Disinformation in anti-Eu Facebook groups
Team Members in alphabetical order
Aïchatou Sow
Berit Renser
Camille Godineau
Céline Chhun
Dagmar Götz
Esther Khinthazin
Freddie Carver
Giulio Valentini
Inês Narciso - Project coordinator
Jackie Ostrem
Jule Scheper
Julia Niemann-Lenz
Karen Pelletier
Laura Maria Huu
Martina Catte
Raïssa Muadi
Rémy Mallet
Sandra Lukijanec
Suania Acampa
Contents
1. Introduction
Since the 2016 United States presidential election (Faris et al., 2017), concerns have raised globally about the risk of instrumentalization of social media by political actors interested in interfering in the democratic process (Del-Fresno-García et. al, 2018). In Europe those concerns grew after reporting of disinformation campaigns in the Brexit (Cadwalladr, 2017), Cataluña (Marino et. al, 2019) and French elections (Chesney & Citron, 2019). Since then, interference of “fake news” in the political discourse has been thoroughly analysed (Fletcher et al., 2018; Jack, 2017; Bennett & Livingstone, 2018).
Research that covers disinformation with an anti-European discourse focuses mostly on possible Russian interference, Twitter and big data sets (Golovchenko, et. al., 2018; Gorrell et. al., 2019, Pierri et. al., 2019) and there is not a lot of understanding about how anti-EU online communities interact, share and produce disinformation.
More importantly, the current project tried to demonstrate the relevance of adapting methodologies to study not only disinformation but digital phenomena in general in an closed API environment (Bruns, 2019; Perriam et. al., 2019). The more hands-on approach of manually fact-checking, categorizing and analysing a smaller number of posts in an ever more closed platform like Facebook contradicts general research focusing on AI, big data, Twitter-based data collection and analysis. However, as translated in this current report and previous findings using the same methodology (Cardoso et. al. 2019), it contributes with valid issues for the knowledge base.
2. Initial Data Sets
Our data set selection and extraction was part of our methodology and consisted on 10050 posts made by users in 42 Facebook groups between the 7th and 15th of January, 2020.
This post list was extracted via Crowdtangle that allowed us to have, among others, the post url, the group, date and time it was posted, and number of total interactions it had during the analysed period.
3. Research Questions
Our research questions were:
-
Is there anti-EU political disinformation in Facebook groups?
-
What are the main techniques being used to build disinformation narratives?
-
How much of this disinformation results from actions inside the platform - Facebook?
-
What are the main actors / agents pushing these narratives and how do they operate?
-
What is the weight and impact of these disinformation narratives, and who / what do they target?
From a methodological point of view we had two objectives:
-
To assess transversal applicability of the methodology used by the project’s coordinator and other colleagues in a study on disinformation in the Portuguese elections.
-
To demonstrate the validity and value of findings using a more hands-on approach and a smaller data set with a deeper analysis of each case. This was possible by introducing peer reviewed fact-checking and other open source intelligence techniques into the methodological process.
4. Methodology
The current project was subject of widespread methodological discussion, with the goal of balancing between validity and rigour of results, efficiency in the collection and analysis process while taking into account fundamental ethical boundaries and privacy rights.
4.1 Selection of data
While structuring the design for the current project, one of the first challenges was posed by the vast amount of data available and technical limitations to its extraction for research purposes. The choice of Facebook instead of other platforms was due to current disproportionality between its unquestionable relevance in the disinformation sphere and the limited amount of research done using Facebook data (Walker et. al., 2019).
Despite social relevance, Facebook has become an increasingly harder platform for researchers to work on due to privacy restrictions on its API and difficulty to extract public data (Bruns, 2019; Venturini et. al. 2019). This restriction has also become an opportunity for researchers to develop and find new ways to approach data on these platforms (Rogers & Venturini, 2019).
Aware of these limitations, but having access to Crowdtangle, a platform working on Facebook’s API that allows to create lists of pages and groups, it was decided to work on a selected sample of groups that had both a high reach and recent content.
4.2 Groups selection
As a starting point for this project, it was proposed to focus on online communities associated with an anti-EU feeling, this case materialized in public Facebook groups that contained a visible anti-EU agenda and whose main language was spoken among project members.
A syllabus was built around the theme “anti-EU” and a multivariate search was used in search engines and inside Facebook to identify groups that fulfilled the above criteria. Search engines were included to minimize the effects of Facebook’s suggestion algorithm and select a variety and politically heterogeneous set of groups. This multivariate method had been identified in recent research (Squire, 2019) and is a good alternative after the removal in June 2019 of Facebook Graph searches.
This multivariate search lead to an extensive table of 154 groups. The total list was reduced to 42 that fulfilled three criteria: 1) they had more than 1000 members, 2) they had more than 100 posts in the last 30 days and 3) in the last 10 posts, more than half were in a language spoken among the participants allocated to this project.
This triangulation allowed us to filter the extensive list to the final set, excluding groups with a low reach, foreign and unverifiable content and no recent activity.
| Group name | Members | Posts - 07-15JAN | |
| 1 | Jacob Rees-Mogg Appreciation Group | 24734 | 1226 |
| 2 | I'M A BREXITEER | 17897 | 1025 |
| 3 | Podpořme referendum o vystoupení ČR z EU konané v roce 2020 | 18369 | 1005 |
| 4 | Stoppt die Deutsche Umwelthilfe (DUH)! | 41268 | 245 |
| 5 | The Brexit party: Supporters | 5302 | 459 |
| 6 | THE PEOPLES BREXIT AND INDEPENDENCE GROUP | 5868 | 554 |
| 7 | THE SILENT MAJORITY (UK) | 5138 | 304 |
| 8 | Boris Johnson Appreciation Group | 4037 | 478 |
| 9 | Voters 4 Brexit Party | 3103 | 179 |
| 10 | Brits Fighting E.U. To Get Their Country Back | 2741 | 147 |
| 11 | Nederland in opstand ‼️boeren protest ‼️ | 2911 | 257 |
| 12 | Gelbe Westen #GelbwestenVereinigungBayern | 2451 | 477 |
| 13 | TEAM 69 - EU Austritt | 10268 | 283 |
| 14 | Fishing For Leave | 3327 | 65 |
| 15 | BRITAIN BEYOND BREXIT | 2187 | 205 |
| 16 | Amis qui aiment François Asselineau | 1645 | 110 |
| 17 | Fr-Exit | 4191 | 263 |
| 18 | MALTEXIT | 2995 | 134 |
| 19 | CZEXIT - CzexitCzexit.cz - pro rychlý konec EU členství, vlasteneckou vládu | 1659 | 256 |
| 20 | ME KANSA - Kansanliike | 4028 | 107 |
| 21 | Brexit, Great Britain & Beyond: The Right Way Forward | 2247 | 134 |
| 22 | Resisting Brexit! | 5124 | 97 |
| 23 | Discussions autour de l'UPR | 12516 | 110 |
| 24 | Sack Remain Rebels From Parliament | 206 | 81 |
| 25 | CZEXIT !!! | 1568 | 122 |
| 26 | We Love Our Country, Vote Leave | 1927 | 116 |
| 27 | Deutschland vernetzt sich Diskussionen | 2107 | 296 |
| 28 | Lega per la Sovranità | 304 | 85 |
| 29 | Stop Kebab | 2077 | 103 |
| 30 | UK And Ireland Unite Against The EU | 101 | 45 |
| 31 | NO EURO NO EUROPA | 4611 | 114 |
| 32 | Wir Befreien Deutschland! Verfassunggebende Versammlung. Private Gruppe ... | 379 | 47 |
| 33 | Erotaan EUsta Kansanliike | 3588 | 25 |
| 34 | Geen EU Superstaat! NEXIT | 107 | 104 |
| 35 | NEXIT ! Nederland uit de Euro ! | 1614 | 267 |
| 36 | The Brexit Central HQ: Public | 1237 | 49 |
| 37 | Salvare l'Italia dall'Europa | 4744 | 73 |
| 38 | Panafricain anti-impérialiste plateforme -Stop OTAN:-USA/UE hors d'AFRIQUE- | 19597 | 138 |
| 39 | AFD-Deutschland"Gruppe" | 1176 | 90 |
| 40 | PATRIOTS TOOT TO LEAVE. | 1977 | 62 |
| 41 | ITALIANI PATRIOTI | 1188 | 95 |
| 42 | NO EUROPA | 3688 | 18 |
Table 1 - Alphabetically ordered list of groups monitored. Source: Facebook. Data extracted through Crowdtangle API
4.2 Extraction and sorting of data
The set of 42 groups was included as analysis lists in Crowdtangle. Crowdtangle is a social media tracking platform owned by Facebook that has privileged access to the social network while anonymizing user data. It allowed for sorted extraction of all posts published (10050) during the 1 week of analysis (from the 7th to the 15th of January), ordering them by the number of total interactions (shares, comments, likes) associated with each post.
In the extraction table, metadata such as time of publishing, links to external content (a media article) and the post’s and link’s text are also included.
4.3 Fact checking, identification and categorization
From the table with the total list of posts sorted by number of interactions, the 60 most viral posts were fact-checked, debunked, labelled and categorized, one by one. The number of analysed posts resulted from time constraints, with the project team deciding they would do as many as possible within the planned timetable. The sample of 60 posts represented 12% of all interactions made in the 42 groups during the analysed period.
The fact-checking process was made complementing two renowned procedure manuals in the field, one by the Consortium of Investigative Journalism Network and the other one by Craig Silverman, for First Draft News (Silverman, 2013). Being aware that there are different positions pertaining the validity and consistency of fact-checking method platforms (Amazeen, 2015, 2016; Marietta, Barker & Bowser, 2015), an effort was made to sustain results not only with these fact-checking methodologies but also by including peer review by at least 2 other project participants. Situations where consensus was not found were discussed by the entire project team with no registered cases of inexistence of agreement after thorough discussion and presentation of facts.
Every post was analysed according to its content, context and visual clues and labelled either as disinformative content (incorrect facts), potentially disinformative content (inaccurate facts) or nothing to register. This labelling process was a result of the evaluation of the tags associated with each post.
Claire Wardle’s First Draft News typology (Wardle & Derakhshan, 2017; Wardle, 2018), was not used due to previous challenges (Cardoso et. al., 2019) found using it, namely because it is a closed and mutually exclusive coding system and because it is strongly associated with the assessment of intent, that is very hard to objectively and accurately evaluate in this sort of research.
The project team used a tagging method developed by the Portuguese communication think tank Media Lab (ISCTE-IUL) in their research on disinformation in Portuguese elections and whose methodology was partially replicated in this project.
The tags were directly associated with different disinformative characteristics identified in the posts. The system isn’t closed, allowing the addition of new tags as disinformation techniques change and develop. They do not consider intent and are non-conflicting. In most cases more than one characteristic will be found in a post. During the project, new possible tags were identified. They also distinguish between intra and outside Facebook content.
| Type | Tag |
| Incorrect | Incorrect fact |
| Incorrect title | |
| Incorrect facts to the current date | |
| Incorrect facts on publishing date | |
| Unfounded accusations | |
| Inaccurate | Inaccurate facts |
| Inaccurate title | |
| Inaccurate facts to the current date | |
| Inaccurate facts on publishing date | |
| Unsubstantiated accusations | |
| Visually out of context | Manipulated image |
| Image spin | |
| Image out of context | |
| Content out of context | Selective copy |
| Out of context use of trustworthy sources | |
| Out of context use of parody content | |
| Isolated case portrayed as general issue | |
| Timing out of context | Recicling |
| Out of context timing | |
| Geography out of context | Out of context geolocation |
Table 2 - Media Lab's tags for disinformation characteristics.
As a last step, the disinformative narrative were identified for all red flagged posts, deconstructing it in a set of keywords, to be used in the second stage of analysis.
4.4 Agents, sharing patterns and impact
Red flagged posts and their narratives were further analysed on sharing patterns and impact. For sharing patterns, the project team focused on understanding how the narrative developed through time. That involved analysing sharing patterns of the post itself, identifying when the link (if applicable) first appeared on Facebook and using the keywords to search for other posts with the same narrative. Profile IDs of first sharers was included with the sole purpose of trying to find repetitions and understand if there were agents with multiple disinformative posts, or agents sharing one disinformative post in multiple groups or platforms.
Secondly, an attempt was made to analyse impact. Values for number of shares of the various posts found with the same narrative inside the considered time frame were registered and summed. Keywords were inserted into Google Trends and analysed to see if any change had occurred with the emergence (or re-emergence) of the disinformative narrative. In the cases were posts with the same narratives were found outside Facebook, timelines were assessed to try to understand if the narrative came from other platforms or had migrated to them afterwards.
4.5 Ethical issues
Some ethical issues were raised in the building of the current project, considering current research guidelines (Rogers, 2018; Franzke et al., 2019). First, the boundaries between what is private and public and to which extend informed consent should be applied. There continues to be a growing discussion on this issue, and whether privacy of data should be determined by a user-platform agreement or by user’s perceptions, given that the later is far more difficult to assess (Fiesler & Proferes, 2018). Without the existence of a general consensus among academia (Tufekci, 2014; Kosinsky et al., 2015; Zimmer, 2018), it was decided to focus only on public Facebook groups. The use of Crowdtangle assured all platform terms of use were fulfilled.
No identifiable information (connecting data and personal identifiers) is included in this report and Crowdtangle strips off personal selectors before collecting the data.
For the analysis of agency, sharing patterns and impact of disinformative narratives, team members had to analyse some public identifiable data, focusing only on user behaviour namely sharing patterns and cross-platform engagement, with no collection of personal data.
5. Findings
5.1. Is there anti-EU political disinformation in Facebook groups?
When examining the most viral posts within anti-EU groups in the last week, we found a significant portion (51.7%) were problematic in some way--either potentially or seriously misleading or disinformative. Confirming our findings, 16.1% of the posts we examined had been removed by the end of the week. It is impossible to determine whether they were removed by Facebook or by the users themselves. Unproblematic content, tagged with the “nothing to register” tag, made up 48.3% of posts. So overall, there was more problematic content than not.
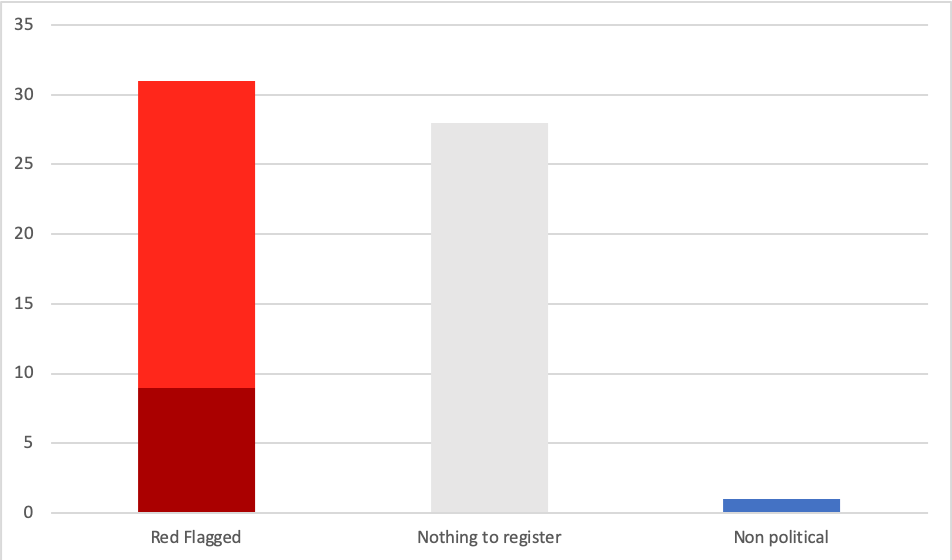
Figure 1 - Number of disinformative, potentially disinformative (both red flagged), nothing to register and non political.
The illustration (fig. 2) shows the relative frequency of topic occurence in the examined posts and thematic overlap. In the English language posts, Brexit dominated the content, complemented by relating themes such as the “Harry and Megan” controversy, which is connected to e.g. narratives of misuse of public funds and elite critique. Migration and refugees was addressed in English and Czech posts, environmental issues connected to negative narratives about “left” and “green” parties and their supposed incompetence in economic matters dominated German posts.

Figure 2 -Main themes in the 60 analysed posts.
Of the problematic posts detected in our dataset, 41.9% were directly related to anti-EU discourse. In the posts that we tagged as unproblematic, anti-EU content makes up 69% of the posts. The sample is too small to draw definitive conclusions regarding this finding. The topics not directly related to anti-EU narratives do not show a consistent theme, meaning that we could not detect one prominent issue being discussed in anti-EU groups, across languages, this week. However, there are some themes in the different language subsets that reflect national politics (e.g. environmental debates in Germany, migration in Czechia). Furthermore, our data seems consistent with papers showing co-occurrence of tabloid-esque topic interest and mis-/disinformation (Chadwick, et. al., 2018), exemplified in the prevalence of e.g. the “Harry and Megan” issue.
To answer the following research questions, we sorted and analysed 31 posts that had either disinformative or imprecise content and left out those that had nothing to register or were non political in nature.
5.2 What are the main techniques being used to build disinformation narratives?
Most of the disinformation on Facebook conveyed either inaccurate facts (14%) or timed out of context (13%). The latter is the most used pattern to spread false information on Facebook in our sample. It means that most of the messages (either on Facebook or via link) were not related to a current event in the real life. In the same vein, nearly 10% of the posts were recycled. This highlights thus the extent to which old story were chosen to argue a point of view about an existing or non-existing event.
Moreover, unsubstantiated or unfounded accusations are commonly used to spread fake news or misinformation as well as image spin.
Finally, incorrect title links are commonly used by mainstream media to attract readers. It is only by reading the entire article that we can understand that the title is actually wrong or exaggerated.

Figure 3 - The different techniques used for disinformation
A Pearson’s r correlation analysis was performed in order to find out if there was any relationship between the techniques used to diffuse disinformation. We identified three pairs of strong correlations:
-
Firstly, there is a strong correlation between the recycling of old news and timing out of context (r = ,668, p < ,01). This highlights the praxis of decontextualizing old news.
-
Secondly, a strong correlation between incorrect facts at date and incorrect facts at publication date was found (r = ,682, p < ,01). That is not surprising, coders might have coded both variables when the fact was out of date when it was published and still is.
-
Thirdly, the strong correlation between selective copy and decontextualized use of trusted sources hints to how trusted media brands are used to disseminate disinformation (r = ,695, p < ,01).
| Recycling * Timing out of context | r = ,668 | p < ,01 |
| Incorrect facts to date * Incorrect facts at publications date | r = ,682 | p < ,01 |
| Decontextualized use of trusted sources * Selective Copy | r = ,695 | p < ,01 |
| n = 31 |
Table 3 : Table of the strong correlations between the techniques used for disinformation
5.3 How much of this disinformation results from actions inside the platform - Facebook?
Following tagging system, we sorted posts with tags intra Facebook and those who had only out of Facebook tags. We found that 32,3% of the disinformative or imprecise content was created exclusively outside of Facebook, meaning that 67.7% disinformation is associated to actions taken inside Facebook.
A good example pertains to out of context timing, with links being shared on Facebook years after their publishing. At the time of writing there was no misinformation in the article itself. However, because the article was shared on Facebook a few years after its original publishing date, it becomes misleading. Those Facebook users who did not open the link or did not notice the publishing date could have been deceived to believe the information was relevant to date and applicable to current events.
5.4 What are the main actors / agents pushing these narratives and how do they operate?
To answer this research question, we reviewed:
• The users that first posted the disinformative posts
• The main sources of the links in all the posts reviewed as part of the project
• The main techniques used to promote the different narratives that we identified through the set of posts.
Review of user identities revealed that almost half of the disinformative posts were posted by individuals responsible for more than one of the posts, with two users responsible for three each. These users were in some cases posting across multiple Facebook groups, suggesting that there is an anti-EU ecosystem of groups and users in existence, with some individuals playing a disproportionately active role. But there is no evidence of automated or bot-related spreading of disinformation.
| Number of posts | Percentage | |
| Posts from users with multiple posts | 14 | 45% |
| Posts from users with one post | 12 | 39% |
| Posts with users no longer identifiable | 5 | 16% |
| Total | 31 | 100% |
Table 4 : Users with multiple or single posts
Turning to the sources of the links, there was a wide range of media sources linked to by the posts reviewed, but a number came up multiple times – these are listed in the table below. The top two sources are traditional UK media outlets that lean to the right and have been very actively involved in supporting the Brexit agenda in recent years. The Daily Express was particularly prominent, with a relatively high level of disinformation amongst the stories linked to.
| Source | Number | Number disinformative |
| Daily Express | 6 | 5 |
| Daily mail | 4 | 1 |
| Kentlive | 4 | 0 |
| Metro | 2 | 1 |
Table 5 : Table with presence of media outlets
The clearest example identified of a specific narrative being promoted was in relation to the issues of fishing rights in the Brexit trade deal. Since the 9th January more than six articles have been published in mainstream news outlets (the Express, Sun and Telegraph) relating to this topic, building on each other, and each of which have had thousands of interactions on Facebook and Twitter. Political actors (specifically two Brexit Party MEPs, Rupert Lowe and June Mummery) are both quoted in these articles (providing outraged responses to quotes from EU officials) and then involved in disseminating them online: for example, in relation to one of the Express articles, their retweets were responsible for more than 50% of the Twitter interactions. This suggests a tightly connected ecosystem of social media users, right wing news outlets and anti-EU politicians, able to create momentum around particular narratives, even without explicit coordination amongst them.
5.5. What is the weight and impact of these disinformation narratives, and who / what do they target?
By summing the values of interactions registered all the posts identified by the team as having the same narrative of the 31 red flagged Facebook posts, we were able to conclude that these disinformative narratives reached over 9 million users up to date.
Collected data also made it clear that some topics were more easily also shared on Twitter like Brexit and anti-UE, climate change, migration and religion. On Reddit and YouTube, disinformative posts we did not register as much engagement.
While running main disinformative narratives keywords into Google Trends we found several examples of recent growth of the issue, like one post about Starbucks COO, Shelina Jan Mohamed were it was easy to see that there was a recent peak of interest directly connected to the date the false narrative began to circulate again. In this case the Starbucks COO was targeted with a racism allegation. The fake story was first released in 2015. But according to Google Trends, the growth of interest is on the exact same day as the narrative began being shared on Facebook in January 2020. It is a good example on how probably a certain amount of people have been confronted with this narrative. Curiously, all the research Google Trends also points out that most search was made in Texas, a rather conservative state.
6. Recommendations
Findings of this project sustained some of the team’s recommendations to contain disinformation:
-
Given a frequent recycling of old news misleadingly presented as current it would be very positive if publishing date of links also appeared on user’s timeline. Meanwhile, media outlets could identify old news from their archive by saving it in a different subdomain, or changing the design, either in the title, or by using a sepia tone in the highlighted picture. Finally, when a user does click on such an article, links to follow up and more recent articles on the subject should appear right under the title.
-
The existence of verified pages from official organizations, companies and entities from non-official pages simply created by a user.
-
Update of regulations to current challenges with tighter controls and fines from incorrect titles or statements from registered media outlets, the impossibility to change a post after publishing for full accountability and more awareness on how social media platforms character and visibility restrictions can give a misleading impression of an article.
-
After a false narrative has been detected and posts related to it have been taken down (as we saw happening during our project) warn all users that interacted with that contact that it was not accurate.
7. Conclusions
As the team prepared for the final presentation of findings at the Winter School some main conclusions were drawn:
-
Disinformation is a far more complex, subtle and identifiable than mainstream discourse about the subject would lead us to believe. Very often the misleading character from an article comes from 2 or 3 little details, that can completely misinform the user.
-
Timing out of context was one of the most often tags identified and very much portraits this reality.
-
The tags were easy to understand and to apply and allowed for deconstruction of the disinformative narratives and a better understanding on how they were built and what could be done to make it less easy and effective to apply them.
-
Mainstream media and Facebook have far more responsibility as facilitators in this ecosystem that they would like to assume. Exactly the same can be said from the regular user, that likes, shares or even posts disinformative content, possibly without real awareness of the implications.
-
Academics, journalists and fact-checking networks have to be more proactive and search for disinformation instead of analysing disinformation campaigns identified by third parties, namely platforms themselves. These are campaigns very often external to the platform and are identified by their inauthentic behaviour therefore excluding more organic examples dealt with in this current project.
As a overall assessment, we felt our small sample gave us really interesting findings, we believe are an essential complement with the abundant big data research done on disinformation. In a Winter School focused on limitations posed by API restrictions we were glad to be an example of how challenges can become opportunities for innovation.
8. References
Amazeen, M. A. (2016). Checking the fact-checkers in 2008: Predicting political ad scrutiny and assessing consistency. Journal of Political Marketing, 15(4), 433-464
Amazeen, M. A. (2015). Revisiting the epistemology of fact-checking. Critical Review, 27(1), 1-22
Bennett, W. L., & Livingston, S. (2018). The disinformation order: Disruptive communication and the decline of democratic institutions. European journal of communication, 33(2), 122-139
Bruns, A. (2019) After the ‘APIcalypse’: social media platforms and their fight against critical scholarly research, Information, Communication & Society, 22(11), 1544-1566
Cadwalladr, C. (2017). The great British Brexit robbery: how our democracy was hijacked. The Guardian, 7
Cardoso, G., Moreno, J. Narciso, I. & Palma, N. (2019) Online disinformation during 2019 Portugal’s elections, Democracy Reporting International
Chadwick, A., Vaccari, C., & O’Loughlin, B. (2018). Do tabloids poison the well of social media? Explaining democratically dysfunctional news sharing. New Media & Society, 20(11), 4255-4274
Chesney, R., & Citron, D. (2019). Deepfakes and the new disinformation war: The coming age of post-truth geopolitics. Foreign Aff., 98, 147.
Del-Fresno-García, M., & Manfredi-Sánchez, J. L. (2018). Politics, hackers and partisan networking. Misinformation, national utility and free election in the Catalan independence movement. El profesional de la información, 27(6), 1225-1238
Faris, R., Roberts, H., Etling, B., Bourassa, N., Zuckerman, E., & Benkler, Y. (2017). Partisanship, propaganda, and disinformation: Online media and the 2016 US presidential election. Berkman Klein Center Research Publication, 6.
Golovchenko, Y., Hartmann, M., & Adler-Nissen, R. (2018). State, media and civil society in the information warfare over Ukraine: citizen curators of digital disinformation. International Affairs, 94(5), 975-994
Gorrell, G., Bakir, M. E., Roberts, I., Greenwood, M. A., Iavarone, B., & Bontcheva, K. (2019). Partisanship, propaganda and post-truth politics: Quantifying impact in online. arXiv preprint arXiv:1902.01752.
Marietta, M., Barker, D. C., & Bowser, T. (2015). Fact-checking polarized politics: Does the fact-check industry provide consistent guidance on disputed realities? The Forum 13(4), 577-596
Marino, R. A., Marín, D. G., & Manzano, L. R. (2019). Noticias falsas, bulos y trending topics: Anatomía y estrategias de la desinformación en el conflicto catalán. El profesional de la información, 28(3), 8
Perriam, J. Birkbak, A. & Freeman, A. (2019): Digital methods in a post-API environment, International Journal of Social Research Methodology, 1-14
Pierri, F., Artoni, A., & Ceri, S. (2019). Investigating Italian disinformation spreading on Twitter in the context of 2019 European elections. arXiv preprint arXiv:1907.08170.
Rogers, R. (2018). Social Media Research After the Fake News Debacle, Partecipazione e Conflitto, The Open Journal of Sociopolitical Studies, 11(2)
Silverman, C. (ed.) (2013). Verification Handbook: A definitive guide to verifying digital content for emergency coverage. Retrieved from http://verificationhandbook.com/book/
Squire, M. (2019). Network, Text, and Image Analysis of Anti-Muslim Groups on Facebook. The Journal of Web Science, 7
Wardle, C. (2018). The Need for Smarter Definitions and Practical, Timely Empirical Research on Information Disorder. Digital Journalism, 6(8), 951-963.
Wardle, C., & Derakhshan, H. (2017). Information Disorder: Toward an interdisciplinary framework for research and policy making. Council of Europe Report, 27.
Walker, S., Mercea D. & Bastos, M. (2019) The disinformation landscape and the lockdown of social platforms, Information, Communication & Society, 22(11), 1531-1543
Venturini, T. & Rogers, R. (2019) “API-Based Research” or How can Digital Sociology and Journalism Studies Learn from the Facebook and Cambridge Analytica Data Breach, Digital Journalism, 7(4), 532-540
Topic revision: 29 Jan 2020, InêsNarciso
Ideas, requests, problems regarding Foswiki? Send feedback