You are here: Foswiki>Dmi Web>SummerSchool2009>SpecialCollectionMaker (29 Oct 2012, ErikBorra)Edit Attach
The Needs of Historical Web Research
To date historical Web research has benefited from the very existence of the Internet archive (archive.org) as well as the methods devised to create special themed collections of Web sites, most notably through the application of "Web sphere" analysis (Foot and Schneider, 2002; Schneider and Foot, 2005). Mainly an editorial approach to identifying sites that belong to a certain theme or sets of events, Web sphere analysis to date has yielded a set of valuable collections, the most well-known of which is the September 11 collection, collected by the Webarchivist group in collaboration with the U.S. Library of Congress. In all, the special collections approach has resulted in nearly 30 completed projects, listed in the ' Web collections' at the Internet archive as well as the ' Web archives' at the U.S. Library of Congress. One may not only browse the collections, but also search them, which is a new feature, available only to the special collections. Conversely, the Wayback machine at the Internet archive accepts single URLs as queries, with certain advanced wildcard options, but not key words. Thus the Web historian (in the U.S. context) currently has at his or her disposal the capacity to browse the history of a single Web site (at archive.org), or browse and search approximately 30 special collections. Elsewhere we have discussed how the Wayback machine privileges single-site histories, and demonstrated a means to capture the history of a site and create a movie (in the style of time-lapsed photography). The history of Google was told in terms of the subtle changes to its interface (over a ten year period), and the analysis concentrated on the demise of the directory (tab), and the human-edited Web more generally. Here we would like to make a further contribution to using the Internet archive for historical Web research. It is a proof-of-concept project that strives to fill certain needs of historical Web research, namely the capacity to build one's own special collection, and query it. In particular we are studying the early blogosphere, and the findings made in separate sub-projects are all a result of building a queriable special collection, entitled the early blogosphere, 1996-2001. The list of URLs to be analyzed are taken from the earliest instance of eatonweb, contained in the Internet archive (from 15 August 2000). All listed Websites are scraped from the Internet archive, and stored for further analysis. One particular contribution we would like to make is in the area of longitudinal Website analysis. To date the special collections have been snapshots of a set of sites, around a theme and/or event. There is only one timestamp-version of each Website.Wayback Web Collections
Create a historical Web collection and analyze it.STEP 1:
Create new collection a) Input URLs (Advanced use: Check URLs for % in archive) b) Show information about the collection (time slider) & Select date (Advanced use: suggest date range (settings, parameters)) c) Name your collection Example: Eatonweb list, 2000. OR: View Available Collections Collections have a status: archiving in progress or archiving completed.- Create a new collection:
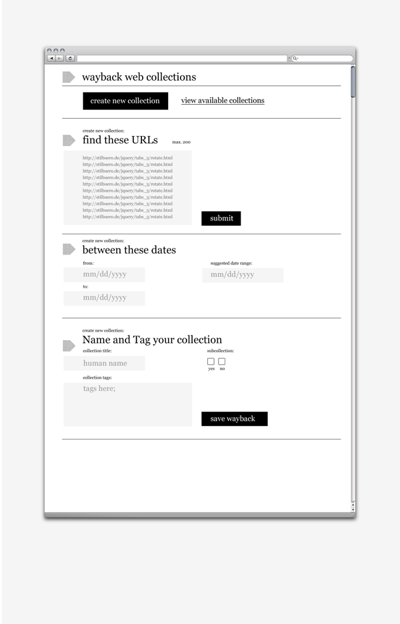
- Or view (and select) available collections:
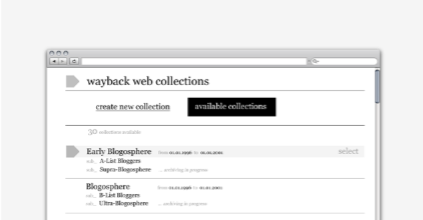
STEP 2:
Once you have a collection, you can:- Browse: load your collection on a grid
- Search: query your collection
- Cloud: cloud your search results
- Map: perform (co-)link analysis of your collection
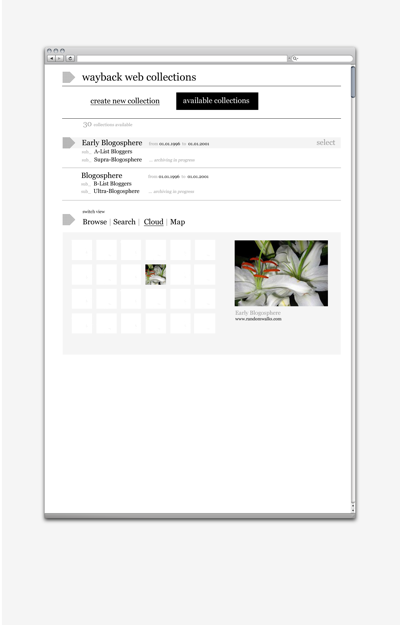
What to do when...
Missing (archived) sites:
- show which other sites mention missing sites (show map of sites with missing sites)
- show historical whois record
- explore URLs through Google
- (Explore URLs through Google cache)


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
availablecollections_small.png | manage | 20 K | 21 Aug 2009 - 16:00 | Main.issuecrawler14 | |
| |
wayback_webcollections_01_Small.png | manage | 35 K | 21 Aug 2009 - 15:51 | Main.issuecrawler14 | |
| |
wayback_webcollections_02_small.png | manage | 41 K | 21 Aug 2009 - 15:52 | Main.issuecrawler14 |
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r6 < r5 < r4 < r3 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r5 - 29 Oct 2012, ErikBorra
Ideas, requests, problems regarding Foswiki? Send feedback