Cross-lingual Art Spaces on Wikipedia
Sub-group members: Sangeet Kumar, Garance Coggins, Sarah
McMonagle, Stephan Schlögl, Han-Teng Liao, Michael Stevenson, Federica Bardelli, Anat Ben-David
Introduction
This project seeks to interrogate the world wide web’s claim to global representativeness through the prism of Wikipedia.
The Internet promises opportunities to transcend cultural, national and linguistic boundaries. We ask whether such promise is realised through the example of Wikipedia which, comprising the world's largest user-generated content (also encyclopedia), is a fitting case study for investigation. Within Wikipedia, we focus exclusively on the topic of "art" as a specific case for analysis. As a universal abstract concept, "art" possesses multiple local, cultural and linguistic articulations. We therefore explore how "art" is represented across different language versions of Wikipedia, using digital methods to analyze both visual and hyper-textual elements.
Method and Data Collection
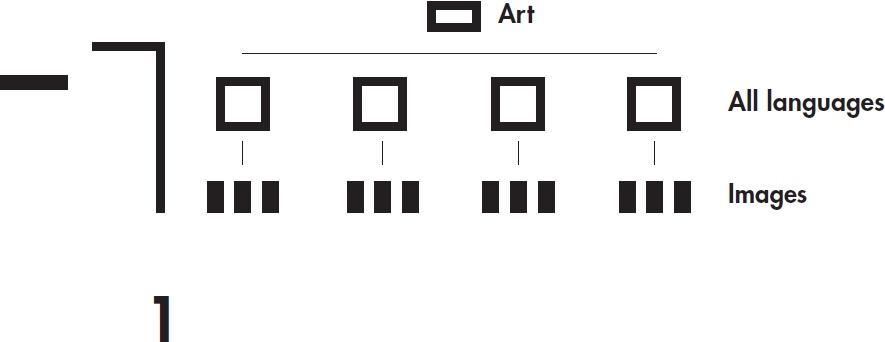
Focusing on identifying the universal and specific elements, the data collection includes two types of content: (a) images and (b) concepts (or strongly related articles) used in the article page of "Art".Since the image collection does not require language expertise for analysis, we collect all the available language versions (154 in total) for research. Because the concept analysis requires language expertise, we gathered just eight language versions of "art" that reflect the language skills in our research group. They are Chinese, Dutch, English, French, German, Hindi, Irish and Swahili (ordered alphabetically).
| Data Set 1 (Image Sharing) |
|
Data Set 2 (Concept Sharing) |
 |
|
 |
|
|
Data Set 1 (Image Sharing)
The DMI cross-lingual image analysis tool allowed us to collect the image data in a straightforward way. However, certain challenges arose when images which might be considered "identical" appeared in different sizes and/or versions.
| Steps |
Actions |
Outcomes or Memos |
| 1. |
Using the DMI tool "Wikipedia Cross-Lingual Image Analysis" (See ToolWikipediaCrosslingualImageAnalysis, thereafter cross-lingual image tool), we retrieve all language versions for the article "Art".The process is straightforward and one only needs to provide the url such as http://en.wikipedia.org/wiki/Art to retrieve the data outcome, which can also be downloaded as tab separated file for further data "massage" and analysis. |
** The data outcome provided by the DMI cross-lingual image tool can be found here: http://users.ox.ac.uk/~kebl3178/CrossLingualArtSpacesOnWikipediaDataRaw1.html |
| 2. |
Using the filenames of the images as the main clue for whether two images are the same, we use simple and straightforward regular expression-based computer scripts to identify the same images, whatever their image sizes are. (Thus, regardless the image size differences, two articles that share the main filenames in their referenced images will be considered to be sharing the same image.) |
We tentatively call this process "image reference disambiguation" , a process that requires further improvement for future research |
| 3. |
The produced table of "language-image" reference connections thus constitute a two-mode network (aka bi-partite network) for further visualization and analysis. |
Future work can be done by using further network analysis methods for two-mode network such as blockmodelling analysis |
| 4. |
Using Gephi, the bi-partite network of "language-image" reference connections are visualized. |
See "Findings" |
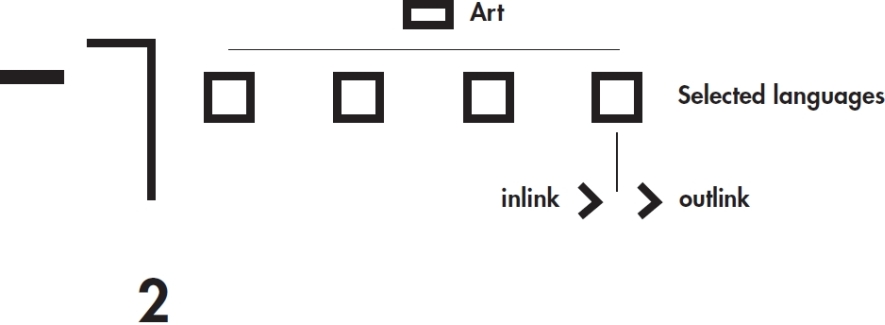
Data Set 2 (Concept Sharing)
The data collection for concept sharing has been made easier with the available Wikidata that provides a list of language names for the same concept/topic, a process that we call "concept reference disambiguation". However, the DMI tool
ToolCompareLists is not enough for our purpose in using Wikidata pages for "concept reference disambiguation". We need to either manually process the data or write some additional computer script to identify whether a concept is shared by two language versions of Wikipedia.
| Steps |
Actions |
Outcomes or Memos |
| 1. |
Using the DMI tool "Link Ripper" (See ToolLinkRipper), we first retrieve the internal links (outlinks) for the selected language versions for the article "Art". For English version, it means extracting internal links from the page http://en.wikipedia.org/wiki/Art |
A list of internal links (outlinks) for each language version on "Art". |
| 2. |
Using the DMI tool "Link Ripper" again (See ToolLinkRipper), we then retrieve the internal links (inlinks) for the selected language versions for the article "Art". For English version, it means extracting internal links from the page http://en.wikipedia.org/wiki/Special:WhatLinksHere/Art (alternatively click on the "What links here" in the toolbox at Wikipedia pages to the left. |
A list of internal links (inlinks) for each language version on "Art". |
| 3. |
To ensure the related concepts are considered (by each language version) to be strongly-associated concepts, we only consider the internal links that are bi-directional, i.e. have both outlinks and inlinks. For this, we use the DMI tool "Compare Lists" ( ToolCompareLists) to identify the related Art articles in individual language versions that not only are linked by the article "Art" (from step 1), but also link to the article "Art" itself (from step 2). |
A list of "strongly-connected" Art-related articles for each language version on "Art" |
| 4. |
Using Wikidata's centralized page for the same concept across language versions, we identify the unique concept id defined by Wikidata for each strongly-related concept, through which we can advance the "concept reference disambiguation" process. |
A list of "strongly-connected" Art-related "concepts" (with unique yet centralized Wikidata ID) for each language version on "Art" |
| 5. |
The produced table of "language-concept" reference connections thus constitutes a two-mode network (aka bi-partite network) for further visualization and analysis. |
Future work can be done by using further network analysis methods for two-mode network such as blockmodelling analysis |
| 6. |
Using Pajek, the bi-partite network of "language-concept" reference connections are first transformed into a one-mode network of "language-language" similarity network, and then, using Gephi, the similarity network can then be visualized to show how many concepts are shared across languages. |
See "Findings" |
Findings
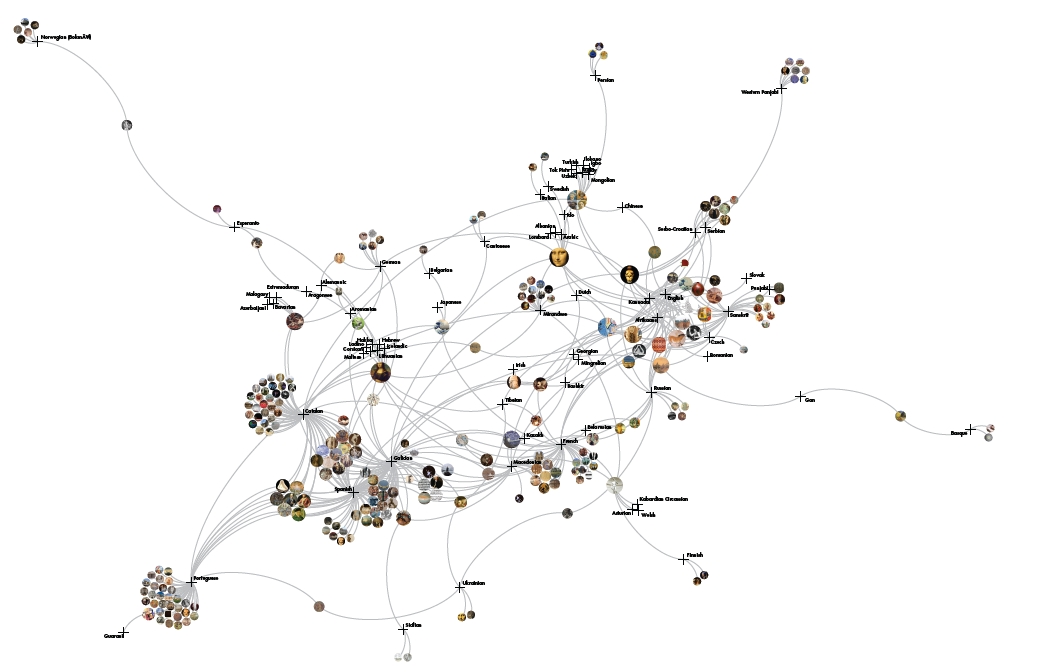
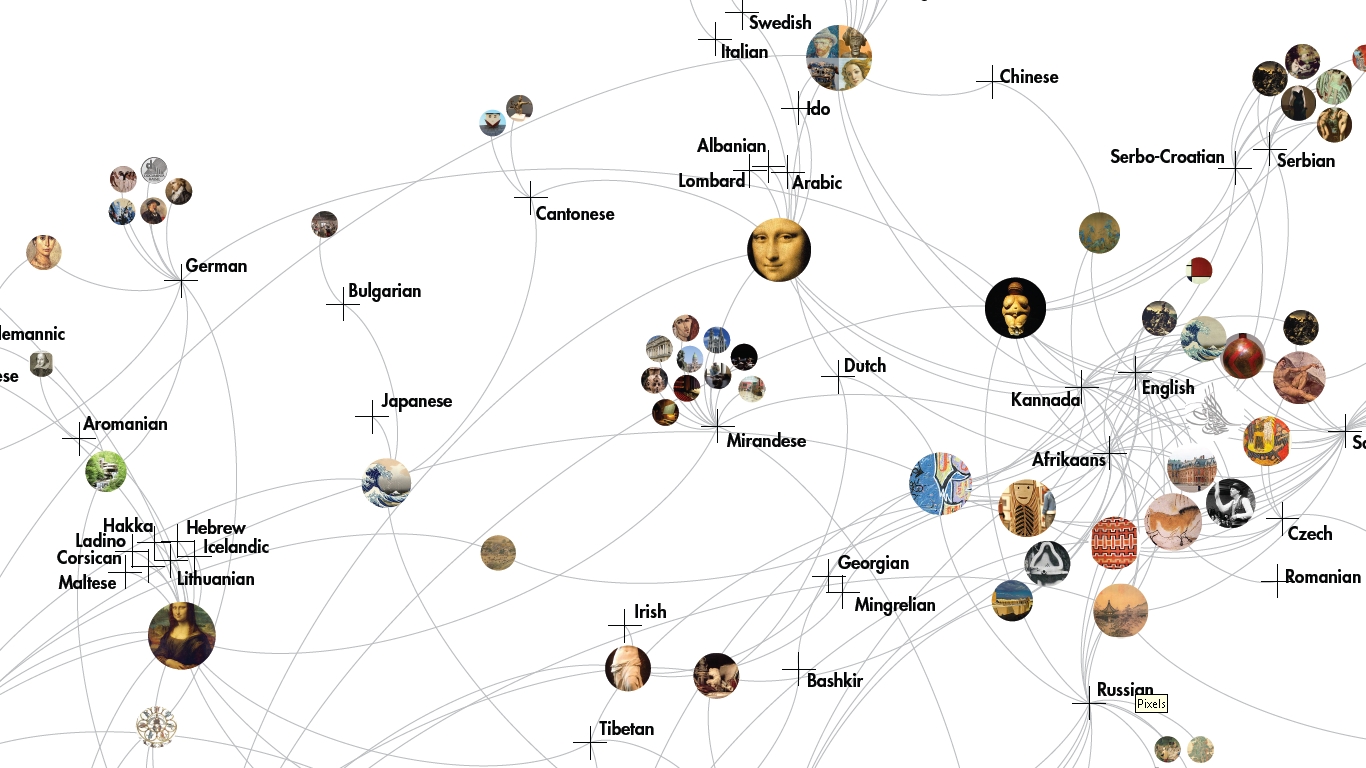
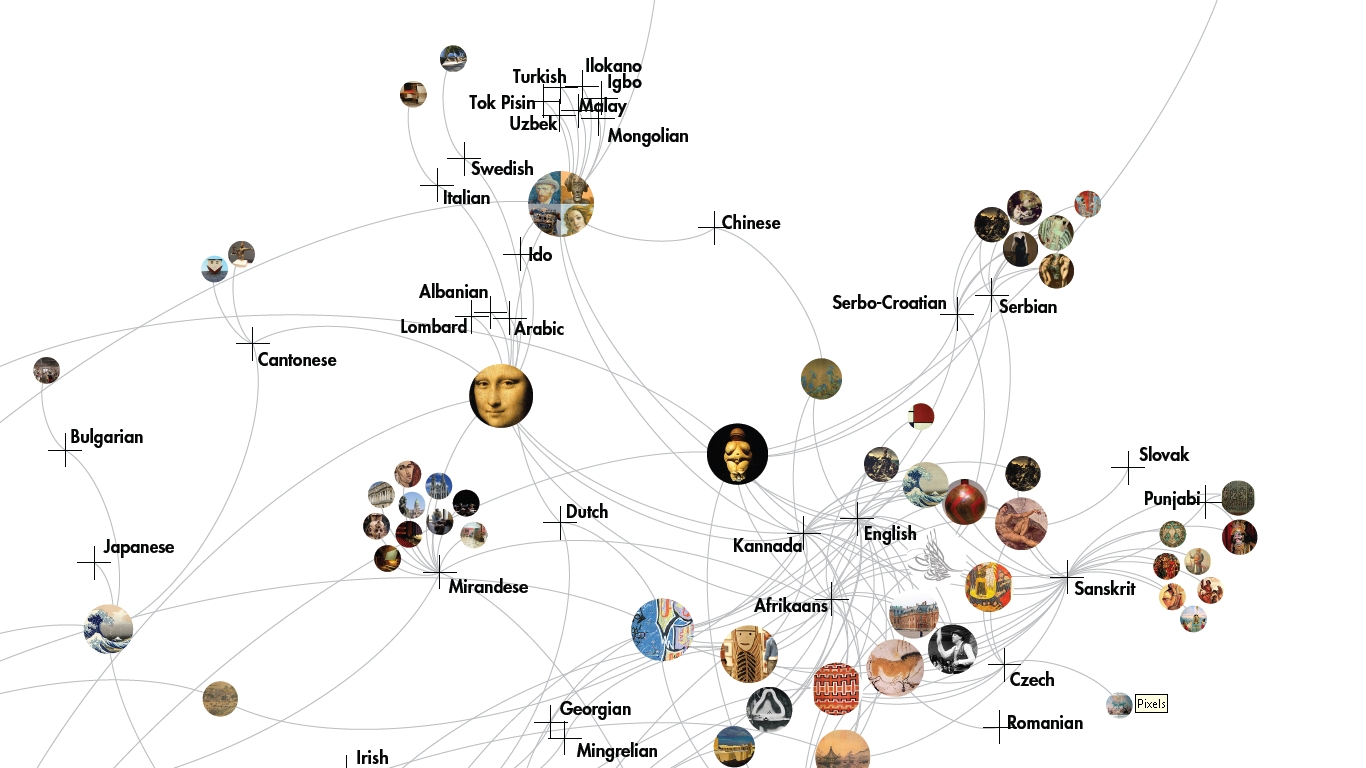
Image Networks: Relationship defined by sharing images or not
Overall, a variety of images are used across the language versions of "art" on Wikipedia, from prehistoric to contemporary times. However there are some discrepancies between the articles themselves: some are not illustrated at all, while others contain several images (see, for example, the "Iberian" cluster below). We observed that certain images are used across many articles. For instance, Mona Lisa is one of the most frequently appearing images across articles. For some languages, it is the only image (for example, the Icelandic, Corsican and Hebrew pages), and for others it appears alongside other images. Another image that we observed across langugae pages is a type of "collage" that comprises a self-portrait by Van Gogh, an African Chokwe Statue, a Japanese Shisa Lion and the Birth of Venus by Botticelli.
| Overall Network |
Network Core |
 |
 |
|
| Cluster: Iberian |
Cluster: Unknown |
 |
 |
|
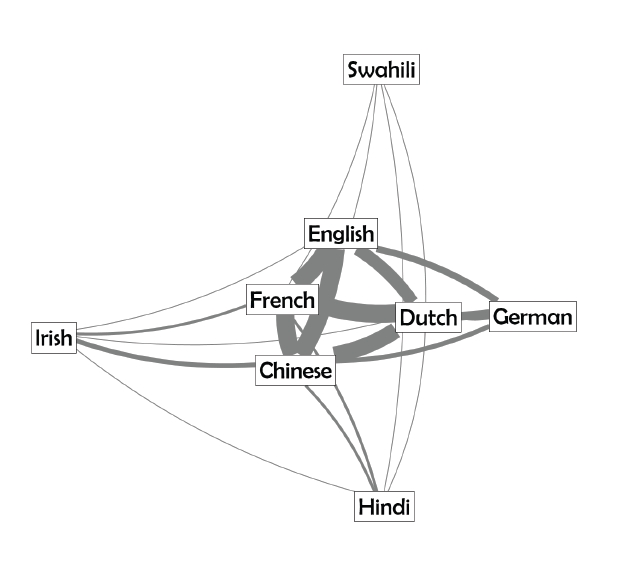
Concept Networks: Relationship defined by sharing concepts or not
Across the eight language versions of "art", some generalities appeared. All languages, for example, contained sub-topics on "dance", "art", "music" and "portal:arts". Some sub-topics were found to be unique, such as "cuisine" in the French-language page and "Metakunst" in the German version. Only the English-language article invited the linked question "What is art?"
Overall there are stark differences between the different language representations of "art" on Wikipedia, with the top tier language pages being significantly better developed than the so-called "smaller" languages. The most densely interconnected language pages were English, French, Dutch, German and Chinese.
Implications
Shared images and topics point to the the clear emergence of a core/periphery structure on Wikipedia whereby a few dominant images and languages are more densely connected than others. We cautiously conclude that images such as the Mona Lisa have become an "iconic" representation of art itself, while the aforementioned collage may be an iconic attempt at representativeness.Stronger relationships between different language versions of the article on "art" shows the proximity of these langauges to one another in the Wikipedia forum. Some languages are clearly better developed in Wikipedia, thus showing a greater presence and vitality.
Suggestions for Wikipedia Communities
- (General) Begin cross-cultural and cross-lingual conversations on art.
- (General) Advance the current discussion on language development for Wikipedia resources.
- (Specific to Hindi) Despite the Hindi language community's potential in terms of contributors and readers, the "art" article in Hindi is not as well-linked by other art-related articles. Hindi is under-performing according to our analysis. Some "wikification" efforts (i.e. providing more internal links to link back to the article "Art") will greatly improve the situation. Note that the Hindi version has under-performed in the "concept" network, especially when compared to the Chinese version. Both Hindi and Chinese belong to the categories of "100,000+ articles" in the tally of number of articles (see http://meta.wikimedia.org/wiki/List_of_Wikipedias ).
- (General research or data management) Provide better tools or APIs for accessing images hosted in Wikimedia Commons for "image reference disambiguation". It is relatively difficult to decide whether two images are essentially the same one.
- (General research or data management) Provide better tools or APIs for accessing concepts organised in Wikidata for "concept reference disambiguation". While very helpful for our research process, it will be much easier if a simple API is made available to produce the Wikidata unique ID based on a language version of encyclopedia entry.(e.g. API input: en:Art --> API output: Q735)
Suggestions for Future Research
- (General) Explore findings with a greater theoretical application. The "world knowledge dependencies" or "world knowledge system" using modernization theories of world-systems theory on the global Wikipedia projects, by expanding the sample topics from art to other topics such as science, technology, culture, government, etc.
- (General) Interrogate history and discussion pages on each article. Examine how editors argue for and against the inclusion of selected images.
- (General) Develop a more comprehensive language analysis with carefully justified sample set.
- (General) Examine and compare "unique" sub-topics per language article in order to avoid cultural/linguistic determinism in findings.
- (General) Explore the similarities and differences in sharing "images" and "concepts".


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}