Language spheres
Team Members
Natalia Sanchez, Diana MesaIntroduction
- Main objectives
- Background
Research Question
What is the proportion between local/ non-local content per country in the query results using national search engine ? What is the frequency of shared or unique URLs in the data set, which contries overlaps the most ?Case Study
Using national engines we query the term “Amazonía” (Amazon region), which concerned geographically South American countries. The query was applied to a much broader group which included other latin American countries and Spain mainteining the initial criteria. As well, to further test the tension between language and national spheres the same methodology was applied to the French-speaking web-sphere using the regional query term “Sahara” which would concern in a regional level the African-French speaking countries and in a more international level other European and American French speaking countries. This comparative study allow constructing some hypothesis on regards of whereas the homogenization is a specific condition to Spanish language or a generality for langue spheres were the delimitation of the national is not sensible to language sutil differences. The query terms are alledgelly related to environmental issues in order to begging questionning the visibility of different agents (countries, type of organization, etc) in this discussion of relation between territory, natural resources and information; the regional, local, national and international.Methodology
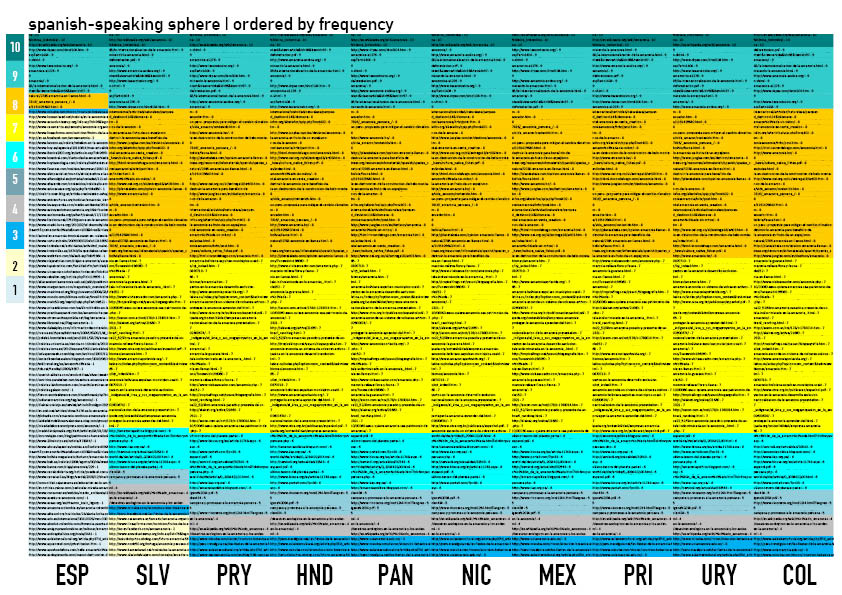
Spanish-speaking sphere 1. The Lippmannian device was used in order to query and obtain a clean list of URL per country using “Amazonia” for Spanish speaking and “Sahara” for French speaking countries. The settings were adjusted to national domains and specific language (spanish or french). The complete listing were exported to an Excel file. A previous test with a proxy to see if it affected the results, turned out to be negative. 2. A specific color was assigned to each country ; we identified each one of the 900 links in the dataset according to it. For the Spanish-speaking web-sphere the criteria and methodology used to perform such identification was based on the domain of the link and later on qualitative individual analysis of content (such as contact address of a website) to determined a relationship to a country. The domain resulted a limiting criteria as only few used the national domains, giving way to a superior number of .com or .org and other domains such as: travel and edu, among others. As well, there was a significant group of URL impossible to associate to a particular country ; they were assigned the color white. To determine this limit, we used the DM tool “TLD Counts”. And still coding...
And still coding...
 3. We used the Triangulation tool to determine the frequency of URL's per country
3. We used the Triangulation tool to determine the frequency of URL's per country

Findings
National search engines are not showing regional results :Proportion graphs showed that query results are not country related. In the spanish speaking sphere results tended to be regional compared to querys results were almost 98% equal in the french-sphere. As the result of the need to perform individual analysis of a URL’s content in order to determined their relationship to a specific country the coding was done manually, as there was not a tool that could allows to extract the information we needed and then to further visualized it. The visualization was done using a simple excel spreadsheet and the color-coding system was implemented. Wikipedia seems to be federating the language spheres
Conclusion
Languages are determinig the search engine spheres. Networks withing a sphere are not machine visible. Color-coding rules!Further Readings
External Links
- http://googleresearch.blogspot.com/2011/07/languages-of-world-wide-web.html
- http://infosthetics.com/archives/2011/06/all_the_names_arranging_the_2982_names_on_the_911_memorial.html
This topic: Dmi > DmiSummerSchool > SummerSchool2011 > DmiSummer2011Projects > DmiSummer2011LanguageSpheres
Topic revision: 10 Jul 2011, DianaMesa
Topic revision: 10 Jul 2011, DianaMesa
Ideas, requests, problems regarding Foswiki? Send feedback