Track the Trackers
Team Members
Yngvil Beyer, Erik Borra, Carolin Gerlitz, Anne Helmond, Koen Martens, Simeona Petkova, JC Plantin, Bernhard Rieder, Lonneke van der Velden, Esther WeltevredeIntroduction
The cloud seems to be a buzz word; what it refers to could be difficult to grasp. This project aims to make (some parts) of the cloud tangible. The project focuses on devices that track users online and show their encounters with the cloud, both those that require active participation of the user (through Widgets) and those encounters that are automated (through tags, web bugs, pixels and beacons). For this purpose we have re-purposed Ghostery, a browser plugin that informs users which companies are present on websites they visit to build a custom tool for tracker detection. We focus on automated tracking devices, that operate as default setting once a user requests a website and widgets, including social buttons, which require user action to set further data transmission in motion. We use a wide definition of “tracker”, including a number of devices that allow for user-data collection, such as internal tracking devices, bugs, widgets, external analytic services and further interfaces to the cloud.The newly developed tool also allows us to create connections among websites, defining relations based on their connection to the same tracking devices, giving insight into the fluidity of content. In short, by repurposing the Ghostery tool we are able to characterize different collections of URLs. We are further interested to study tracking ecologies in a number of URL collections, issue spaces or web spheres, to see if there are specific trackers at work in particular countries, whether data-protective countries or web spheres deploy less tracking devices and whether countries like Iran use trackers from major US corporations. On top of that we are interested in which trackers are at work in the news sphere, in specific issue spaces, such as health/addiction sites, adults' and childrens' sites, privacy-concerned sites and technology blogs.
The wider aim of the project is to contribute to explicate and make more concrete the more abstract claims of ongoing data-veillance in the back-end by providing detailed insights in the ecology and economy of tracking.
Research questions
General questions:- What is the relative presence of the different trackers?
- Are there clusters of trackers? i.e. Which trackers can be found on the tracker sites?
- What is the reach of specific trackers?
- What is the political economy of the cloud looking at ‘cloud technology’? ‘Power concentrations of the cloud’
- Which trackers are at work in specific issue spaces, such as health/addiction sites, privacy-concerned sites or technology blogs?
- What type of statistics do the privacy advocate sites recommend?
- How ‘likable’ (or ‘social’ or ‘tracky’) are different URL-lists, for instance, adult’s sites compared to children’s sites?
- Do data-protective countries or web spheres deploy less tracking devices? Do countries such as Iran use trackers from major US corporations?
- How 'social' is the news?
- How 'tracky' is the news?
- How did specific sites (New York Times) become more social or tracky over time?
- Can we visualize the visible sharing elements (buttons) and invisible tracking elements (cookies)
- Are there friendly relationships between beacons?
- Self-hosted versus cloud-hosted analytics
- When did the trackers start and when did they cease to exist? Related: The lifespan of a beacon :)
- “Back-date” trackers
- Find out how the tracker code has changed over time, so we can detect the same technology over time. For example, the tracking javascript for Google Analytics may have been coded differently in 2008 and 2010.
- Find ‘old’ trackers by looking into the source code of the retrieved pages of the Internet Archive. Add those to the list of trackers. (Date them?)
- Comparing adult entertainment sphere and the kids and teens entertainment sphere: which one is most likable or trackable?
- The focus on widgets and tracking devices could further be extended to also tracking content delivery APIs in order to not only see what data is flowing from the website to tracking services and analytics, but also what data is flowing into the site itself.
Methodology
Our methodology is based on repurposing Ghostery. We have built a tool on top of Ghostery, designed as alternative hyperlink analysis, which is not following the links but tracking the trackers. We named it ‘Tracker Tracker’.About Ghostery: “Ghostery is your window into the invisible web – tags, web bugs, pixels and beacons that are included on web pages in order to get an idea of your online behavior.
Ghostery tracks the trackers and gives you a roll-call of the ad networks, behavioral data providers, web publishers, and other companies interested in your activity.” http://www.ghostery.com/
Comparing the “trackiness” of three national spheres
Ghostery itself distinguishes between five different types of elements: analytics, ads, widgets, trackers, privacy. We adopt these categories for our analysis. Mapping the back-end of the web for a set of URLs
- Make URL lists of top 100 results, ideally based on Alexa Topsites in a Googledocs : We composed 25 lists of URL types (source is Alexa, unless mentioned otherwise): news sites, country sites (Germany, Iran), Wired (Archive.org), privacy advocate sites (privacyadvocates.ca), adult industry, trackers (ghostery), technology and science blogs (technorati), Top 100 alexa (Dutch, Brasil, Russia), New York Times 1996-2011 (archive wayback machine), social media networking sites (Wikipedia), e-commerce sites/shopping, US embassies (US site), Children's sites, dating sites, alcohol&drugs, addictions.
- Select three types of URL to compare: eg. Germany, Netherlands, Iran - and run it in the “Tracker Tracker” tool: https://testing.digitalmethods.net/tools/beta/trackerTracker/
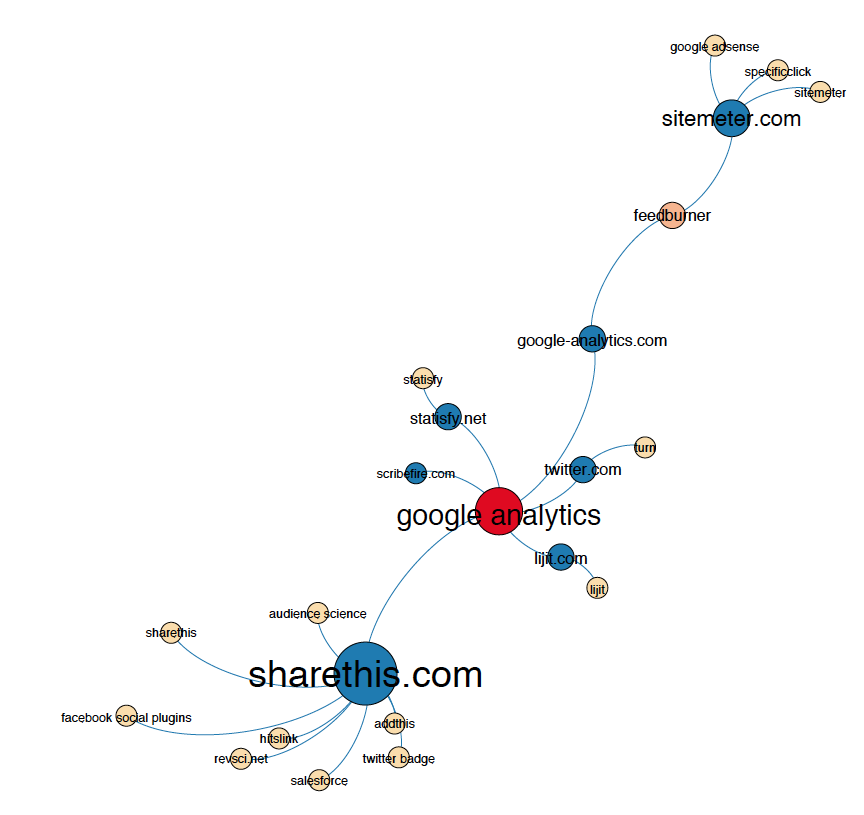
- Map the results using Mondrian (presence of trackers across sites) or Gephi (relations between sites based on tracker presence)
Proposed method:
- Select a website eg: http://www.newyorktimes.com
- Run it through the Internet Archive Tool: https://tools.issuecrawler.net/beta/internetArchiveWaybackMachineLinkRipper/
- For the scope of this study, take one single Archive URL per year
- Put URLs in Track tool: https://testing.digitalmethods.net/tools/beta/trackerTracker/
- Write down the trackers per year
- Visualize the rise of trackers over time
Data and tools
URL collections: https://docs.google.com/spreadsheet/ccc?key=0Amv6UO8S5qbHdF93LVhERngxTWt6ektXVjZuTjRUN2c&hl=en_US#gid=5Collected with: https://tools.issuecrawler.net/beta/harvestUrls/ and https://tools.issuecrawler.net/beta/linkRipper/
Tracker Tracker tool: https://tools.digitalmethods.net/beta/trackerTracker/
Visualization tools: http://www.theusrus.de/Mo ndrian/
http://gephi.org
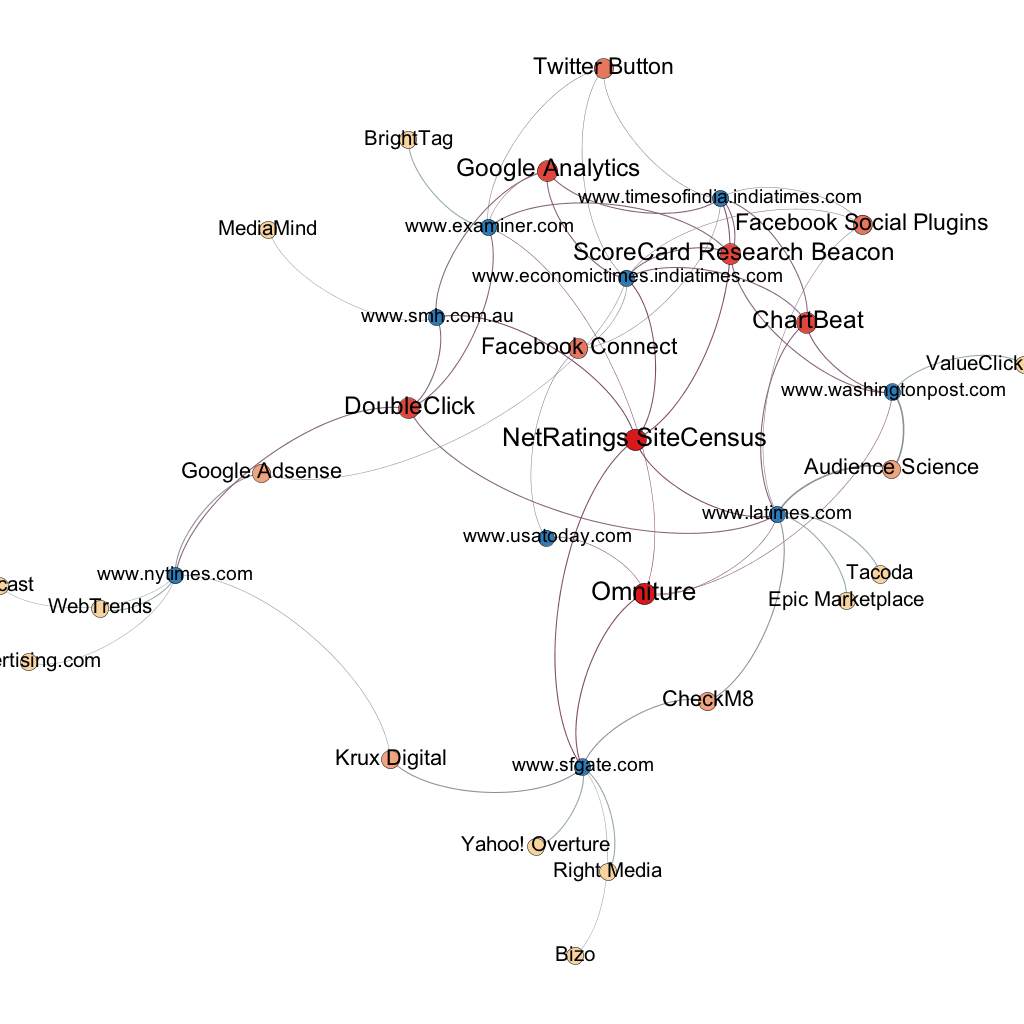
Findings
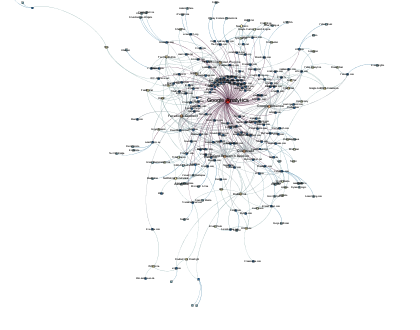
Trackers in Top10 Technology blogs according to Technorati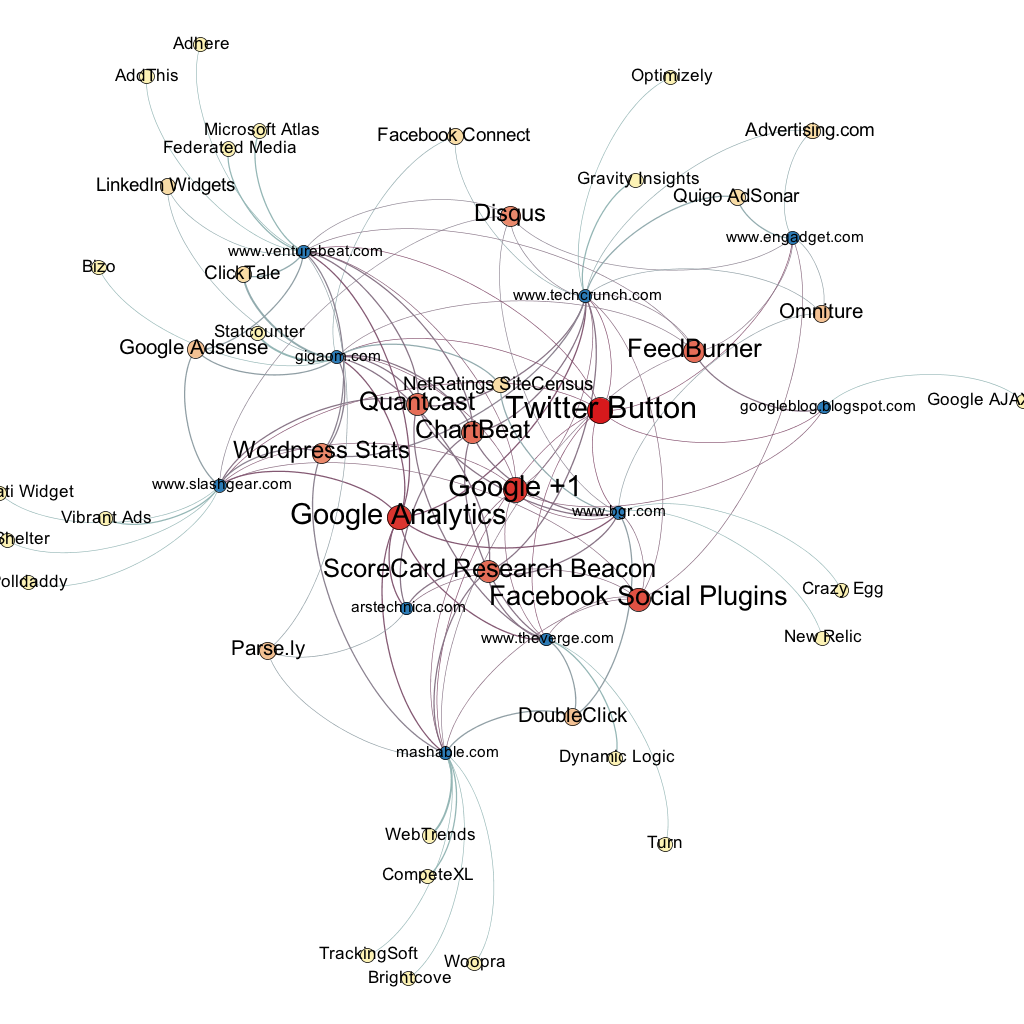 Trackers in Top10 News websites according to Alexa
Trackers in Top10 News websites according to Alexa
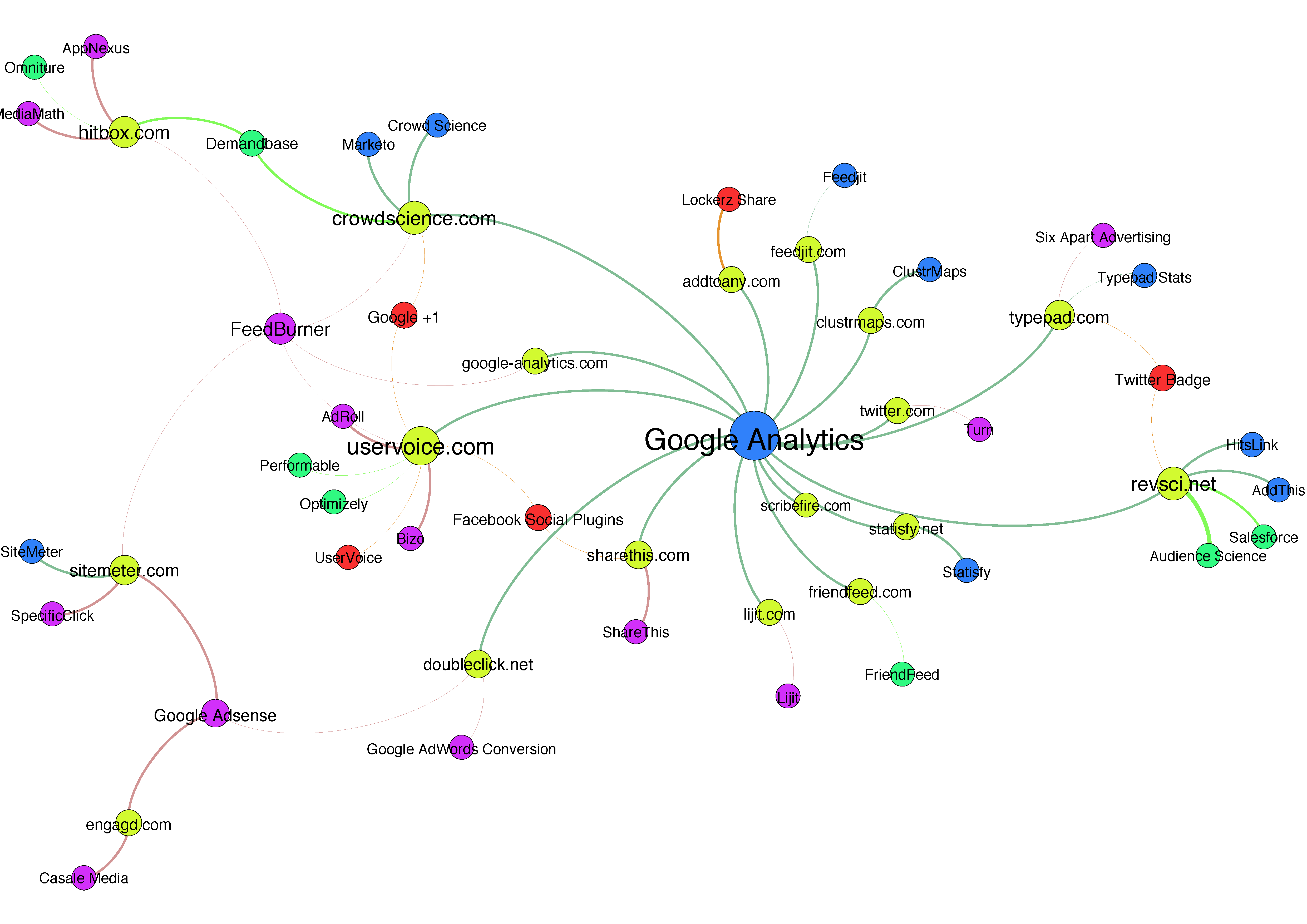
 Top 10 Children Pre-School sites (Alexa)
Top 10 Children Pre-School sites (Alexa)

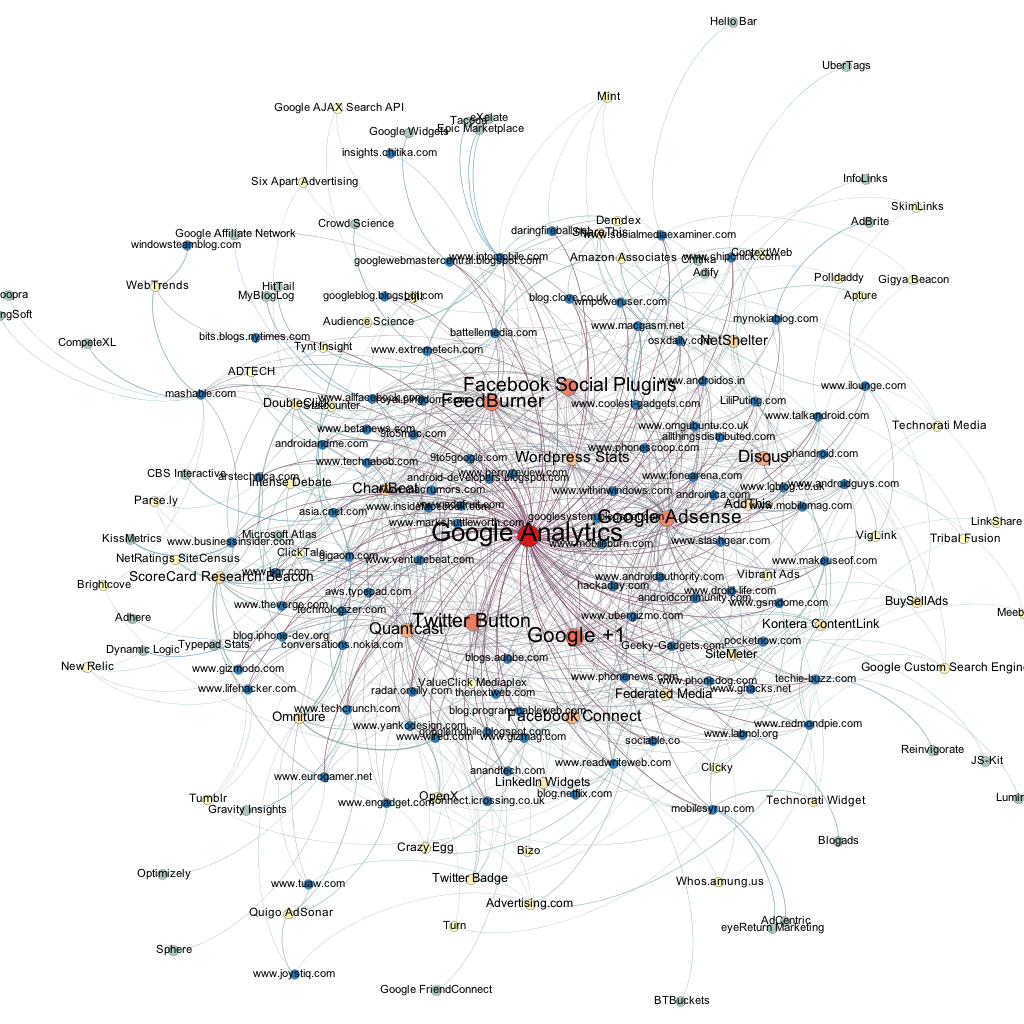
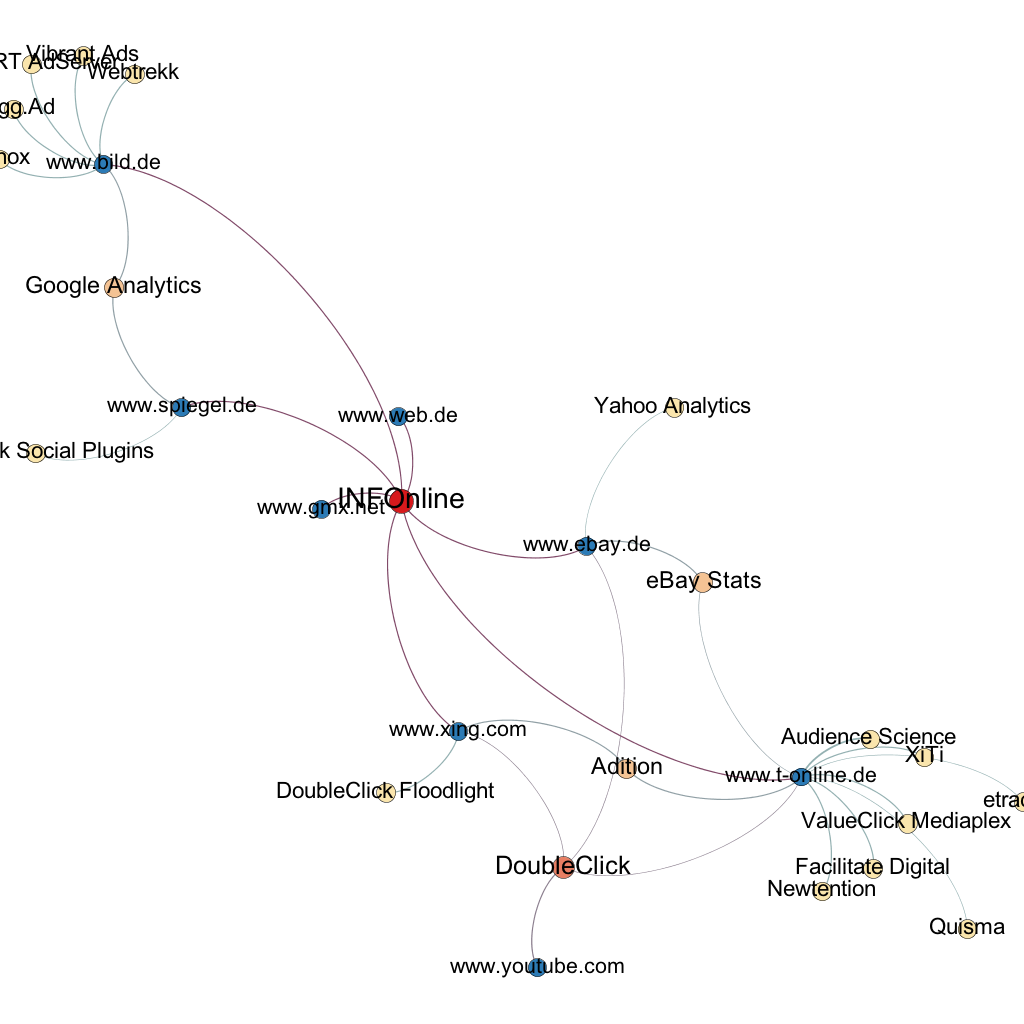
Top 100 Technology Blogs based on Technorati

Tools adjustment requests
To work with Internet Archive URLsInput: http://web.archive.org/web/19961112181513id_/http://www.nytimes.com/
Array ( [0] => http://web.archive.org/web/19961112181513id_/http [1] => http://www.nytimes.com/ ) Retrieving: http://web.archive.org/web/19961112181513id_/http
> Does the tool break the URL? It outputs http://www.nytimes.com/ which is not the archive URL but the live web URL. It takes the second part of the second http://
Tools adjustment requests
Include content delivery sites, such as youtube, flickr, amazon.Howto? Detect platform URL not sufficient (may also point to presence). Widget codes. Embed codes. Or content farm URLs:
 Repurpose Firebug (?)
Repurpose Firebug (?)Include other plugin tools.
Further projects that use this tool:
Visualizing Facebook’s Alternative Fabric of the Web by Anne Helmond & Carolin Gerlitz, see blogpost for more information.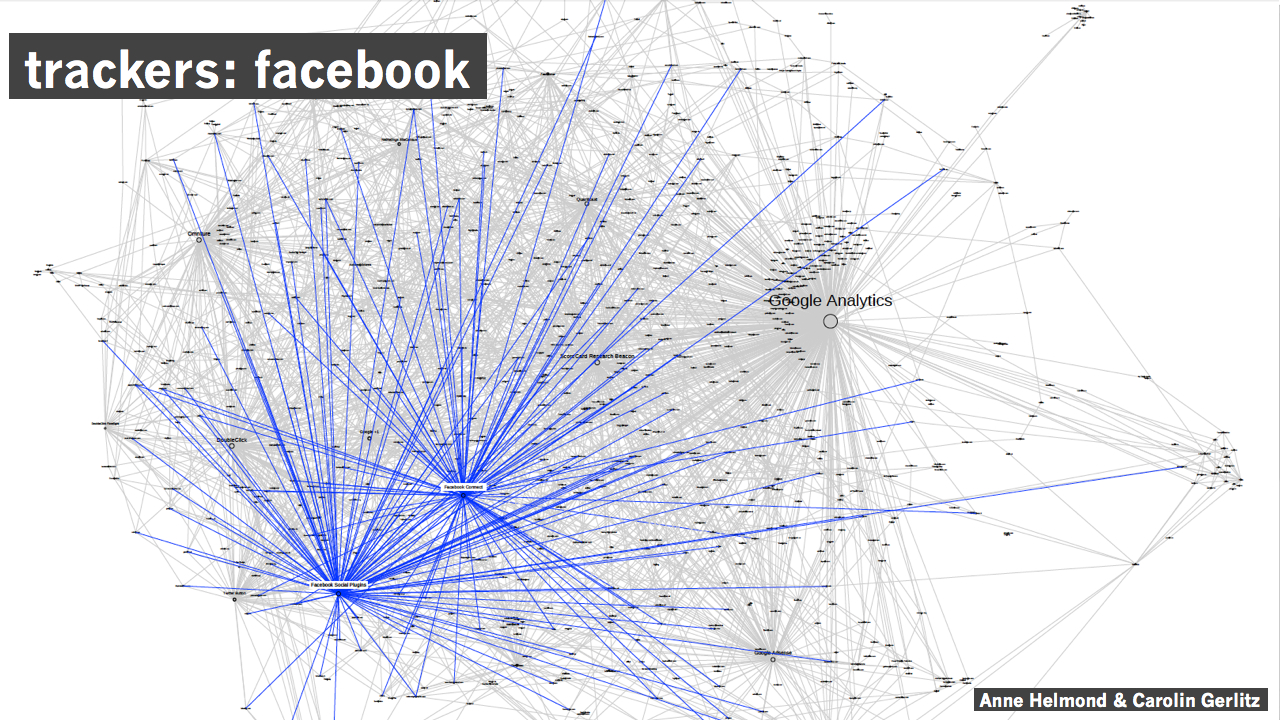 Trackers gebruikt op de websites van Nederlandse politieke partijen
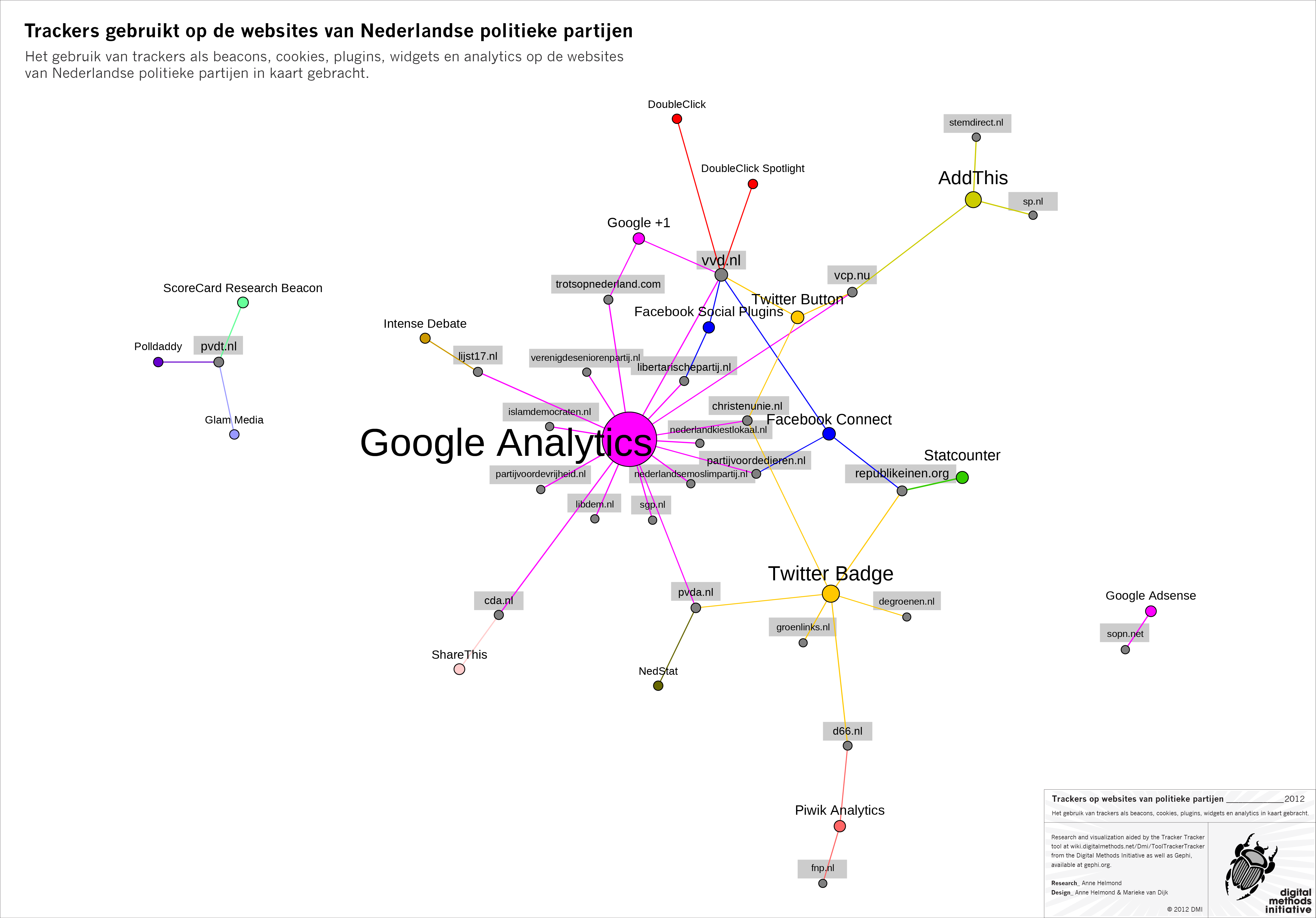
Trackers on Dutch political websites by Anne Helmond.
Het gebruik van trackers als beacons, cookies, plugins, widgets en analytics op de websites van Nederlandse politieke partijen in kaart gebracht. > Download full PDF.
Trackers gebruikt op de websites van Nederlandse politieke partijen
Trackers on Dutch political websites by Anne Helmond.
Het gebruik van trackers als beacons, cookies, plugins, widgets en analytics op de websites van Nederlandse politieke partijen in kaart gebracht. > Download full PDF.
Resources
Andrejevic, M. 2007. iSpy: Surveillance and Power in the Interactive Era. Lawrence: University Press of Kansas.Berry, D. 2011. Philosophy of Software. London: Palgrave Macmillan.
Elmer, Greg, Profiling machines: mapping the personal information economy, MIT press, 2004
Langlois, G., McKelvey, F., Elmer, G. and Werbin, G. 2009. Mapping Commercial Web 2.0 Worlds: Towards a New Critical Ontogenesis. Fibreculture 14, online.
Roosendaal, A. 2010. Facebook Tracks and Traces Everyone: Like This!, [[http://papers.ssrn.com/sol3/papers.cfm##?abstract_id=1717563][Tilburg Law School Research Paper No. 03/2011]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This topic: Dmi > DmiWinterSchool > DmiWinterSchool2012TrackingTheTrackers
Topic revision: 11 Jun 2012, AnneHelmond
Topic revision: 11 Jun 2012, AnneHelmond
Ideas, requests, problems regarding Foswiki? Send feedback