Containing Homophily
Network analysis and social media platforms assume and construct homophily: they use similarity to breed connection. These projects question homophily’s axiomatic status by exploring its history, questions, methods and platforms—and by exploring and imagining other modes of connection. Heterophily was coined in the same article as homophily; mutual indifference is key to cities and infrastructures. In particular, these projects ask:- How has the concept traveled across scientific disciplines? How did homophily transform from questionable finding from unpublished data to a core principle of network epistemology?
- How can we re-conceptualize social media platforms by exploring and operationalizing mutual indifference, invisibility, and heterophily?
- How can social media alternatives contest network logics of distinction and segregation?
- To what extent do our current social media networks prescribe the homophily they claim to only describe?
Group 1. How has homophily traveled?
Project members
Ainsley Dankort
Ine van Zeeland
Jason Chao
Julia Wolny
Summary of Key Findings
-
While initially, the 1954 article ‘Friendship As Social Process’ by Lazarsfeld and Merton was mostly discussed within the research field of Sociology, it was suddenly picked up in the mid-90s by other research fields, most notably Business, Management, and Computer Science.
-
Page 18, the title page of the article, is cited more than any other page, and even the whole article combined. We speculate that this reflects a tendency for authors to cite the original article without having actually read it, meaning the spreading of this faulty concept is not built on a firm understanding of it.
-
In contrast, page 27, which includes the footnote that explains that only white respondents were taken into account for the creation of (il)liberal clusters, is never cited.
-
While in general, the use of the homophily concept remains the same across contexts, it is associated with different terms in different fields of interest.
-
Many of the most related terms to homophily, when paired with or discluded from all related disciplines, have roots in eugenics.
-
The concept of heterophily is almost never discussed, yielding no results on the Google News Word2Vec model, and only appearing in 54 articles on Web of Science.
Intro and Research Question(s)
In 1954, sociologists Paul F. Lazarsfeld and Robert K. Merton published an article entitled ‘Friendship As Social Process: A Substantive and Methodological Article’, in which they explored the idea that people make friends with others who are like them in some respect, for which they needed to develop a methodology. Lazarsfeld and Merton coined the terms ‘homophily’ for ‘a tendency for friendships to form between those who are alike in some designated respect’ and ‘heterophily’ for ‘a tendency for friendships to form between those who differ in some designated respect’ (p. 23), along the lines of the existing terms ‘homogamy’ and ‘heterogamy’.
In an attempt to develop a methodology to gauge the degree of homophily for a specified group, they look for ways to cluster people into groups, e.g. based on their (social) status or their values. Crucially, they give an example of how this clustering works by grouping people who live together in a ‘bi-racial’ housing project based on their opinions on blacks and whites living together in one project. They note that black respondents don’t appear to have a diversity of opinions on the subject of where they can live (one suspects they all think they should be allowed to live anywhere they like) so they do leave black people out of this part of the study, and then go on to cluster the white people in the housing projects according to whether they are in favour of blacks and whites living together (‘liberals’), or opposed (‘illiberals’) or generally not in favour, but fine in their current environment (‘ambivalents’). Lazarsfeld and Merton then find that people tend to be friends with people with similar opinions (or ‘racial values’, as they put it), i.e. people in the same group, more often than with people from the other two groups.
While this study has a number of flaws, the concepts introduced in it have travelled far, and much automated decision-making these days is based on the idea that people can be clustered according to characteristics in which they are ‘alike’, which clusters can then be used to make predictions about people’s behaviour or preferences. What we set out to do, is to study how both the Lazarsfeld and Merton article, and the ideas in it, have travelled over the years.
Our main research question was therefore: How has the concept of homophily travelled?
Subquestions were:
-
How was Lazarsfeld & Merton’s article ‘Friendship As Social Process’ (1954) adopted in various scientific disciplines?
-
How are the terms ‘homophily’ and ‘heterophily’ used in different contexts?
Methods
We decided to start by looking into citations of the original Lazarsfeld and Merton article included in “Freedom and Control in Modern Society” on both Google Scholar and Web of Science. However, we found a striking disparity in the number citations each site gave us. Google Scholar yielded 2,653 citations while Web of Science gave us 26,380. Having doubts about this extremely high number, we verified that for authors who cited it numerous time, it was always in a unique publication and that none of those citations were self-citations. One possible explanation of the difference is that Google Scholar might skew towards more recent years than WOS. With all this is mind, we decided to continue our research under the assumption that all citations found of Google Scholar would also be present on Web of Science.
We then downloaded the full citation and abstract for each of the WOS articles citing the original article in groups of 500 (the maximum number allowed each time) and merged them into a single CSV file to be imported to Excel. Once there, we were able to further research how the concept appears in different disciplines over time, what parts of the article are most cited, and who are its biggest fans.
Our other path towards understanding how the word homophily is being defined or related in a variety of fields was by using the word embedding method. We used Word2Vec vectors trained on Google News and PubMed. These two models were chosen because we hoped to capture both social and medical uses of the concept. Executing the program for both “homophily” and “heterophily” we compiled two lists of synonyms or closely related words for homophily and one, from the PubMed model, for heterophily.
Once a list of synonyms was compiled, we could then query for these words. The program also allowed us to look up words related to “homophily” both when in the presence of another word (for example, “housing” which would give us it’s meaning in relation to the topic of housing) or in all articles not mentioning another word (for example, “biology” giving us related words that do not come up in the field of biology.) We then decided to try putting other related words or names of disciplines into these positive and negative fields.
We also trained another Word2Vec model on all the articles in an archive from Cornell from the last 2 years in order to let it practice on other types of academic language, but we did not have time to implement it due to the length of the training process.
Findings and visualizations

-
Most citing documents refer to page 18, the first page of the Lazarsfeld & Merton article.
-
A number of referencing documents incorrectly refer to pages before the first page, notably page 8 (16 references), page 16 (2), and page 11 (2).
Spot checking, we found that the articles that referred to page 16 probably made typos or made a mistake, but they did not use the same incorrect reference; “16-88” and “16-66” respectively (in other words, they did not simply copy each other). -
There is a clear uptick in the number of citations in the past 15 years.
-
Page 27 is the page that contains the footnote on not including black residents; it is not referred to once.
As for the distribution of citations over various research fields, we found the following:

Fig.2 Timeline for top 10 research areas of documents citing Lazarsfeld and Merton (1954) in Web of Science
These are the top 10 WoS research areas for documents referring to the 1954 article. As can be expected, the article was initially mostly discussed in Sociology. However, from the mid-1990s onwards, the article was suddenly picked up in other research areas, most notably Business, Economics, Managements, and Computer Science.
When it comes to our second question, how are the terms ‘homophily’ and ‘heterophily’ used, we noticed that we could not find any words related to ‘heterophily’ in our corpus at all.
The Word2vec results for PubMed showed for the queries
- homophily + ecology,
- homophily + housing,
- homophily + segregation,
that ‘assortative mating’ (which has its origin in eugenics) is what the ecology, housing, and segregation perspectives on homophily have in common. The meaning of the homophily concept remains mostly the same, but is associated with different terms in different fields of interest.


 Fig.3 Similar shared keywords for Homophily (first) and Heterophily (second) on Google News and for Homophily on PubMed (third).
Fig.3 Similar shared keywords for Homophily (first) and Heterophily (second) on Google News and for Homophily on PubMed (third).
However, besides ‘assortative mating’, it seemed that words similar to ‘homophily’ in the three topics do not have have a significant intersection. In other words, these three topics have their own set of words to convey the meaning of homophily. The scattered expressions of the idea of ‘homophily’ if different domains suggest that when homophily entered a domain, the terms used to elaborate on the idea tended to be ‘home-grown’ and were not borrowed from other disciplines.
Interestingly, we did not find related words for ‘heterophily’ in the Google News corpus. As for the documents found in Web of Science, ‘heterophily’ only appeared in 54 of them.
Due to the limited availability of pre-trained Word2Vec models, we could not make queries against more diverse corpora. Training new models on academic articles on arXiv was attempted but could not to produce a working model due to time limitations. If sufficient time and computing resources permitted, we would train models on corpora of different times and subjects to see how homophily was conceived across time and domains. The word embedding method looks has potential in research related to semantics.Discussion
Looking at the numbers of citations for Lazarsfeld and Merton’s 1954 article over the years, we found that initially, ‘Friendship As Social Process’ was mostly discussed within the research field of Sociology. This was true for decades, albeit that there were some occasional references in other research fields. The article was then suddenly picked up in the mid-90s by other research fields, most notably Business, Management, and Computer Sciences (particularly, in the subfields of Information Systems and Artificial Intelligence). We also found that one particular article from 2001, ‘Birds of a Feather: Homophily in Social Networks’ by McPherson, Smith-Lovin and Cook, was itself cited more than 12,000 times and may have contributed to a wider distribution of the idea of homophily.
Another interesting finding is that most of the citations we found in Web of Science referred to page 18, the first page of the article, which basically contains the title and a couple of introductory, but not substantive, paragraphs. This page is not only cited more than any other page, it is cited even more often than the whole article combined. This may reflect a tendency for authors to cite the original article without having actually read it, meaning the spreading of the faulty concept of homophily is not built on a firm understanding of it. This appears the more so because page 27, which includes the footnote that explains that only white respondents were taken into account for the creation of (il)liberal clusters, is never cited. One would expect authors in later decades to at least attend to this issue.
When it comes to the analysis of words related to the term ‘homophily’ itself, we found that in general, the use of the concept remains the same across contexts, even if it is associated with different terms in different fields of interest. Many of the most related terms to homophily, when paired with or discluded from all related disciplines, have roots in eugenics. The opposite term coined by Lazarsfeld and Merton, ‘heterophily’, is almost never discussed, yielding no results on the Google News Word2Vec model, and only appearing in 54 articles on Web of Science.
Conclusion
The sudden increase in references to the Lazarsfeld and Merton article in the research areas of Business, Management, and Computer Sciences from the 1990s on may reflect a rising interest in using data about people’s past preferences to predict their future behavior by clustering them with ‘people like them’, e.g. in the areas of advertising, sales, marketing, and other fields interested in consumer manipulation. Whether homophilic foundations can be effective in pursuing these interests remains outside of the scope of this project.
For further analysis, it would be interesting to look into such questions as whether the popular article ‘Birds of a Feather: Homophily in Social Networks’ by McPherson et al (2001) re-ignited (sociological) interest in the Lazarsfeld and Merton article in subsequent years, and how this article gave rise to new academic and economic approaches to studies of social media users. In general, further analysis of the influence of authors who cite this article would shed more light on how the concept of homophily has travelled.
Most importantly, what we have not looked into yet is the question of whether the documents we found in Web of Science are in support of the concept of homophily, or if they critique it. Not finding any citations referring to the questionable note on page 27 of the article and finding few mentions of the term ‘heterophily’ are suggestive of an uncritical approach to the article; nevertheless, further analysis will be required for more nuance.
Using a homophilically based machine learning tool, Word2vec, ourselves to look into the relatedness of the term ‘homophily’ to other terms in different corpuses was an interesting exercise. We found that he meaning of the homophily concept remains mostly the same, but is associated with different terms in different fields of interest. We would have to explore further what this ‘relatedness’ means.
References
Lazarsfeld & Merton (1954): “Friendship as Social Process: A Substantive and Methodological Analysis”, Freedom and Control in Modern Society”, p. 18-66.
McPherson, M., Smith-Lovin, L., & Cook, J. M. (2001), “Birds of a feather: Homophily in social networks”, Annual review of sociology, 27(1), p. 415-444.
Group 2.[Sub-project title here]
Project members
Petra Audyova Ben Blackwell Andra Irina Cristina Ene Jiyoung Ydun Kim Cengiz SalmanIntro and Research Question(s)
We aim to explore heterophily through the indifference present across social media platforms and in social networks. We ask how exclusion and erasure may be ingrained in the infrastructure of social media platforms, and whether they are necessary for the formation of networks. This begs the question: how might one detect invisible users in a network? How might we visualise the ‘invisibles’? Most research focuses on the strongly expressed positive or negative connections between individuals, with network science ultimately oriented toward finding and analysing clusters. These clusters are defined by their rejection of that which lies outside of their boundaries. In our project we intended to map mutual indifference, which we defined as a lack of (expressed) affective regard for the other or object encountered in a shared space. We gesture toward one potential method for detecting and measuring indifference across social media platforms: measuring and mapping “fuzzy clusters” or sets of edges that are relatively homophily-resistant.Methods
To begin, we conducted short interviews with experts to define the metrics for indifference per platform. These interviews led us to conceptualise a split between indifference from the perspective of users, and from the perspective of the content. Indifferent users were seen to be the ones who showed a low level of engagement with infrequent original posts whilst indifferent content was found to be the posts with low levels of views, comments and other signifiers of engagement. Indifference, as seen in these perspectives, would most obviously be presented as the absence of data, which poses difficulties to the researcher aiming to detect and visualise it. We were then faced with the task of tackling the subject of indifference in a way which could be traced through interactions by and between users and content. In other words, we thought it was important to identify “mutual indifference” within datasets that capture a matrix of interactions between users and use these relations to detect homophilous communities.Findings and visualizations
According to Newman, a network of neatly clustered communities can be evaluated according to a measure of modularity, which is based on the normalized difference between a the supposed random number of edges one would expect to appear between clusters and the number of edges that a network scientist actually observes. “A good division of a network into communities is not merely one in which there are few edges between communities; it is one in which there are fewer than expected edges between communities” (Newman 2006, 8578). A positive value indicates that there are fewer links between clusters than one would expect, suggesting a network consisting of relatively discrete communities. Positive values, that is, indicate a greater degree of homophily. In contrast, a negative modularity score suggests a that there are more links between clusters than you would expect, indicating the presence of “fuzzy clusters” or sets of relations between nodes that resist easy clustering. We collected data with the Twitter Capturing and Analysis Toolset (TCAT) from DMI’s “american politics” dataset for June 21, 2018, a day with a smaller volume of twitter activity to inverse the event and controversy-based approach that network scientists often take to identify homophilous activity online. Because we used the “social graph by mentions” module in TCAT, identified clusters represent communities of twitter users engaging in conversation and citing one another. Using Matthieu Latapy’s “Partition Analysis Supplement” script, available at Graph Recipes, we identified modularity scores for each partition/cluster/community in our dataset to identify a potential “fuzzy cluster.”Group 3. Engineering Homophily: what is alternative in ''alternative'' social networks?
Project members
Loes Bogers, Serena Coppolino Perfumi, Anu Masso, Silvia Semenzin, Dan XuIntro and Research Question(s)
Which features in “alternative” social media platforms can be seen to enable forms of heterophily and homophily? How and to what extent can they be seen as engines of homophily? A walkthrough of Path, Mastodon and Peanut.Lazersfeld and Merton (1954) coined the terms homophily and heterophily as key concepts to understand friendships as social process in what were at the time racially segregated neighbourhoods in the US. Since the 50s, homophily and the idea that “birds of a feather flock together” stubbornly remained at the core of ideas of friendships and social networks. Heterophily however has not taken off to the same extent as far as understanding social attraction goes, although it would help understand how “opposites attract”, something commonly believed to be as prevalent as its birds-of-a-feather counterpart.
Online news consumption through untraditional sources such as Facebook and Twitter, have produced a coupling between news consumption and personalization: algorithms learn about users’ behaviours and curate content accordingly. Such “content” can by anything suggested by the platform to the user, from news to products to people they might like and want to know more about. These algorithmic suggestive practices are both are said to lead to so called algorithmic filter bubble (Pariser 2011) or echo chambers (Flaxman, Goel & Rao 2016) and can be seen as a threat to the social fabric and even democracy as they decrease people’s exposure to diverse perspectives and difference. In the context of social networks, algorithmic suggesting might occur on the level of news content, but also in terms of people and groups to befriend or link with. Homophily is the operating axiom here: where such suggestions are made based on likeness, meaning they are similar to what/who a user has interacted with before.
The infrastructure of the technical system and the way it curates content and constantly suggests lines of action are both prescriptive and performative (Chun 2018a); it constantly nudges users into performing certain actions (and not others). Each user action conversely, also confirms the system’s predictions about that user, training it its algorithm to recognize likeness even more accurately. If including and promoting difference within social networks can be seen as a social and political imperative, we need to engineer its affordances in such a way, but our understanding of networks is too strongly anchored in axioms of homophily (Chun 2018a). In this project we have set out to recognize and identify moments in which heterophily is actively engineered inside of “alternative” social media platforms such as Path, Mastodon and Peanut. In doing so, we have also started to identify moments in which systems’ patterns for user interaction and other affordances promote homophily instead. The outcomes of this project could be a starting point for developing concrete UI/UX design principles for platform features that can work as engines for heterophily (as well as homophily), with the ultimate goal to envision social networks that can expose us to difference and dissent without disconnecting from otherness, or in Chun's words (2018a) can we move from correlation to co-relation and explore how we are all entangled, to explore difference rather than similarity?
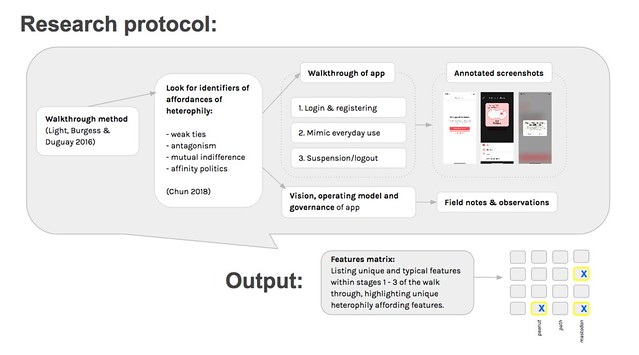
Methods
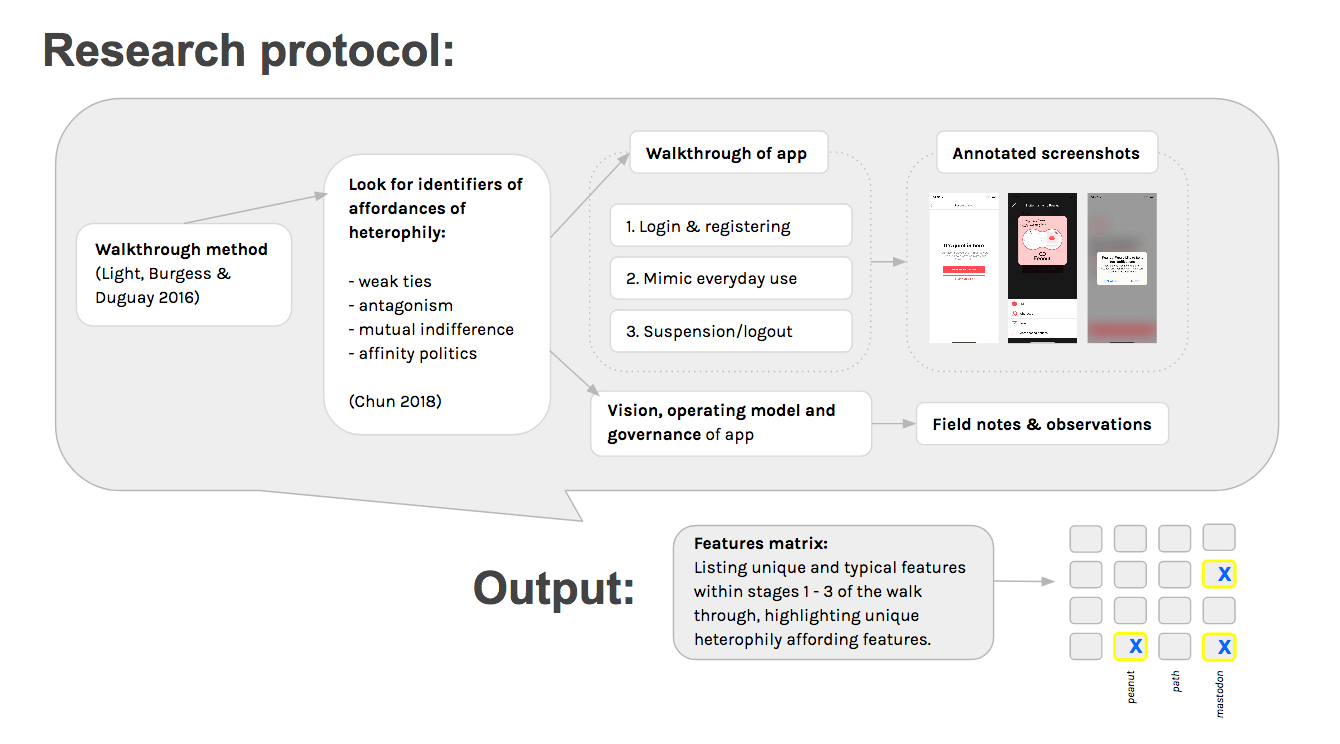
We used the walkthrough method (Light, Burgess & Duguay 2016) to examine the different platforms. The method is developed for critical analysis of apps, building on STS and cultural studies). By engaging with the interface, looking at screens, features and flows of activity, technological mechanisms as well as embedded cultural references can be examined to stake out the app’s “environment of expected use” (Light, Burgess, Duguay 2016: 1). A walkthrough consists of three stages: 1) login and registering; 2) mimicking everyday use, and 3) suspending or logging out or deleting the account. The researcher records field notes and observations throughout, logging screenshots or screencasts. Light, Burgess and Duguay also suggestion looking at additional materials such as business models, revenue sources, economic and political interests, employee recruitment materials, press releases, policies of use, terms and conditions etcetera, while paying attention to mediator characteristics such as UI arrangements, textual content and tone, functions and features, and symbolic representations (2016: 10-15).Key concepts
Chun pointed out that Lazarsfeld and Merton fail to give instructions as to how one might operationalize the examination of heterophily (Chun in Apprich et.al., forthcoming). In the context of the Summer School where this project was developed, Chun has suggested four modes of heterophily that might be identified inside networks:
- Weak ties (as developed by Granovetter 1977, 1983) can be understood as features that leverage outer circles, rather than already strong ties;
- Antagonism or anti-homophily, being moments in which a systems features afford forms of disagreement or dissent;
- Mutual indifference: moments in which actors are connected by being equally indifferent to eg. content or an algorithmic suggestion.
- Affinity politics: organising around a general agenda or cause. This idea was developed by Donna Haraway (1985) as alternative to identity politics (modes of organising around issues and causes that circumvent mobilization along lines of identity labels which still hold the premise of “sameness” in terms of eg. being queer, POC, differently abled).
We selected three case studies that can be considered “alternatives” to the big social media platforms like Instagram, Facebook and Twitter. We selected Mastodon, a Twitter-like platform that emerged from the hacker community and actively positions itself against ad-based incomes and does not sell user data in anonymized nor aggregated form, where uses can program and host their own nodes (implying a rather tech-savvy user base). Secondly, we selected Path, a platform similar to Instagram aimed at a young user base, that emerged from a business start-up. Path is is promoted as putting user agency first when it comes to privacy. We had to nuance these statements very early on, as we will describe below. Thirdly we selected Peanut. A Tinder-like app and discussion platform developed for moms to meet other mom friends near them. Peanut was selected because it starts out from the idea of a small homogenous user base (young cis gender women with children), yet at the same time signifies a form of affinity politics in the way it positions itself: “Meet as mamas, connect as women”. The shared agenda her is that young mums suffer from a big change in identity after having children and can support each other in dealing with these changes that all moms seems to face to a greater or lesser extent.
Findings and visualizations
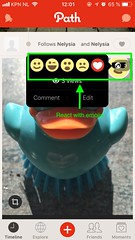 Example of an annotated screenshot from the Path Walkthrough
Example of an annotated screenshot from the Path Walkthrough
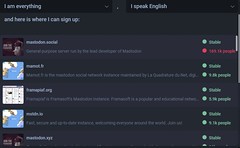 Example of an annotated screenshot from the Path Walkthrough
Example of an annotated screenshot from the Path Walkthrough
Outcomes of the project is a features matrix based on Light, Burgess & Duguay’s analytical categories. We extended their analytical categories with subcategories based on the small, but very typical or very unique features inside the social media platforms studied. We have highlight the features that afford more potential for heterophily.

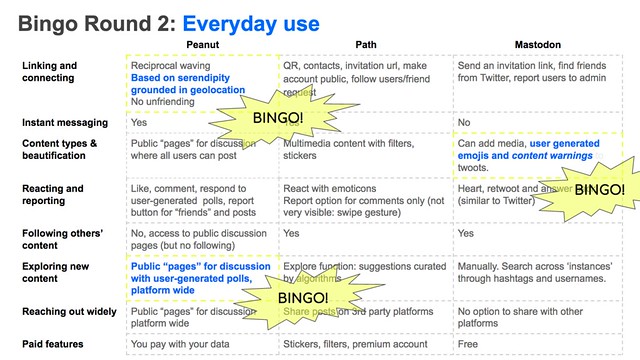
 Homophily works as a basic assumption to greater or lesser extent when approaching social networks, for engineers/developers/designers as well as users themselves. The idea of “sameness” as the basis for connecting is present to greater or lesser extent everywhere.
Homophily works as a basic assumption to greater or lesser extent when approaching social networks, for engineers/developers/designers as well as users themselves. The idea of “sameness” as the basis for connecting is present to greater or lesser extent everywhere. Overall, open-source platform Mastodon offers the most potential in its unique features. It explicitly distances itself from ad-based models and promotes user agency in terms of privacy, both in terms of social privacy (what you share with whom) and privacy on the back-end: user data is not sold in aggregated/anonymized form to third parties. Also, the way privacy is engineered in Mastodon, enables more heterophily as it promotes users’ agency to select content while using something that can be called "decentralized identities". In Mastodon you can engage in different spaces with an avatar registered under a different email address for each community you join within the platform. This practice of several identities makes it impossible to pull together user actions into one single profile, and as a result, circumvents practices of algorithmic profiling that can make predictive/performative suggestions to the user.
We can see an ongoing tension between homophilous and heterophilius “engines” insides alternative social media platforms. Some features are explicitly developed to produce serendipity for example (potential feature for heterophily), while others are latent in the system. Some features that nudge actions along lines of homophily are actively requested by users ("I want a filter to see only people who have similar interests"), or ironically are prevented from taking place due to a small user base (where algorithms do not have large enough “pools” of users to draw suggestions from).
Bibliography Chun, W. (2018a) "Critical Data Studies, or How to Desegregate Networks. From Correlation to Co-relation." Keynote lecture, 9 July Digital Methods Initiative Summer School, Amsterdam. Apprich, C., Chun, W., Cramer, F. and Steyerl, H. (forthcoming) _Pattern Discrimination_ Minneapolis: University of Minnesota Press. Flaxman, S., Goel, S., & Rao, J. M. (2016). Filter bubbles, echo chambers, and online news consumption. Public opinion quarterly, 80(S1), 298-320. Granovetter, M. S. (1977). The strength of weak ties. In Social networks (pp. 347-367). Granovetter, M. (1983). The strength of weak ties: A network theory revisited. Sociological theory, 201-233. Haraway, D. J. (1985). A manifesto for cyborgs: Science, technology, and socialist feminism in the 1980s (pp. 173-204). San Francisco, CA: Center for Social Research and Education. Lazarsfeld, P. F., & Merton, R. K. (1954). Friendship as a social process: A substantive and methodological analysis. Freedom and control in modern society, 18(1), 18-66. Light, B., Burgess, J., & Duguay, S. (2018). The walkthrough method: An approach to the study of apps. New Media & Society, 20(3), 881-900. Pariser, E. (2011). The filter bubble: What the Internet is hiding from you. Penguin UK.
Group 4. Uncommon associations: Metrics and modes of heterophily on Twitter
Project members
Ana Pop Stefanija, Andrea Benedetti, Beatrice Gobbo, Chad Van De Wiele, Clark Powers, Mathieu Jacomy, Yarden SkopIntro and Research Question(s)
In order to operationalize homophily/heterophily we need to clearly define these concepts. The first issues emerges from the fact that heterophily has often been overlooked. Since its introduction by Lazersfeld and Merton (1954), research and literature concerned with social networks has focused almost exclusively on identifying homophily; and when translated onto Web 2.0 technologies, the conceptual ambiguity of heterophily further increases. Moreover, there are few notions, such as affinity politics and potentiality, antagonism and weak ties, closely tied to the dichotomy of homophily and heterophily that require further investigation.
What is regarded as heterophily in social networks and how can we investigate heterophily? Answering this question required a process of going back and forth. Can we investigate by looking at the clusters of co-hashtags (co-occurrence of hashtags)? Can we take the low frequency of hashtags (the outliers) in a data set as a sign of heterophily? Which connections are important? And most importantly, is heterophily visible on a network level? We narrowed our research question to How can we measure heterophily (on Twitter)?"Methods
Research protocol
As a starting point, we decided to look at two networks: the co-hashtags network and the bipartite network of users and hashtags. As we were also learning through a process of trial and (potential) error, we used a small dataset (#chemtrails) to get acquainted with the data and test our analyses on a smaller scale.
The traditional assumption would be that a combination of a pair like #metoo and #MAGA can be considered as a form of difference, or heterophily, of two oppositions meeting. But looking at our findings we saw that this pair is quite commonly used. This led us to look at this as perhaps a form of homophily, where both oppositions attempt at “hijacking” popular hashtags or counter-framing an issue. The main question is then - how to treat what we as researchers usually refer to as “noise” - the long tail of uncommonly used hashtag pairs.On Twitter, the dynamic of attention-seeking dominates the dynamic of opposition.
Case: #MeToo and #MAGA (Make America Great Again) and #FakeNews and #Trump - are some of the most common pairs
There is mutual hijacking - both sides use similar strategies to maximize diffusion. So what can be defined as homophily and heterophily in this context?Limitations:
It is important to acknowledge that there are a lot of variables that influence the way the data is collected, manifested and analyzed. First there is the query, in this case, the hashtag #metoo. The entry point for collecting tweet datasets is usually a trending hashtag, which already creates a mode of homophily in the way the dataset was generated -- similarity is presupposed.
The affordances of the tools social researchers use also have matrix that favor homophily, for example the data visualization tool Gephi, that is used to create clusters of close terms that are connected to each other. Researchers usually ignore or undermine any node that does not cluster, or what we referred to earlier as “noise”. Our challenge was to think beyond the tools that structure our understanding of the data and find a way to characterize this noise. The TCAT tool to query Twitter data also limits the researchers with what can be investigated and how. Relying on particular tools drives the analysis in a particular direction. The “nature” of the social network and its affordances also leads toward community-building based on similarities. Especially specific to Twitter is the affordance to form ad hoc networked publics around issues, represented by particular hashtags.Step-by-step conceptualization diagram
 Fig.XXX Starting from the visualization of frequency of pairs of hashtags in a co-hashtag network exported from TCAT, the result is mathematically inverted and then used to see, for each user, which pairs of hashtags are used and to then calculate their entropy value, allowing categorization between being an entropist inside the issue, or a conformist.
Fig.XXX Starting from the visualization of frequency of pairs of hashtags in a co-hashtag network exported from TCAT, the result is mathematically inverted and then used to see, for each user, which pairs of hashtags are used and to then calculate their entropy value, allowing categorization between being an entropist inside the issue, or a conformist.
Findings and visualizations
We looked at how pairs of hashtags are used by the same users (not necessarily in the same tweets, so here “co-occurrence” is extended as a concept).
We ranked the hashtag associations from most common to less common, then split them in two parts, each containing half the total frequency of co-occurrences:
-
The “head” (black)
-
The “tail” (blue)
 Settings
Settings
Only the top* 100 hashtags top 10000 users have been used, in terms of frequency (the "Infinity" value means that all of them were used). In addition, the users having used less than 2 of those hashtags have been omitted.
* HASHTAG MEDIAN mode: OFF. In this mode, we use the median hashtags instead of the top.
Anonymization in viz: ON. If enabled, the names in the visualizations are replaced by random proxies. They will be the same from one time to another (seeded randomization). The data will not be anonymized, though.
ProcessThe initial network contains associations of users with hashtags (and their frequency). We first filter to keep only a part of the users and hashtags (settings exposed below). Then we build the network of hashtag pairs. It is important to note that by design, hashtag pairs are necessarily appearing in the same tweets. The pairs mean that users have used both hashtags in the observed period, but not necessary at the same time. We keep track of two metrics: (1) we count the number of users involved in each pair, and (2) we build a score named "Cumulative Cooccurrence Frequency" that accounts for users mentioning hashtags multiple times. It is computed as such: when a user mentions hashtags A and B, it adds to the score the minimum frequency of A and B.
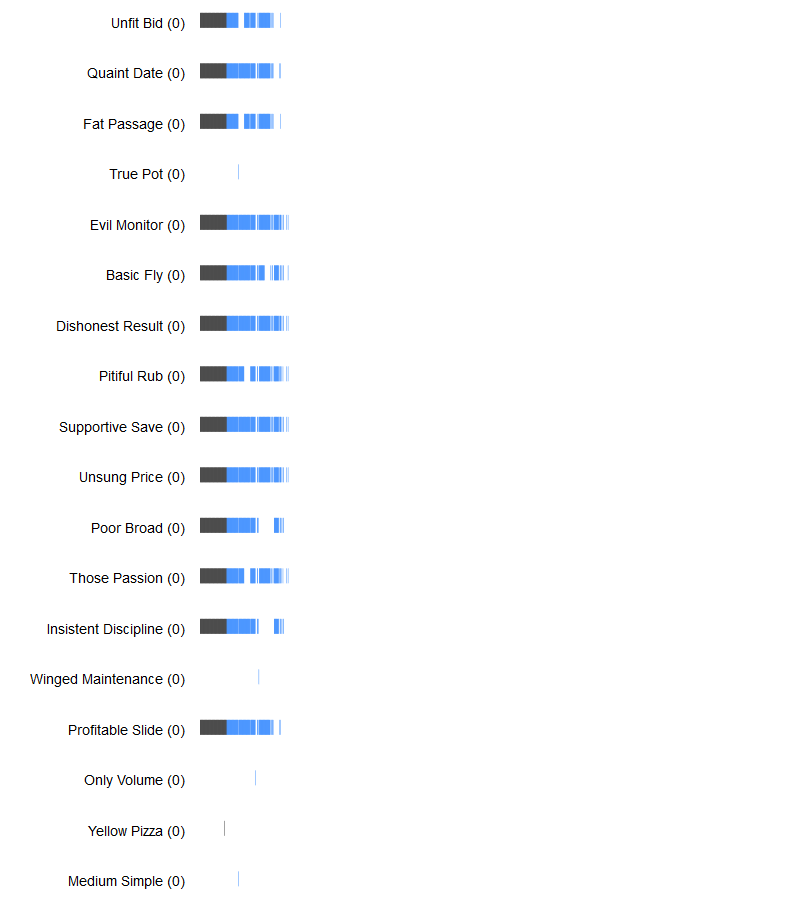
Data summaryAfter filtering, we have 100 hashtags, 99 users and 4816 hashtag pairs.
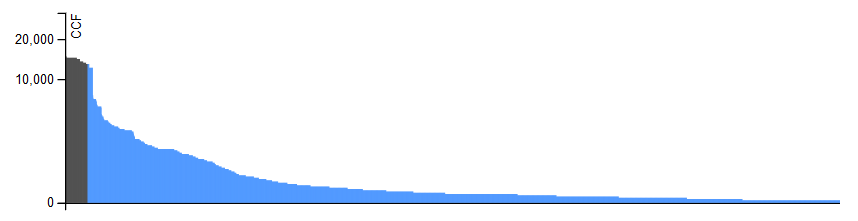
Cumulative cooccurrence frequency of pairs of hashtags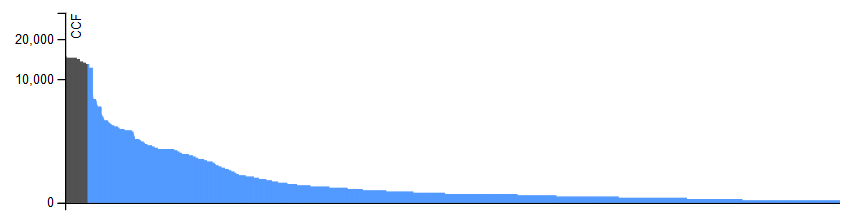 Above is a bar chart of the 4816 hashtag pairs. The pairs are ranked by decreasing "cumulative cooccurrence frequency" (CCF), which is also plotted in the Y axis. The chart is split on two parts (black and blue colored) containing the same total of CCF. In other terms, each part has the same area. The areas do not look the same because a power scale is used (for the sake of readability). It will probably be shaped as a "power law" and the black part is the (tall) "head" and the blue is the (long) "tail".
Infrequency
Above is a bar chart of the 4816 hashtag pairs. The pairs are ranked by decreasing "cumulative cooccurrence frequency" (CCF), which is also plotted in the Y axis. The chart is split on two parts (black and blue colored) containing the same total of CCF. In other terms, each part has the same area. The areas do not look the same because a power scale is used (for the sake of readability). It will probably be shaped as a "power law" and the black part is the (tall) "head" and the blue is the (long) "tail".
Infrequency
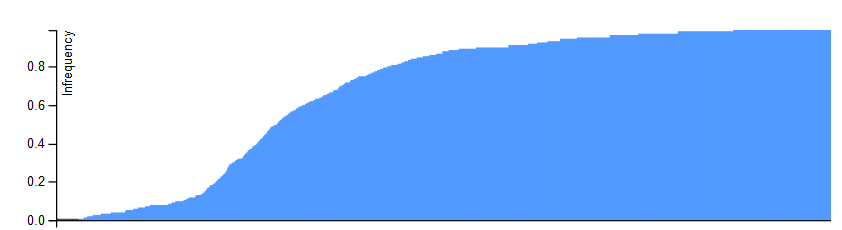
This is also a bar chart of the 4816 hashtag pairs, ranked by CCF (it aligns with the chart above). Here the Y axis plots "Infrequency", which is basically the inverse of CCF (but not exactly).
Infrequency = D / (D + CCF) ...where D is a damping factor, arbitrary set to 100.
Infrequency is comprised in [0, 1] and gives a higher score to hashtag pairs that have a low CCF. The rationale for the damping factor is to not overvalue very small CCF (1 or 2) compared to less small but still small values (5-10), especially compared to the head (>10,000).
User profiles (limit: 300)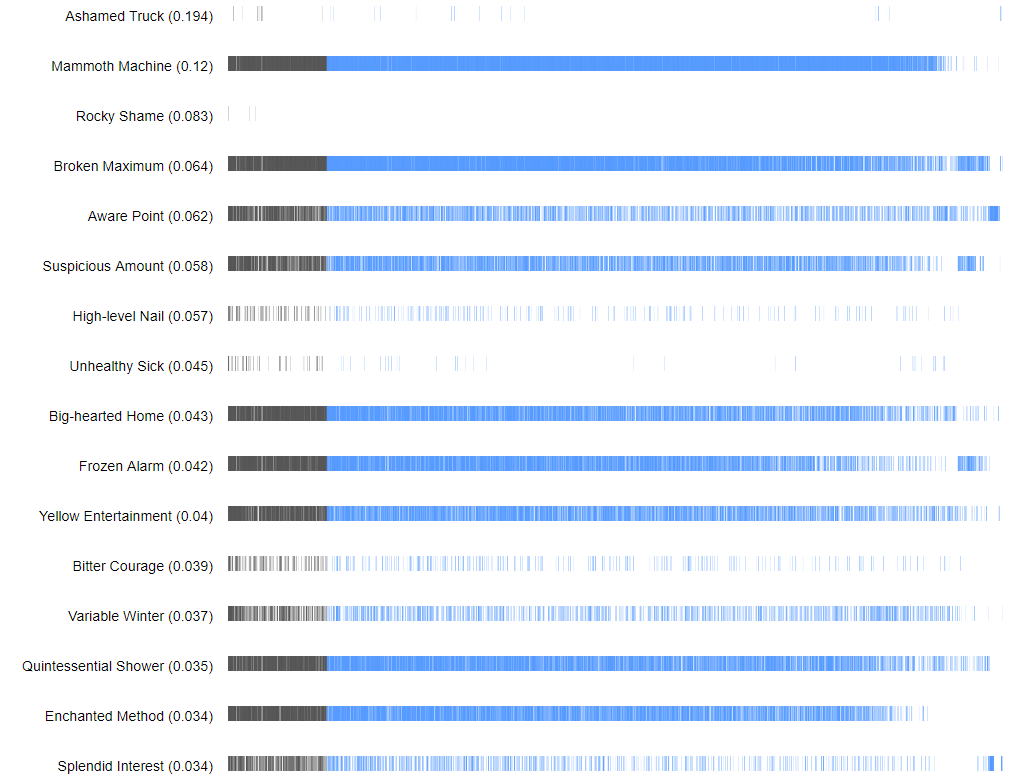
Each user chart pictures the pairs of hashtags appearing in the user's tweets. Each pair is a line whose opacity is weighted after the cooccurrence frequency (CF): for hashtags A and B, the CF equals the minimum number of occurrences of A and B. The pairs are aligned with the charts above (decreasing CCF).
For each user we computed an individual score, the "average infrequency share" (AIS), roughly corresponding to the average infrequency of its hashtag pairs.
AIS = SUM_pairs[ S(pair) * I(pair) ] / P
...where S is the share of CCF, I is the infrequency of the pair, and P is the number of pairs.
S(pair|user) = Frequency(pair|user) / CCF(pair)
Users are ranked by decreasing AIS. AIS is high if the user uses many infrequent pairs. The presence of a few frequent pairs will not matter much, but many of them will lower the score. It's also an average, so users with just a few pairs can have extreme scores.
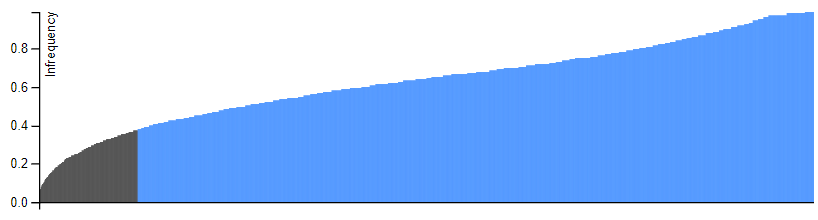
conceptualisationEntropy is viewed as producing noise and chaos, but what if minority uses are not just noise, but rather a different activity? Not discarding the many uncommon hashtag associations to the benefit of the few common ones.
Some users, whom we chose to call "entropists" seem to be strongly skewed toward uncommon associations, producing new questions: Who are they? What do they do? How many are there? Is there a structured desire for uncommon associations? To answer these questions, we seek to draw the line between noise and non-dominant activity.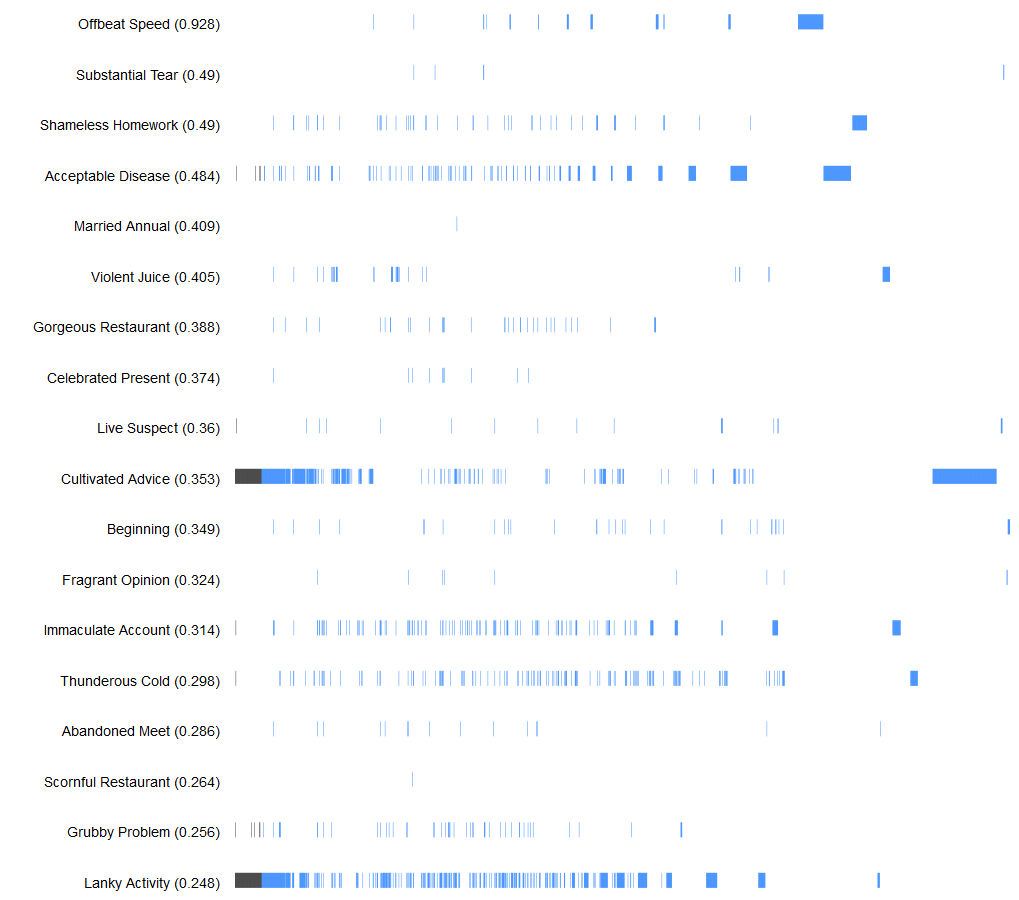
left: Top "entropists" from top 300 users of #MeToo
right: Top "conformists" from top 300 users of #MeToo
Step-by-step conceptualization

Questions Raised, and Further Work
-
A continuation of this study can be testing our hypothesis on other datasets, by using the same methods. Perhaps in other contexts common co-occurrences are not antagonistic? Then what are they?
-
Also trying to conduct more research not only on the "entropists" but on the entropy itself - can we identify patterns there?
-
The challenge is also to create new tools to visualize and analyze entropy and heterophily in network theory.
-
Text analysis suggests further pathways through which to approach homo / heterophily (panel data on co-occurrence, segmentation by RT vs non-RT, hashtag variants).
-
Textual analysis, although constrained by the platform, offers an approach that resists a fixation on platform affordances.


| I | Attachment | Action | Size | Date | Who |
Comment |
|---|---|---|---|---|---|---|
| |
researchprotocol.png | manage | 149 K | 19 Jul 2018 - 13:01 | LoesBogers | Research Protocol |
{kind=link}
{kind=link}
Ideas, requests, problems regarding Foswiki? Send feedback