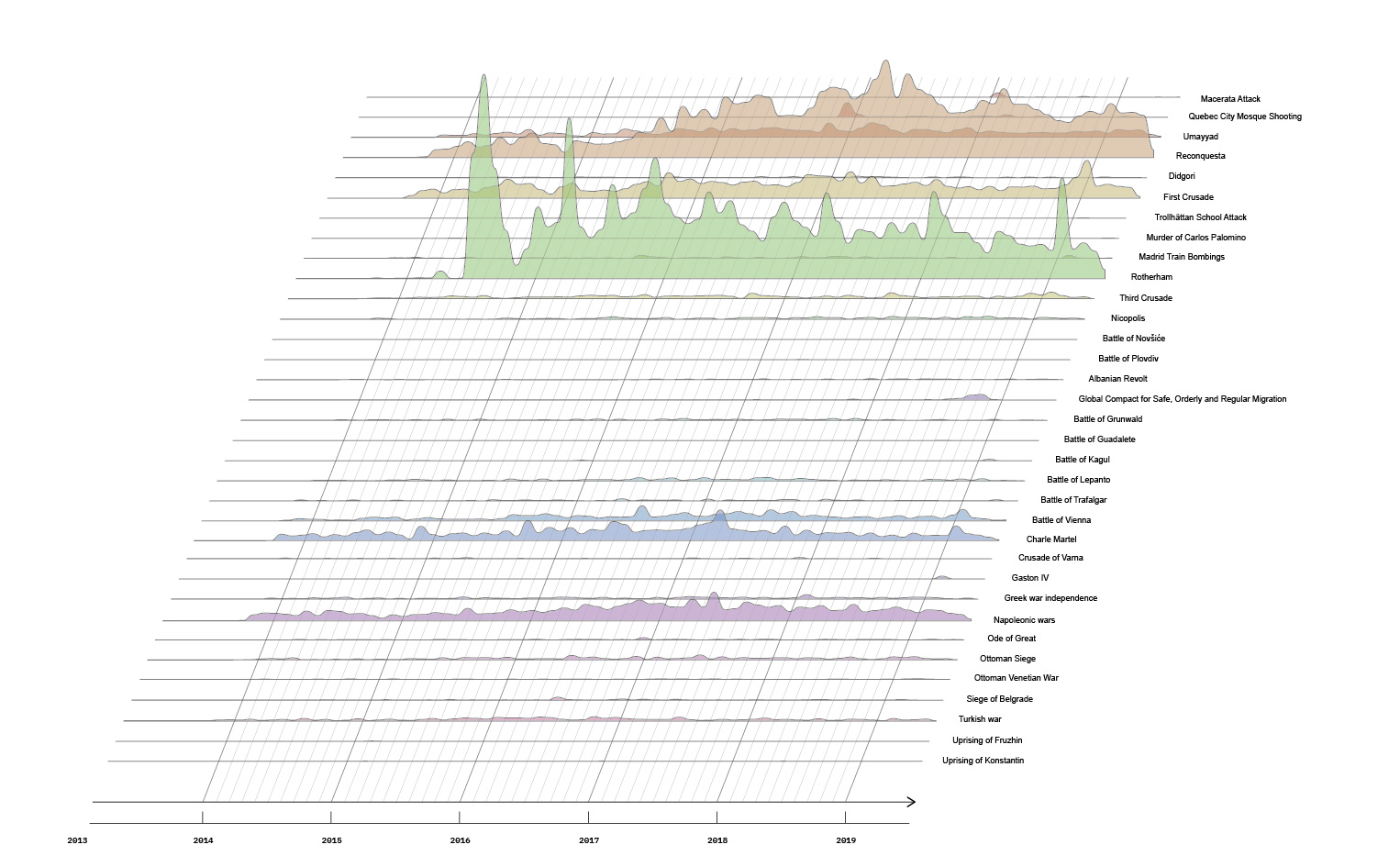
A co-hashtag network was created from the resulting dataset and visually analysed with Gephi (Venturini et al. 2015; Bastian et al. 2009). The ego network was used to review the ‘neighboring’ hashtags and its relevance according to the usage frequency (node size). Throughout observation it was possible to review the themes or words associated to ‘#nepnieuws’ & ‘#misinformatie’ such as ‘geenprikvoormij’ (no shot for me), ‘gentherapie’ (gene therapy), Dutch politicians & Oekraine (Ukraine). A sample of 50 TikTok videos containing the hashtag in the video description and/or comment section were viewed in order to establish a ‘conductor thread’ in the content itself and the Network Analysis.
-
Prominent (clusters of) hashtags - additionally including e.g. #health, #food, #doctor, #doctors, #wellness, #surgeon, #weightloss #medicine and #supplements - were identified as topics for further qualitative analysis.
-
From these topics, a sample of 36 videos was analysed qualitatively. This allowed an inductive coding of 'genres' and practices of debunking. A qualitative analysis was conducted on these videos to understand which topics, users and debunking practices were popular in the videos.
-
We analysed them by watching and coding the videos according to the types of TikTok accounts (claiming expert or non-expert) and the debunking practices (giving information, showing and commenting over the misinformation video,using fun and satire, criticising the misinformation creators, on these videos or making fun with debunking itself.
Project 2: Media Diet: Moderation & Obfuscation
-
How to know if something is relevant or not, what characteristics of a TikTok post can we use to make that decision?
-
What tools can we use for this (e.g. networks, word filters, date ranges)?
-
How to deal with large TikTok datasets?
A second line of investigation started from a previously collected dataset that we knew to represent the 'media diet' of a small sample of six Dutch teenagers. This data was collected by asking participants to do a 'data request' from the TikTok app, after which they received an archive which listed every video they had seen, liked and/or shared while using the app. Such data donations can be effective ways of gaining insight into platforms that resist data collection, such as TikTok, though care should be taken to properly demarcate the use of the dataset and respect the privacy of the donors (Hummel et al. 2019). We therefore anonymised and combined all donated data, so that videos could not be traced back to their donor.
We then collected metadata for all these videos with 4CAT for a dataset of 277,877 items that we knew had been seen by the teenagers in our sample. In our subsequent analysis, we made no distinction between the individuals in our sample, i.e. the dataset was considered to be broadly representative of the sample and we did not inquire into the media diet of specific individuals.
Our interest here was again to explore if and how problematic information was present in our data, but also more generally how one could draw on such a big dataset to identify specific topics or genres engaged with by the people who donated their data.
-
A co-hashtag graph is created from the main dataset to identify clusters of related content through the hashtags that are used. This allows an initial impression of what the salient topics that posts are tagged with are.
-
The thumbnails of all videos in the dataset are plotted in a 2D graph with their position dependent on the visual content, as determined by , an application that plots a set of images according to their (machine-detected) visual features (Duhaime 2017). This provides an additional impression of the type of content covered in the dataset, as hashtags do not fully describe the content they tag, and a visual analysis allows the identification of salient visual styles and formats in addition to the topics and themes that are discussed.
-
Both initial steps allow for the identification of unexpected or potentially problematic categories of content, for which posts can then be isolated (through querying for the specific hashtag or subsetting posts with relevant thumbnails) and subjected to qualitative analysis, in particular a close reading.
-
The initial analysis (discussed in more detail in the next section) indicated that users deployed obfuscated hashtags to escape automated moderation and discuss 'forbidden' topics. As a side-line, a small case study on pro-ana content (content that promotes anorexic behaviour) investigated one specific instance of this, looking for the precise tactics deployed by users to 'fly under the radar' and promote this content.
Findings
Project 1: Debunkers as Proxy
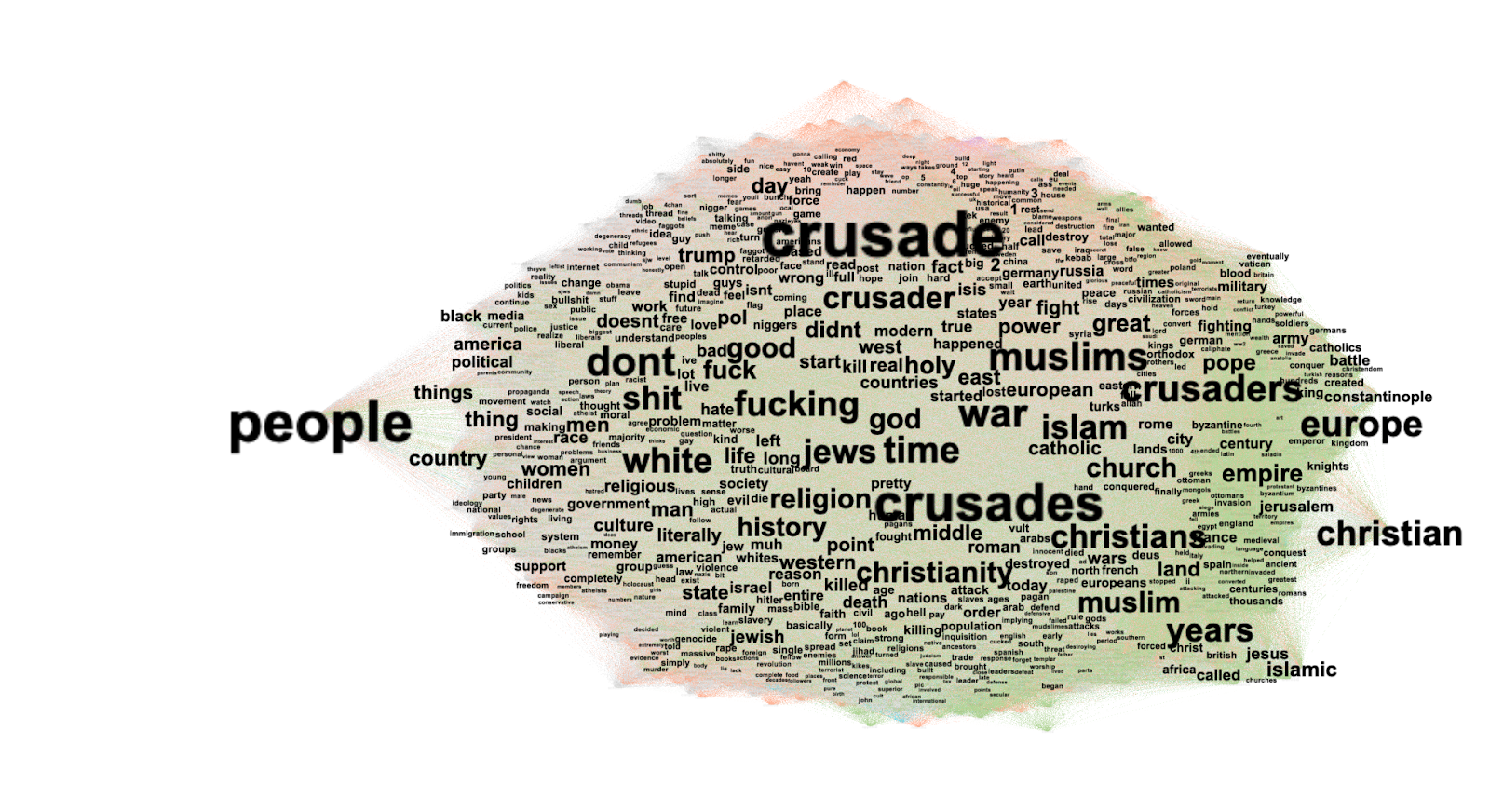
General styles and foci of debunkers: 'experts' and 'pre-bunking'
In the dataset collected for the hashtag '#misinformation' and variations thereon, 24 out of 36 (2 in 3) videos were published by the users which define and portray themselves as 'experts', when the rest were 'ordinary' users who do not make such claims. Claims to experthood are made by styling oneself as 'professor', 'doctor', 'coach', et cetera, as well as the wearing of e.g. hospital gowns. However, it is often not possible to verify if these self-proclaimed experts are actually who they claim to be. For example, a user with 110.3K followers introduces himself as a 'patient advocate professor', but none of his videos seem to actually be filmed in a hospital - despite him wearing a nurse's gown in all videos. Additionally, it was not possible to identifying information about his professional background on Google (though his full name was provided in his TikTok profile). This does not apply to all 'experts', and some are indeed relatively public figures and are in fact practicing doctors; nevertheless, as seen in Figure 1, to the average user the distinction would be impossible to make without doing further research (e.g. looking up the person's name in a search engine).. 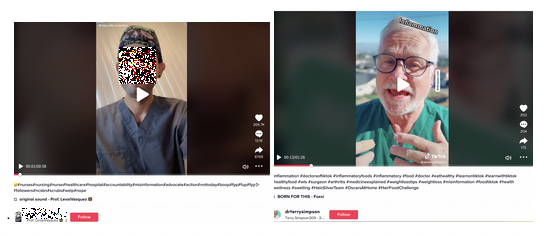
Figure 1. On the left: a self-styled 'professor'; on the right, actual 'weight loss surgeon' Terry Simpson.
As this dataset is relatively specific and small, an analysis of it can be a useful and realistic way to identify categories of misinformation-adjacent content, as by identifying the topics covered by debunkers, we are in fact collecting topics that apparently need to be debunked, i.e. misinformation (according to the debunkers). The overwhelming majority of posts in our data concerned health information, and an inductive coding of the data identified the following main topics in this area:
-
Health, Covid19, vaccination, fake vaccination
-
User vs Expert Problem, fake expert problem, gut-health expert,patient advocacy
-
Pills, birth control, steroids
-
Supplements, Omega 3, Fish oil, processed or natural
-
Food, nutrition, processed food, sugar, light drinks, light Coke
-
Food, nutrition, cooking, vegetable oil, olive oil
-
Health, dermatology, tanning, melanoma, nasal spray,
-
Healthcare,pharmacist,pharmacy,science
-
Weight loss, fitness ,surgeon, surgery, nutrition scam and companies,
Concerning the style of the debunking videos, the most popular debunking method used in the videos was showing misinformation video and talking over that video. This also enables us to detect popular misinformation videos - as they are used as a backdrop - for further research; but additionally highlights the difficulty of identifying misinformation visually, as the same video is used by both those that spread misinformation as well as those that debunk it. In fact, we also saw instances of debunkers being debunked, i.e. someone talking over someone talking over a video that was considered 'debunkable' (see Figure 2), illustrating how this is a useful method to find relevant topics, but also one that requires close attention to the nature of the collected videos.
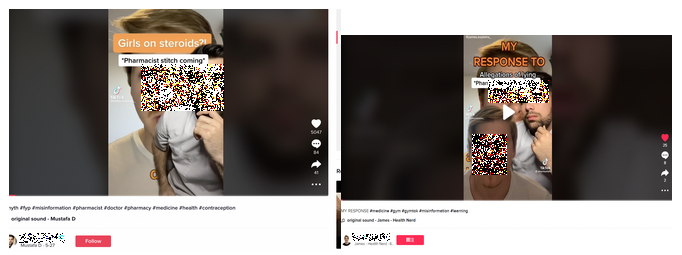
Figure 2. A debunking video, and another video 'debunking the debunker'.
Giving scientific information about a topic which is related to misinformation, without showing a specific piece of misinformation to debunk was another popular method. This took the shape of experts (actual or self-proclaimed) addressing a topic they considered to be at risk of leading to misinformation, a practice also known as 'pre-bunking' (see Motta et al. 2022), i.e. to pre-emptively warn users of these risks.
TikTok debunking and misinformation in The Netherlands
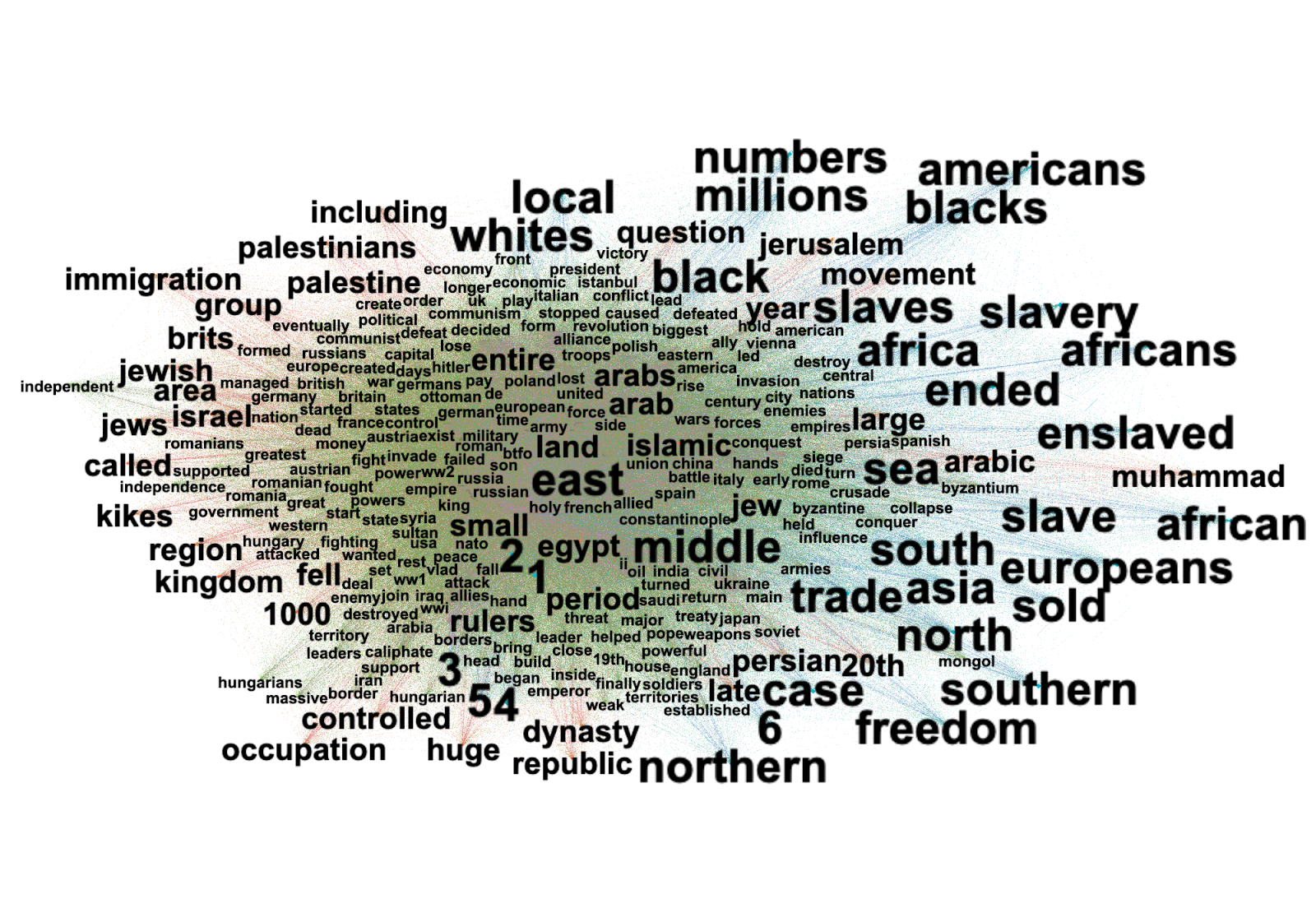
After this general analysis, we looked into the Dutch context more specifically, by querying for hashtags corresponding to Dutch words adjacent in meaning to 'misinformation'. We collected posts tagged with #nepnieuws (fake news) & #desinformatie (misinformation) to analyze the debunking behavior in TikTok regarding the Netherlands. After creating a network of the related ‘neighboring’ hashtags we could find that the search for relating hashtags for #nepnieuws showed up a relation with a number of subjects in particular:
-
Covid-19 vaccines: #geenprikvoormij (no shot for me), #gentherapie (gene therapy)
-
Dutch public figures (in paritcular, far right politicians Thierry Baudet and Gideon van Meijeren, as well as Dutch gossip queen Yvonne Coldeweijer)
-
The holocaust and Palestine.
As a note, we also found an account impersonating or ‘sock puppeting’ the account of Thierry Baudet: Thierry Bouqet (@thierrybouqet). This account presents more activity than the real account, such as videos, likes, shares, comments and views (plays), and primarily posts videos that incorporate Baudet's parliament speeches and interviews as templates for various (mostly non-political) memes.
Interestingly, and echoing our findings from the more internationally oriented dataset, the war in Ukraine was relatively absent from this data, indicating that it is not a topic debunkers are engagin with particularly strongly.
Tentative Conclusions
This explorative case study demonstrates that using the debunkers as proxy to detect misinformation topics works, and allows the identification of salient topics of misinformation, such as health and particular politicians. However, it remains necessary to include a qualitative component in the method, as it is not always clear whether what is being debunked is actually problematic information. 'Fake experts' and 'the debunked' use the same terminology as actual experts and legitimate debunkers, and separating the two is not trivial.
More generally speaking, this method may also be beneficial for the institutions and organizations to capture and measure public opinion and take action to form evidence-based health policies. It could be also employed for detecting the political conflictual issues and political manipulation tactics across social media platforms as TikTok and Instagram in the post-truth age. The use of images and related visual materials in the set up of the videos may give significant insights in this context.
This initial exploration then indicates that the method on offer can be productive. Future iterations of it could be improved in a number of ways. In our case study, the dataset size was relatively low, and adding more relevant hashtags to the query (e.g. in other languages or based on an expert list of known relevant topics) could broaden the scope of the study. Furthermore, the content of the videos could be analysed in more detail, and in fact this could be an opportunity to compile a lexicon of both misinformation and debunking tactics. One could then use the metrics of the relevant videos (likes, plays, etc) as a proxy for their effectiveness.
A final avenue for further research would be the comments on the videos. These offer a rich insight into how people react to both misinformation and debunking and can reveal if e.g. misinformation is actually believed by viewers or not.
Project 2: Media Diet: Moderation & Obfuscation
This line of research was concerned with our pre-existing dataset of 277,877 TikTok videos engaged with by our data donors. The first step was to map their general 'media diet' by doing a co-hashtag graph based on the hashtags attached to the videos, as well as a visual clustering effort through plotting all images via PixPlot. An analysis of the main clusters then revealed the primary topics covered by the videos in the dataset. Here we found the following topics (see also Figure):
-
Gaming
-
Sports
-
Movies
-
Health/ Physical Appearance
-
Art/ Drawing
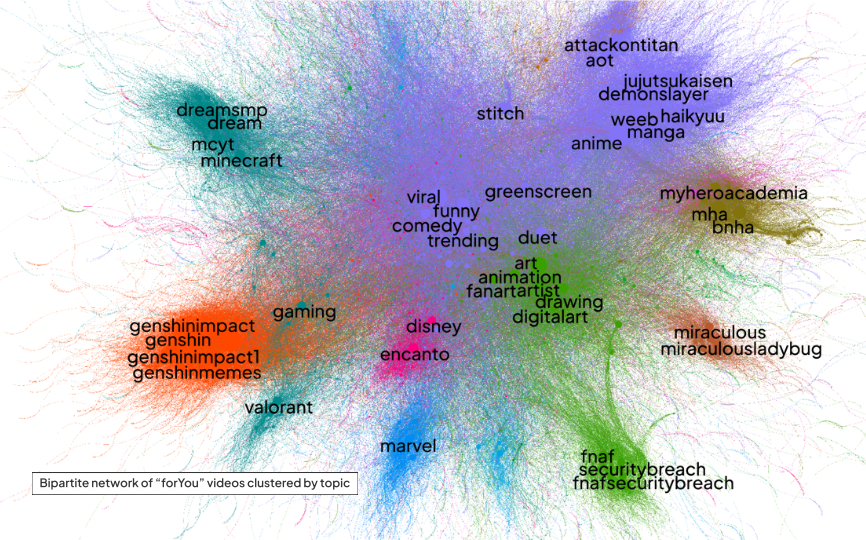
Figure 3. The co-hashtag graph of our donated dataset. Only the most prominent hashtags are highlighted. Rendered by Gephi with the ForceAtlas2 layout.
Keeping in mind the context of misinformation we focussed on areas where possible vulnerabilities were present. From this perspective, the category of content related to health and physicial appearance was most relevant, considering the abundance of existing work that has demonstrated the potentially harmful effects of social media content on the health and self-image of particularly teenagers (see e.g. Pedalino & Camerini 2022; Triệu et al. 2021). We thus focused our subsequent analysis on this category of videos.
Videos on health and physical appearance
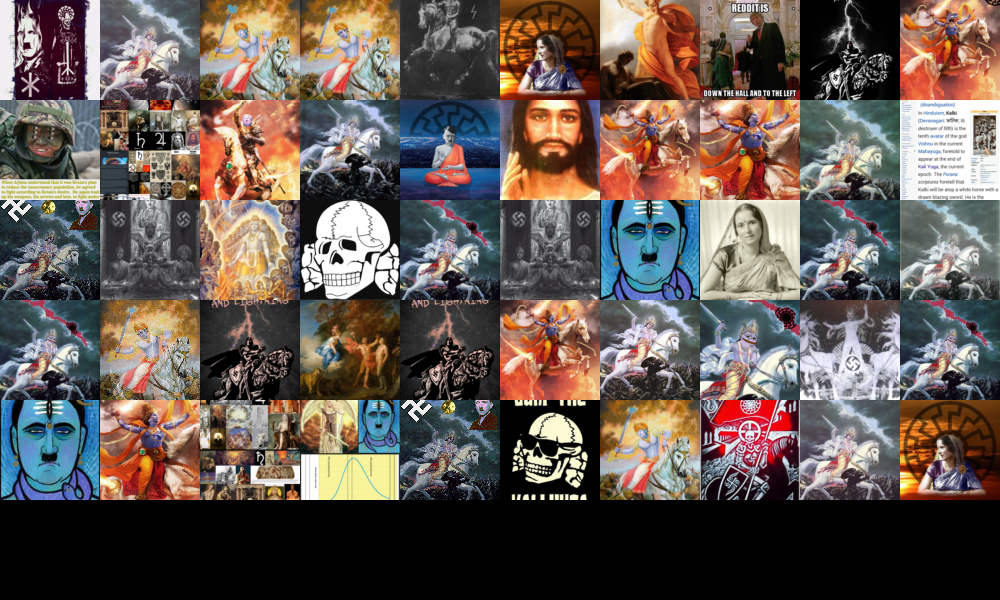
Physical appearance was less obvious in the co-hashtag graph (though it can be found in there) but easily identified through a visual appraisal of the thumbnails of the videos, in which groups of thumbnails showing e.g. people showing their fitness regime or results of plastic surgery were prevalent (see Figure). Related hashtags often centered around weight loss, with variations on 'weight loss journey' particularly prominent. Interestingly, when one searches for ‘weight loss journey’ on TikTok via the app's search feature the app only provides a link to a page that allows the user to contact medical professionals, and does not show any search results (see Figure 4).
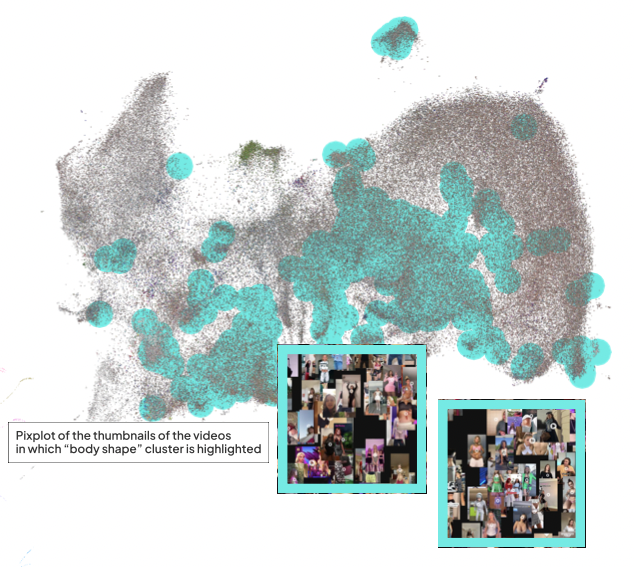
Figure 4. The overall render of thumbnails from our dataset with PixPlot, and a zoomed-in version of two specifically health-related clusters of images.
The 'weight loss' genre then represents a significant portion of the content found in the user data. As discussed, this type of content might provide pathways to some questionable content related to weight loss surgery and problematic eating trends. While these videos are not labeled as problematic, TikTok does identify a risk associated with this content. For instance, if one searches for the term ‘weight loss journey’ on the platform, no results are shown and one sees the following warning:
-
Covid-19 and covid-19 vaccines (493x)
-
The holocaust (46x)
-
Disturbing content (18x)
-
Dangerous activities (609x)
-
Russian state-controlled media (1x)
This flagging seems to be at least partially automated, as we found several videos with such a label that had no clear relation to the topic (such as a video of football player Cristiano Ronaldo being tagged with a Covid-19 warning) and many videos that were about these topics but did not receive a warning. Sometimes such videos had clear markers that should have made them obviously relevant to flag, but often we also saw users deploying obfuscation to circumvent automated detection, e.g. spelling covid as 'c0vid'. This is a known technique used on many other platforms as well (see Brunton & Nissenbaum 2015).
Moderation & obfuscation case study: pro-ana content
One example of obfuscation that was particularly problematic was its usage to spread pro-ana content on TikTok. Pro-ana content, which promotes and encourages anorexia, is a known problem that has existed for decades, and much has been written about this and how platforms may approach limiting its spread (see e.g. Branley & Covey 2017; Logrieco et al. 2021). Conversely, the videos with “obfuscated” hashtags regarding anorexia – at least in this dataset – seem to have been created explicitly so that they could be spread. Indeed, most of this content is created by teenagers and young adults seeking to “spread awareness”. The hashtag #awareness is a frequently used hashtag in conjunction with hashtags such as #anoressiarecovery or #an0rexia. The purpose of the obfuscation seems to be to circumvent the TikTok algorithm’s censorship, which is rather indiscriminate when it comes to eating disorder-related content. Note that these specific hashtags are not necessarily pro-anorexia, but rather demonstrate how in its apparent effort to stop pro-ana content TikTok has blocked all anorexia-related content, including that which seeks to dissuade or educate people about the topic.
Explicitly pro-ana content was impossible to find through TikTok search. However, a single social media platform is not a stand-alone; rather, it exists within a wider context of digital cultures that intersect with each other across several popular platforms. Hence, the strategy used was to look for pro-ana content on Twitter and Reddit using “tiktok” as a keyword in order to find pro-ana content and discussion of TikTok pro-ana content in other platforms. One then finds a lively discourse of 'algorithmic gossip' (Bishop 2019) where people share pro-ana hashtags that seem to change rapidly and have a very short shelf-life, such as #thynspiration, #th!nsp0, #pro4na, #promi4, all of these examples again displaying obfuscation. Earlier research has demonstrated that TikTok remains a gateway to content encouraging anorexic behaviour (Logrieco et al. 2021); this small case study indicates that TikTok's attempts at countering this are not effective and a more holistic cross-platform approach would be needed to adequately address it.
Tentative Conclusions
Our analysis of the donated dataset highlighted health and body shape-related content as one that was seemingly popular with our donors, and also constitutes a potential gateway to problematic content. A combination of a visual and co-tag analysis was needed to reveal this, which highlights how hashtags on their own are not enough to fully map a dataset's content.
!TikTok seems to be aware of the issues around weight loss culture on the platform, and directs users with ‘problematic queries’ to professionals that might help with possible body image issues. However, the automated flagging system that puts warnings on such problematic categories of content seems limited to Covid-19 related content, and in any case is not particularly effective, with many false positives and negatives found in our data set. Obfuscation seemed to be a known and popular tactic of circumventing such automated moderation.
Obfuscation is not in and of itself an indication of harmful or extremely marginal content. For example, TikTok ’s indiscriminate removal or blocking of any content related to eating disorders makes it so that the sufferers of eating disorders have to circumvent the application’s moderation to build support communities or educate about the topic, even if they have no intention of glorifying anorexia. That specific case study - pro-ana content and the tactics deployed to spread and combat it - seems to be a fruitful avenue for further research, particularly from a cross-platform perspective as initial analysis suggests that other platforms are used to spread and generate new obfuscatory hashtags that guide users to the content on TikTok itself.
Conclusion
The contributions of this research are twofold. We have demonstrated a method that appropriates the work of 'debunkers' on TikTok to find salient topics around which misinformation is (perceived to be) a problem. Due to the activity of such debunkers on the platform, this constitutes a viable way to find misinformation in any TikTok dataset - or on TikTok in general - though care should always be taken to separate 'fake experts' and spreaders of misinformation who appropriate debunking terminology for their own purposes.
Additionally, we demonstrate how through the use of co-tag analysis and visual network analysis one can identify salient categories of content in an existing dataset, and then zoom in on those for a closer qualitative analysis. In our case study of content related to weight loss, we found that while TikTok has implemented some measures to counter the spread of problematic information - such as pro-ana content or misleading 'weight loss journeys' - these countermeasures are often inaccurate and easily bypassed by users.
In terms of concrete findings based on our specific dataset, these are then the most important; that health-related information constitutes a major part of the 'media diet' of the teenagers whose data we studied; and that TikTok 's own attempts at countering this constitute only a token effort at best and do not seem effective on their own in preventing such content from proliferating on the platform. More generally, the methods discussed here can be repeated with other datasets or at other times to find relevant categories of content in those cases.
Concerning the countering of misinformation on TikTok, a surprising finding is that 'mainstream' categories of misinformation (related to political issues and e.g. the war in Ukraine) were relatively absent in our datasets, though more so in our donated dataset. On the other hand, health-related misinformation was prominently included. This could indicate that TikTok is effective in preventing young users from engaging with some (but not all) categories of potentially problematic content, but more research would be needed to be sure, as this may also be due to our limited dataset and data sourced from larger groups of teenagers may well show a different picture.
Works cited
Bastian, M., Heymann, S., & Jacomy, M. (2009). Gephi: An Open Source Software for Exploring and Manipulating Networks. Third International AAAI Conference on Weblogs and Social Media, 361–362.
Bautista, P. S., López, N. A., & Giacomelli, F. (2021). Espacios de verificación en TikTok. Comunicación y formas narrativas para combatir la desinformación. Revista Latina de Comunicación Social, 79, 87–113. https://doi.org/10.4185/RLCS-2021-1522
Branley, D. B., & Covey, J. (2017). Pro-ana versus Pro-recovery: A Content Analytic Comparison of Social Media Users’ Communication about Eating Disorders on Twitter and Tumblr. Frontiers in Psychology, 8. https://www.frontiersin.org/articles/10.3389/fpsyg.2017.01356Brunton, F., & Nissenbaum, H. (2015). Obfuscation: A User’s Guide for Privacy and Protest. MIT Press.
Duhaime, D. (2017). PixPlot. https://dhlab.yale.edu/projects/pixplot/
Harsin, J. (2018, December 20). Post-Truth and Critical Communication Studies. Oxford Research Encyclopedia of Communication. https://doi.org/10.1093/acrefore/9780190228613.013.757
Hummel, P., Braun, M., & Dabrock, P. (2019). Data Donations as Exercises of Sovereignty. In J. Krutzinna & L. Floridi (Eds.), The Ethics of Medical Data Donation (pp. 23–54). Springer International Publishing. https://doi.org/10.1007/978-3-030-04363-6_3
Logrieco, G., Marchili, M. R., Roversi, M., & Villani, A. (2021). The Paradox of Tik Tok Anti-Pro-Anorexia Videos: How Social Media Can Promote Non-Suicidal Self-Injury and Anorexia. International Journal of Environmental Research and Public Health, 18(3), 1041. https://doi.org/10.3390/ijerph18031041Marquardt, D. (2019). Linguistic Indicators in the Identification of Fake News. Mediatization Studies, 3(0), 95–114. https://doi.org/10.17951/ms.2019.3.95-114
Miao, W., Huang, D., & Huang, Y. (2021). More than business: The de-politicisation and re-politicisation of TikTok in the media discourses of China, America and India (2017–2020). Media International Australia, 1329878X211013919. https://doi.org/10.1177/1329878X211013919
Motta, M., Sylvester, S., Callaghan, T., & Lunz-Trujillo, K. (2021). Encouraging COVID-19 Vaccine Uptake Through Effective Health Communication. Frontiers in Political Science, 3. https://www.frontiersin.org/articles/10.3389/fpos.2021.630133
Pedalino, F., & Camerini, A.-L. (2022). Instagram Use and Body Dissatisfaction: The Mediating Role of Upward Social Comparison with Peers and Influencers among Young Females. International Journal of Environmental Research and Public Health, 19(3), 1543. https://doi.org/10.3390/ijerph19031543
Peeters, S. (2022). Zeeschuimer. Zenodo. https://doi.org/10.5281/zenodo.6845136
Peeters, S., & Hagen, S. (2022). The 4CAT Capture and Analysis Toolkit: A Modular Tool for Transparent and Traceable Social Media Research. Computational Communication Research. https://doi.org/10.2139/ssrn.3914892
Rogers, R. (2013). Digital Methods. The MIT Press.
Sweney, M. (2022, April 9). The rise of TikTok: Why Facebook is worried about the booming social app. The Guardian. https://www.theguardian.com/technology/2022/apr/09/rise-of-tiktok-why-facebook-is-worried-booming-social-app
Toxic TikTok: Popular social-media video app feeds vaccine misinformation to kids within minutes after they sign up. (n.d.). NewsGuard. Retrieved July 19, 2022, from https://www.newsguardtech.com/special-reports/toxic-tiktok
Triệu, P., Ellison, N. B., Schoenebeck, S. Y., & Brewer, R. N. (2021). Implications of Facebook Engagement Types and Feed’s Social Content for Self-Esteem via Social Comparison Processes. Social Media + Society, 7(3), 20563051211042400. https://doi.org/10.1177/20563051211042400
Venturini, T., Jacomy, M., & Pereira, D. (2015). Visual Network Analysis: The Example of the Rio+20 Online Debate. http://spire.sciencespo.fr/hdl:/2441/1698ddv85d9ffo13hjld5iudlo
Weimann, G., & Masri, N. (2020). Research Note: Spreading Hate on TikTok. Studies in Conflict & Terrorism, 0(0), 1–14. https://doi.org/10.1080/1057610X.2020.1780027

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback