Twitter and the Hong Kong Protests: A Comparative Research on Twitter API Bias and Missing Data
Team Members
Markéta Horázná (10849637), Samuel Leon, Jade Pauli (10350764), Oskar trajn (10849912), Dominique Verschragen (6284035)Table of Contents
- Twitter and the Hong Kong Protests: A Comparative Research on Twitter API Bias and Missing Data
1. Introduction
Twitter is a microblogging site where users share short, 140- character messages called tweets. Launched in 2006, Twitter has become one of the largest social networking sites in the world with 284 million monthly active users who sent 500 million tweets per day from their web browsers and mobile phones (Alexa, Twitter). The Twitter User Statistics display around 6000 tweets a second in average, which corresponds to over 350,000 tweets sent per minute, 500 million tweets per day and around 200 billion tweets per year, (Internet Live Stats). Fred Morstatter et al. suggest that [d]ue to Twitters massive size and ease of mobile publication, Twitter has also become a central tool for communication during protests and disasters, (n. pag.). Richard Rogers acknowledges this notion; however, he argues that most recently Twitter has settled into a data set: Twitter [...] is thus being studied as data, which requires both contractual access as well as technical infrastructure to take in the tweets, store them and analyze them.
Twitters policy for data sharing is considered very open, which makes Twitter particularly attractive for research (Morstatter et al. n. pag, Discroll and Walker 1746, Rogers 7). Compared to other platforms where large volumes of social data is collected, such as Facebook and Instagram, Twitter is particularly compelling because of its accessibility (Discroll and Walker 1746). There are different sets of methods for interacting with the system as public APIs and the non-public Firehose, intermediary commercial collection vessels and analytical tools (Rogers 7). The type of access the API offers to the underlying database of Twitter activity has changed over the years, becoming increasingly more restrictive (González-Bailón et al 3). Currently, there are two main channels to collect data from Twitter: the Search API and the Stream API. Both APIs are publicly accessible interfaces for third-party software programs to collect data from the Twitter platform (Discroll and Walker 1750). Twitters Search API is used for querying the social network periodically in order to get a limited corpus of recent tweets (Twitter). As such, the Search API allows one to retrieve data from tweets that have already been posted. According to Twitters documentation, its important to know that the Search API is focused on relevance and not completeness. This means that some Tweets and users may be missing from search results (Twitter).
The Streaming API returns tweets matching a query provided by the streaming API user in near real time (Morstatter et al. n. pag, Brightplanet). Twitter announces that [t]he set of streaming APIs offered by Twitter give developers low latency access to Twitters global stream of Tweet data, (italics by author). The notion of low latency access points directly at one of the drawbacks of the Streaming API as it only returns 1% of the tweets on Twitter at a given moment. It is important to take into consideration that once the volume of the query surpasses 1% of all of the tweets on Twitter, the response is sampled, (Morstatter et al. n. pag.).
Discroll and Walker argue, that none of the publicly accessible APIs offer the same degree of access that one of the companys own engineers might enjoy, (1746). In other words, none of the available APIs provide an unfiltered, direct interface to Twitters internal data store (1746). Different sources suggest, that one way to overcome the public API limitations is to use the data provided by Twitters Firehose, which is in fact very similar to the streaming API as it pushes data to end users in near real-time. The difference is that Firehose is not limited to 1%. As such, we understand the Firehose as the baseline dataset as it provides the full stream of activity, which allows access to 100% of all public tweets (Morstatter et al. n. pag). According to Twitter, Firehose returns all public statuses.
In order to move platform research beyond the study of online culture, we need to understand the work that APIs perform and whether the sampled datasets they provide are representative for the full stream of data. Recent researches pointed at the opaque way in which Twitter samples the data (Morstatter et al. n. pag.). Morstatter et al. acknowledge that [r]ecent research has shown that there is evidence of bias in this sampling mechanism under certain conditions, (n. pag). This could make one wonder when the public APIs are representative, and when they are biased (Morstatter et al. n.pag.). Logically following out of the notion that public APIs are limited and the Firehose represents 100% of all the tweets, is the understanding that access to Firehose would provide the baseline dataset to assess the bias that derives from using the Stream API and Search API. By comparing the public APIs with the Firehose data, we aim to research whether an identifiable bias exists and, if so, to determine its nature and consequences.
This paper connects to a larger research The Interface Bias, which mainly focuses on identifying the interface bias by comparing data samples from the Stream API and the Search API with the firehose dataset. The empirical context is given by Hong Kong protests, which took place between September and December 2014. The Internet Bias research collected data of three datasets around these protests for the period of 1 October until 15 October 2014. The 15 days were divided in smaller segments, as such, this particular research focusses on the datasets provided on 9-10 October. Following the Interface Bias research, the aim of this research will be twofold. Firstly, we will be researching whether a problematic bias can be identified. Secondly, if so, we will zoom in on the nature of this bias and examine which variables influence the deviation.
1.2. Hong Kong Protests
The Hong Kong protests came in response to a decision by the Beijing government to limit voters choices in future elections for the autonomous territorys chief executive in August 2014 (Freedomhouse n. pag). This decision effectively ended a 17-year period in which Chinese leaders attempted to retain control of Hong Kong politics while still holding out the promise of eventual universal suffrage, (Freedomhouse n. pag.). Boldly, the protesters want an open vote, but Chinas plan would only allow candidates approved by Beijing. The protests began in September 2014 and continued until mid December 2014. The western media related the Hong Kong protests to notions as the social media revolution (the Guardian, ABC news) and social media fuel (USAtoday). Moreover, recent researches question the role that social media plays in the protests, for example, whether new social media have any real effect on contentious politics (Segerberg and Bennet 197). As such, researches deal with social media data in order to study cultural phenomena. This relatively recent trend makes it even more important to research the reliability and validity of various data collection strategies.1.3. Research Question
To what extent can we identify bias in the Twitter Search and Streaming APIs using the Firehose as a baseline? If we identify a bias, we will furthermore address the following questions:- What is the nature of this bias?
- Who is responsible for this bias?
1.4. Structure of the research
Our methodology and findings sections have been divided into two parts: A and B. Part A is focused on the metrics and statistics of variables of all datasets. Here, we aim to identify a bias. In part B, we will zoom in on the nature of the bias and explore possible reasons why this bias may have occurred.
2. Methodology
In this research, we are expanding upon the idea that the use of a certain type of API might yield different results. As explained before, we will be comparing two different methods to a baseline dataset, which is Firehose. Deviations in datasets when working with different research tools are common, yet it is necessary to find out whether these deviations are substantial and therefore cause a problematic bias. If a bias can be identified, it is relevant to know what the nature is of this bias.
The Streaming API and Search API data has been imported into TCAT (Twitter Capturing and Analysis Toolset), which is a program that allows researcher to retrieve statistical information about the dataset. Furthermore, it is connected to Gephi, software which returns visualisations and gives different metrical options. We will be focusing on the @mentions to find out which Twitter users were the most prominent. Furthermore, we will employ a hashtag analysis to see which hashtags are most prominent and how they are connected to the overall network of protest tweets.
2.1. Scope of research
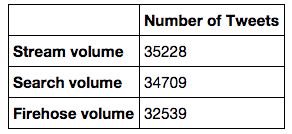
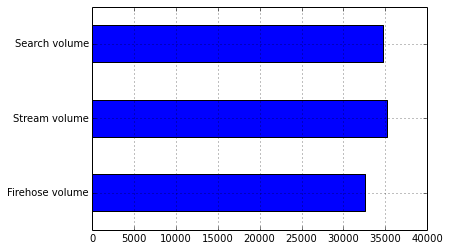
As stated before, this paper connects to a larger research, which mainly focuses on the period of 1-15 October 2014. Due to the large amount of data, in this paper we will only be looking at the 9-10 October 2014. During this period, a total of 35,228 tweets were captured by the Streaming API and 34,709 by the Search API. The Firehose dataset consisted of 32,539 tweets, which we will use as our control data (see image 1).
2.2. Methods part A. Metrics and statistics
We obtained the raw data from the Interface Bias project and some, already cooked data, from TCAT. We parsed the data in IPython Notebook and consequently retrieved some basic summary statistics, which helped us determine whether there was any bias; the two main aspects that were scrutinized were the volume of tweets and the occurrence of the six hashtags (#hongkong OR #occupycentral OR #umbrellarevolution OR #occupyadmiralty OR #hk929 OR #hkstudentstrike).
In order to analyze the three different datasets, we used the IPython Notebook software for writing data analysis code. The key aspect of this software is that it allows researchers to work interactively, record the steps and go back to them if necessary. It runs online, therefore multiple researchers are able to reproduce the work. The main reason why we opted for this software was that some of the files were too large and as a consequence, MS Excel was crashing. Above all, sometimes, it was necessary to manipulate the data and use functions that are not supported by MS Excel therefore, it was more efficient to use IPython Notebook.
2.2.1. Hashtag analysis
In order to find the most used hashtags across our different datasets, we used IPython to calculate the numbers and draw a visualisation table. We did not explore this further, because it is not the most relevant variable for this research. Rather, this information serves as a statistical overview of the data we are working with.2.2.2. @mentions analysis
The first interaction with the tweets from the Hong Kong Protest was facing the vast number of information in three different datasets; the Search API collection, the Stream API collection, and the Firehose dataset. In order to gain insight into the exported graphs, we used Gephi, a visualization platform for networks. More particular, to visualize a network of the top mentions for each of the three datasets. In other words, we used TCAT and Gephi to draw a mention network graph. This graph shows which Twitter users are being mentioned by other Twitter users. We employed this step for all three datasets to find out whether they provide different data.
A priori considerations
The first consideration before commencing the visualization of the mentions network was the large amount of the data we were dealing with. Firstly, we had to decide how to limit the provided datasets as we are subjected to technological and time limitations. Secondly, we had to decide what tools to use to retrieve the information in order to insert them into Gephi. Furthermore, dealing with three different datasets forced us to consider how to apply the same limitations to all of them.
2.2.3. Sampling
As we worked with large datasets, the first step was to extract three representative samples, that each represent the top 500 mentioned users. In order to do so, we made use of the TCAT Digital Methods tool. First, we filtered out all the tweets that did not contain the at (@) sign as this particular sign displays that the tweet is a mention tweet. Subsequently, we removed all of the users that did not belong in the top 500. With TCAT, we were able to extract the datasets provided by the Stream API as the Search API. However, we encountered struggles while extracting the dataset provided by the Firehose. Due to legislation, the Firehose dataset is not allowed to be inserted into the TCAT, as such, the dataset had to be manually extracted. To repeat the steps that TCAT did, a separate algorithm had to be written. We emulated its functionality in IPython Notebooks and the Panda Library. We deduced the top 500 most frequently mentioned users from the Firehose data by analysing the mentioned user name columns. Subsequently, we exported the columns as a table that included details on the number of times these top users were mentioned. Besides, we exported another table containing all tweets in which the top 500 users were mentioned. Finally, this table containing the top 500 mentioned users extracted from Firehose formed the basis for the network graph where source nodes are the tweets and the target nodes are those users mentioned.
2.2.4. Gephi
We inserted three datasets in Gephi but only those extracted from TCAT (Stream API and Search API) allowed us to generate a visualization of the dataset. Without going into details, we noticed that when we inserted the sample of Firehose dataset in Gephi, the dataset did not open as expected. However, the Firehose sample still applied for a statistic overview. The visualizations of both, the Search API and Stream API were made according to the same procedure. However, for each dataset there was a different time needed to render the nodes to produce a satisfying visualization. In order to gain a clear layout we applied the Force Atlas 2 algorithm that gathers the more connected nodes in the center and pushes the less or non-connected nodes to the outer edge of the graph. We adjusted the scaling to 100 and set gravity on 10. Subsequently, we used the prevent overlapping function to put weight on the more mentioned nodes using the no_mentions within the Ranking section. Furthermore, we applied the heat scale to paint the nodes. As such, the more frequently mentioned nodes are red coloured and less frequently mentioned nodes have a light blue colour. The nodes are named by adding the text to the graph and run another layout algorithm, Label adjust, to prevent overlapping of the texts.
2.3. Methods B. Exploring the nature of bias
When comparing the Streaming, Search and Firehose API, we found that they returned different numbers of results (see image 2). This deviation in volume of tweets can partly be explained by the terms of use of the APIs. Both the streaming and the search API have set limitations to the amount of data that can be retrieved. As those terms of use differ from one another, the difference in volume of tweets can thereby be explained. The Firehose API, however, is supposed to be a complete list of tweets. Only when tweets have been deleted by users or Twitter, for instance when they are considered to be spam, the APIs are required to remove those tweets from the datasets. This means that although theoretically the Firehose dataset should return 100%, practically it will never meet this percentage.
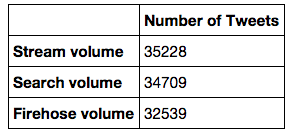
Figure 1: Total number of Tweets from Stream API, Search API and Firehose
Strikingly, the amount of tweets from the Search and Streaming APIs are higher than the number of tweets in Firehose. This is a relevant finding, because if the Firehose data should be close to 100%, then its dataset should in any case be larger than the Streaming and Search API. In other words, if Firehose would be the complete dataset, only excluding those tweets that have been deleted, this could mean that the search API and streaming API did not remove deleted tweets from their dataset. In that case, those APIs are not meeting Twitters terms of service. Another explanation is that the Firehose API did not only remove deleted tweets, but also removed other content. That would mean that the Firehose API does not return a complete dataset. Both options relate to the question of bias and hence deserve further examination.
To examine the cause of the different volume of tweets, we compared the tweets' IDs of the streaming and search API datasets with the Firehose tweet IDs. We manually retrieved a list of tweets that were missing from Firehose and were existent in the streaming API. As Firehose states that it is a complete list, only excluding tweets that were deleted, this list would consist of deleted tweets. Rather than assuming that the Streaming API and the Search API did not meet Twitters terms of service by simply including all deleted tweets, we zoomed in on a sample of those tweets to see whether they were deleted or still online. Our list of missing tweets from the streaming API consisted of 2802 tweets. The total of URLs existing in the search API that were missing in the Firehose data was 2784 tweets. We constructed these lists by comparing the ID numbers of the streaming API and the search API with the Firehose data. We then manually reconstructed the URLs these tweets could be found on, by using the concatenate function in Excel. With this function, it is possible to reconstruct a URL, because you can combine different values (stored in the Excel columns) into one new value: the URL.
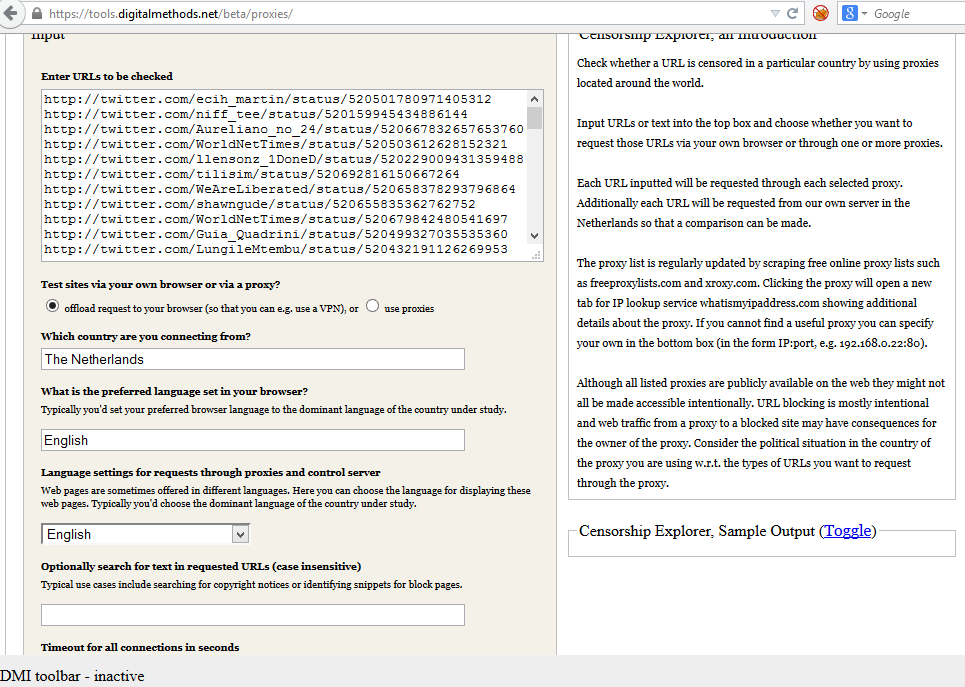
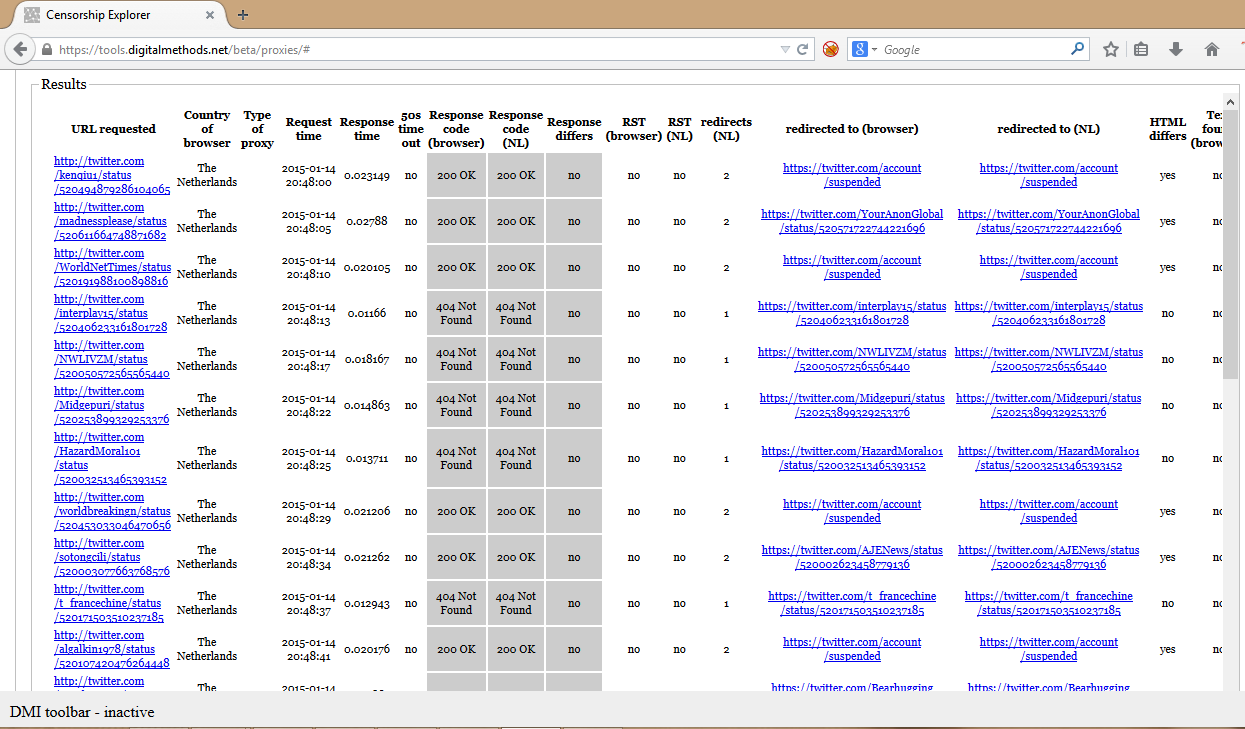
From this URL list, we randomly selected 301 tweets from the streaming API, which correlates to 10,7 percent of the corpus. For the Streaming API, we looked at 300 URLs, which amounts to 10,8 percent. We employed the Censorship Explorer tool from the Digital Methods initiative to check whether these URLs were still online or had actually been deleted. Usually, one would use this tool to detect censorship; however, it also shows response codes from a list of URLs when searching from a regular and properly working IP address. It furthermore returns information on URLs that are being redirected. Hence, by testing our sample of URL tweets in the Censorship Explorer, we are able to find out whether those URLs are still online, not found or have been redirected. The input field and result page of the Censorship Explorer are shown respectively in figure 3 and figure 4 In the input field, one enters a list of URLs and specifies the country from where you are testing.
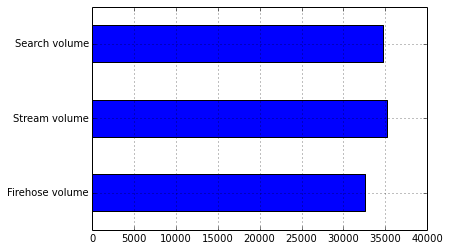
Figure 2: Overall volume of tweets in different APIs
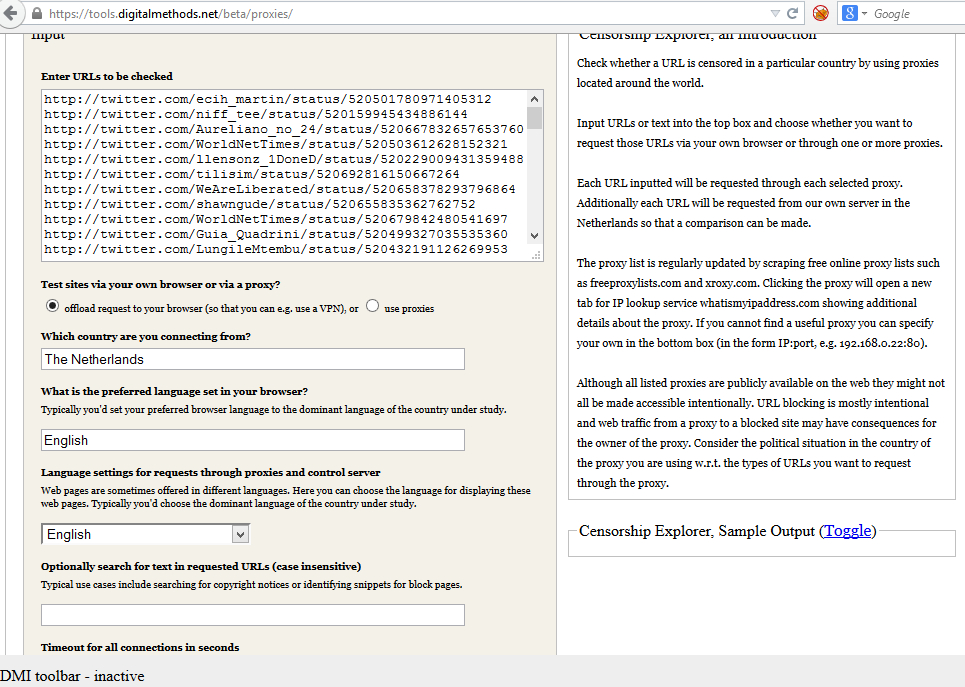
Figure 3: Censorship Explorer input field
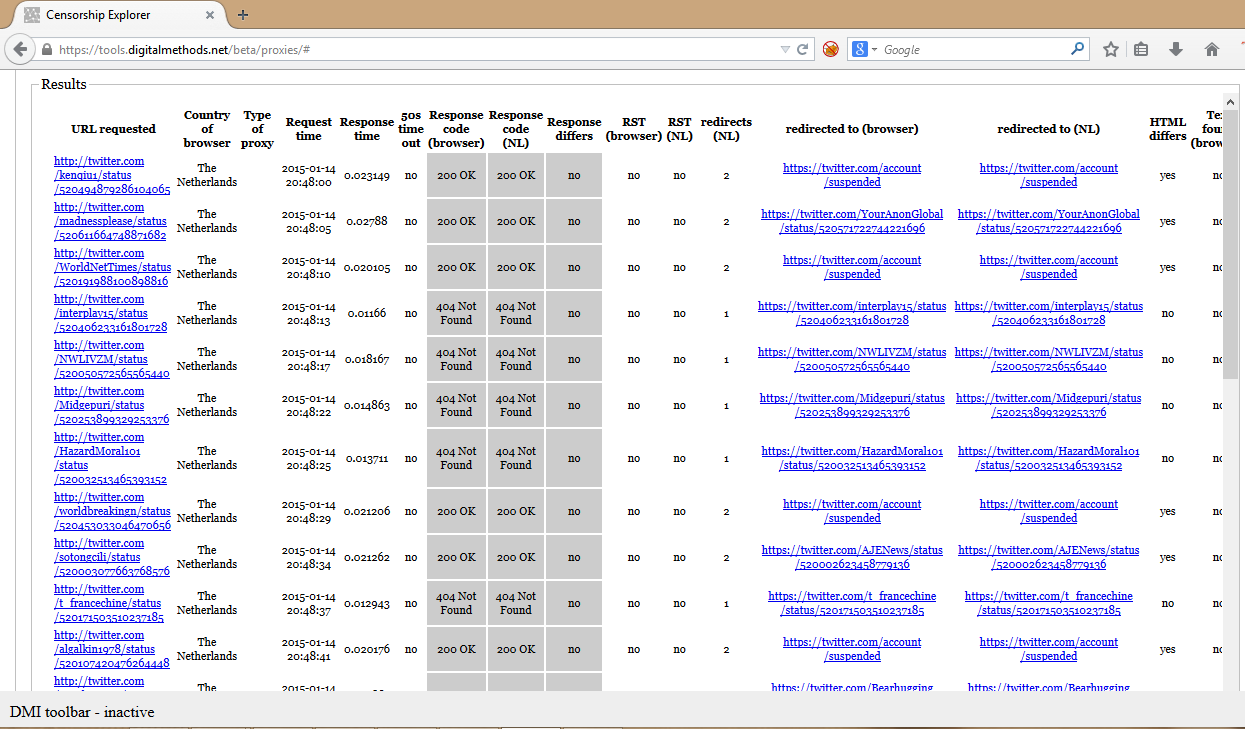
Figure 4: Censorship Explorer result page
As a next step, we exported the data from the tool to a .csv file, from where we could conduct a further analyses. Here, our main aim is to find out what this group of missing tweets consists of. Were tweets or user profiles temporarily suspended, completely removed, or were they still online? Moreover, what narrative can we construct from these missing URLs?
Firstly, we calculated the number of URLs with a '200 OK' response message. These URLs still provide an online result and might thus not be completely removed from Twitter. URLs that returned a '404 Not Found' response code refer to broken links. These should have been deleted by the TCAT Streaming API. Secondly, we looked into the different types of '200 OK' URLs. We paid special attention to redirects and examined to what type of URLs they redirect.3. Findings
3.1. Part A - Metrics and Statistics
3.1.1. Hashtag analysis
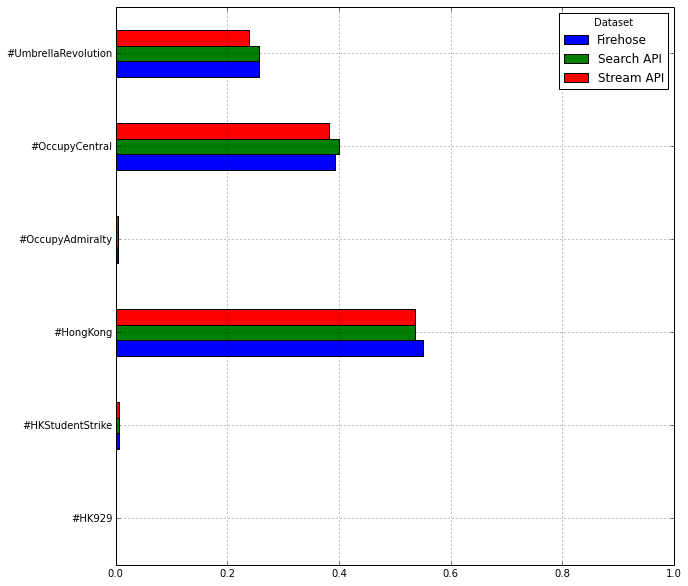
In the table below (see figure 5), the popularity of the six different hashtags is displayed per API. We see here that there are differences, but there are no major deviations.
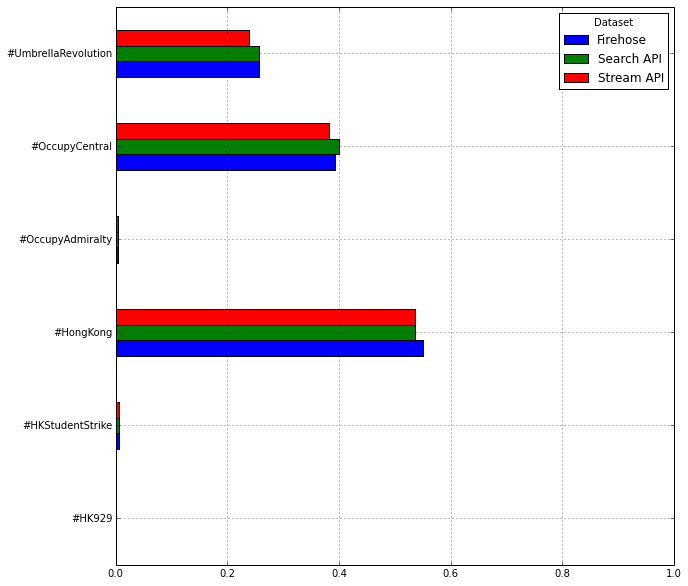
Figure 5: Popularity of the six different hashtags across the three different APIs, displayed in percentages
3.1.2. Top mentions results
Color: heat scale - red represents the most mentioned user, blue the least mentioned user
Nodesize: number of tweets mentioning the user
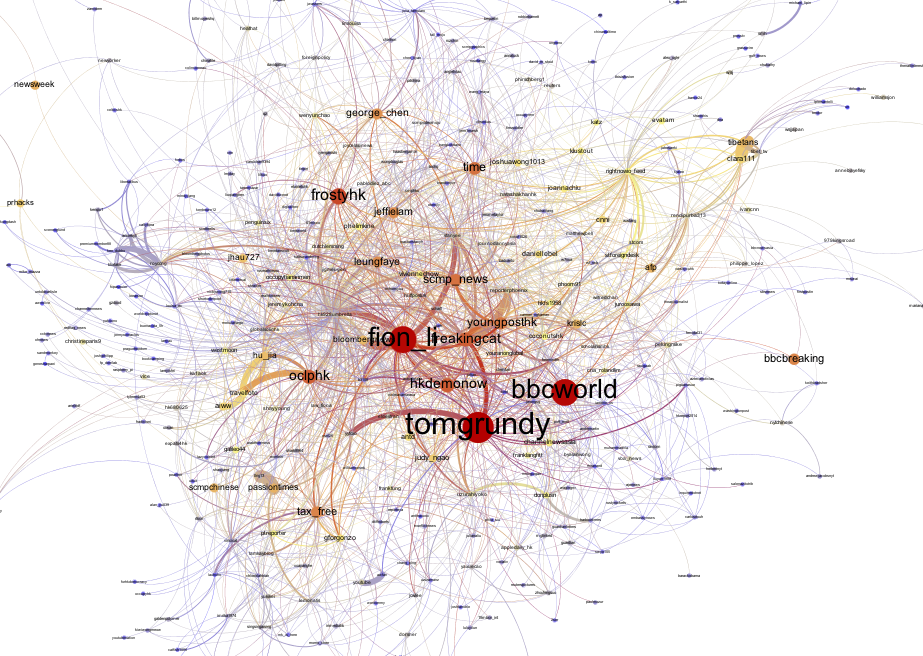
Edgesize: amount of mentions from user to user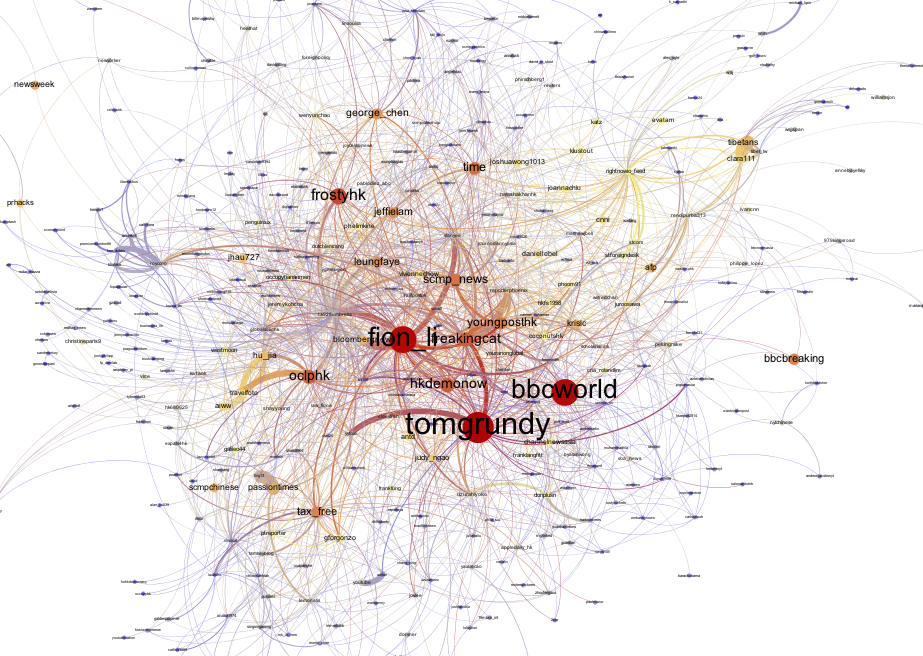 Figure 6: Visualization of the Search API top 500 mentions, closeup
Figure 6: Visualization of the Search API top 500 mentions, closeup
3.1.3. Stream API top mentions visualization
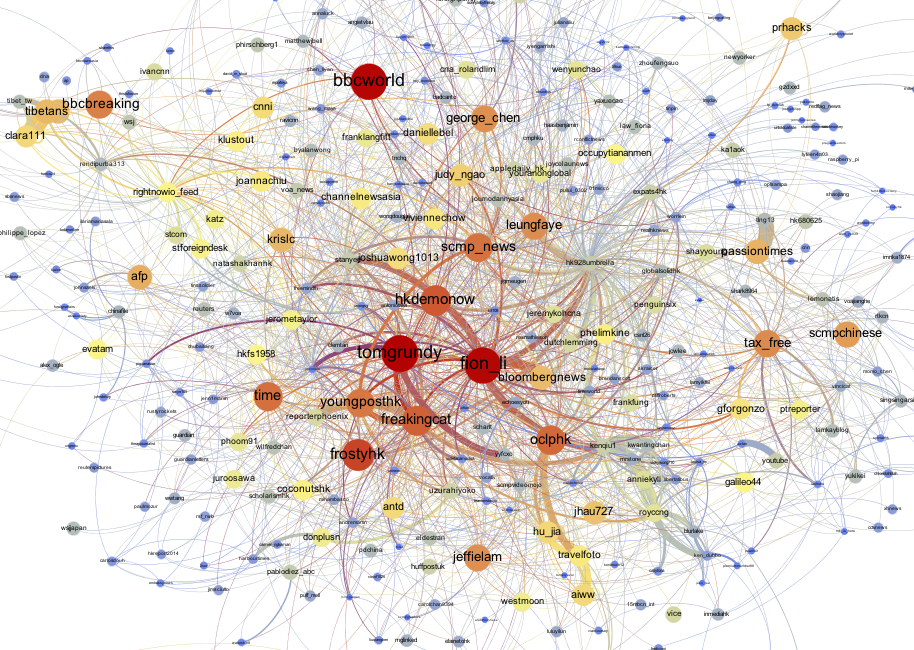
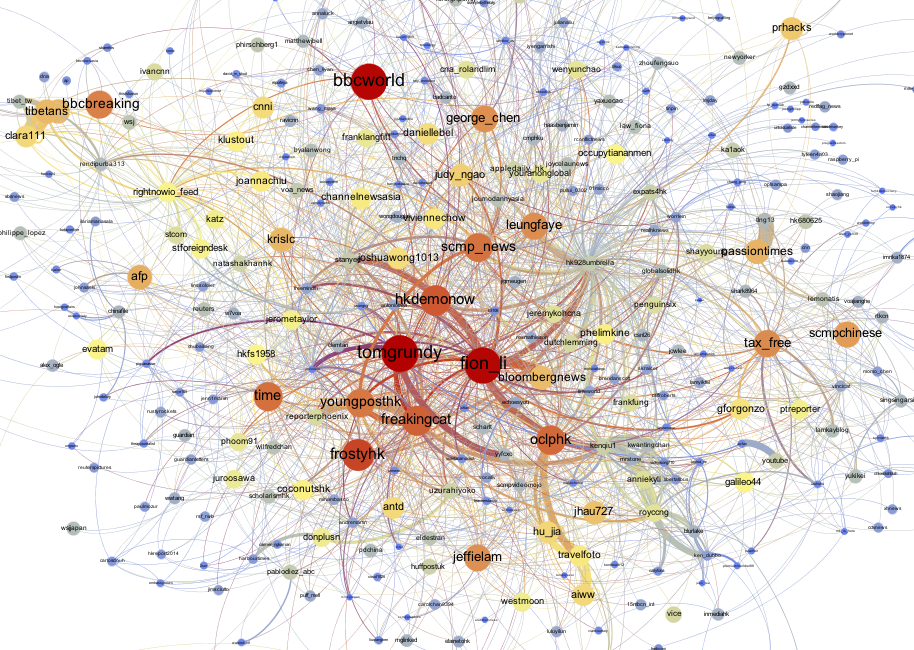 Figure 7: Visualization of the Stream API top 500 mentions, closeup
Figure 7: Visualization of the Stream API top 500 mentions, closeup
3.1.4. Most mentioned users according to Stream API
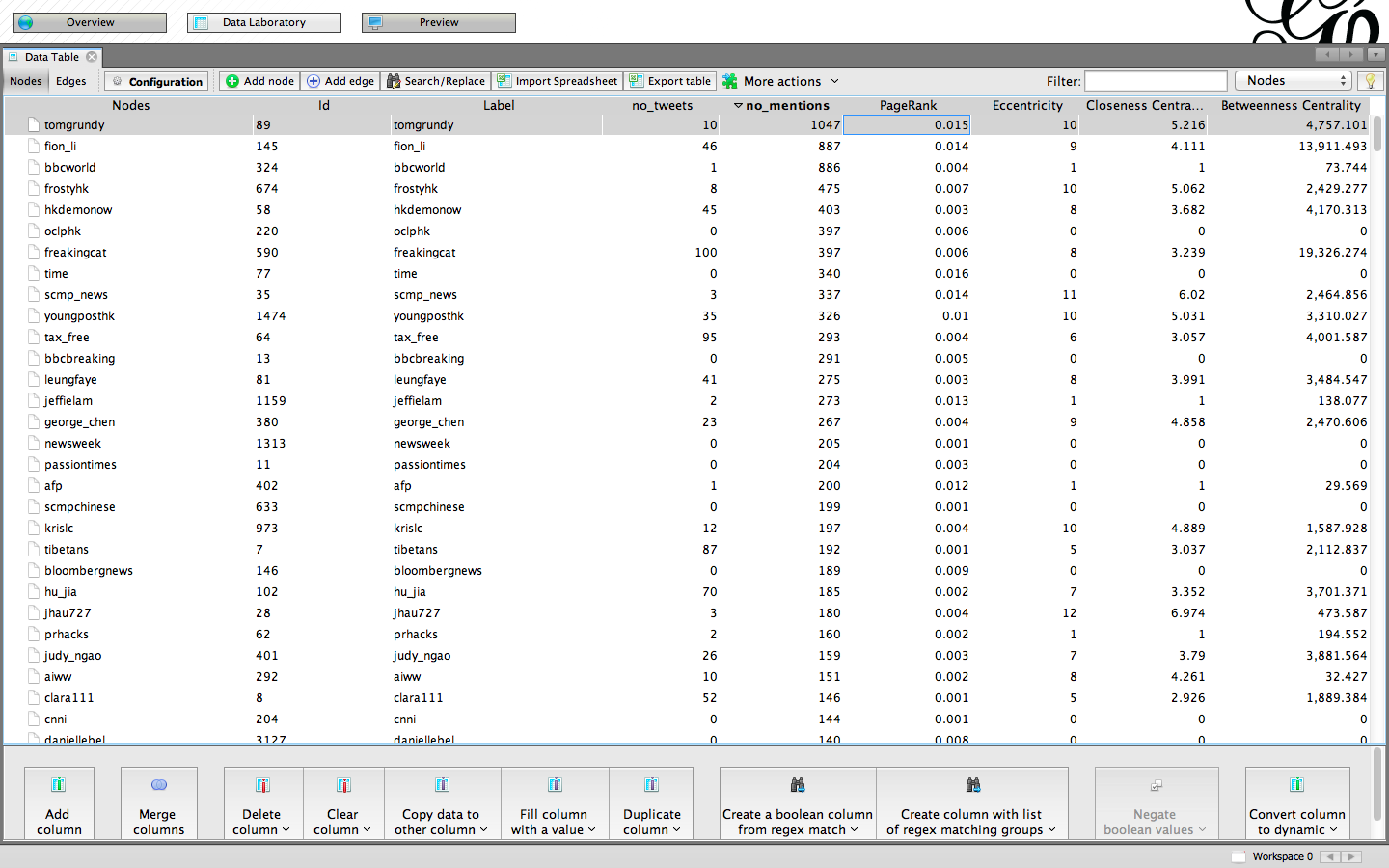
We examined the results of the Stream API and Search API datasets in Gephis Data Laboratory view. The overview showed us that according to the Stream API, the top three most frequently mentioned users were tomgrundy, who was mentioned 1109 times, fion_li, who was mentioned 949 times, and finally bbcworld with 943 mentions. Following in the top ten most frequently mentioned users are frostyhk, hkdemonow, oclphk, freakingcat, time, scmp_news and youngposthk with 513, 439, 411, 385, 366, 355, and 343 mentions respectively (see image 7.1).
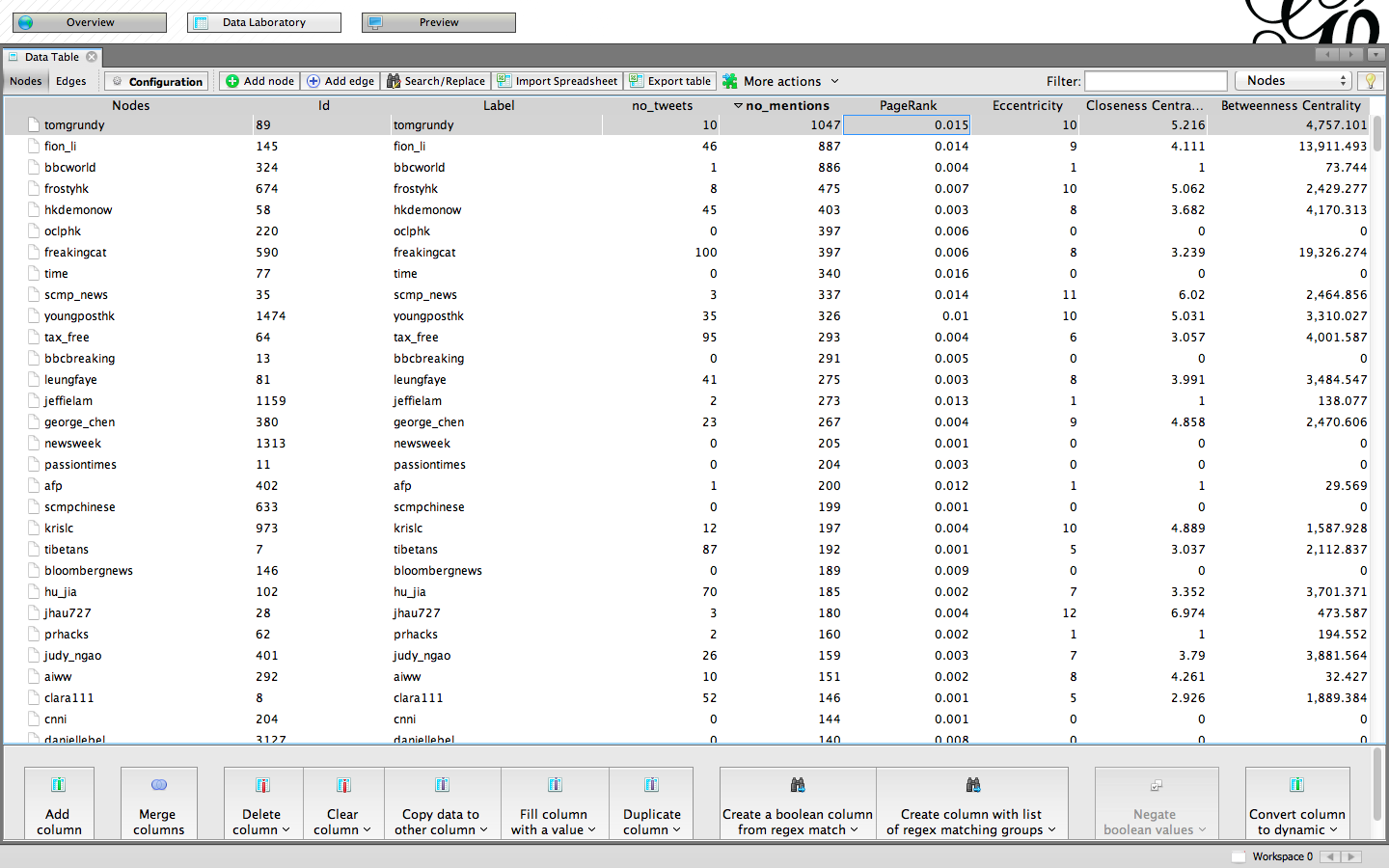
Figure 8: Most frequently mentioned users according to Stream API in Gephi's Data Laboratory
3.1.5. Most mentioned users according to Search API
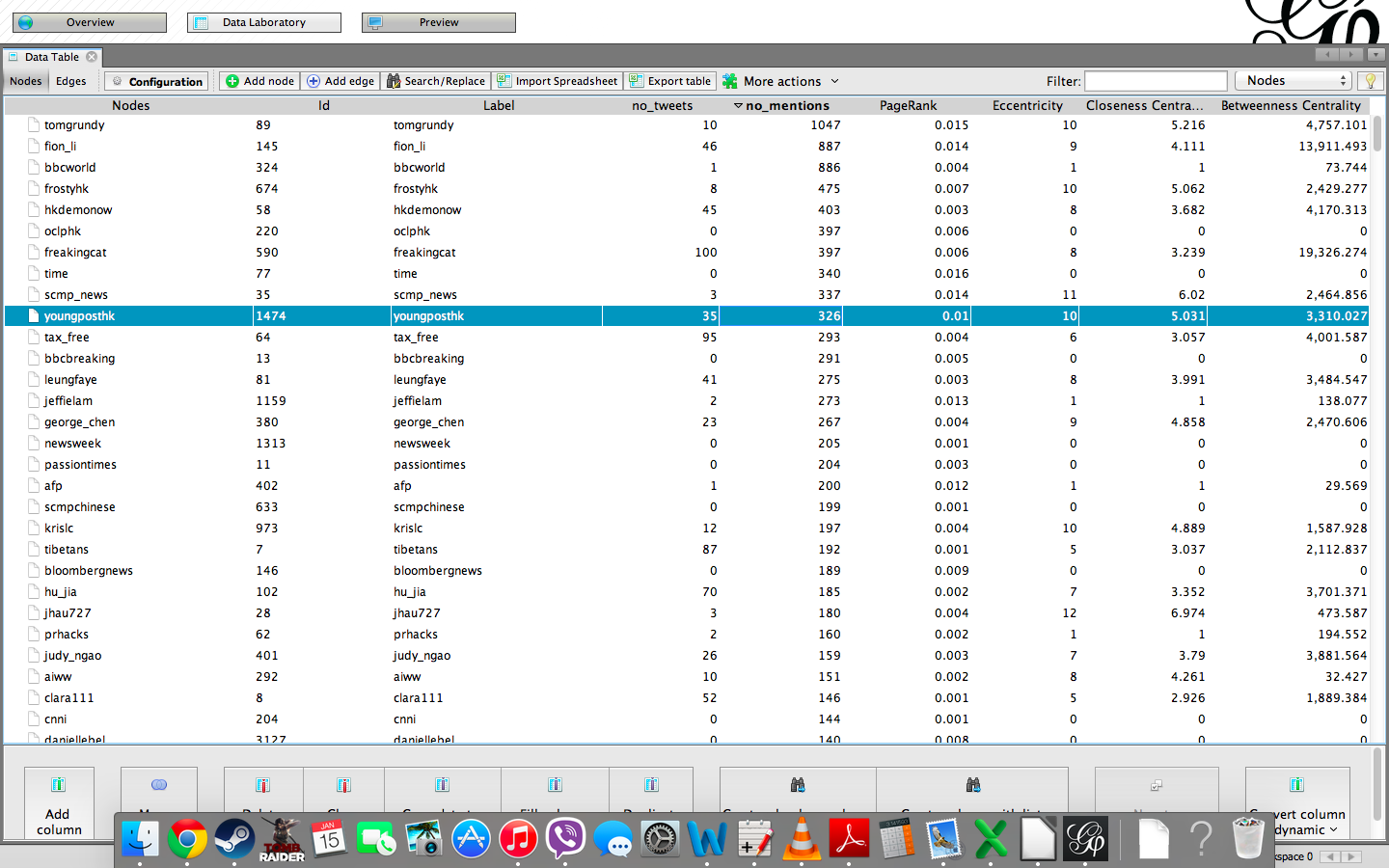
The Search API dataset was examined in the same regard as the Stream API. We observed the top ten list and identified that the results are similar, however not identical. Usernames and their order are the same, but the number of mentiones slightly changed. The top three positions remain unchanged the most mentioned user is tomgrundy with 1047 mentions (67 less than found by Stream API), fion_li was mentioned 887 times (62 less than in Streaming) and bbcworld 886 times (57 less than in Streaming). The remaining top ten mentioned users are frostyhk, hkdemonow, oclphk, freakingcat, time, scmp_news, and youngposthk with 475, 403, 397, 397, 340, 337 and 326 mentions respectively (see figure 9).
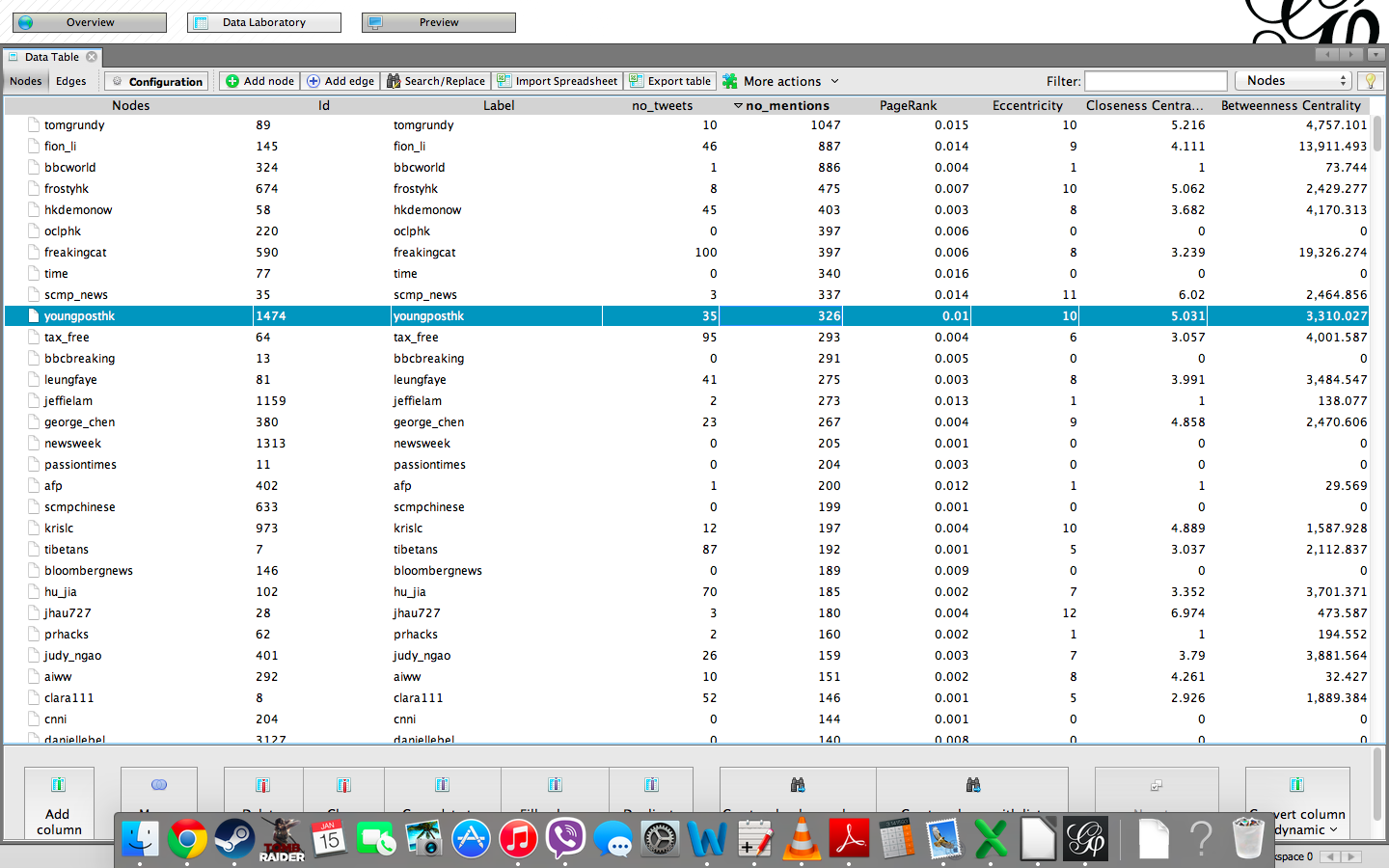
Figure 9: Most frequently mentioned users according to Search API in Gephi's Data Laboratory
3.1.5. Most mentioned users according to Firehose API
The Firehose dataset was not extracted from the TCAT tool. We had to examine two tables in order to get sufficent results. The first file contained the relations between the users posting and mentioning users. The second file contained the top 500 mentions count and it was the one examinated.
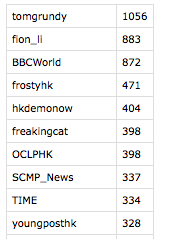
The Firehose dataset contained the same top users as the Stream API and Search API datasets but in a different order. According to Firehose, the most frequently mentioned user was tomgrundy with 1056 mentions. The second most frequently mentioned user was fion_li with 883 mentions and the third was BBCWorld with 872 mentions. Following in the top 10 were frostyhk, hkdemonow, freakingcat, OCLPHK, SCMP_News, TIME, and youngposthk with 471, 404, 398, 398, 337, 334, and 328 mentions respectively.
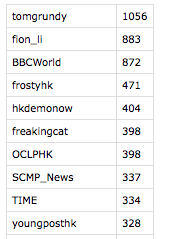
Figure 10: Most frequently mentioned users according to FirehoseAPI
3.1.6. Findings overview part A.
From the extracted results we observed that the examined datasets contained the same results considering the top users. In all of the sets, three top mentioned users were the same; tomgrundy, fion_li and bbcworld. The numbers of mentions differ per dataset. The order of the top results (ranking 4-10), however, are the same across the different APIs. It is argueable, that the differences between the APIs appear due to the usage of different extraction algorithm. However also in the case where we used the same algorithm, TCAT, inconsistency of results is present. Bias between the datasets is noticeable and due to variations between the datasets top results, we suggest that all of the results should be taken into the consideration in order to make one conclusive list of top mentioned users.
3.2. Findings Part B - Exploring the nature of bias
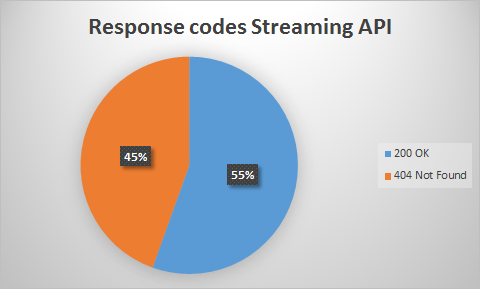
From our total of 301 tweet URLs from the streaming API, 167 URLs returned a response code of '200 OK' and 134 URLs returned a '404 Not Found' code (see figure 11). A pie chart with the differences in percentages can be found in figure 12.

Figure 11: Response codes of sample of Streaming API
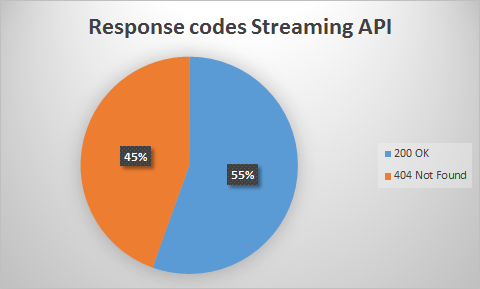
Figure 12: Percentages of response codes for the streaming API.
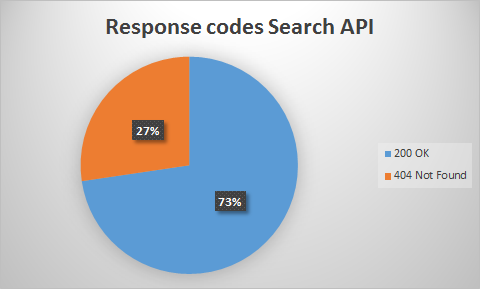
For the search API, we retrieved similar results, as is shown in images 10 and 11. One can see that the percentage of 200 OK results is higher for the search API than for the streaming API.

Figure 13: Response codes of sample of search API
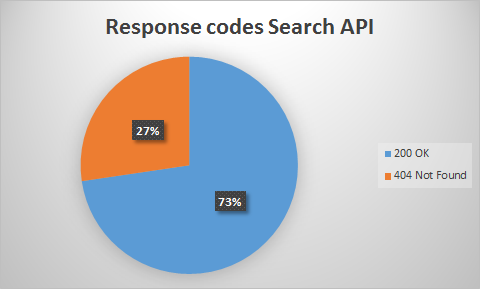
Figure 14: Percentages of response codes for the search API
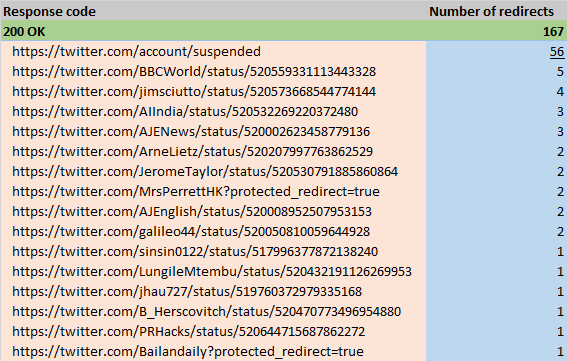
Within our section of '200 OK' results, we counted how many of those URLs redirected to a different URL. The Censorship Explorer showed that all of the URLs with the '200 OK' response code were actually redirected. To find out why they were being redirected, we looked at the messages of the Censorship Explorer. Figure 15 displays a sample of the most frequent redirects. As one can see there is that the URL sometimes shows the reason for redirection, such as suspended or protected. The column Number of redirects show the frequency another URL has been redirected to the URL in the first column (200 OK). What can be drawn from this is that for instance the second URL from BBCWorld from the streaming API has been retweeted at least 5 times. As all URLs had at least 1 redirect, we know that in this case, all URLS with response code 200 OK are redirects. What we moreover established is that the URLs with 1 redirect were in fact retweets.
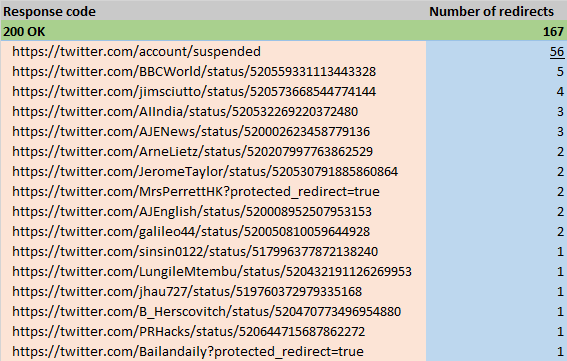
Figure 15: Most frequently redirected '200 OK' URLs
Different types of '200 OK' URLs that have been redirected. This is an image of the results from the streaming API. Note that 56 URLs redirect to a URL that shows that the account has been suspended.
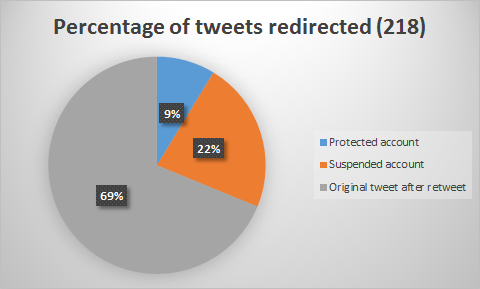
A summary of these findings for the Streaming and Search API is displayed in images 16, 17, 18 and 19. It shows where all tweets have been redirected to, i.e. the page of a suspended account, protected account or a redirect to the original tweet.

Figure 16: Types of redirects - streaming API

Figure 17: Types of redirects - search API

Figure 18: Percentages of different types of redirects in Streaming API
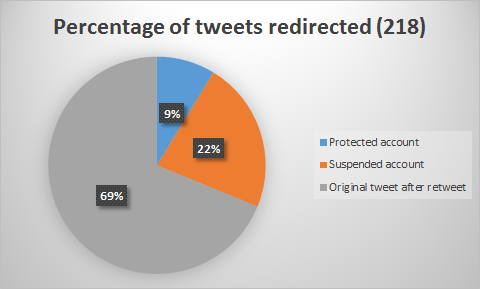
Figure 19: Percentages of different types of redirects in Search API
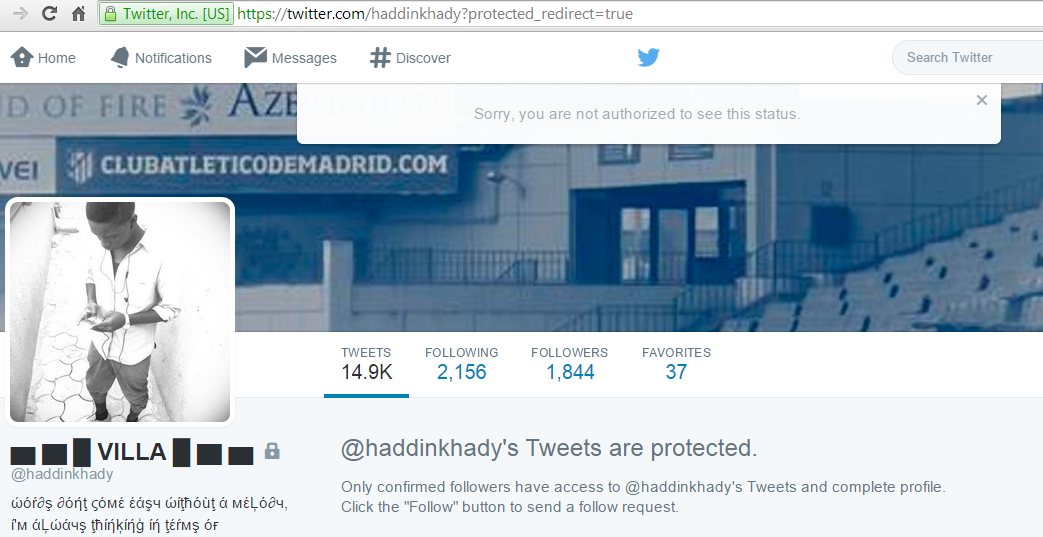
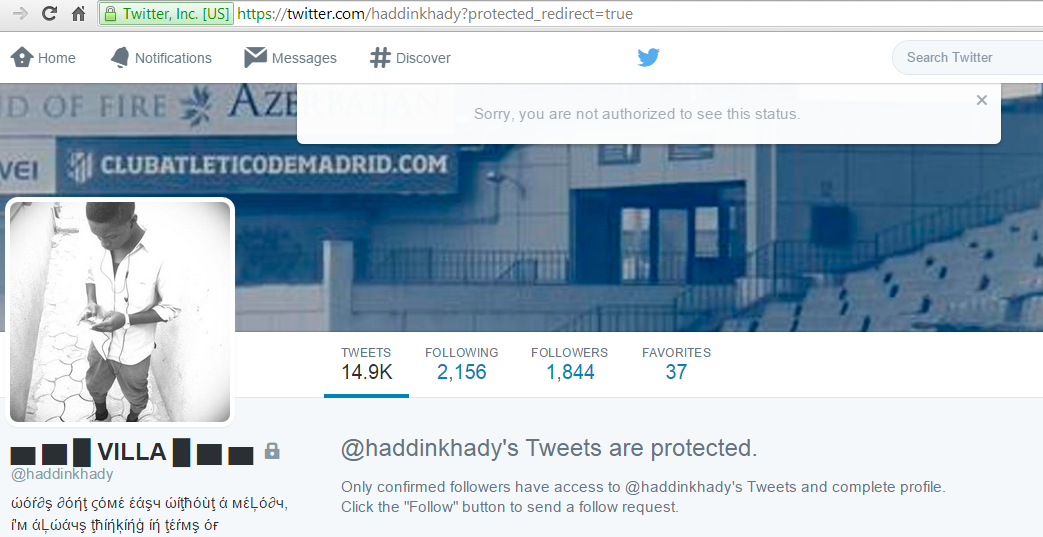
Figure 20: Example of accounts that have been suspened
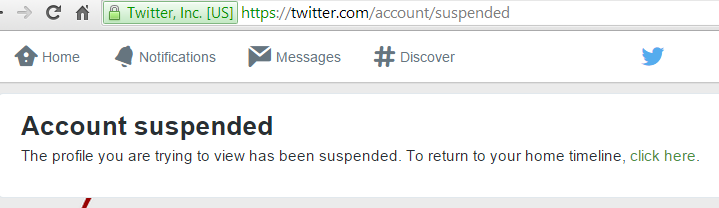
Figure 21: Example of accounts that have been suspened
4. Discussion
The aim of our research was to examine to what extent we could identify a problematic bias across different Twitter APIs and, if so, whether it would be possible to find out more about the nature of this bias. Our initial metrical analysis of mentions and hashtags showed that no major differences could be identified. One could argue that it nonetheless represents a bias, as the datasets were - as could have been expected - not completely identical. However, we argue that since the top mentions and top hashtags were the same across the different APIs, this bias is not necessarily problematic. Yet, as Twitter is increasingly used as a dataset, it is important to take note of any differences, minor or not. While dataset deviations can always be part of research, it is important for social research through Twitter data to have knowledge about the nature of these differences. We would therefore argue that even though our metrics have not proven any intentional bias, it has opened space for researchers to further investigate the implications of choosing a certain type of API to work with.
One important finding is that the datasets of the streaming and the search API were larger than the dataset of the Firehose API, while this should have been the complete archive. By checking the URLs for response codes, we were able to map some of the specific features of this group of URLs. This is particularly interesting, because it reveals some of the information that is generally conceived as part of a black box. By extracting the mismatches between the streaming and Firehose API, we have constructed a narrative on what is missing, rather than what is shown. While some of the causes for the deviating datasets cannot be explained, there are some conclusions we can draw from this.
1. Firstly, our samples of the Streaming and the Search API showed that respectively 45 percent and 27 percent of the URLs were broken, marked by a 404 Not Found response code. According to Twitters terms of service, those URLs should have been deleted from the datasets. This would mean that, as those tweets were not deleted, TCAT did not meet Twitters terms of service. Yet, the way the streaming and search API function is by capturing online tweets, which means that they are collected legally. When tweets are being deleted afterwards, TCAT does not receive any notifications. As such, it is not possible for TCAT to delete those tweets from the dataset.
2. Secondly, we found that all of the working URLs were actually working because they are being redirected. These URLs were retweets, which shows that retweets from the Streaming API were captured, while it seems that those were not included in the Firehose dataset. The reason for this difference remains unclear. It could be an artefact of the softwares different scraping methods. The Streaming API might capture retweets as separate URLs with a unique address, while the Firehose might treat retweets as part of the original tweet and therefore not log them as a unique tweet. Another option is that the Firehose API did record the retweets, but that our dataset is lacking these tweets. Because the Firehose data was acquired indirectly, errors could have emerged during this process. It is for instance possible that the file has been read incorrectly due to formatting issues.
3. We have established a method by which one can gain insight in the number of tweets being deleted (either by users or others) and the number of accounts that are protected or have been suspended. In times of a political event, such as the Hong Kong protests, these numbers are extremely valuable and call into question the advocacy of using the Firehose API as opposed to the Streaming API. It would be interesting to find out more about these users, or the content of those tweets. This would require further research, but this analysis is a starting point in bringing up data that was previously out of sight.
What we can learn from this is that one should not use any data, even Firehose, naively. Even if the data deviations were not created on purpose, it questions the reliability of APIs. It should be admitted that we cannot determine with certainty that either Firehose or TCAT is responsible for the dataset differences. Our findings can be valuable for other researchers who are working with large datasets, as they might run into similar issues. Therefore, without blaming any party on dataset deviations, one should be cautious in treating any dataset as truth. Another implication we can derive from this research is that missing data might be very useful, because it gives more information about that which is not visible directly online. Knowing how many accounts were suspended can be very valuable for social and political research. This information might be hidden underneath the dataset surface, but can be retrieved by looking more closely at the missing data. We would conclude by stating that statistically speaking, there is a bias, because the datasets show deviations. We cannot, however, determine whether this bias is problematic or not, because we do not have enough information on the nature of the bias. It is therefore impossible to know if deviations occurred intentionally or not. What we do know is that the data lacking in Firehose can be very useful. Hence, it would be beneficial to further examine the missing data. This research would furthermore benefit from a more extensive statistical research that would include the complete period of the research, rather than just the 9 and 10 October 2014.
Overall, we believe that the Streaming API is the most useful resource when following a protest on Twitter. If one manages to stay under the 1 percent data limit and start the streaming with good timing, one is likely to receive a very complete dataset. As the missing data from Firehose shows, it might be equally - or even more - practical to take the Streaming API as a leading source. It is furthermore less costly to obtain data from the Streaming API than from Firehose, and therefore it can be preferable for researchers to use this dataset. As the Search API states that it returns random data, the Streaming API is most likely more reliable. Nonetheless, the deviations in the different datasets stress the need to be cautious in taking any dataset for granted. While a bias does not necessarily have to occur intentionally, it is always important to realize that your source might influence your results. As such, we hope that further research will be done in discovering more information about API bias.
5. Limitation
A limitation we encountered during this research is that TCAT captured a set of tweets only containing #HongKongProtests, without any of the six key hashtags. We identified those tweets and removed those from our dataset before employing metrics or analyses. It is possible that other wrong tweets were collected by TCAT, however, we believe this number was very low and therefore not significant to our research.
6. Bibliography
About.twitter.com,. 'About Twitter, Inc. | About'. N.p., 2015. Web. 18 Jan. 2015. Alexa.com,. 'Alexa Top 500 Global Sites'. N.p., 2015. Web. 17 Jan. 2015. BrightPlanet,. 'Twitter Firehose Vs. Twitter API: WhatS The Difference And Why Should You Care? - Dataasaservice - Brightplanet'. N.p., 2013. Web. 18 Jan. 2015. Dastagir, Alia E., and Rick Hampson. 'Hong Kong Vs. Tiananmen: Social Media Fuel 'Umbrella Revolution''. USA Today 2014. Web. 18 Jan. 2015. Dev.twitter.com,. 'FAQ | Twitter Developers'. N.p., 2015. Web. 18 Jan. 2015. DRISCOLL, KEVIN, and SHAWN WALKER. 'Working Within A Black Box: Transparency In The Collection And Production Of Big Twitter Data'. International Journal of Communication 8 (2014): 1745-1764. Web. 16 Jan. 2015. Fern Tay, Huey. 'Hong Kong Student "Umbrella Revolution" Movement Takes To Social Media To Separate Fact From Fiction In Pro-Democracy Protests'. ABC News 2014. Web. 18 Jan. 2015. Freedomhouse.org,. 'Background On Hong KongS Quest For Democracy | Freedom House'. N.p., 2015. Web. 16 Jan. 2015. Gonzalez-Bailon, Sandra et al. 'Assessing The Bias In Communication Networks Sampled From Twitter'. SSRN Journal n. pag. Web. Greenwood, Phoebe, and Richard Sprenger. 'Hong Kong Protests: A Social Media Revolution Video'.the Guardian. N.p., 2015. Web. 18 Jan. 2015. Morstatter, Fred et al. 'Is The Sample Good Enough? Comparing Data From TwitterS Streaming API With TwitterS Firehose'. International Conference On Weblogs And Social Media. AAAI, 2013. 400-408. Web. 16 Jan. 2015. Morstatter, Fred, Jürgen Pfeffer, and Huan Liu. 'When Is It Biased?: Assessing The Representativeness Of Twitter's Streaming API'. WWW Companion '14. International World Wide Web Conferences Steering Committee Republic and Canton of Geneva, Switzerland ©2014, 2014. 555-556. Web. 16 Jan. 2015. Twitter.com,. 'The Search API'. N.p., 2015. Web. 18 Jan. 2015.

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
1.png | manage | 15 K | 18 Jan 2015 - 18:02 | OskarStrajn | |
| |
10.png | manage | 19 K | 18 Jan 2015 - 18:14 | OskarStrajn | |
| |
11.png | manage | 1 K | 18 Jan 2015 - 18:15 | OskarStrajn | |
| |
12.png | manage | 22 K | 18 Jan 2015 - 18:15 | OskarStrajn | |
| |
13.png | manage | 2 K | 18 Jan 2015 - 18:16 | OskarStrajn | |
| |
14.png | manage | 21 K | 18 Jan 2015 - 18:16 | OskarStrajn | |
| |
15.png | manage | 21 K | 18 Jan 2015 - 18:16 | OskarStrajn | |
| |
16.png | manage | 2 K | 18 Jan 2015 - 18:17 | OskarStrajn | |
| |
17.png | manage | 2 K | 18 Jan 2015 - 18:17 | OskarStrajn | |
| |
18.png | manage | 27 K | 18 Jan 2015 - 18:18 | OskarStrajn | |
| |
19.png | manage | 24 K | 18 Jan 2015 - 18:18 | OskarStrajn | |
| |
2.png | manage | 8 K | 18 Jan 2015 - 18:03 | OskarStrajn | |
| |
20.png | manage | 450 K | 18 Jan 2015 - 18:20 | OskarStrajn | |
| |
21.png | manage | 14 K | 18 Jan 2015 - 18:21 | OskarStrajn | |
| |
3.png | manage | 66 K | 18 Jan 2015 - 18:03 | OskarStrajn | |
| |
4.png | manage | 95 K | 18 Jan 2015 - 18:04 | OskarStrajn | |
| |
5.png | manage | 20 K | 18 Jan 2015 - 18:27 | OskarStrajn | |
| |
6.png | manage | 656 K | 18 Jan 2015 - 18:07 | OskarStrajn | |
| |
7.png | manage | 869 K | 18 Jan 2015 - 18:09 | OskarStrajn | |
| |
8.png | manage | 196 K | 18 Jan 2015 - 18:12 | OskarStrajn | |
| |
9.png | manage | 287 K | 18 Jan 2015 - 18:13 | OskarStrajn |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback