Open Data Outside the Open Data Bubble
Team Members
Dr. Christoph Raetzsch (Freie Universität Berlin), Prof. Helen Kennedy (University of Sheffield), Ivar Dusseljee (University of Amsterdam), Jan-Jaap Heine (University of Amsterdam).
Introduction
This research project is set out to map the open data revolution outside of the open data bubble, focusing on the United Kingdom as a case study. In order to do this, first, the bubble needed to be defined. Open data advocate Alisdair Rae refers to open data as the less-glamorous cousin of big data. Rae states that mainly experts make use of open data whilst it offers a myriad of possibilities for people outside what we define as the "open data bubble". The question Rae posits about open data - i.e., "open to whom", is of relevance to our research for it asks who can access the data. In theory, "open" means that the data is available to anyone. However, what this research finds is that not everybody actually uses or engages with such data. Primarily because the field is still expert based (Rae n. pag). Moreover, Dan McQuillan argues that the opening of data is highly managed by corporations, who are actively involved in open data initiatives precisely so they can control what Rae talks about - what is opened, by whom, and for what purposes.
Further, according to Bates (2013), open initiatives (for example, Open Government Data, Open Access, Free and Open Source Software) can be understood, in part, as efforts to reverse the trend towards the private ownership of and therefore differential access to data. Open data groups lobby for access to and the ability to reuse datasets which often produced by public institutions. They insist on access and reuse for everyone, free of charge, and without discrimination (Bates xx). Such groups see the opening up of public datasets as a form of democratization of data, allowing the kind of access to data that Boyd and Crawford argue is ominously absent from the data delirium. This research explores who is participating in the open data initiatives: advocates, activists, experts and/or ordinary people?
Building on Williams Keywords (1976), Thumim (2012) offers a useful sketch of what is evoked by the term ordinary people. The first sense in which the term is used is denigratory it infers an inferior position in a hierarchy, as well as the banal, the dull and the mundane. The second, opposing sense is celebratory, in which the ordinary is valued precisely because it is marginalised by its powerful opposite. The third sense in which the term ordinary people is used is to refer to people whose everyday practices are not remarkable, or what van Zoonen calls ordinary daily humdrum (2001: 673, cited in Thumim 2012: 43). The final sense is as citizens in a democracy, invoking a sense of citizenship, or of a public. As such, ordinary people are a political force; they ask us to question whether the right kinds of access and literacy are in place to enable themselves to act as citizens. This final sense of "ordinary people" constructs them as potential civil society actors. So the third sense of the term as identified by Thumim is most relevant for our purposes. That is to say, we use it neither in a denigratory nor a celebratory way, and we are not interested in active civil society actors. Of course the term is problematic arguably, most people is active and engaged in some ways, in some things. But we need a working definition in order to proceed, so this is ours.
Critics of open data argue, in different ways, that open data enables the already enabled. According to Rae, although the release of open datasets can be for the good, it needs to be accompanied by answers to these three questions: opened by whom, open to whom, and open to what (Rae, 2014)? McQuillan argues that big tech corporations are involved in open data initiatives precisely in order to control the answers to these questions.Thus open access to data alone is not enough to sidestep the emergence of data-driven digital divides. Bates (2013) study of open government data confirmed that governments' release of open data was consistently under conditions that all them to control information flows and exercise power. But the question of who is enabled by open data rarely looks at who the actors are in the open data, activists or "ordinary people", and whether open data is gaining traction not just in other civil society groups but amongst these "ordinary people". Our research fills this gap.
Research Questions
1. Is open data gaining traction as an issue amongst broader publics (outside the open data bubble)? If so, how? 2. Who is participating in open data initiatives? Advocates, experts or ordinary people?Methodology
1. Identify the UK bubble by drawing up a list of groups and organizations from Twitter, Facebook and Google:
-
From the list of groups and organizations on Twitter with open data or #opendata in their bio, remove non-UK groups and organizations.
-
Add groups identified through searching for Facebook groups in Google.
-
Add groups identified from affiliate lists of UK-based open data networks.
-
Google searches for UK-based open data groups.
-
Manually cluster the 58 UK groups from the original list; 6 added through Facebook and one other known group. Total number of groups is 65.
-
Extract URLs from search results.
-
Identify non-governmental/not-in-the-bubble websites.
-
Identify core/top issues discussed by these not-in-the-bubble sites.
Findings
Who tweets?
Taking the accounts from the open data and transparency dataset, we manually deleted non-UK tweeters and bots, leaving 24 UK-based tweeters. Those remaining are categorized as follows:
-
business: 6
-
private individuals: 9
-
government: 3
-
NGOs: 6
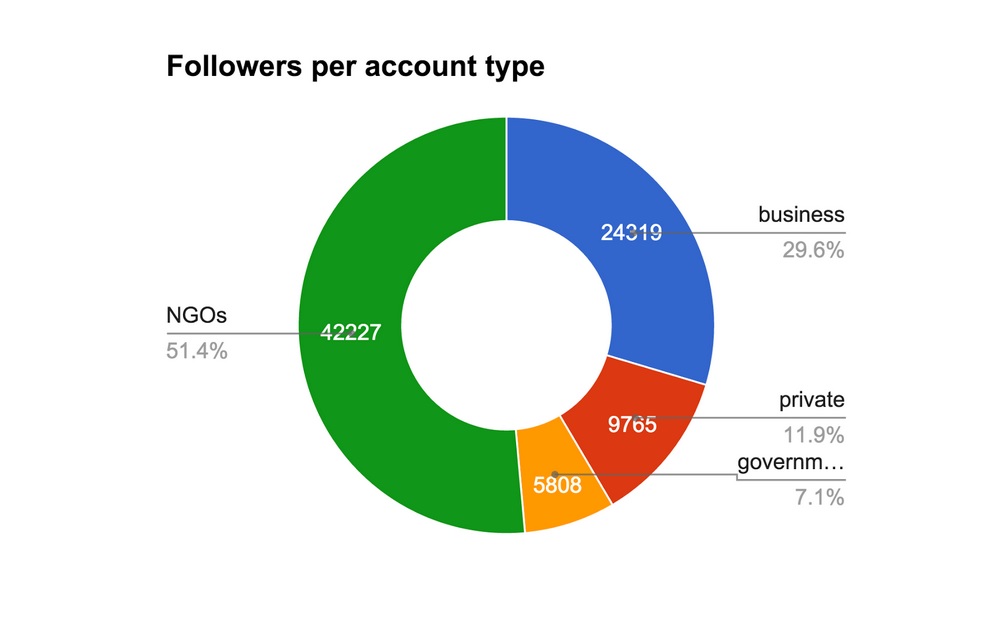
Whilst it is good to see that the highest number of actors are private individuals, almost all work in or with open data in an NGO, the government or business organizations. And there are overlaps between actors - i.e., two accounts for one organisation (as in the case of the Open Data Institute). More than half of the total followers in this set of tweeters follow NGOs; just under half follow two major NGOs, ODI (Open Data Institute) and OKFN (Open Knowledge Foundation). See the pie chart below:
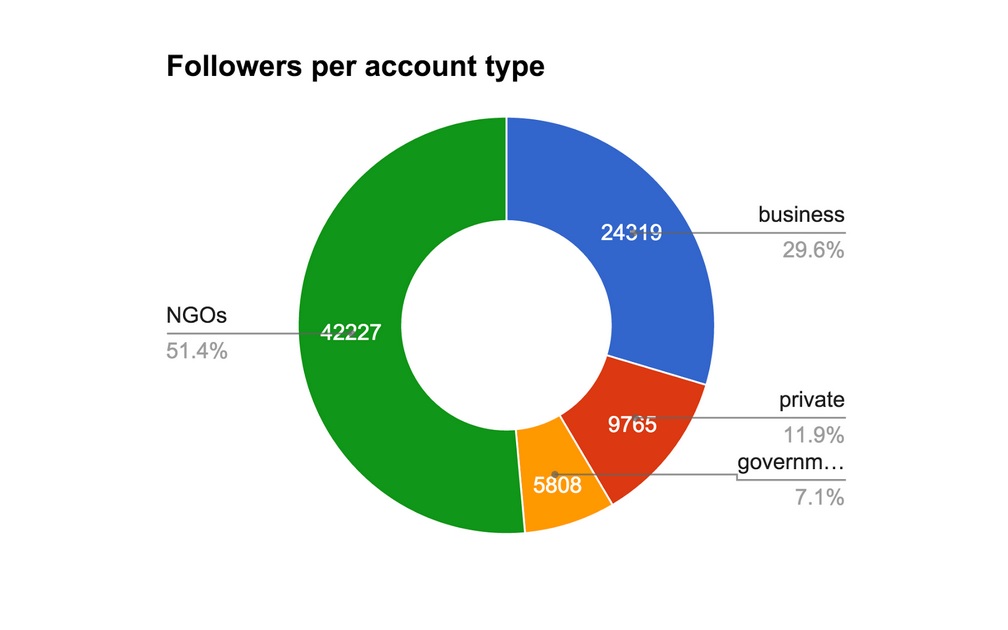
Follower overlap
Open Knowledge Foundation and Open Data Institute Twitter followers overlap substantially, as seen in this untreated NodeXL visualisation of the relationship between the two sets. Of the top 24 tweeters, 15 of whom are groups and organizations, 6 are on our list of 65 UK open data organizations.

Co-hashtag analysis of "open data" & #opendata tweets
Dataset: open_data_and_transparency (#accountability, #bigdata, #corruption, #dataprotection, #datarevolution, #dataviz, #eudatap, #foi, #gov20, #lobbying, #opendata, #opengov, #openup14, #provacy, #transparency, #WebTAP, open data) Start date: 1 january 2015 End date: 12 January 2015 Search query: [open data OR opendata] Opened in Gephi, removed node open data and applied Force Atlas 2 layout: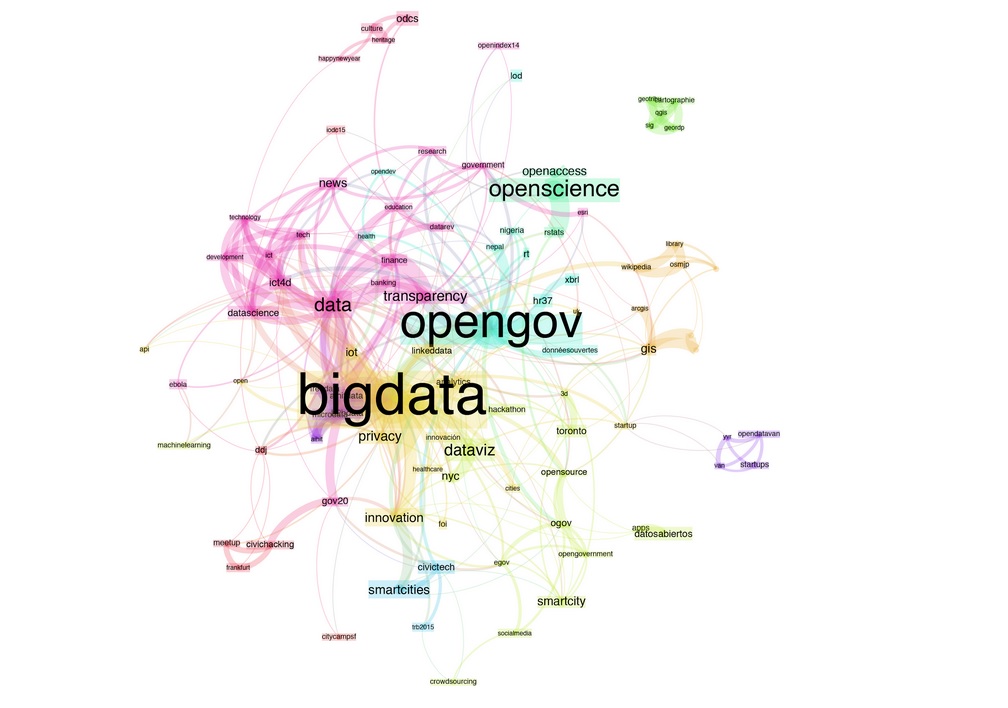 The co-hashtag analysis revealed that the most frequently mentioned topics are specialist terms (big data (mentioned most frequently, 605 times), open government and open science). Issues, retrieved from local as well as national UK forums, which might concern ordinary people (city planning, safe streets, weather, healthcare, transport) were mentioned infrequently (1-12 times).
The co-hashtag analysis revealed that the most frequently mentioned topics are specialist terms (big data (mentioned most frequently, 605 times), open government and open science). Issues, retrieved from local as well as national UK forums, which might concern ordinary people (city planning, safe streets, weather, healthcare, transport) were mentioned infrequently (1-12 times).
Search engine link analysis
Comparative search across Yahoo!, Google and Bing for links to British government data platforms returned very different results. Most links were generated within the http://data.gov.uk website itself. These were excluded from analysis. The rest of the websites were mined for the main top issues, using Issue Discovery. The differences between the search engines are telling. Yahoo! shows a trend toward traffic related issues. Google shows a trend toward technical questions and portals, Bing has month names as the main issue, probably because of one or few sites having a structure organized around monthly entries.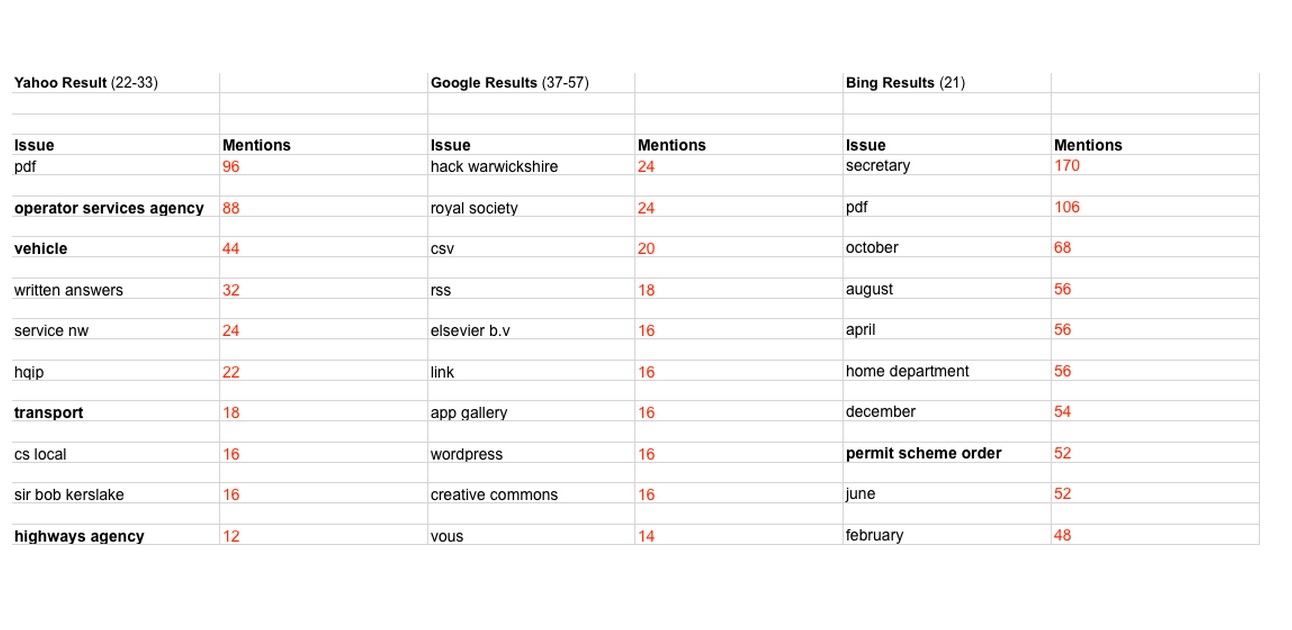
One of the main issues with sites linking to data.gov.org, analyzed through Issue Discovery, is file formats. This poses the question of how data is shared with the public and the difference between .pdf, .xml or .kml files also limits further uses.
The results from Yahoo!, though, can be confirmed preliminarily by the five most popular datasets accessed in data.gov.org, of which three relate to traffic and planned roadworks.Moreover, the overview of the UK Open Data City Census shows that the top cities are Cambridge, Leeds, Nottingham, Manchester, Nottingham and Bristol, given that these cities have registered open data on several public subjects (see http://gb-city.census.okfn.org/). The sources of this data, though, are very diverse and do not come all from the same centralized open data hub of a municipal government.
Looking for links to the above open data portals returned very low results for Manchester (2), Leeds (4), from media or civil society actors (i.e., not ordinary people).
The exception here was London, with 161 sites referring back to London DataStore. When changing settings in Google without instant search, there are only 113. A Harvester analysis of these (removing duplicates, Google and YouTube results) returned a list of 24 links, but only 13 different actors. This shows how important manual sorting of results is. The issues returned from an analysis of these links are not useful. This method of generating issues through website links does not generate additional insights.
Combining the Yahoo! search with the co-hashtag analysis, we generated themes that are being discussed in relation to open data (the link analysis focused on outside-bubble actors, co-hashtag analysis included people inside and outside):
-
City planning, safe streets
-
Transport, road safety, road conditions
-
File type (.pdf, .csv)
-
Health/health care
-
Poverty
Establishing connections between "ordinary people" and open data
The challenge was to establish a link between open data as a technical question and a policy issue (which is the dominant framing of the theme inside the bubble of advocates) to ordinary people, who will use data for specific purposes without necessarily mentioning the term itself. One way around this challenge was to take the top 100 terms associated with open data (TCAT open data and transparency dataset) and see if voluntary organizations in the UK were referring to any of these. The list was reduced to 38 terms, by taking out terms which where too specific (place names, particular technical terms, personal names, etc.) We furthermore obtained a list of 11,000+ organizations from the UK National Council for Voluntary Organisations and selected those that were mentioned with a website (6,200). A first attempt to use Google Scraper for matching the 38 terms with 6,200 websites failed, probably because of the volume of variables. We then reduced the list of terms to 6 (opendata, open data, applications, application, tool, interface). This combination also proved to include too many variables, so we reduced to using the term open data only, and searched the first approx 1000 voluntary organisation websites. Out of 553 pages, 1 site mentioned open data three times. We cannot retrieve the details of these mentions because the process was terminated by Google and that lost stored data.
Other strategies used to explore whether "ordinary people" are talking about open data included:
-
Two IssueCrawler searches, one seeded with the list of 65 UK open data organisations identified by us, and one seeded with a list of top 100 websites returned in a Google search for [open data]. This revealed that diverse actors and subjects are mentioning open data; this shows some tractions outside the bubble. However, we do not know how they are mentioning it.
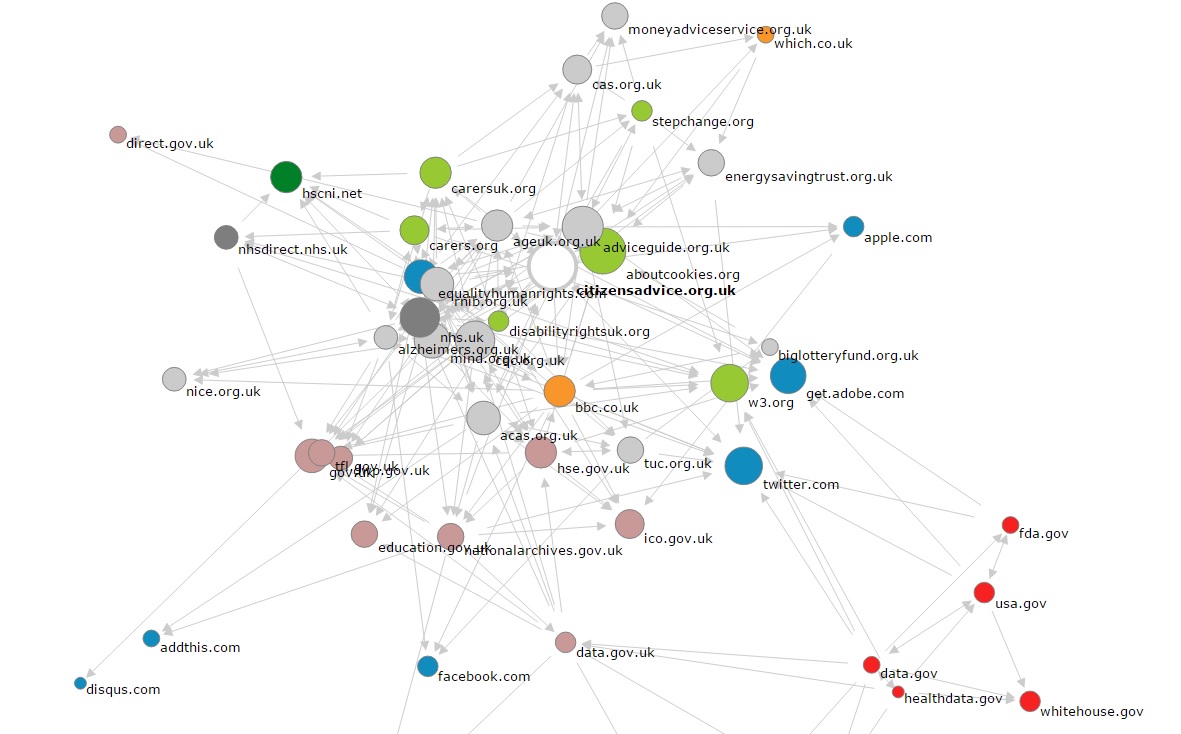
-
LexisNexis search for the term [open data] in news publications; returned 246 mentions; mainly shown in professional journals - financial, business, IT, UK/US focus, but global theme. The nature of the discussion confirms that there is a bubble of actors, discussing mainly the technical aspects of open data applications. Mentions of civic uses remain marginal. Filtered down to UK publications, only six news articles were published in mainstream newspapers (3 articles in The Guardian; 3 articles on telegraph.co.uk) since 1980.
Limitations
The datasets we worked with (Twitter dataset only 12 days worth of tweets - feasibility versus research considerations); further, not UK specific.
The available tools only enable you to answer particular types of questions; within each tool there are technical limitations because they piggyback on technologies (e.g., Google), that want to restrict what we do.
Platforms restricting access limits research that can be done on Facebook.
Conclusion
We conclude that open data has very little traction outside of the bubble of open data. Our analysis of top UK tweeters from the original open data and transparency dataset showed that 9 out of 24 were private individuals, which suggests some traction, but most of these work with or in open data and are connected to an NGO, to the government or business open data organisations. Moreover, these 9/24 have less than 12% of the total follower community for these top tweeters. Co-hashtag analysis (not UK-specific) showed that the most frequently mentioned topics mentioned in combination with opendata or #opendata were specialist terms, such as big data (mentioned most frequently, 605 times), open government and open science. Terms which might be considered as the concerns of ordinary people (like city planning, safe streets, weather, healthcare, transport and the file type that open data comes in) were mentioned infrequently, sometimes only once, and not more than 12 times.
Further evidence of the lack of traction beyond the bubble could be seen in the search engine link analysis that we undertook. Searches on Yahoo!, Google and Bing for links to datasets at data.gov.uk, leedsdatamill.org, open.manchester.gov.uk and data.london.gov.uk returns very small numbers of links: links to the national open dataset, data.gov.uk numbered up to 33 on Yahoo!, 57 on Google and 21 on Bing. There were 2 links to the Manchester open dataset, 4 links to Leeds, and 24 links to London. These are very low numbers within the broader context of online activity.
Also, on forums on which ordinary people might discuss issues that concern them, we found very few references to open data, so few that there was no point searching [open data AND transport]. Previous research (Kennedy et al 2014) identifies that comments spaces of local newspapers are active spaces for discussion, but searching the three local newspapers of the three local datasets we looked at, Leeds, Manchester and London, we found one article mentioning open data, from Leeds, two years old, with no comments.
Moving away from a focus on private individuals, we searched the websites of around 500 voluntary organisations in the UK and found only three mentions on one website. We cannot retrieve the details of this because the process was terminated by Google and that lost stored data. A LexisNexis search for the term [open data[ in UK publications found that the issue is mainly discussed in terms of its technical feasibility, technologies and legislative frameworks.
Thus we conclude that, based on the datasets that were available to us (which has certain limitations as identified above), online discussion of open data takes place (on Twitter) primarily amongst actors inside the bubble. Based on our searches, elsewhere online, there is very little discussion of the term open data.
Of course, it may be that ordinary people and/or active citizens are applying open data in specific contexts without using the term open data. The challenge then is to identify the language the ordinary people use to talk about open data. At present, it is difficult to make the connection between formal discussion of open data within the bubble and less formal discussion outside the bubble, because the term open data itself might not be used. A challenge for future research, then, is to identify the terms and language used by ordinary people to talk about open data, if indeed they do talk about it. It may be that digital methods are not the best tools to meet this challenge. Once this has been achieved, it might be possible to search for and identify best practices for engaging ordinary people with open data this means enabling people to see that opening data is relevant to and has an impact on their lives. These are big challenges which extend beyond open data (how do people talk about online privacy, for example? How to enable peoples interest in what happens to their social media data?).
Bibliography
Bates, J. Information policy and the crises of neoliberalism: the case of Open Government Data in the UK. Proceedings of the IAMCR 2013 Conference, 25-29 June 2013. Available at: http://eprints.whiterose.ac.uk/77655/7/WRR0_77655.pdf (accessed 29th September 2014). Rae, A. Open data visualization: the dawn of understanding? StatsLife Blog, Royal Statistical Society, 29th September 2014. Available at: http://www.statslife.org.uk/opinion/1815-open-data-visualisation-the-dawn-of-understanding (accessed 29th September 2014). Rogers, Richard. Digital Methods. Cambridge, MA: MIT Press, 2013. Thumim, N. Self-Representation and Digital Culture. Basingstoke: Palgrave MacMillan, 2012. Williams, R. Keywords: a vocabulary of culture and society. Kent: Croom Helm, 1976. van Zoonen, L. Desire and Resistance: Big Brother and the recognition of everyday life. Media, Culture and Society, 23.5 (2001): 667-9.

| I | Attachment | Action | Size | Date | Who |
Comment |
|---|---|---|---|---|---|---|
| |
FollowersTwitter.jpg | manage | 51 K | 19 Jan 2015 - 09:33 | IvarDusseljee | Pie chart |
| |
IssueCrawler_100Google_1.jpg | manage | 156 K | 19 Jan 2015 - 10:37 | IvarDusseljee |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Topic revision: 19 Jan 2015, IvarDusseljee
Ideas, requests, problems regarding Foswiki? Send feedback